大模型价格战背后的技术革命:剖析DeepSeek-V3.2的DSA稀疏注意力
DeepSeek 2025年9月29日正式发布DeepSeek-V3.2-Exp 模型,这是一个实验性(Experimental)的版本。作为迈向新一代架构的中间步骤,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 引入的DeepSeek Sparse Attention (DSA)是一项重要的原创稀疏注意力机制,它通过改变模型处理信息的方式,在基本保持性能的同时,显著提升了效率。
本次更新带来了 API 大幅度降价,开发者调用 DeepSeek API 的成本将降低 50% 以上。

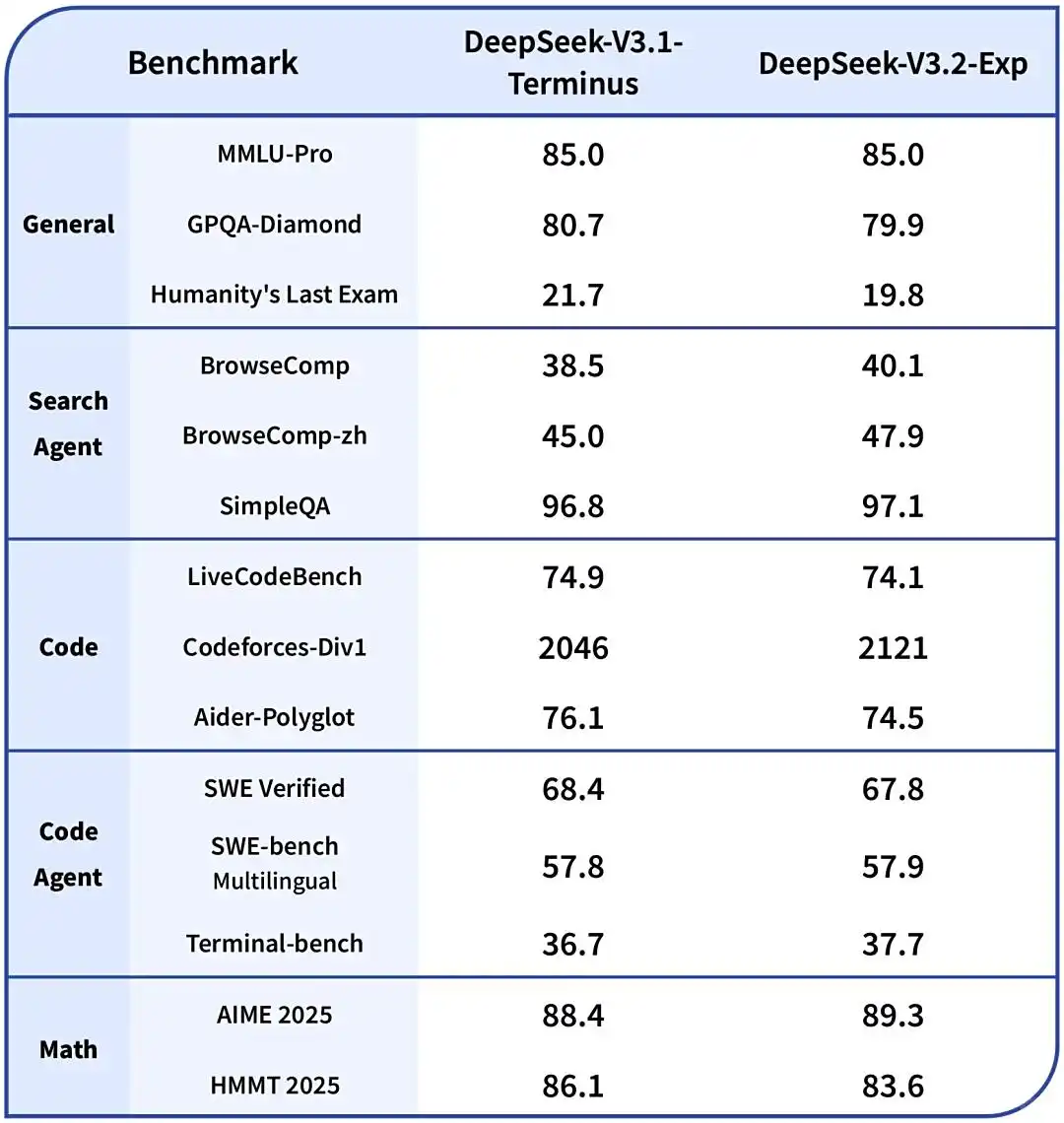
相较V3.1-Terminus,各方面指标也有明显的提升
一、核心技术原理:从“面面俱到”到“精准捕捉”
DSA 的核心创新在于,它不再让序列中的每个 Token(词元)都与其他所有 Token 进行计算,而是智能地筛选出最关键的一部分进行精细处理。
- 传统注意力机制:其计算方式需要每个 Token 与序列中所有其他 Token 进行交互,计算复杂度随着序列长度(L)的增加呈平方级(O(L²)) 增长。这在处理长文本时,会带来巨大的计算和内存开销。
- DSA 的突破:通过其核心组件 "闪电索引器"(Lightning Indexer),DSA 能够快速判断对于当前正在处理的 Token,序列中哪些历史 Token 是最重要的。模型随后只从这些最重要的 Token 中选取一小部分(例如 Top-2048 个)进行精细的注意力计算。这使得其核心计算复杂度从 O(L²) 降至 O(L·k),其中 k 是一个远小于 L 的固定值。
在此前的文章《 让Transformer模型更小、更快的一系列技术?—— 一份关于注意力优化、条件计算与搜索的综合论述 》中介绍transform模型优化技术,其中就包括稀疏注意力这条路径
二、模型架构与训练方法
模型架构
DSA并非凭空创造,而是与DeepSeek-V3.1的现有架构深度融合的结果,其中的工程实现非常精妙。它主要包含三个部分:
- 闪电索引器(Lightning Indexer):一个轻量级的索引器,负责快速评估并选出最重要的 Token。这个索引器本身计算复杂度仍是O(L²),但其头数(H^I)远少于主注意力头数,并且支持FP8低精度计算,因此其实际计算开销非常小,是高效实现的关键。
- 细粒度 Token 选择机制:根据索引器的评分,执行精确的 Top-k 选择,并进行后续的注意力计算。
- 与MLA协同工作:DSA是在V3.1的MLA(Multi-head Latent Attention)架构的MQA(Multi-Query Attention)模式上实例化的。简单来说,MLA已经通过“共享潜在向量”压缩了KV缓存,而DSA在此基础上进一步做了“稀疏化”筛选,实现了 “共享 + 压缩 + 稀疏”三重极致优化 。
三阶段训练法
为了在提升效率的同时确保模型性能不下降,DSA 采用了一种精心的三阶段训练策略:
- 稠密预热阶段:在此阶段,模型仍使用传统的稠密注意力机制,但会冻结主模型的参数,仅训练新引入的“闪电索引器”。目标是让索引器的输出分布与原始模型的注意力分布对齐,可以理解为让索引器“学会模仿”老师。
- 稀疏训练阶段:在索引器初始化完成后,模型正式启用稀疏注意力模式。在此阶段,索引器和模型的其他部分会分别进行优化,让整个模型适应这种新的、高效的信息处理模式。
- 后训练阶段:此阶段与 DeepSeek-V3.1 的训练流程类似,包括专家知识蒸馏和混合强化学习,旨在进一步增强模型在特定领域(如数学、编程)的能力并完成与人类偏好的对齐,同时避免多阶段训练中可能出现的“灾难性遗忘”问题。
三、技术优势与潜在影响
DSA 技术带来的好处和深远影响是多方面的:
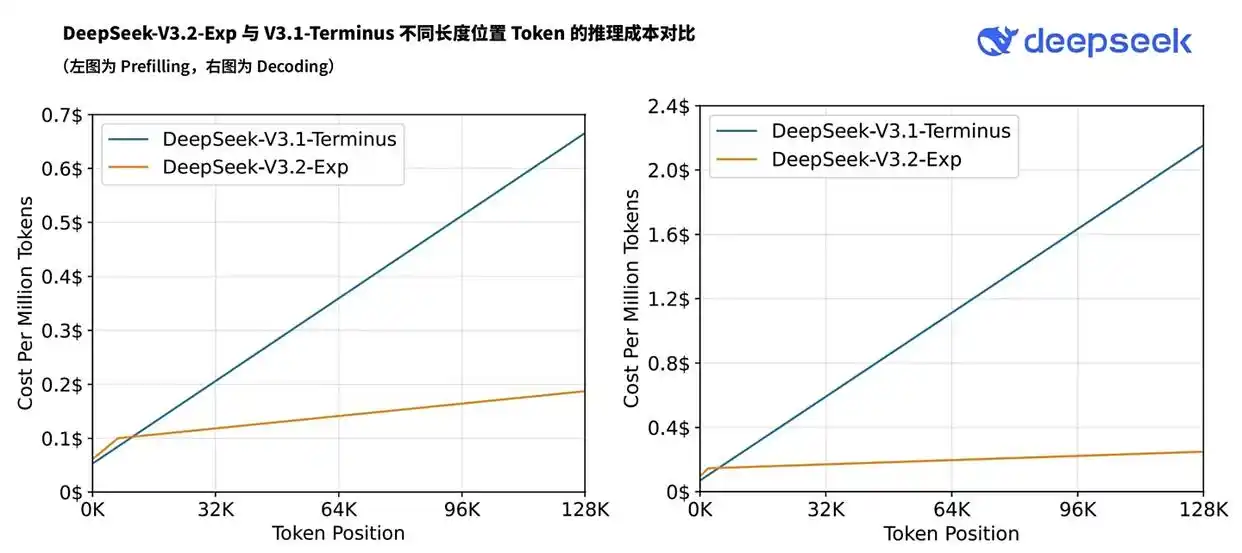
- 效率大幅提升:根据官方数据,DSA 带来了显著的效率提升。长文本推理速度提升了约 2-3倍,同时内存使用量降低了 30-40%。
- 使用成本降低:效率的提升最直接的体现就是成本的下降。得益于 DSA,DeepSeek-V3.2 的 API 调用价格降低了超过 50%,使得高性能大模型的应用更加普惠。
- 为下一代架构铺路:DSA 被官方定义为一次“实验性”的探索,是迈向下一代模型架构(如 V4)的关键中间步骤。它验证了稀疏注意力在大规模生产环境中的可行性,为未来的架构创新奠定了基础。
四、技术权衡与潜在风险
任何技术革新都是在进行权衡,DSA 也不例外。它在带来高效率的同时,也可能引入一些潜在的风险:
- 信息丢失的可能:Top-k 机制本质上是一种信息过滤,存在极小概率遗漏掉某些关键但不起眼的远距离信息,导致在复杂的长链条推理中出现偏差。
- 模型视野收窄:如果筛选机制过于保守,可能会过度地将模型的推理过程限制在某个“舒适区”内,从而削弱其进行跨领域联想和创造性思考的能力。
- 索引器偏差累积:索引器本身是一个轻量化的近似器,如果它在特定语境下做出了错误的Token选择决策,那么后续的所有计算都将建立在这个有偏差的子集上,可能导致答案不稳定
五、实际应用场景中的表现
DeepSeek-V3.2 所采用的DSA,在长文档总结和代码生成这类任务上,不仅仅是简单提升了速度,它通过改变模型处理信息的方式,带来了能力上的切实改变。
下面的表格详细对比了 DeepSeek-V3.2 在这两项任务上的核心表现与提升原因。
| 任务类型 | 性能表现 | 背后的关键技术 (DSA) |
|---|---|---|
| 长文档总结 | 在长文本推理场景下,速度提升约2-3倍,同时内存使用降低30-40%。在经典的“大海捞针”测试中,能在64K长度的文本中实现100%的信息检索准确率。 | 通过“闪电索引器”快速判断并只关注当前最重要的历史Token(例如Top-2048个),将计算复杂度从O(L²)降至O(L·k),从而高效处理长序列。其技术原型NSA通过压缩、选择、滑动窗口三种策略,模拟了人类“粗读摘要、精读重点、强记近期”的智慧,确保关键信息不遗漏。 |
| 代码生成 | 在Codeforces编程竞赛评分上从 V3.1 的2046提升至2121。在考验代码能力的Aider-Polyglot基准上略有波动(76.1 → 74.5)。作为智能体处理SWE-bench Multilingual任务时,性能持平或微升(57.8 → 57.9)。 | 稀疏注意力机制迫使模型在训练时专注于最重要的信息,这可能通过过滤掉不相关的注意力噪声来提高其逻辑推理和代码规划能力。在处理仓库级代码时,能更好地在冗长代码库中捕捉关键依赖关系。 |
总结
DeepSeek-V3.2-Exp的核心创新在于其DeepSeek稀疏注意力(DSA)机制,这是一种细粒度的稀疏注意力技术。
DSA通过其核心组件“闪电索引器” (Lightning Indexer),动态选择序列中最重要的少量Token进行精细计算。此举将主模型的注意力计算复杂度从传统的 O(L²) 成功降低至 O(L·k),其中k是一个远小于序列长度L的固定值。
这一根本性的优化,使得模型在处理长文本时,推理速度提升了约2-3倍,内存使用降低了30-40%,同时保持了与前代模型V3.1-Terminus相当的性能水平。显著的效率提升也直接带来了应用成本的下降,其API调用价格降低了超过50%。
DSA的发布,不仅是一次技术实验,也为处理更长上下文、更高效率的下一代大模型架构奠定了重要基础