Spark专题-第三部分:性能监控与实战优化(1)-认识spark ui
Spark专题-第三部分:性能监控与实战优化(1)-spark ui
Spark UI 概述
Spark UI 是 Spark 提供的 Web 监控界面,用于实时查看应用程序的执行状态、性能指标和资源配置。
各模块详细解析
1. Jobs 页面
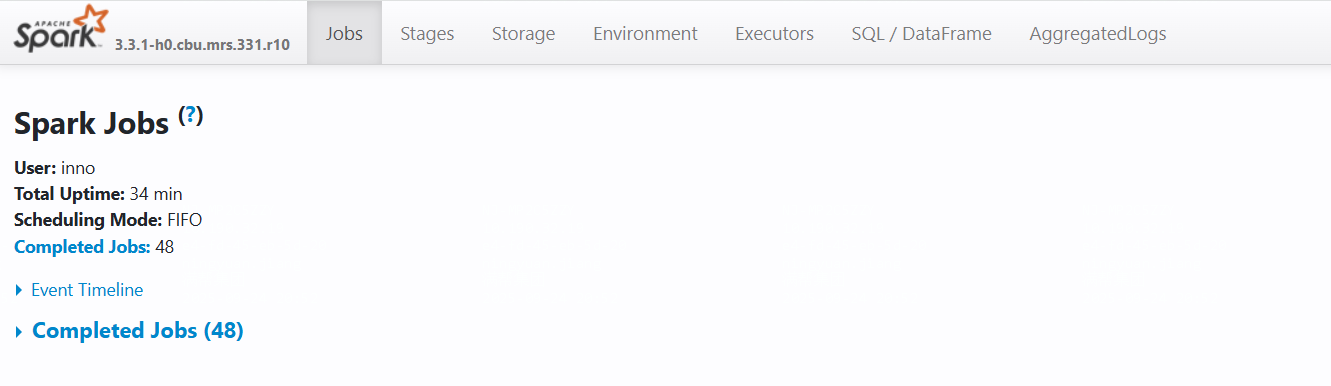
核心信息区域
**User:** inno # 提交作业的用户
**Total Uptime:** 34 min # 应用总运行时间
**Scheduling Mode:** FIFO # 调度模式(FIFO/FAIR)
**Completed Jobs:** 48 # 已完成的作业数量
主要功能区域
- Event Timeline:作业执行时间线可视化
- Completed Jobs:已完成作业列表,显示执行详情
2. SQL/DataFrame 页面
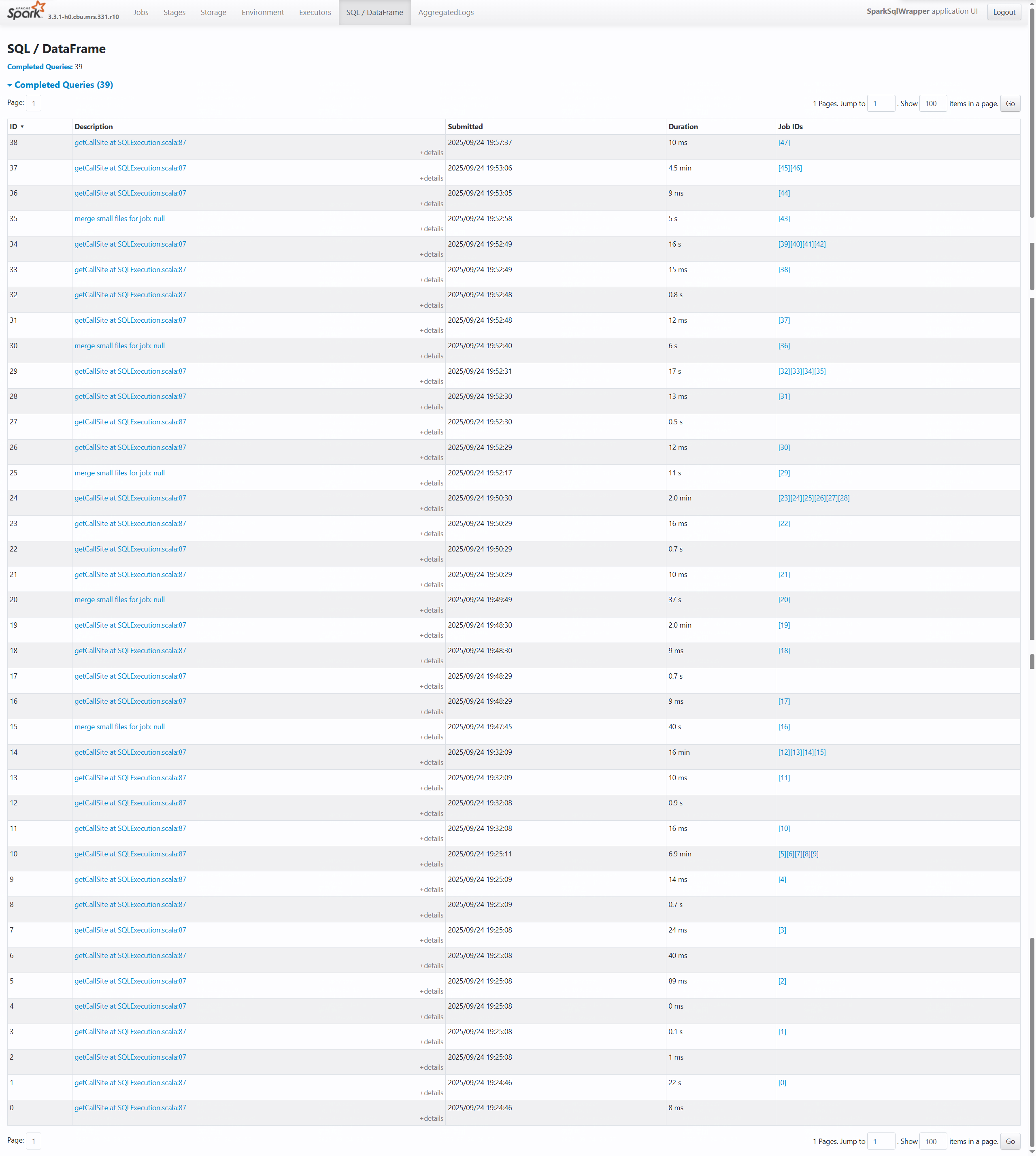
表格字段说明
-- 各列含义解析
ID * : SQL查询的唯一标识符
Description : 查询描述(通常显示触发查询的代码位置)
Submitted : 查询提交时间
Duration : 查询执行耗时
Job IDs : 关联的Spark Job ID列表
性能分析要点
- 查询38:执行仅10ms,属于高效查询
- 查询37:耗时4.5分钟,可能存在性能瓶颈
- 查询34:关联多个Job([39][48][41][42]),涉及复杂计算
3. Environment 页面
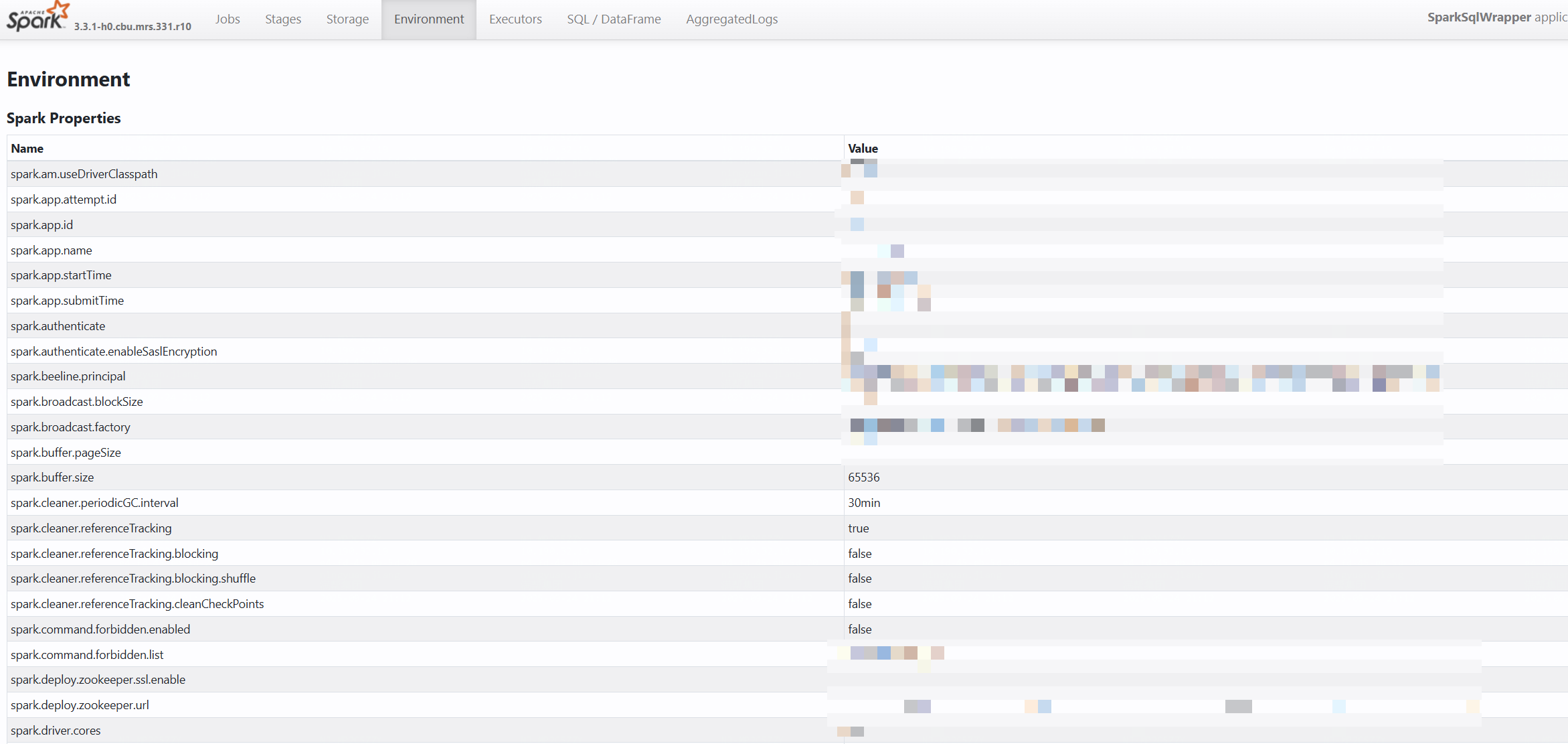
配置分类
Spark Properties : Spark核心配置参数
Runtime Information : 运行时环境信息
关键配置参数
# 内存相关配置
spark.buffer.pageSize = 65536 # 内存页大小
spark.broadcast.blockSize = 65536 # 广播变量块大小# 动态分配配置
spark.dynamicAllocation.enabled = true # 启用动态资源分配# 序列化配置
spark.serializer = ... # 序列化器设置
实际SQL执行案例解析
案例:用户行为分析查询
-- 实际执行的Spark SQL
SELECT user_id,COUNT(*) as action_count,AVG(duration) as avg_duration
FROM user_actions
WHERE event_date = '2025-09-04'AND action_type IN ('click', 'view')
GROUP BY user_id
HAVING COUNT(*) > 10
ORDER BY action_count DESC
LIMIT 100;
在Spark UI中的对应显示
性能优化洞察
-
查询37耗时分析:
- 4.5分钟执行时间表明可能存在数据倾斜
- 关联Job[48][46]需要进一步分析Stage详情
-
配置优化建议:
# 针对大数据集的优化配置 spark.conf.set("spark.sql.adaptive.enabled", "true") # 启用自适应查询 spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true") # 自动合并分区 spark.conf.set("spark.sql.adaptive.skew.enabled", "true") # 处理数据倾斜
这一篇主要是对spark ui的界面熟悉一下,后面会举出实际的案例进行性能优化