数据标注、Label Studio
概述
图像或视频标注是ML和计算机视觉任务中数据预处理中最耗时和劳动密集型的步骤之一,也叫数据标记。本文汇总一些开源项目或平台,注:仅对部分产品做简单使用和调研。
Label Studio
Label Studio是一个开源(24.5K Star,3K Fork)的数据标注和数据管理平台,由Human Signal开发并维护。提供多模态数据支持(文本、图像、音频、视频等)、丰富的可视化界面、内置多种模板并支持自定义标注模板的能力,灵活、高效且适用于多种领域和场景的数据标注平台,能够降低标注门槛,提高标注效率和准确性。
从文本三元组关系抽提到视频对象追踪,从低资源语言的语音标注到医学影像的像素级分割,Label Studio通过统一的交互界面打破传统标注工具的场景局限。
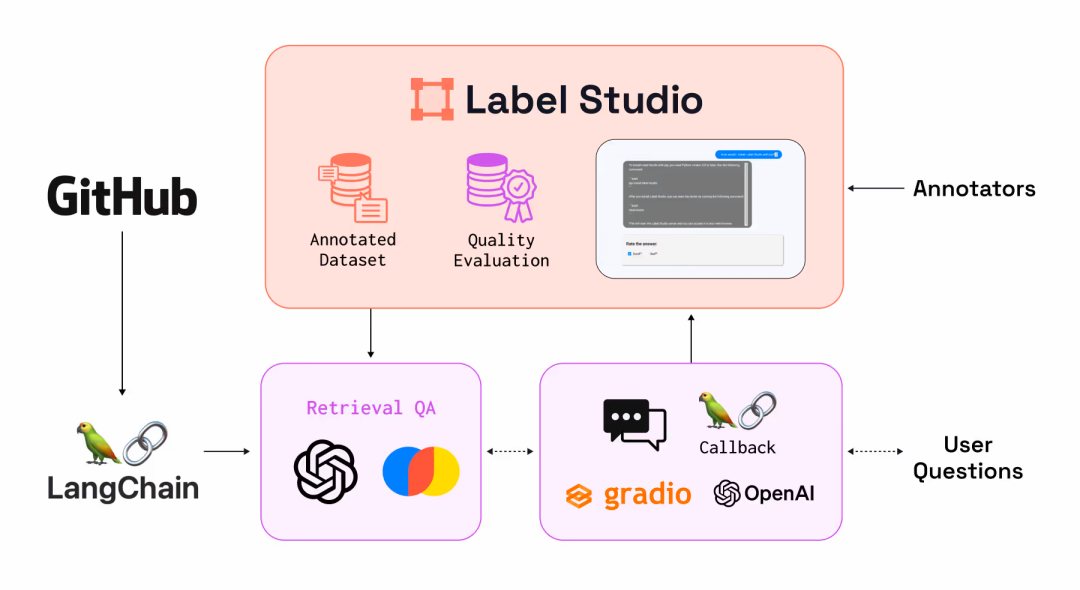
支持多种标注任务:
- 图片
- 图像分类:根据图像的语义信息将不同类别的图像区分开来。这是计算机视觉中的基本任务,也是其他高层视觉任务(如图像检测、图像分割等)的基础。
- 物体检测:检测图像上的物体,并使用框(边界框)、多边形、圆形或关键点等形状进行标注。这有助于机器学习模型学习如何识别图像中的特定物体及其位置。
- 语义分割:将图像分割成多个具有特定语义含义的片段。这需要对图像中的每个像素进行分类,实现像素级别的分类和标注。
- 语音:
- 音频分类:将音频文件根据其内容或特征进行分类。适用于多种场景,如音乐分类(摇滚、爵士、古典等)、环境声音识别(街道噪音、雨声、鸟鸣等)等。
- 说话人分类:根据说话者的身份或特征将音频流划分为同质片段。可用于语音识别、会议记录、电话客服等场景。
- 情绪识别:从音频中标记并识别情绪,如高兴、悲伤、愤怒、平静等。这对于情感分析、心理研究、客户服务等领域具有重要意义。
- 音频转录:将口头交流用文字记录下来的过程。可与语音识别系统(如NVIDIA NeMo)集成,实现自动或半自动的音频转录功能。
- 文本:
- 文档分类:上传待分类的文档,并定义分类标签。可根据文档内容将其归类到相应的类别中。
- 命名实体识别:NER,定义需要识别的实体类型(如人名、地名等)。标注者随后会在文本中标注出这些实体,并将其归类到相应的类别中。
- 问答系统:创建问答标注项目,并上传包含问题、答案的文本数据。标注者将问题与答案进行关联,以生成训练数据。
- 情绪分析:创建情绪分析项目,并定义情绪标签(如正面、负面、中性)。标注者随后会阅读文本内容,并根据其表达的情绪倾向进行标注。
- 时间序列
- 时间序列分类:将时间序列数据转换为表格形式,其中每一行代表一个时间点,每一列代表不同的特征(如时间序列中的值、时间戳等),为每个时间序列样本分配类别标签。
- 分割时间序列:使用Python等编程语言进行时间序列的分割,并将分割结果(如分割点的索引或时间戳)作为标签导入Label-Studio进行验证或进一步处理。
- 事件识别:使用矩形或多边形标签来标记图表上的事件区域。这通常适用于那些可以通过视觉识别的事件,如峰值、谷值或突然的变化。
- 视频
- 视频分类:上传视频并定义分类标签,标注者根据视频内容选择相应标签进行分类。
- 对象追踪:设置视频对象追踪项目,上传视频并配置追踪工具,标注者逐帧或关键帧标记对象位置,实现对象在视频中的追踪。
- 辅助标注:标注者选择视频中的关键帧并精确标注对象位置,可选地结合外部工具进行自动插值以估算非关键帧的对象位置。
LabelImg
GitHub,24.2K Star,6.5K Fork。已于2024年3月1日归档,停止维护,合并到Label Studio社区。
Labelme
官网,GitHub,14.9K Star,3.6K Fork,基于Python+Qt。
功能:
- 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注,可用于目标检测,图像分割等任务;
- 对图像进行Flag形式的标注,可用于图像分类和清理任务;
- 视频标注,生成VOC格式的数据集,用于语义、实例分割;
- 生成COCO格式的数据集,用于实例分割。
安装:
# 会自动安装pyqt5
pip install labelme
# 打开GUI
labelme
遇到问题: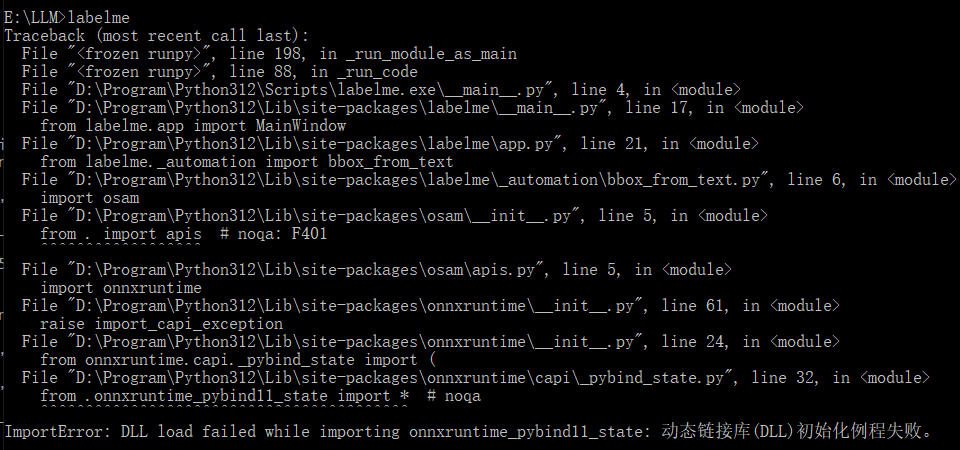
搞虚拟环境?在前面命令前追加如下命令:
mkdir labelme
cd labelme
python -m venv myenv
myenv\Scripts\activate
结果还是同样的报错。
根因分析:版本兼容问题。这特么比Java恶心,Java版本不兼容会给出很明确的关键词。
解决方法:
pip uninstall -y onnxruntime
# Found existing installation: onnxruntime 1.23.0
# 故意写个不存在的版本,得到所有版本号
pip install onnxruntime==1.15.1
ERROR: Could not find a version that satisfies the requirement onnxruntime==1.15.1 (from versions: 1.17.0,..., 1.23.0)
# 可能需要多次尝试
pip install onnxruntime==1.20.1
界面:
编辑菜单:
视图菜单
支持的(掩码)模型列表:
- EfficientSam
- SegmentAnything
- Sam2
几个调整参数

看看日志(有省略):
labelme.config:get_config:66 - Loading config file from: C:\Users\johnny\.labelmerc
labelme.widgets.canvas:set_ai_model_name:140 - Setting AI model to 'sam2:latest'
labelme._automation.bbox_from_text:get_bboxes_from_texts:23 - Requesting with model='yoloworld', image=((391, 391, 3), dtype('uint8')), prompt=Prompt(points=None, point_labels=None, texts=[''], iou_threshold=1.0, score_threshold=0.01, max_annotations=1000)
osam.types._model:__init__:23 - Initializing model yoloworld:latest
labelme.__main__:write:25 - Cached downloading...Hash: sha256:
From:
https://clip-as-service.s3.us-east-2.amazonaws.com/models/onnx/ViT-B-32/textual.onnx
To: C:\Users\johnny/.cache/osam/models/blobs/sha256:
Cached downloading...Hash: sha256:
From:
https://github.com/wkentaro/yolo-world-onnx/releases/download/v0.1.0/yolo_world_v2_xl_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.onnx
To: C:\Users\johnny/.cache/osam/models/blobs/sha256:
osam.types._model:__init__:57 - Initialized inference sessions with providers ['CPUExecutionProvider']
解读:不管是从AWS S3还是GitHub下载模型文件,都需要有稳定代理,否则体验较差。
除了GUI,还可使用命令行:
labelme --help
usage: labelme [-h] [--version] [--reset-config] [--logger-level {debug,info,warning,fatal,error}] [--output OUTPUT] [--config CONFIG] [--nodata] [--autosave][--nosortlabels] [--flags FLAGS] [--labelflags LABEL_FLAGS] [--labels LABELS] [--validatelabel {exact}] [--keep-prev] [--epsilon EPSILON][filename]positional arguments:filename image or label filenameoptions:-h, --help show this help message and exit--version, -V show version--reset-config reset qt config--logger-level {debug,info,warning,fatal,error}logger level--output OUTPUT, -O OUTPUT, -o OUTPUToutput file or directory (if it ends with .json it is recognized as file, else as directory)--config CONFIG config file or yaml-format string (default: C:\Users\johnny\.labelmerc)--nodata stop storing image data to JSON file--autosave auto save--nosortlabels stop sorting labels--flags FLAGS comma separated list of flags OR file containing flags--labelflags LABEL_FLAGSyaml string of label specific flags OR file containing json string of label specific flags (ex. {person-\d+: [male, tall], dog-\d+: [black, brown,white], .*: [occluded]})--labels LABELS comma separated list of labels OR file containing labels--validatelabel {exact}label validation types--keep-prev keep annotation of previous frame--epsilon EPSILON epsilon to find nearest vertex on canvas
参数解读:
--output:标注文件存放位置--flags:为图像创建分类标签,多分类用逗号隔开--nosortlabels:是否对标签进行排序--config:指定配置文件,未指定则使用用户目录下.labelmerc配置文件
示例:
# 自动标注男生和女生,并导出为JSON文件
labelme 1.png --output 1.json --flags boy, girl
CVAT
Computer Vision Annotation Tool的缩写,官网,GitHub,14.3K Star,3.3K Fork。
X-AnyLabeling
一款基于Labelme和Anylabeling深度优化的增强版开源(6.4K Star,701 Fork)标注工具,擅长处理图像/视频标注,能提升标注效率,通过自动化标注降低成本。
专为应对LLM时代的自动化数据标注挑战而生,无缝集成多种深度学习算法(如Grounding-DINO、Grounding-SAM),开箱即用,支持图像、视频、文本等多模态数据,支持目标检测、图像分割、语义分割、OCR、姿态估计等多场景。
优势:
- 内置SOTA模型(如YOLO、RT-DETR、DETR、SAM)实现零样本标注,减少人工重复劳动;
- 支持Windows、Linux、MacOS系统一键部署,CPU/GPU双硬件加速,适配有限硬件资源,适应不同场景需求;
- 界面简洁直观,操作与主流工具(如LabelImg、CVAT)对齐,方便快速上手;
- 支持导出COCO JSON、YOLO TXT、Pascal VOC等格式数据,可直接输入大模型进行微调,形成
标注-训练-优化闭环;
部署
pip install numpy opencv-python matplotlib
git clone https://github.com/CVHub520/X-AnyLabeling.git
cd X-AnyLabeling
pip install -r requirements.txt
python main.py
读取COCO格式:
import json
def load_coco_annotations(file_path):with open(file_path, 'r') as f:coco_data = json.load(f)images = coco_data['images']annotations = coco_data['annotations']return images, annotations
使用技巧:
- 内置标注结果统计(如标注框数量、类别分布)→支持导出审核报告;
- 小目标筛查:启用循环遍历子图功能,避免遗漏小尺寸目标。
Make Sense
GitHub,3.4K Star,571 Fork,提供本地私有化部署选项。也可选择SaaS平台官网,无需注册即可使用。
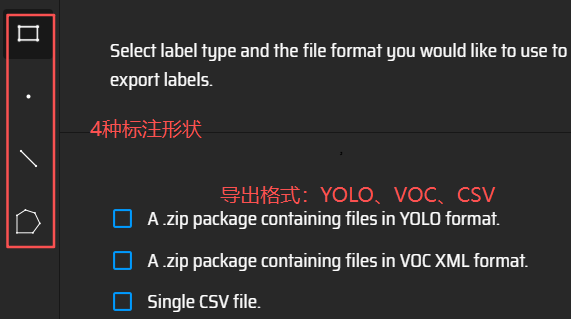
开始→上传文件(可单个也可批量),单击左侧要标注的图像。从矩形、点、线和多边形中选择标注形状。一般来说,YOLO格式的标注文件使用矩形包围框。右侧
有3个按钮:
如果没有选择标签,则导出的zip文件夹为空!!所有文件一一标注好之后,点击动作:
选择导出
快捷键
AnyLabeling
GitHub,2.8K Star,278 Fork。
PixelAnnotationTool
GitHub,1.4K Star,311 Fork。
VIA
VGG Image Annotator,VGG图像注释器,项目主页。VGG,Visual
Geometry Group缩写,官网。
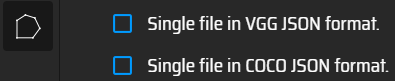
一款开源(GitLab,170 Star)的图像标注工具,由牛津大学计算机视觉组 Visual Geometry Group开发。可在线和离线使用,可标注矩形、圆、椭圆、多边形、点和线,标注完成后,可导出为CSV和JSON格式。
从项目主页下载得到via-3.0.13.zip,解压缩:
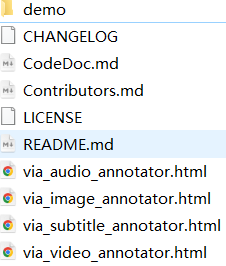
不知道怎么标注?打开demo文件夹,有示例:
以图像为例,双击via_image_annotator.html,浏览器打开
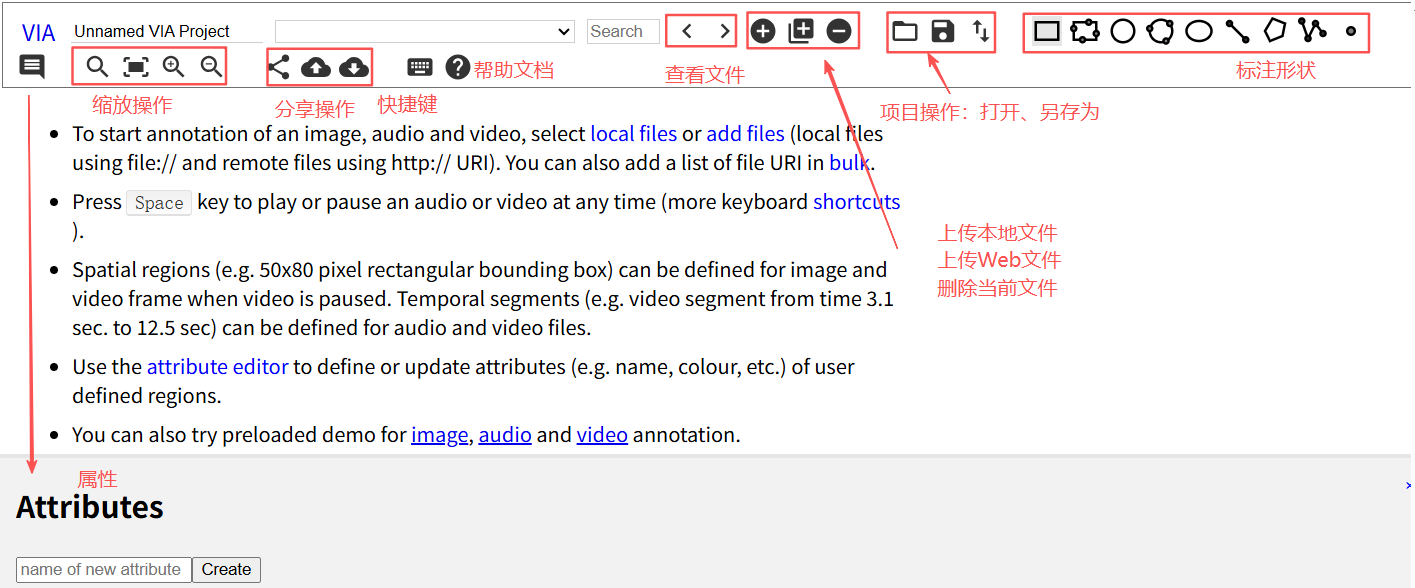
虽然打开的是via_image_annotator.html文件,用于标注图像,也支持上传音频文件,没有限制文件后缀名,不过对音频文件做形状标注也没有什么意义。
导出文件:
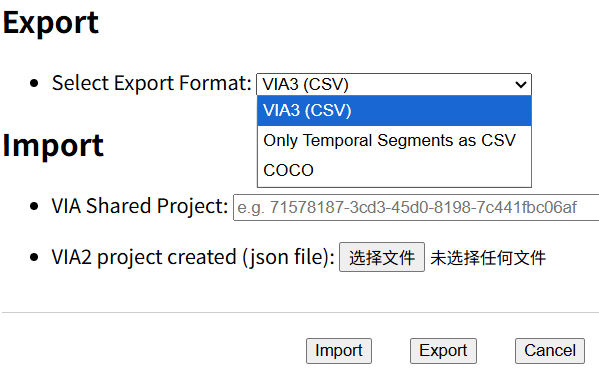
其他
COCO
Common Objects in COntext缩写。
参考
- COCO数据集的标注格式