Flink 架构组件、任务链路、Slot 资源与集群形态
1. 为什么先懂架构再写代码?
Flink 是分布式流处理系统。相同的作业,因资源管理、任务并行度、Slot 配置不同,性能差异可能是数量级的。理解运行时架构,能帮助你:
- 以更少机器跑出更高吞吐;
- 正确地做弹性伸缩与故障恢复;
- 在 Kubernetes / YARN / Standalone 等环境下平滑部署。
2. 组件与职责速览
2.1 三类进程/角色
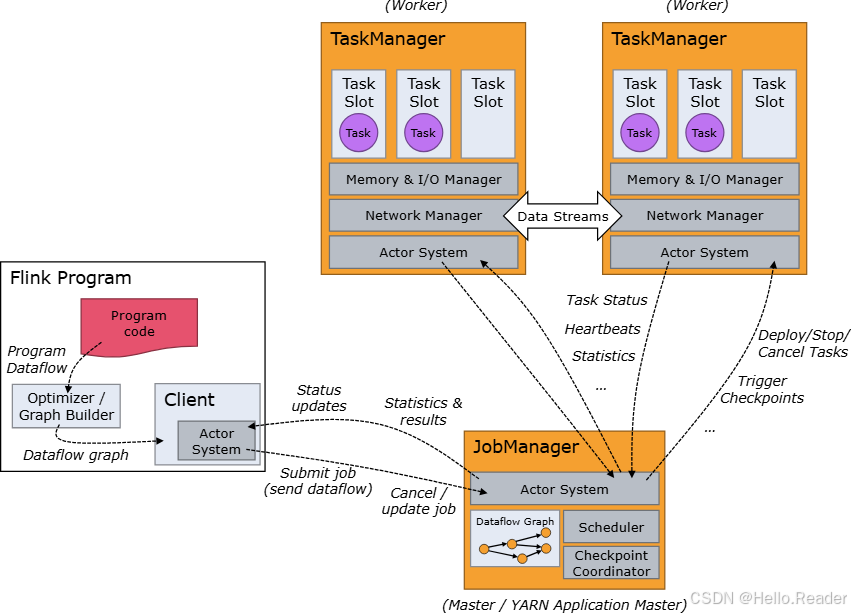
-
Client(客户端):负责编译、构建 JobGraph 并提交到集群。可 attached(持续拿进度)或 detached(提交后即断开)。
-
JobManager:调度与协调的大脑,包含三个子组件:
- ResourceManager(RM):Slot 的供给与分配。对接 YARN/K8s/Standalone 资源提供者;Standalone 只能分配已有 TM,不能主动拉起 TM。
- Dispatcher:REST 提交入口,为每个作业启动一个 JobMaster;同时承载 Web UI。
- JobMaster(JM):单个作业的执行控制器(一个作业一个 JM)。
-
TaskManager(TM):Worker 进程,执行算子子任务,负责数据缓冲与网络交换。每个 TM 持有若干 Task Slot。
2.2 HA(高可用)要点
- 集群可配置多台 JobManager;始终一主多备。
- 故障恢复依赖 Checkpoint/Savepoint + JM 切主 + TM 重连。
3. 任务是怎么“跑起来”的?
3.1 Operator Chain(算子链)
Flink 会把可链式的相邻算子合并到同一 Task 中,由一个线程执行,减少线程切换和缓冲开销,提升吞吐并降低延迟。链化行为可配置(禁止/强制/自动)。
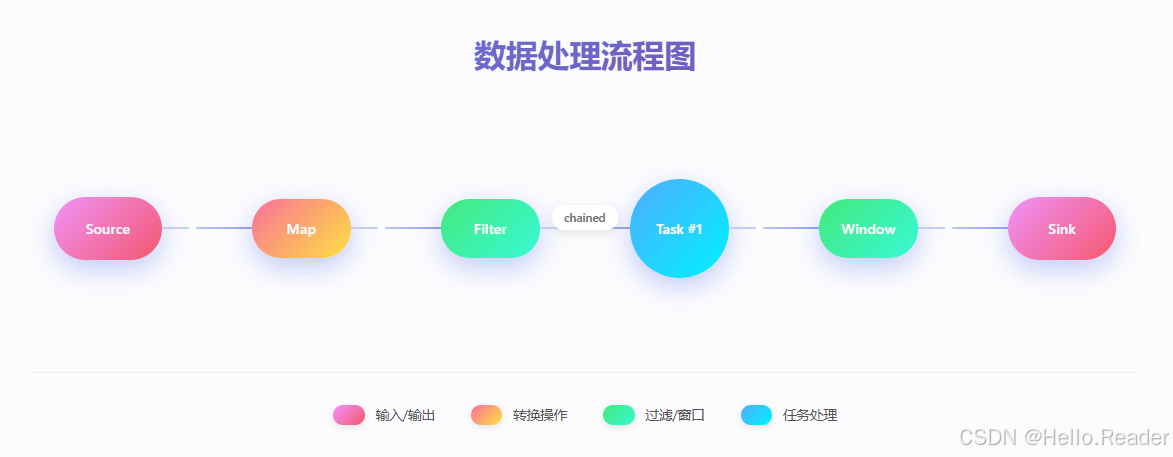
上图中 Source→Map→Filter 被链成一个 Task(同线程),Window 由于需要分区/对齐,被放在下一个 Task。
3.2 并行度与 Subtask
每个算子根据 parallelism 拆成多个 subtask;链化后,一个 Task 内含多个 subtasks 的片段。Flink 会把这些任务分配到不同 Task Slot 上执行。
4. Task Slot:Flink 的资源刻度
- TaskManager = 1 个 JVM 进程;内部包含
N个 Task Slot。 - 一个 Slot = TM 资源(受管内存)的固定份额。Slot 默认只隔离受管内存,不做 CPU 隔离。
- Slot Sharing(默认开启):同一作业内不同算子的 subtasks 可以共享同一 Slot → 一个 Slot 能承载整条流水线,提升资源利用率。
工程意义:
- 需要的 Slot 总数 ≈ 作业最高并行度(有 slot sharing 时的经验法则)。
- 同一 JVM 内的任务可共享 TCP 连接与心跳、复用数据结构,降低开销。
- 若关心强隔离(比如垃圾回收、类加载冲突),可设置每 TM 只开 1 个 Slot,等价于“每 JVM 一个 Slot”。
常见配置(flink-conf.yaml):
taskmanager.numberOfTaskSlots: 4
# 受管内存、网络缓冲等也应配套调优
taskmanager.memory.process.size: 4096m
taskmanager.memory.managed.size: 1024m
5. 提交流程与集群形态
5.1 Flink Application(用户程序)
你的 main() 通过 ExecutionEnvironment 构建作业图并提交执行:
- LocalEnvironment:本地 JVM 调试;
- RemoteEnvironment:远程集群(K8s/YARN/Standalone)。
5.2 Session Cluster vs Application Cluster
| 维度 | Session Cluster | Application Cluster |
|---|---|---|
| 生命周期 | 预先存在、长时间运行;可接收多作业 | 专属于单应用;main() 在集群端运行;集群生命周期与应用绑定 |
| 资源隔离 | 作业共享 RM/TM 资源;一个 TM 挂掉会影响其上运行的多个作业 | RM/Dispatcher 仅服务该应用,隔离性更好 |
| 启动/提交 | 先起集群 → 再多次提交作业 | 一步式:打包 JAR 即部署,入口调用 main() 生成 JobGraph |
| 适用场景 | 交互式/短作业频繁提交;起集群成本要低 | 云原生应用、版本独立、强隔离、易运维(K8s 推荐) |
快速选型
- 多租户/交互式查询:Session Cluster
- 生产应用/一应用一集群:Application Cluster(K8s 原生)
6. 典型部署食谱
6.1 Kubernetes(推荐)
-
Session Cluster(先起集群,再
flink run):- 优点:作业冷启动快;对多短作业友好
- 缺点:多作业资源竞争,隔离弱
-
Application Cluster(一应用一集群):
- 优点:隔离强、部署/升级流程清晰;观测面简单
- 缺点:每应用一套 RM/JM,集群数量多时需平台化运维
K8s 关键点:
- 使用 Native K8s 模式(
kubernetes-session/kubernetes-applicationentrypoint) - 配置 HA(K8s StatefulSet + HA 存储,如 ZK/Consul 或 K8s HA 控制面)
- Pod 资源与
taskmanager.numberOfTaskSlots同步规划(CPU/Memory Request & Limit)
6.2 YARN
- Session 模式:
yarn-session.sh起集群,flink run -m yarn-session提交 - Per-Job(已逐步被 Application Cluster 取代):每作业单独集群,关闭后释放资源
6.3 Standalone
- 手工拉起 JM/TM;适合离线环境或嵌入式场景。RM 只能分配已有 TM 的 Slot,不能自动扩容。
7. 性能与稳定性:实战调优清单
7.1 并行度与 Slot
- 估算最高并行度 = 关键算子瓶颈并行度;集群 Slot 总数 ≥ 最高并行度
- 充分利用 Slot Sharing;若需隔离,减少 sharing 或设置每 TM 1 Slot
- 热点 Key 倾斜 → 预分区/加盐 或 two-phase 聚合
7.2 网络与内存
taskmanager.memory.*与taskmanager.numberOfTaskSlots协同规划- 调整 network buffers(批量/吞吐/反压敏感)
- 大状态优先 RocksDB + 增量 Checkpoint;合理设置 State TTL
7.3 调度与可靠性
- 合理设置 checkpoint interval / timeout / max concurrent
- Kafka Source 开启 exactly-once(两阶段提交/事务)
- Restart Strategy:固定延时、失败率、或由平台托管的重启策略
- HA:多 JM + 持久化元数据存储(ZK/文件系统)
7.4 可观测与告警
- 关键指标:BackPressure、Checkpoint Duration/Alignment、Busy Time、Watermark Lag、State Size、Full GC
- Web UI + 日志 + 外部监控(Prometheus/Grafana)
8. 常见坑与排查
-
并行度够、吞吐仍低
- 算子未链化(operator chaining 被禁用或断链)
- Slot 与资源规划不匹配(CPU/Memory 争用)
- 下游 Sink 阻塞 → 观察 BackPressure
-
窗口迟迟不触发
- 上游某分支无水位线(source idle)→ 开启
withIdleness - 多输入合并取最小水位 → 排查最慢支路
- 上游某分支无水位线(source idle)→ 开启
-
一个 TM 掉,多个作业跟着挂(Session)
- 这是共享集群的限制;关键作业迁移至 Application Cluster 或提升 TM 稳定性
-
内存溢出/频繁 Full GC
- Slot 数过多导致 JVM 压力大;RocksDB 内存与堆外未限制
- 增大进程内存、限制 RocksDB write buffer/Block cache、优化序列化
9. 最小可用的配置骨架
flink-conf.yaml(示例)
# 并行度与 Slot
parallelism.default: 4
taskmanager.numberOfTaskSlots: 4# 内存(示意值,需压测后定)
taskmanager.memory.process.size: 4096m
taskmanager.memory.managed.size: 1024m# Checkpoint
execution.checkpointing.interval: 10000
execution.checkpointing.timeout: 60000
execution.checkpointing.max-concurrent-checkpoints: 1
state.checkpoints.dir: s3://flink/ckpt
state.savepoints.dir: s3://flink/savepoints# HA(示例,按环境配置)
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
K8s Application Cluster 启动(示意)
# 打包后直接以 application 模式提交
flink run-application \-t kubernetes-application \-Dkubernetes.cluster-id=my-app \-Dkubernetes.namespace=streaming \-Dkubernetes.taskmanager.cpu=1 \-Dtaskmanager.numberOfTaskSlots=1 \local:///opt/flink/usrlib/job.jar
10. 结语:把抽象变成生产力
- JobManager(RM/Dispatcher/JM) 负责调度协调,TaskManager 提供执行和数据交换;
- Operator Chain 让任务更“紧凑”,Task Slot 决定资源刻度与并行承载;
- Session Cluster 适合交互式与多租户,Application Cluster 适合强隔离的生产应用;
- 生产稳定依赖于:合理的 Slot & 内存规划 + Checkpoint/HA + 观测告警。
从今天起,先画清你的算子链与并行度,规划Slot 与内存,再选对集群形态。你会明显感受到:同样的代码,在正确的架构下跑得又快又稳。