南洋理工大学与Netflix Eyeline Studios梦幻联动:CineScale给视觉扩散模型8K图像、4K视频电影级高清生成来场“免费革命”!
南洋理工大学S-Lab与Netflix Eyeline Studios研究者合作,提出全新推理范式CineScale,以解决视觉扩散模型生成高分辨率图像和视频的核心难题。受训练数据和计算资源限制,多数开源扩散模型在低分辨率训练,生成高分辨率内容时问题频出。CineScale通过无需或极少量微调的推理技巧,释放预训练模型潜力,实现无需微调生成8K图像、极少量LoRA微调生成4K视频,还将高分辨率生成能力从文生图、文生视频扩展到更具挑战的图生视频和视频生视频任务,拓宽了应用场景。

结果展示
文本转视频 (960 × 1664)
虽然所有变体都会产生粗略的结果,CineScale效果最佳。

文本到视频比较(960 × 1664)
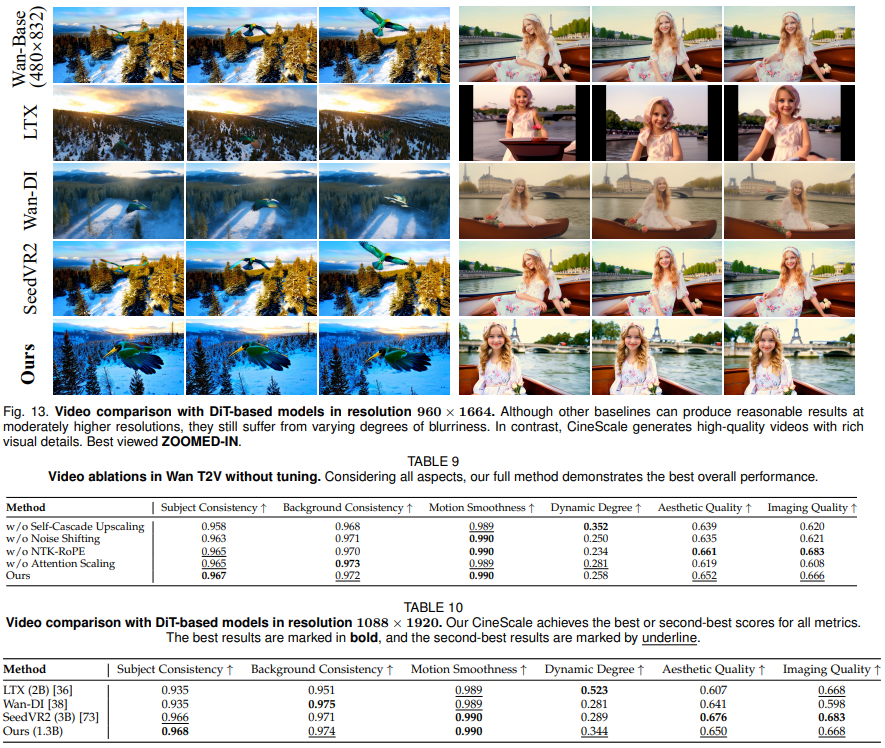
虽然其他基线在略高的分辨率下也能产生不错的效果,但仍然存在不同程度的模糊问题。相比之下,CineScale 可以生成具有丰富视觉细节的高质量视频。

文本到视频比较(1920 × 3328)
与其他基线进行图像定性比较。在比训练时使用的分辨率高出数倍的分辨率下,LTX 和 Wan-DI 往往会完全失败。虽然视频超分辨率方法 UAV 仍然可以产生视觉上合理的结果,但它无法恢复低分辨率输入中模糊或缺失的精细细节。相比之下,CineScale 始终能够生成具有丰富而忠实的视觉细节的高质量视频。

图像到视频烧蚀(960 × 1664)
虽然所有变体都会产生粗略的结果,CineScale方法效果最佳。

图像到视频生成(2176 × 3840)
通过最少的 LoRA 微调,CineScale 可以实现 4k 图像到视频的生成。

ReCamMaster 视频到视频烧蚀 (960 × 1664)
如果没有 NTK-RoPE,由于位置编码错误,很容易出现重复模式。虽然所有变体都会产生粗糙的结果,但我们的完整方法表现最佳。

局部语义编辑(2176 × 3840)
CineScale 支持高效编辑,允许用户以低分辨率预览结果,同时通过提示修改高分辨率局部语义。

相关链接
论文:https://arxiv.org/abs/2508.15774
项目:https://eyeline-labs.github.io/CineScale
代码:https://github.com/Eyeline-Labs/CineScale
论文介绍

标题: CineScale:高分辨率电影视觉生成中的免费午餐
作者: Haonan Qiu, Ning Yu, Ziqi Huang, Paul Debevec, Ziwei Liu
机构: 南洋理工大学、Netflix Eyeline Studios
视觉扩散模型取得了显著进展,然而由于缺乏高分辨率数据和计算资源受限,这些模型通常在有限的分辨率下进行训练,从而限制了它们生成高分辨率高保真图像或视频的能力。近期研究探索了无需调整的策略,以展示预训练模型尚未开发的高分辨率视觉生成潜力。然而,这些方法仍然容易生成具有重复模式的低质量视觉内容。关键障碍在于,当模型生成的视觉内容超过其训练分辨率时,高频信息不可避免地会增加,从而导致由累积误差衍生出不良的重复模式。在这项工作中,我们提出了CineScale,一种新颖的推理范式,可实现高分辨率视觉生成。为了解决两种视频生成架构引入的各种问题,我们针对每种架构提出了专门的变体。与现有仅限于高分辨率 T2I 和 T2V 生成的基线方法不同,CineScale 扩展了生成范围,支持高分辨率 I2V 和 V2V 合成,并构建于最先进的开源视频生成框架之上。大量实验验证了我们范式在扩展图像和视频模型的高分辨率视觉生成能力方面的卓越性。值得注意的是,我们的方法无需任何微调即可生成8k图像,仅需少量 LoRA 微调即可生成4k视频。
方法概述
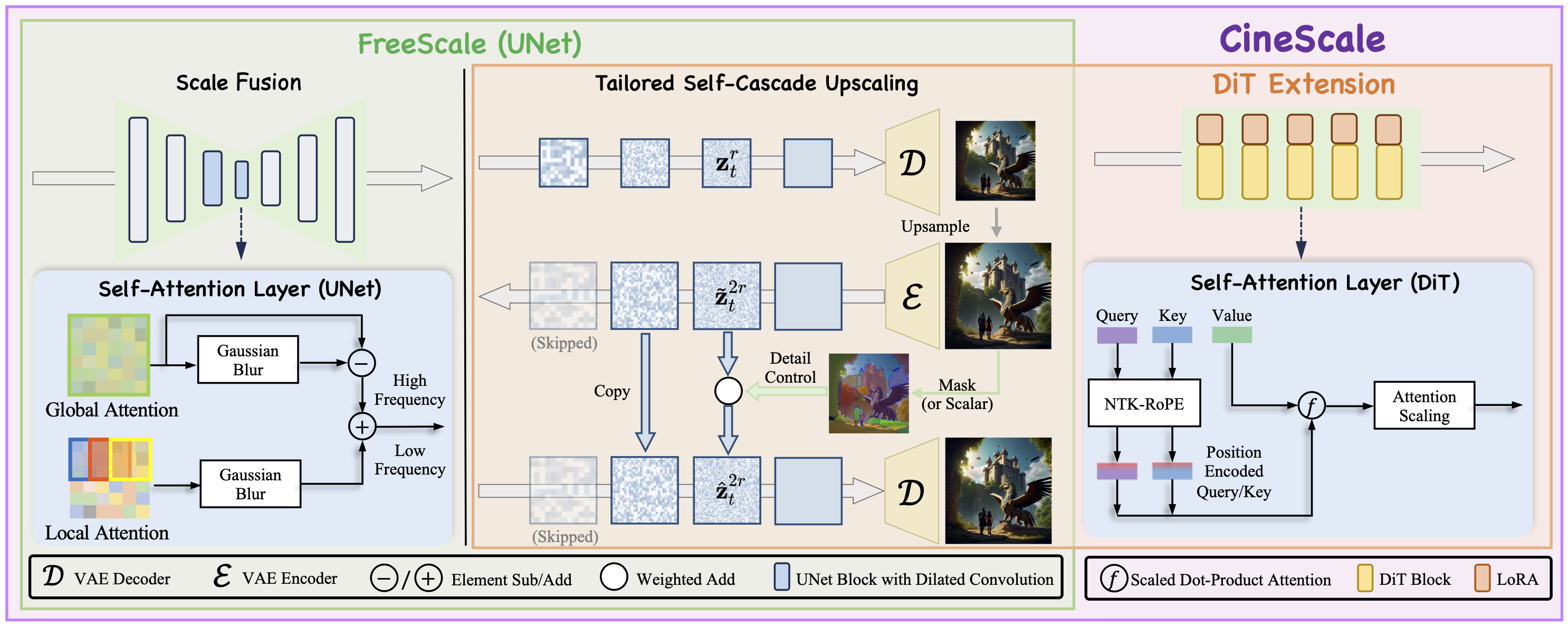
CineScale 的整体框架。 (a)定制自级联上采样。CineScale 首先从训练分辨率对生成的图像或视频进行上采样,然后逐渐向高分辨率潜在层添加噪声,最后对其进行去噪以实现细节重建。在去噪过程中,部分干净的潜在层被重新引入,以稳定生成并控制细节。(b)尺度融合。对于 UNet 结构,我们修改了自注意力层,使其结合全局注意力和局部注意力,通过高斯模糊将高频细节和低频语义融合到最终输出。我们还使用约束扩张卷积使模型的卷积层适应高分辨率,以减少重复。(c)DiT 扩展。为了支持 DiT 模型,我们额外添加了 NTK-RoPE 和注意力缩放。在无需调优的设置基础上,额外引入了最小 LoRA 微调,以帮助模型更好地适应修改后的 RoPE,从而提升性能。
实验结果

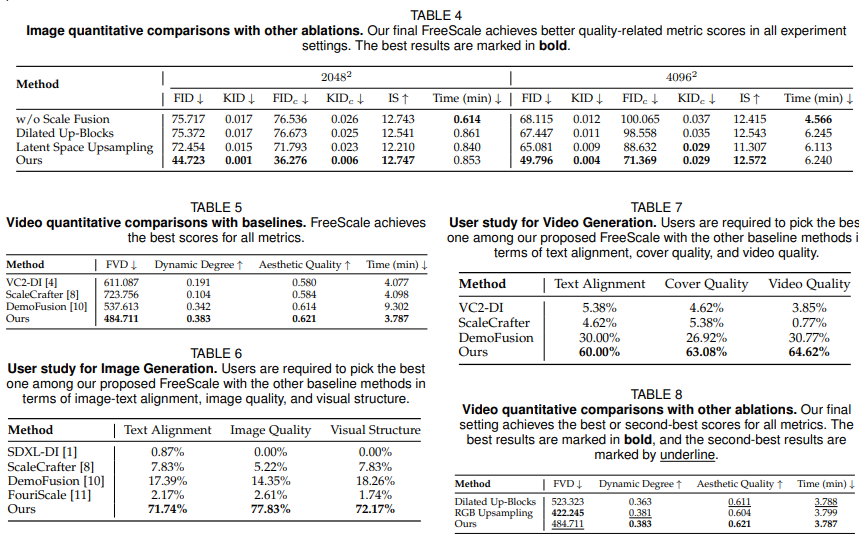
与其他基线方法的图像定性比较。论文的方法分别生成了 20482 和 40962 张生动图像,且具有更好的内容连贯性和局部细节。

放大 8k 图像的细节。FreeScale 可以根据模型学习到的先验知识,在低分辨率下重新生成原始模糊区域。如下一行所示,两张原本混乱模糊的脸在 8k 分辨率下清晰可见。
结论
论文介绍的 FreeScale 是一种旨在增强预训练扩散模型高分辨率生成能力的新型推理范式。通过利用多尺度融合和选择性频率提取,FreeScale 有效地解决了高分辨率生成中常见的问题,例如重复模式和质量下降。然后将 FreeScale 扩展为 CineScale,以支持基于 DiT 的视频扩散模型,并将任务范围从 T2V 扩展到 I2V 和 V2V。实验结果证明了 CineScale 在图像和视频生成方面的优势,其视觉质量超越了现有方法。额外的局部控制功能为用户提供了更大的灵活性。该方法仅需极少的 LoRA 微调即可实现 4k 视频生成。虽然 CineScale 展现出强大的能力,但生成超高分辨率内容仍然需要相当大的计算成本。未来的工作将专注于通过架构优化、去噪加速和模型压缩技术来提高推理效率,从而使高分辨率生成更加实用且易于实现。