【完整源码+数据集+部署教程】城市交通场景分割系统: yolov8-seg-C2f-MSBlock
背景意义
研究背景与意义
随着城市化进程的加快,城市交通管理面临着前所未有的挑战。交通拥堵、交通事故频发以及环境污染等问题日益严重,亟需通过智能化手段进行有效管理与优化。在此背景下,计算机视觉技术的迅猛发展为城市交通场景的分析与处理提供了新的可能性。尤其是目标检测与分割技术的进步,使得对复杂交通场景中各种交通参与者的实时识别与分类成为可能,从而为交通管理提供了重要的数据支持。
YOLO(You Only Look Once)系列模型因其高效的实时检测能力而广受关注,尤其是YOLOv8的推出,进一步提升了目标检测的精度与速度。然而,尽管YOLOv8在多种场景下表现出色,但在复杂的城市交通环境中,尤其是涉及到多个类别的实例分割任务时,仍然存在一定的局限性。因此,基于改进YOLOv8的城市交通场景分割系统的研究显得尤为重要。
本研究所使用的数据集“crosswalk-hq-medium”包含1500张图像,涵盖了13个类别,包括自行车、公交车、汽车、人行道、狗、消防栓、摩托车、停车计时器、行人、停车标志、街道标志、交通信号灯和卡车等。这些类别的多样性为模型的训练与评估提供了丰富的样本,有助于提升模型在实际应用中的适应性与鲁棒性。通过对这些类别的实例分割,研究能够更深入地理解城市交通场景中各类对象的空间分布与相互关系,为后续的交通管理决策提供科学依据。
此外,城市交通场景的复杂性使得传统的目标检测方法往往难以应对。在这种情况下,改进YOLOv8的实例分割能力,将有助于提升模型对交通参与者的识别精度和实时性。例如,在繁忙的交叉口,行人与车辆的交互关系复杂,准确的实例分割能够有效减少交通事故的发生概率,提升交通安全。同时,精准的交通参与者识别也为智能交通系统的实施提供了数据基础,促进了智能信号控制、交通流量预测等技术的发展。
综上所述,基于改进YOLOv8的城市交通场景分割系统的研究,不仅能够推动计算机视觉技术在交通管理领域的应用,也为解决当前城市交通问题提供了新的思路与方法。通过对交通场景的深入分析与理解,研究将为实现更高效的城市交通管理体系奠定基础,助力构建安全、便捷、环保的现代城市交通环境。
图片效果
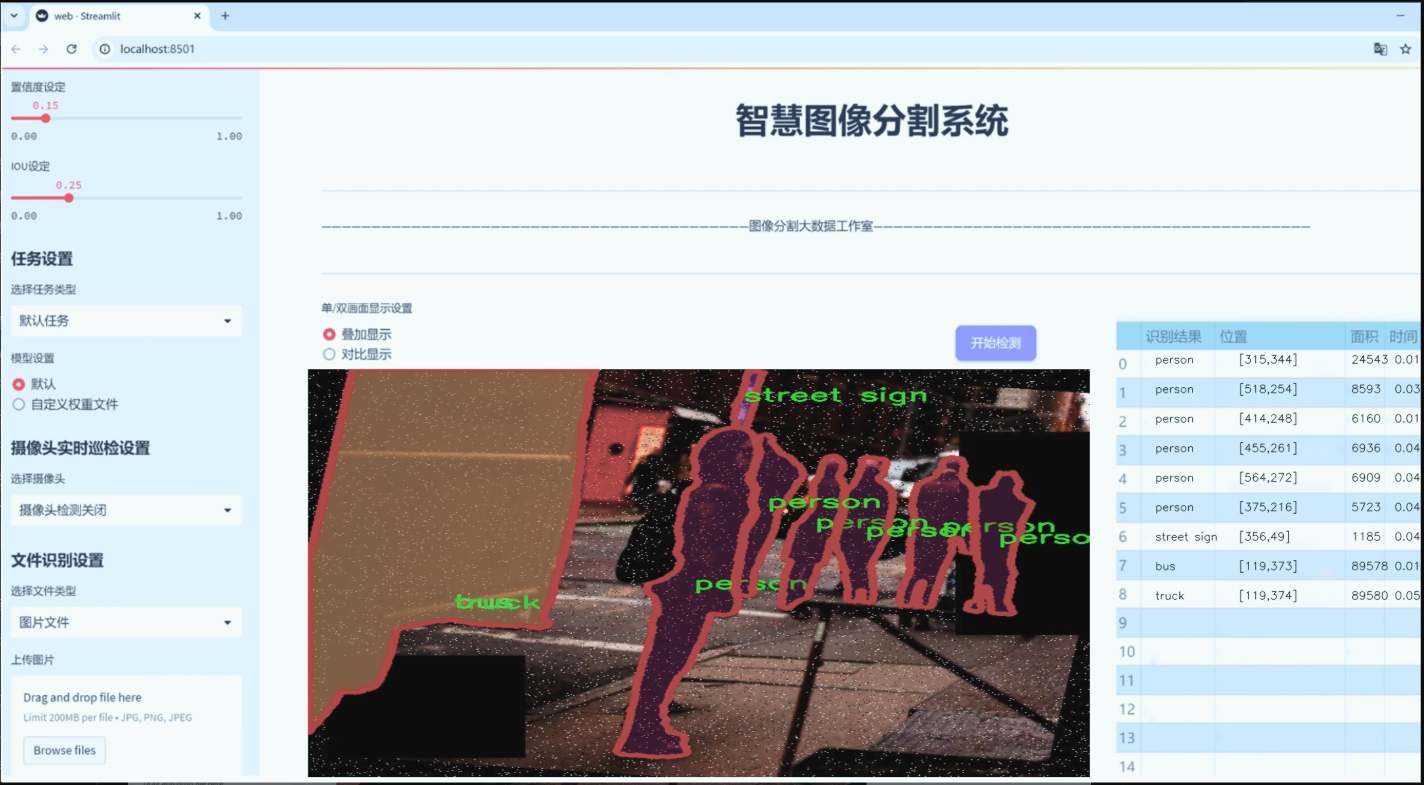
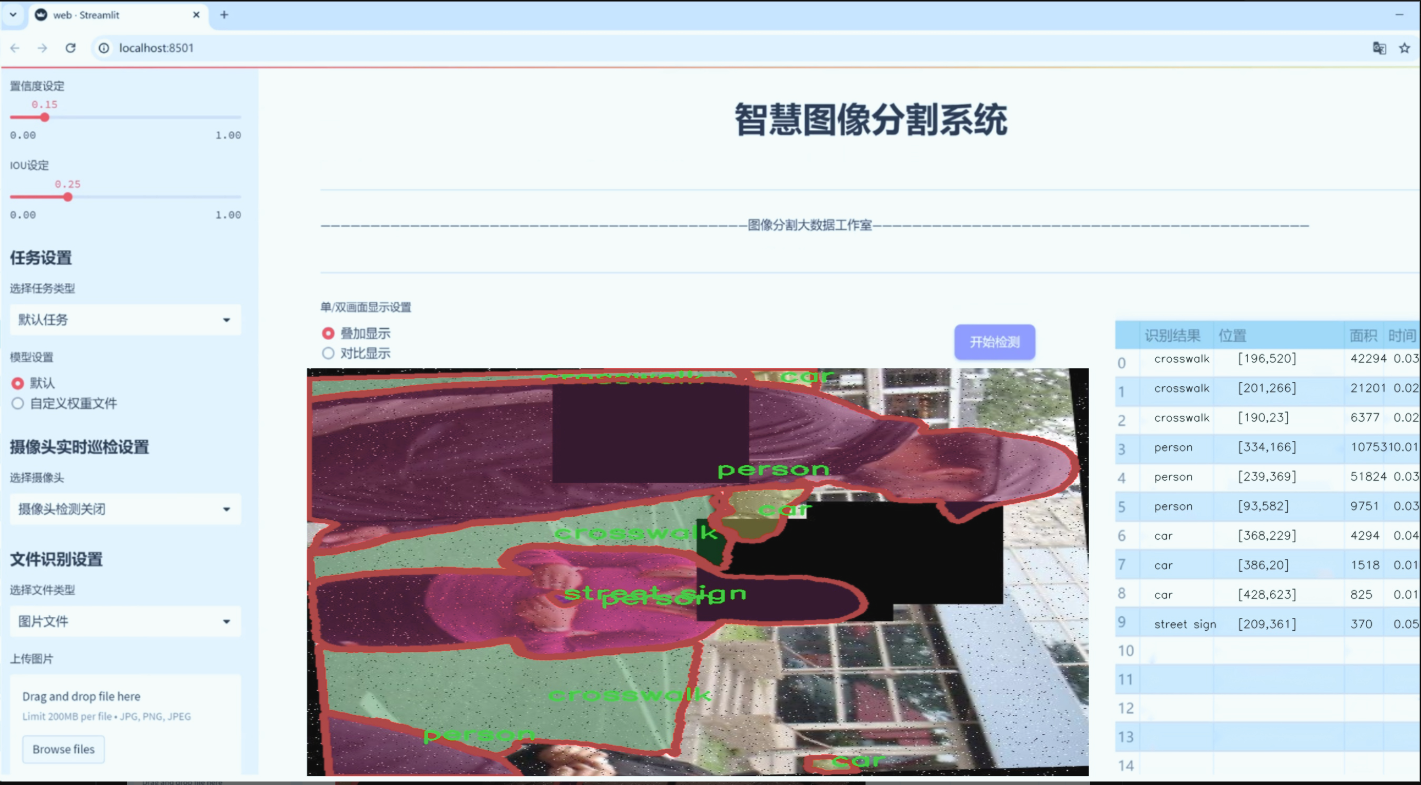
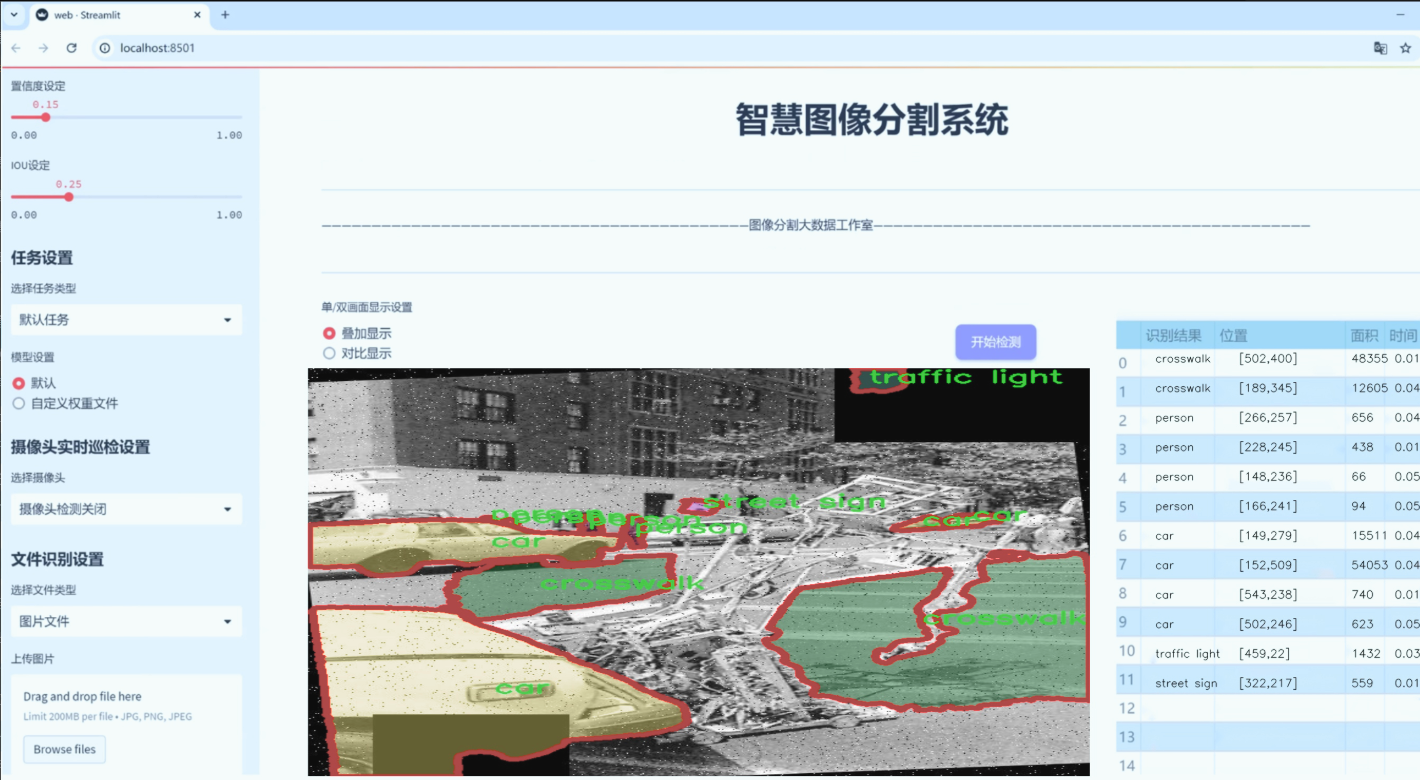
数据集信息
数据集信息展示
在城市交通场景分割系统的研究中,数据集的选择至关重要。为此,我们采用了名为“crosswalk-hq-medium”的数据集,以支持对YOLOv8-seg模型的改进与训练。该数据集专门设计用于城市环境中的目标检测与分割任务,涵盖了多种交通元素,旨在提高自动驾驶系统和智能交通管理的效率与安全性。
“crosswalk-hq-medium”数据集包含13个类别,分别为:自行车(bicycle)、公交车(bus)、小汽车(car)、人行横道(crosswalk)、狗(dog)、消防栓(fire hydrant)、摩托车(motorcycle)、停车计时器(parking meter)、行人(person)、停车标志(stop sign)、街道标志(street sign)、交通信号灯(traffic light)和卡车(truck)。这些类别的选择反映了城市交通场景中的常见元素,能够为模型提供丰富的上下文信息,从而提升分割精度。
数据集中每个类别的样本均经过精心标注,确保了高质量的训练数据。这些标注不仅包括物体的边界框信息,还涵盖了精确的像素级分割掩码,能够帮助模型学习到更为细致的特征。尤其是在复杂的城市环境中,物体之间的相互遮挡和背景的多样性使得目标分割任务变得更加具有挑战性。通过使用“crosswalk-hq-medium”数据集,我们能够有效地训练YOLOv8-seg模型,使其在处理这些复杂场景时表现出更高的鲁棒性和准确性。
此外,该数据集的多样性也为模型的泛化能力提供了保障。城市交通场景的多样性体现在不同的天气条件、时间段以及不同的城市布局中。“crosswalk-hq-medium”数据集包含了在各种环境下拍摄的图像,使得模型能够学习到在不同条件下的物体特征。这种多样性不仅提高了模型在训练集上的表现,也有助于其在实际应用中的适应性,确保在真实世界中能够有效识别和分割各种交通元素。
在训练过程中,我们将“crosswalk-hq-medium”数据集与YOLOv8-seg模型相结合,采用了先进的训练策略和数据增强技术,以进一步提升模型的性能。通过不断迭代和优化,我们期望最终实现一个能够在城市交通场景中高效、准确地进行目标分割的系统。这一系统不仅能够为自动驾驶车辆提供实时的环境感知能力,还能够为交通管理系统提供重要的数据支持,助力智慧城市的建设。
综上所述,“crosswalk-hq-medium”数据集在城市交通场景分割系统的研究中发挥了不可或缺的作用。它不仅为模型提供了丰富的训练样本和多样的场景信息,还为后续的研究和应用奠定了坚实的基础。通过对该数据集的深入分析与利用,我们期待在未来的工作中能够实现更高水平的交通场景理解和智能化管理。

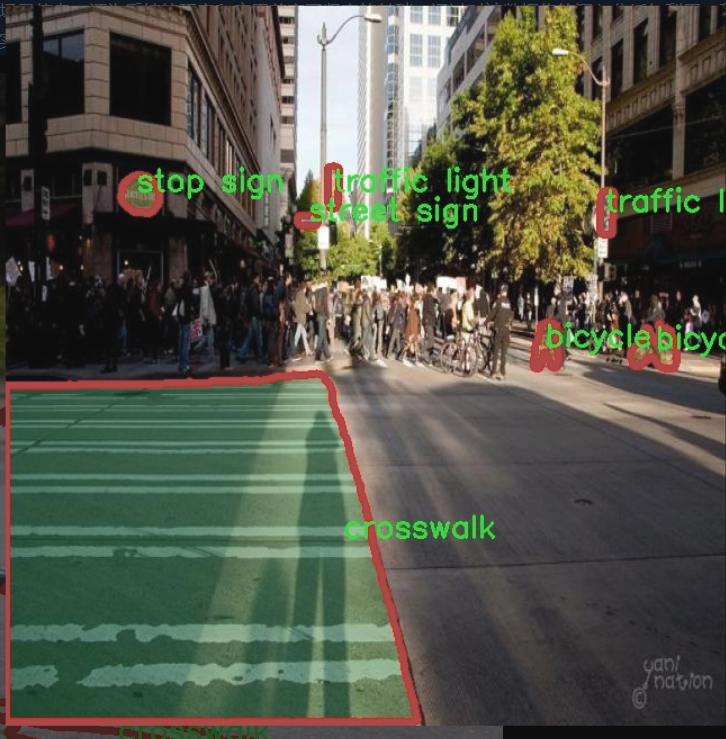



核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import signal
import sys
from pathlib import Path
from time import sleep
import requests
from ultralytics.hub.utils import HUB_API_ROOT, HUB_WEB_ROOT, smart_request
from ultralytics.utils import LOGGER, version, checks, is_colab
from ultralytics.utils.errors import HUBModelError
AGENT_NAME = f’python-{version}-colab’ if is_colab() else f’python-{version}-local’
class HUBTrainingSession:
“”"
HUB训练会话,用于Ultralytics HUB YOLO模型。处理模型初始化、心跳和检查点上传。
“”"
def __init__(self, url):"""使用提供的模型标识符初始化HUBTrainingSession。参数:url (str): 用于初始化HUB训练会话的模型标识符,可以是URL字符串或特定格式的模型键。异常:ValueError: 如果提供的模型标识符无效。ConnectionError: 如果不支持与全局API密钥连接。"""from ultralytics.hub.auth import Auth# 解析输入的URLif url.startswith(f'{HUB_WEB_ROOT}/models/'):url = url.split(f'{HUB_WEB_ROOT}/models/')[-1]if [len(x) for x in url.split('_')] == [42, 20]:key, model_id = url.split('_')elif len(url) == 20:key, model_id = '', urlelse:raise HUBModelError(f"model='{url}' not found. Check format is correct.")# 授权auth = Auth(key)self.model_id = model_idself.model_url = f'{HUB_WEB_ROOT}/models/{model_id}'self.api_url = f'{HUB_API_ROOT}/v1/models/{model_id}'self.auth_header = auth.get_auth_header()self.metrics_queue = {} # 用于存储模型指标的队列self.model = self._get_model() # 获取模型数据self.alive = Trueself._start_heartbeat() # 启动心跳self._register_signal_handlers() # 注册信号处理器LOGGER.info(f'查看模型: {self.model_url} 🚀')def _get_model(self):"""从Ultralytics HUB获取并返回模型数据。"""api_url = f'{HUB_API_ROOT}/v1/models/{self.model_id}'try:response = smart_request('get', api_url, headers=self.auth_header, thread=False, code=0)data = response.json().get('data', None)if data.get('status', None) == 'trained':raise ValueError('模型已训练并上传。')if not data.get('data', None):raise ValueError('数据集可能仍在处理,请稍等。')self.model_id = data['id'] # 更新模型ID# 根据模型状态设置训练参数if data['status'] == 'new':self.train_args = {'batch': data['batch_size'],'epochs': data['epochs'],'imgsz': data['imgsz'],'patience': data['patience'],'device': data['device'],'cache': data['cache'],'data': data['data']}self.model_file = data.get('cfg') or data.get('weights')self.model_file = checks.check_yolov5u_filename(self.model_file, verbose=False)elif data['status'] == 'training':self.train_args = {'data': data['data'], 'resume': True}self.model_file = data['resume']return dataexcept requests.exceptions.ConnectionError as e:raise ConnectionRefusedError('ERROR: HUB服务器未在线,请稍后再试。') from eexcept Exception:raise@threaded
def _start_heartbeat(self):"""开始一个线程心跳循环,向Ultralytics HUB报告代理状态。"""while self.alive:r = smart_request('post',f'{HUB_API_ROOT}/v1/agent/heartbeat/models/{self.model_id}',json={'agent': AGENT_NAME},headers=self.auth_header,retry=0,code=5,thread=False) # 已在一个线程中sleep(300) # 每300秒发送一次心跳
代码说明:
导入模块:导入必要的模块和库,包括信号处理、路径操作、时间处理和HTTP请求。
AGENT_NAME:根据当前环境(Colab或本地)设置代理名称。
HUBTrainingSession类:主要类,用于管理与Ultralytics HUB的训练会话。
初始化方法:解析模型标识符,进行授权,获取模型数据,启动心跳和注册信号处理器。
_get_model方法:从Ultralytics HUB获取模型数据,并根据模型状态设置训练参数。
_start_heartbeat方法:在一个线程中循环发送心跳,报告代理状态。
这个程序文件定义了一个名为 HUBTrainingSession 的类,主要用于管理与 Ultralytics HUB 的 YOLO 模型训练会话。该类负责模型的初始化、心跳检测和检查点上传等功能。
在初始化方法 init 中,程序首先解析传入的模型标识符 url,确保其格式正确。如果 url 是以 Ultralytics HUB 的模型网址开头,则提取出模型的关键部分。接着,程序会创建一个 Auth 实例以进行身份验证,并设置一些属性,包括模型的 URL、API URL、身份验证头、速率限制、定时器、模型数据队列等。然后,调用 _get_model 方法从 HUB 获取模型数据,并启动心跳检测。
_register_signal_handlers 方法用于注册信号处理程序,以便在接收到终止信号时能够优雅地关闭程序。_handle_signal 方法处理这些信号,停止心跳并退出程序。
upload_metrics 方法用于将模型的性能指标上传到 Ultralytics HUB。它会构建一个包含指标的有效负载,并通过 smart_request 方法发送 POST 请求。
_get_model 方法负责从 Ultralytics HUB 获取模型数据。它会检查模型的状态,并根据状态决定是开始新的训练还是恢复已有的训练。如果模型状态为“新”,则提取训练参数;如果状态为“训练中”,则准备恢复训练。
upload_model 方法用于将模型的检查点上传到 Ultralytics HUB。它会检查权重文件是否存在,并根据是否为最佳模型或最终模型来构建上传请求。
最后,_start_heartbeat 方法启动一个线程,定期向 Ultralytics HUB 发送心跳请求,以报告代理的状态。这个方法会在类实例存活时持续运行,并使用 smart_request 方法发送 POST 请求。
总体而言,这个文件实现了与 Ultralytics HUB 进行交互的基本功能,确保模型训练过程中的数据上传和状态监控。
11.5 chinese_name_list.py
以下是代码的核心部分,并附上详细的中文注释:
-- coding: utf-8 -- # 指定文件编码为UTF-8,以支持中文字符
创建一个字典,键为’person’,值为中文’人’
Chinese_name = {‘person’: “人”}
从字典中提取所有值,生成一个列表
Label_list = list(Chinese_name.values())
注释说明:
-- coding: utf-8 --:这行代码指定了文件的编码格式为UTF-8,以确保能够正确处理和显示中文字符。
Chinese_name = {‘person’: “人”}:定义一个字典Chinese_name,其中包含一个键值对,键为’person’,对应的值为中文字符"人"。
Label_list = list(Chinese_name.values()):使用values()方法从字典中提取所有的值,并将其转换为列表,赋值给Label_list。此时,Label_list将包含字典中的所有中文名称。
这个程序文件的名称是 chinese_name_list.py,它的主要功能是定义一个包含中文名称的字典,并从中提取出值列表。
首先,文件的第一行 # -- coding: utf-8 -- 是一个编码声明,表示这个文件使用 UTF-8 编码格式。这对于处理中文字符非常重要,因为它确保了中文字符能够被正确识别和显示。
接下来,定义了一个字典 Chinese_name,其中包含一个键值对。键是字符串 “person”,对应的值是中文字符 “人”。这个字典的目的是存储中文名称及其对应的英文标识。
然后,使用 list(Chinese_name.values()) 这一行代码从字典中提取出所有的值,并将它们转换成一个列表。这里,Chinese_name.values() 方法返回字典中所有值的视图,而 list() 函数则将这个视图转换为一个列表。最终,提取出的值被存储在变量 Label_list 中。
综上所述,这个程序的核心功能是创建一个包含中文名称的字典,并将这些名称以列表的形式存储,方便后续使用。
12.系统整体结构(节选)
整体功能和构架概括
该项目是Ultralytics YOLO模型的实现,主要用于目标检测和跟踪。项目的整体架构分为多个模块,每个模块负责特定的功能,以提高代码的可维护性和可重用性。主要模块包括数据加载、模型训练、工具函数、与Ultralytics HUB的交互等。通过这些模块,用户可以方便地进行模型训练、数据处理和性能监控。
以下是各个文件的功能整理表:
文件路径 功能描述
ultralytics/utils/torch_utils.py 提供与PyTorch相关的工具函数和类,包括设备选择、模型信息、权重初始化等。
ultralytics/trackers/utils/init.py 初始化包,声明许可证信息,允许导入该目录下的模块。
ultralytics/data/loaders.py 定义数据加载类,支持从视频流、图像、截图和张量等多种数据源加载数据。
ultralytics/hub/session.py 管理与Ultralytics HUB的训练会话,包括模型上传、心跳检测和状态监控。
chinese_name_list.py 定义一个包含中文名称的字典,并提取出名称列表。
通过这些模块的协同工作,Ultralytics YOLO项目能够高效地进行目标检测和跟踪任务,同时提供了良好的用户体验和灵活性。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻