深度学习激活函数:从 Sigmoid 到 GELU 的演变历程
在深度学习领域,激活函数是神经网络的核心组成部分,它赋予了神经网络学习复杂非线性关系的能力。如果没有激活函数,无论神经网络有多少层,都只能表示输入和输出之间的线性关系,这大大限制了网络的表达能力。激活函数的作用是对神经元的输入进行非线性变换,从而使神经网络能够学习和表示复杂的非线性映射。
激活函数的选择对神经网络的性能至关重要。不同的激活函数具有不同的数学特性,因此在不同的问题上表现也会有所不同。随着深度学习技术的不断发展,激活函数也经历了从简单到复杂、从基础到高级的演变过程。本文将全面介绍深度学习中常用的激活函数,包括 Sigmoid、Tanh、ReLU、Softmax、Leaky ReLU、PReLU、ELU 和 GELU,探讨它们的数学原理、优缺点以及演变过程:
早期激活函数:Sigmoid 和 Tanh
Sigmoid 函数:深度学习的起点
Sigmoid 函数是最早被广泛使用的激活函数之一,看到他大家往往可以联系起逻辑回归,它的数学表达式为:
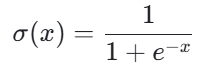
Sigmoid 函数是一个 S 型曲线,它将任意实数映射到 0 到 1 之间的范围内。这种特性使得 Sigmoid 函数特别适合用于二元分类问题,因为它可以将输出解释为概率值。
Sigmoid 函数的历史可以追溯到 19 世纪,数学家们当时就研究了类似的函数形式。在 1986 年,David Rumelhart、Geoffrey Hinton 和 Ronald Williams 在提出多层感知器(MLP)和反向传播算法时,Sigmoid 函数被广泛使用,因为它的导数形式简单,便于计算梯度。
Tanh 函数:Sigmoid 的改进版
Tanh(双曲正切)函数可视为 Sigmoid 函数的改进版本,其数学表达式为:
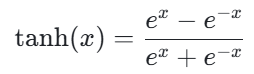
Tanh 函数也是一种 S 型曲线,但它将输出范围限制在 - 1 到 1 之间,这是与 Sigmoid 函数的主要区别:随着神经网络的发展,Tanh 函数被引入作为一种激活函数,它在 Sigmoid 函数的基础上进行了改进。
虽然 Tanh 在某些方面优于 Sigmoid,但两者都存在梯度消失的问题,这使得它们在深度神经网络中的应用受到限制。研究表明,当使用 sigmoid 和 tanh 激活函数时,它们的导数在输入值较大或较小时会变得非常小,导致梯度消失,使得深层网络难以训练。这一局限性推动了后续激活函数的发展。
ReLU 时代:深度学习的转折点
ReLU 函数:开启深度网络新纪元
ReLU(Rectified Linear Unit,修正线性单元)函数的提出是激活函数发展的一个重要里程碑。其数学表达式为:
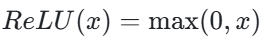
ReLU 函数在输入大于 0 时输出等于输入,否则输出为 0。这一简单的数学形式却带来了深度学习领域的重大突破。
ReLU 函数最早可追溯到 1941 年,由 Alston Householder 首次提出。1969 年,Kunihiko Fukushima 在其 “cognitron” 论文中首次将 ReLU 引入视觉特征提取领域。然而,ReLU 真正被广泛应用是在 2010 年,由 Vinod Nair 和 Geoffrey Hinton 在他们的论文《Rectified Linear Units Improve Restricted Boltzmann Machines》中展示了 ReLU 在深度神经网络中的有效性。
ReLU 的出现极大地推动了深度学习的发展,因为它解决了长期困扰深度网络训练的梯度消失问题,使得训练更深的神经网络成为可能。与 Sigmoid 和 Tanh 相比,ReLU 在深度网络中表现出显著优势,主要体现在训练速度和缓解梯度消失方面。
Leaky ReLU:解决 “死亡 ReLU” 问题
为了解决 ReLU 的 “死亡” 问题,Leaky ReLU 被提出,Leaky ReLU 首次出现在 2013 年的论文《Rectifier Nonlinearities Improve Neural Network Acoustic Models》中,该论文由 Andrew L. Maas、Awni Y. Hannun 和 Andrew Y. Ng 撰写。其数学表达式为:
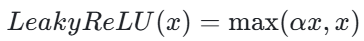
其中,α 是一个小于 1 的常数,通常取 0.01。Leaky ReLU 在输入小于 0 时,不再输出 0,而是输出一个很小的值 αx,这样可以避免 ReLU 函数的 “神经元死亡” 问题。
PReLU:可学习的 Leaky ReLU
PReLU(Parametric ReLU,参数化 ReLU)是 Leaky ReLU 的一个变体,PReLU 是由何凯明(Kaiming He)、张翔(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jian Sun)在 2015 年的论文《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》中提出的。其中负半轴的斜率是可学习的参数,其数学表达式为:
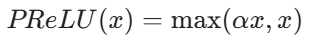
(这里的 α 是通过反向传播学习得到的参数)
ELU:结合指数特性的 ReLU 变体
ELU 激活函数是在 2015 年由 Djork-Arné Clevert、Thomas Unterthiner 和 Sepp Hochreiter 在论文《Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)》中提出的——ELU(Exponential Linear Unit,指数线性单元)试图结合 ReLU 的优点和负值输入的处理,其数学表达式为:
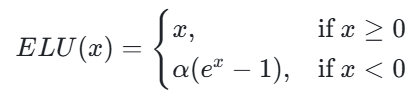
其中 α 是一个大于 0 的常数,通常取 1。
ReLU 及其变体的出现极大地推动了深度学习的发展。从 ReLU 到 Leaky ReLU、PReLU 再到 ELU,每一步改进都针对前一代激活函数的缺点进行了优化:
- ReLU解决了梯度消失问题,但存在 “死亡神经元” 问题。
- Leaky ReLU通过在负半轴引入小的斜率解决了 “死亡神经元” 问题,但需要手动设置斜率参数。
- PReLU进一步改进,允许斜率参数通过学习获得,增强了模型的适应性。
- ELU则在保持 ReLU 优点的同时,通过指数形式处理负值输入,实现了更平滑的过渡和零均值输出。
这些改进体现了深度学习研究中不断优化的过程,每个新的激活函数都试图解决前一代的局限性,从而推动整个领域的进步。
Softmax:分类问题的必备工具
Softmax 函数的概念来源于统计力学中的 Boltzmann 分布,它在 20 世纪中期开始被应用于神经网络中。在统计力学中,Softmax 函数作为 Boltzmann 分布出现在基础论文 Boltzmann (1868) 中,后由 Gibbs 在 1902 年的权威教科书中正式确立和推广。在神经网络领域,Softmax 首次被提出是在 1993 年,由研究者使用统计力学中的平均场理论方法从不连续的 “winner-takes-all”(WTA)映射推导而来,是一种常用的多分类激活函数,它的公式为:
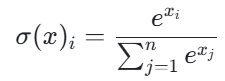
Softmax 函数将一个实数向量转换为一个概率分布,其中每个元素都在 0 到 1 之间,且所有元素的和为 1。
Softmax 与 Sigmoid 的关系:
值得注意的是,Softmax 是 Sigmoid 函数的推广。当类别数为 2 时,Softmax 退化为 Sigmoid 函数。具体来说,对于二分类问题,Softmax 可以表示为:

这与 Sigmoid 函数的输出形式一致。因此,Sigmoid 可以视为 Softmax 在二分类问题中的特例。
新一代激活函数:超越 ReLU
GELU:概率启发的激活函数
激活函数GELU(Gaussian Error Linear Unit,高斯误差线性单元)是一种相对较新的激活函数,是在 2016 年由 Dan Hendrycks 和 Kevin Gimpel 在论文《Gaussian Error Linear Units (GELUs)》中提出的。然而,这一函数在提出后的几年内并未引起广泛关注,直到 2019 年以后才开始在 Transformer 架构中得到广泛应用,如 BERT、GPT-2 等模型都采用了 GELU ,它的公式为:
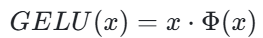
其中,Φ(x) 是标准正态分布的累积分布函数,数学表达式为:
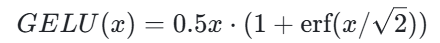
这里的 erf 是误差函数,是高斯分布的积分形式。
其他新型激活函数简介
除了上述主要的激活函数外,深度学习领域还涌现了许多新型激活函数。这些函数通常基于特定的设计理念或针对特定任务进行优化:
- Swish:由 Google Brain 团队在 2017 年提出,公式为:
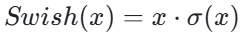
Swish 结合了 Sigmoid 的门控机制和线性部分,在多个任务上表现优异。 - Mish:2019 年提出的自门控激活函数,公式为:
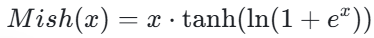
Mish 在保持非单调性的同时,具有更好的正则化效果。 - GLU(门控线性单元):公式为:
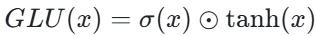
其中 σ 是 Sigmoid 函数,⊙表示元素级乘法。GLU 在输入上应用了门控机制,通过 Sigmoid 函数来控制输入的信息流动。 - SELU(自归一化指数线性单元):2017 年提出,公式为:
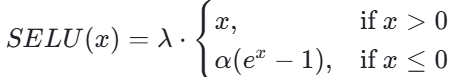
SELU 具有自归一化特性,可以使得网络的输出保持稳定。
这些新型激活函数虽然在特定场景下表现优异,但尚未像 ReLU 和 GELU 那样被广泛采用。它们的出现反映了深度学习研究中对更好激活函数的持续探索。
激活函数的演变历程与设计理念
激活函数发展时间线
通过回顾各种激活函数的发展历程,我们可以构建一个清晰的时间线,展示激活函数是如何随着时间发展和改进的:
19 世纪:Sigmoid 函数的数学形式开始被研究。
1868 年:Softmax 的前身 Boltzmann分布在统计力学中被提出。
1902 年:Boltzmann 分布由 Gibbs 在教科书中正式确立和推广。
1941 年:ReLU的数学形式首次由 Alston Householder 提出。
1969 年:Kunihiko Fukushima 首次将 ReLU引入视觉特征提取领域。
1986 年:Sigmoid 函数在多层感知器和反向传播算法中被广泛使用。
1993 年:Softmax函数首次被正式提出并应用于神经网络。
2010 年:Vinod Nair 和 Geoffrey Hinton 展示了 ReLU在深度神经网络中的有效性。
2013 年:Leaky ReLU 首次出现在论文中,用于缓解 “死亡 ReLU” 问题。
2015 年:PReLU 由何凯明等人提出,引入可学习的负斜率参数。 ELU 由 Djork-Arné Clevert等人提出,结合指数特性处理负值输入。
2016 年:GELU 由 Dan Hendrycks 和 Kevin Gimpel提出,基于概率理论设计。
2017 年: Swish 由 Google Brain 团队提出。 SELU 和 GLU也在这一年被提出。
2019 年:Mish 激活函数被提出。
激活函数设计的核心原则
随着激活函数的不断发展,研究者们逐渐形成了一些设计激活函数的核心原则:
缓解梯度消失 / 爆炸:早期的 Sigmoid 和 Tanh 函数由于梯度消失问题限制了深度网络的训练。ReLU 及其变体通过引入线性区域解决了这一问题。
计算效率: 激活函数的计算复杂度直接影响模型的训练和推理速度。ReLU 之所以广受欢迎,很大程度上是因为其计算简单高效。
稀疏性: ReLU 的稀疏激活特性(即部分神经元输出为零)有助于提高模型的泛化能力,并减少过拟合风险。
平滑性: 平滑的激活函数(如 GELU 和 Swish)通常具有更好的优化特性,能够帮助模型更快收敛。
自适应性: 从 Leaky ReLU 到 PReLU 再到 GELU,激活函数越来越注重根据数据自动调整其行为,增强模型的适应性。
生物学合理性: 一些激活函数(如 ReLU 和 GELU)试图模拟生物神经元的行为,这为模型提供了一定的生物学解释。
这些设计原则反映了深度学习研究者对神经网络本质的深入理解,以及对更好模型性能的不懈追求。每个新的激活函数都试图在这些原则之间找到更好的平衡,以适应不断发展的深度学习需求。
激活函数选择指南
分类问题的输出层:
二分类:使用 Sigmoid 函数。
多分类:使用 Softmax 函数。
隐藏层:
一般情况:优先考虑 ReLU,因其简单高效。
存在 “死亡神经元” 问题:尝试 Leaky ReLU、PReLU 或 ELU。
需要更快收敛速度:考虑 ELU 或 GELU。
自然语言处理任务:考虑 GELU 或 Swish。
对计算资源有限:坚持使用 ReLU。
特殊情况:
循环神经网络:考虑 Tanh 函数。
需要概率解释的激活:考虑 GELU。
对模型性能要求极高:尝试最新的激活函数如 Mish。
选择激活函数时还应考虑以下因素:
数据特性:不同的数据分布可能适合不同的激活函数。
模型架构:某些激活函数与特定的模型架构(如 Transformer)配合更好。
计算资源:复杂的激活函数(如 GELU 和 Swish)可能需要更多的计算资源。
训练目标:不同的激活函数可能在不同的任务(如分类、回归)中表现不同。
值得注意的是,激活函数的选择通常需要通过实验来验证。在实际应用中,可以尝试多种激活函数,并比较它们在验证集上的性能,选择表现最好的一个。