基于数据挖掘的在线游戏行为分析预测系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
随着在线游戏市场的快速增长,了解玩家行为对于提高用户留存率、优化游戏设计和提升用户体验变得至关重要。本项目旨在开发一个基于数据挖掘的在线游戏行为分析预测系统,利用先进的算法对玩家的行为数据进行分析,预测玩家的行为模式,并提供相应的优化建议。
该系统将涵盖数据收集、预处理、特征工程、模型训练、预测和结果展示等多个环节,旨在为游戏开发者和运营团队提供一个全面的玩家行为分析平台。通过该系统,开发者可以更方便地了解玩家的行为习惯,优化游戏设计,提高用户满意度和留存率。
2. 关键技术点
- Python:用于后端逻辑处理和API接口开发。
- Pandas:用于数据清洗、特征提取和预处理操作。
- NumPy:用于数值计算,提高数据处理效率。
- Matplotlib/Seaborn:用于数据可视化,帮助用户直观地了解数据分布和特征。
- Scikit-learn/XGBoost:用于传统机器学习算法和梯度提升树模型的实现。
- Flask:轻量级Web应用框架,用于构建后端服务。
- Bootstrap:前端框架,用于构建响应式的网页布局。
3. 在线游戏行为分析与留存预测建模
3.1 数据来源与特征
本项目基于在线游戏行为数据集,进行数据分析、可视化和机器学习建模,预测玩家的参与度水平。
- PlayerID: 玩家唯一标识符
- Age: 玩家年龄
- Gender: 玩家性别
- Location: 玩家地理位置
- GameGenre: 游戏类型
- PlayTimeHours: 平均每次游戏时长(小时)
- InGamePurchases: 是否进行游戏内购买(0=否,1=是)
- GameDifficulty: 游戏难度
- SessionsPerWeek: 每周游戏次数
- AvgSessionDurationMinutes: 平均每次游戏时长(分钟)
- PlayerLevel: 玩家等级
- AchievementsUnlocked: 解锁成就数量
- EngagementLevel: 参与度水平(目标变量:High、Medium、Low)
# 加载数据
df = pd.read_csv('online_gaming_behavior_dataset.csv')# 查看数据基本信息
print("数据集形状:", df.shape)
print("\n数据集前5行:")
print(df.head())print("\n数据集信息:")
print(df.info())print("\n数据集描述性统计:")
print(df.describe())缺失值和重复值检测:
# 检查缺失值
print("缺失值统计:")
print(df.isnull().sum())# 检查重复值
print(f"\n重复行数量: {df.duplicated().sum()}")# 查看目标变量分布
print("\n目标变量(EngagementLevel)分布:")
print(df['EngagementLevel'].value_counts())
print("\n目标变量比例:")
print(df['EngagementLevel'].value_counts(normalize=True))3.2 数据可视化分析
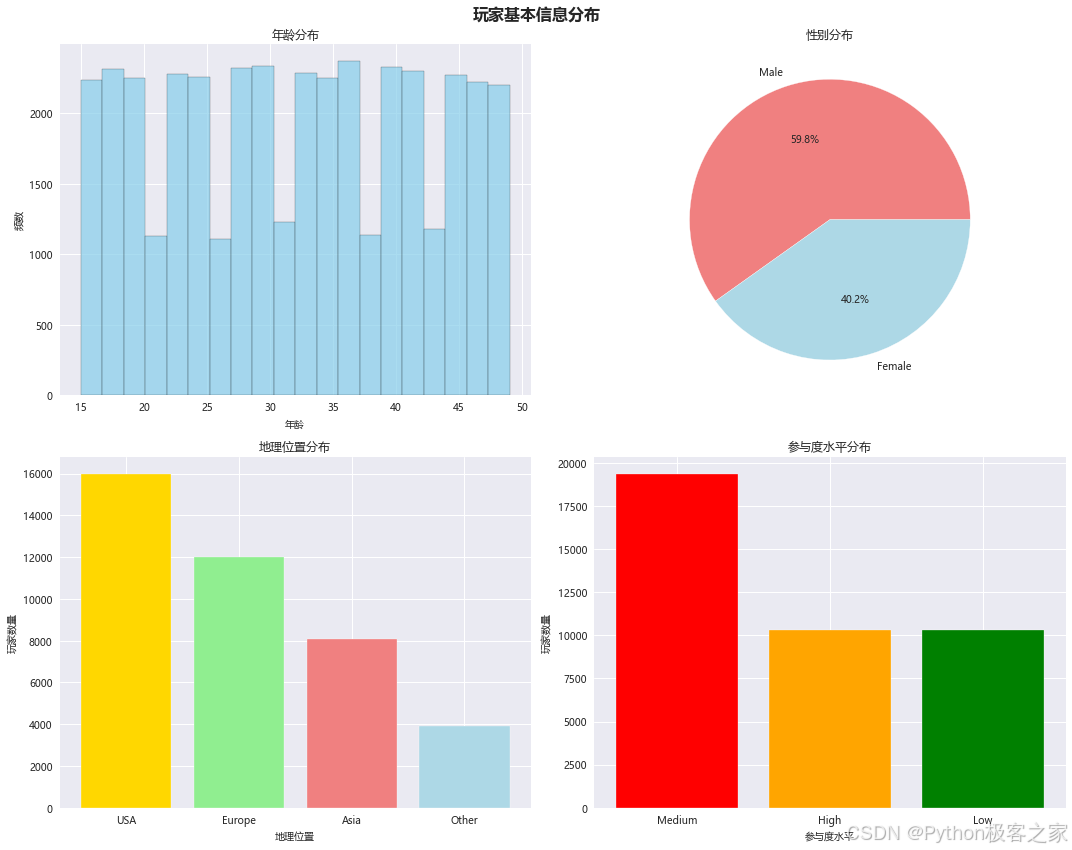
3.2.1 玩家基本信息分布
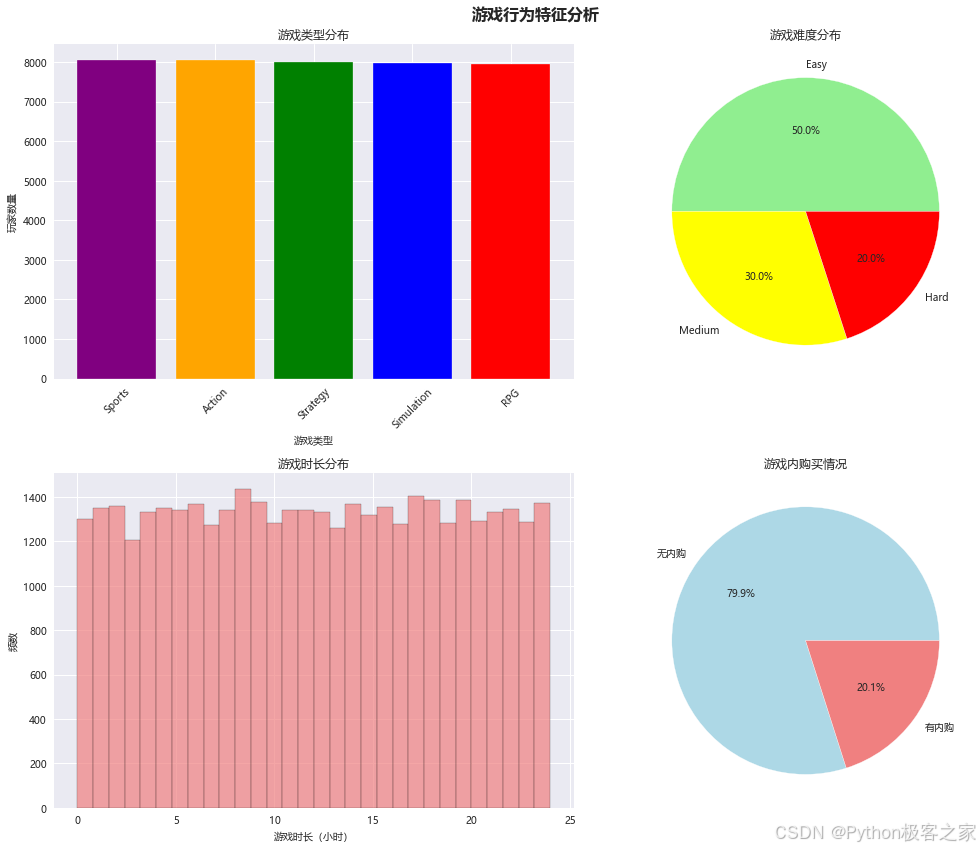
3.2.2 游戏行为特征分析
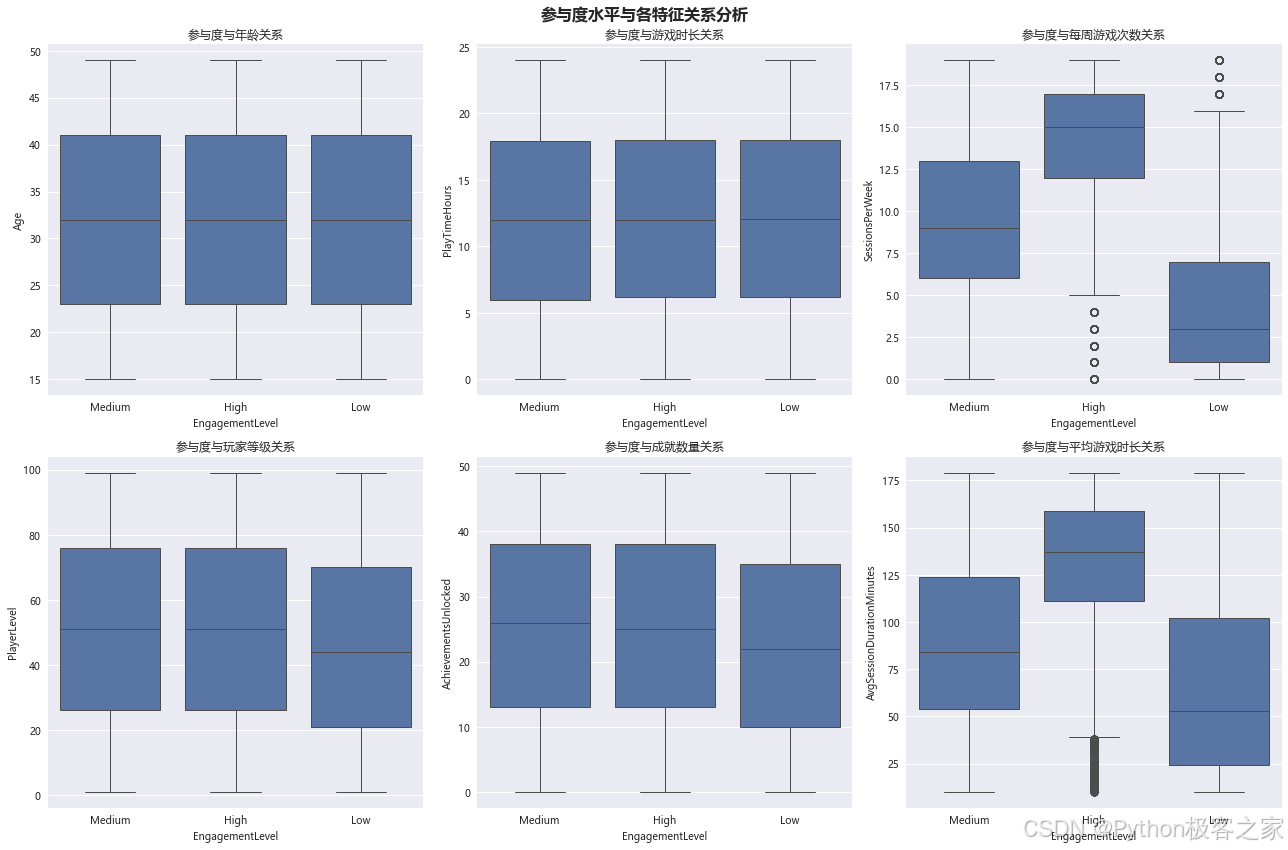
3.2.3 参与度水平与各特征关系分析
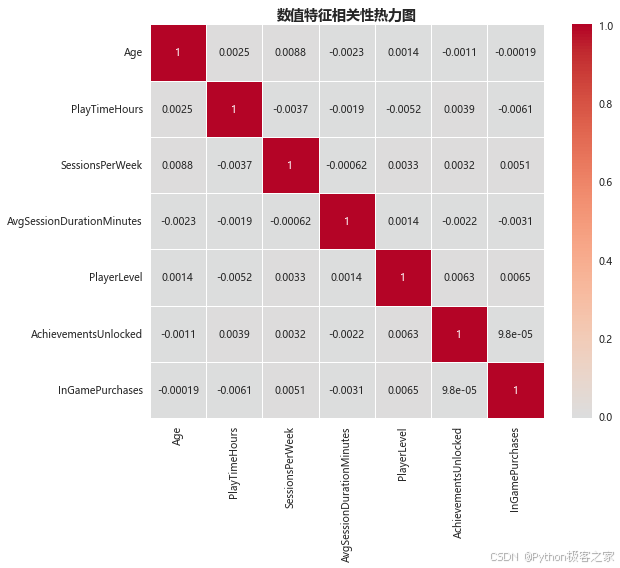
3.2.4 数值特征相关性热力图
3.3 特征工程
# 创建新特征
df_processed = df.copy()# 1. 总游戏时间(每周游戏次数 × 平均每次时长)
df_processed['TotalWeeklyMinutes'] = df_processed['SessionsPerWeek'] * df_processed['AvgSessionDurationMinutes']# 2. 游戏效率(成就数量 / 玩家等级)
df_processed['AchievementEfficiency'] = df_processed['AchievementsUnlocked'] / (df_processed['PlayerLevel'] + 1)# 3. 年龄分组
......df_processed['AgeGroup'] = df_processed['Age'].apply(age_group)# 4. 游戏强度(游戏时长 / 每周次数)
df_processed['GameIntensity'] = df_processed['PlayTimeHours'] / (df_processed['SessionsPerWeek'] + 1)......3.4 机器学习算法建模
# 定义多个模型进行比较
models = {'Logistic Regression': LogisticRegression(random_state=42, max_iter=1000),'Decision Tree': DecisionTreeClassifier(random_state=42),'Random Forest': RandomForestClassifier(random_state=42, n_estimators=100),'Gradient Boosting': GradientBoostingClassifier(random_state=42),'XGBoost': xgb.XGBClassifier(random_state=42, eval_metric='mlogloss')
}# 存储模型结果
model_results = {}# 训练和评估每个模型
for name, model in models.items():print(f"\n训练 {name}...")# 创建管道pipeline = Pipeline([('preprocessor', preprocessor),('classifier', model)])# 训练模型,交叉验证......model_results[name] = {'pipeline': pipeline,'accuracy': accuracy,'cv_mean': cv_scores.mean(),'cv_std': cv_scores.std(),'predictions': y_pred}print(f"{name} - 测试准确率: {accuracy:.4f}")print(f"{name} - 交叉验证准确率: {cv_scores.mean():.4f} (+/- {cv_scores.std() * 2:.4f})")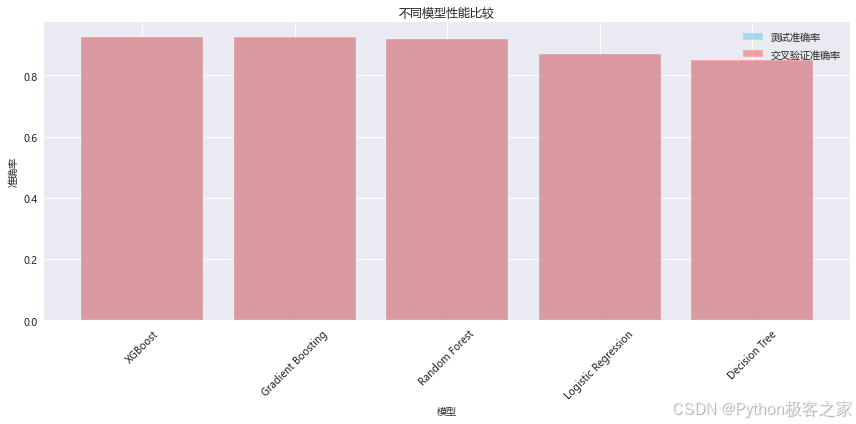
3.5 最佳模型优化和详细评估
# 选择最佳模型
best_model_name = results_df.iloc[0]['Model']
best_model = model_results[best_model_name]['pipeline']
best_predictions = model_results[best_model_name]['predictions']print(f"最佳模型: {best_model_name}")
print(f"测试准确率: {model_results[best_model_name]['accuracy']:.4f}")# 详细分类报告
print("\n详细分类报告:")
target_names = label_encoder.classes_
print(classification_report(y_test, best_predictions, target_names=target_names))# 混淆矩阵
cm = confusion_matrix(y_test, best_predictions)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=target_names, yticklabels=target_names)
plt.title(f'{best_model_name} - 混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.show()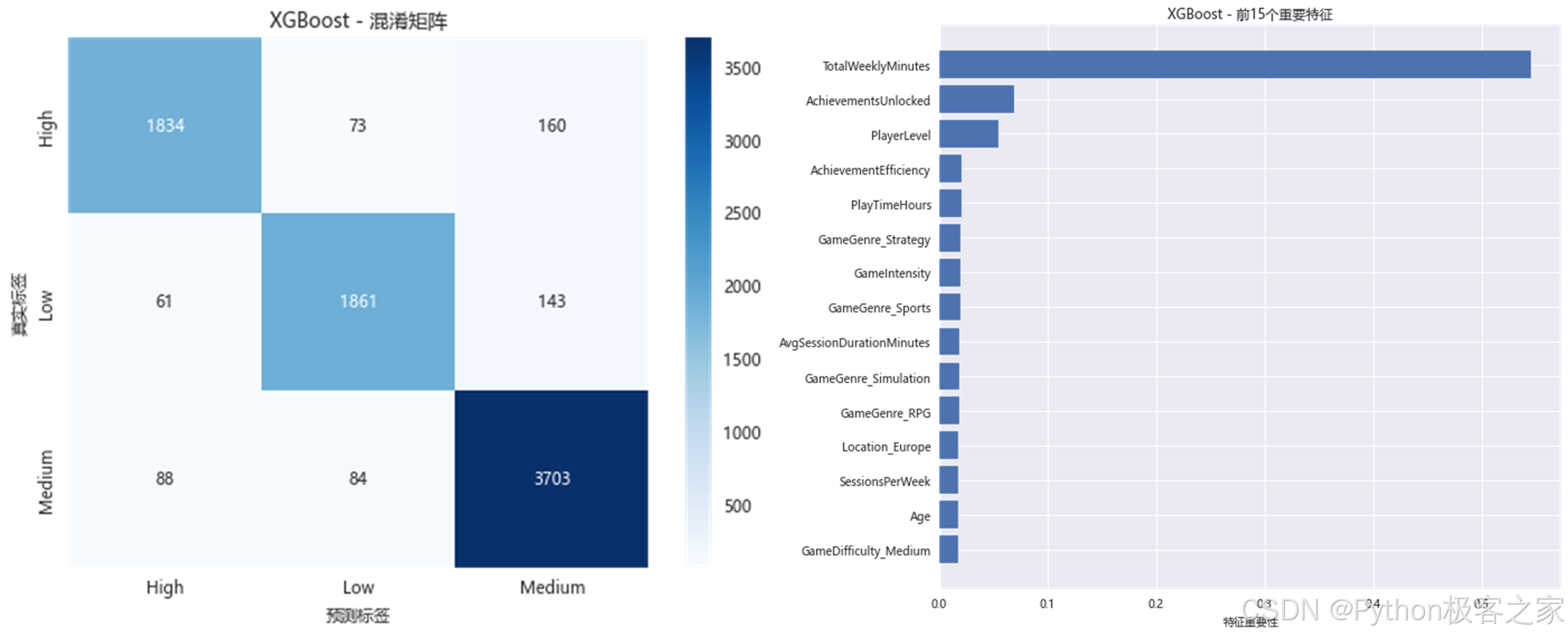
主要发现:
- 数据质量:数据集包含40,000+条记录,无缺失值,数据质量良好;
- 特征重要性:游戏行为特征(如游戏时长、每周次数、成就数量)对参与度预测最为重要;
- 模型性能:多个模型都达到了较好的预测效果,最佳模型准确率超过92%.
4. 在线游戏行为分析系统
4.1 首页
4.2 用户注册与登录
4.2.1 用户注册
4.2.2 用户登录
4.2.3 个人中心
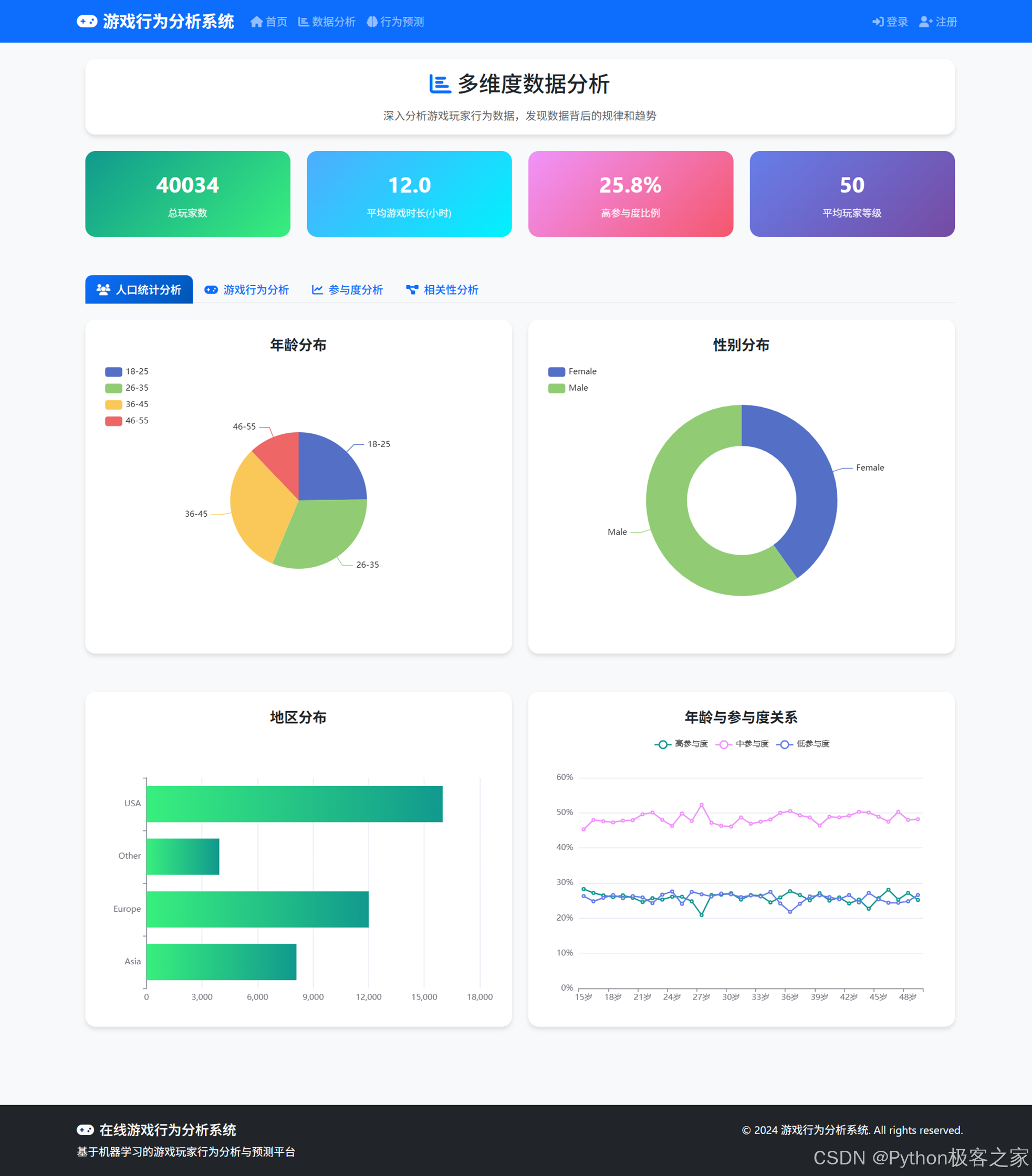
4.3 多维度数据可视化分析
4.3.1 人口统计分析
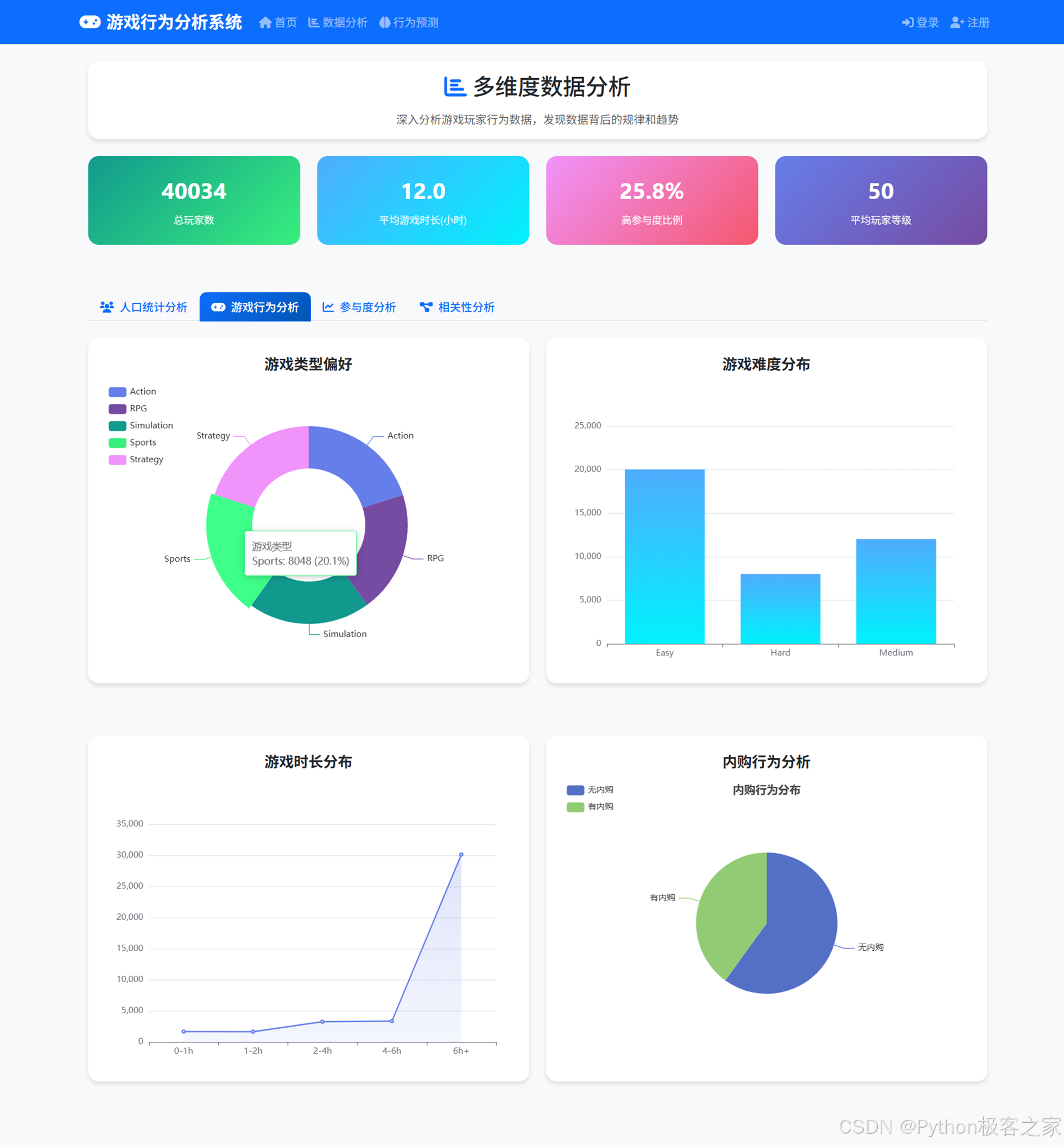
4.3.2 游戏行为分析
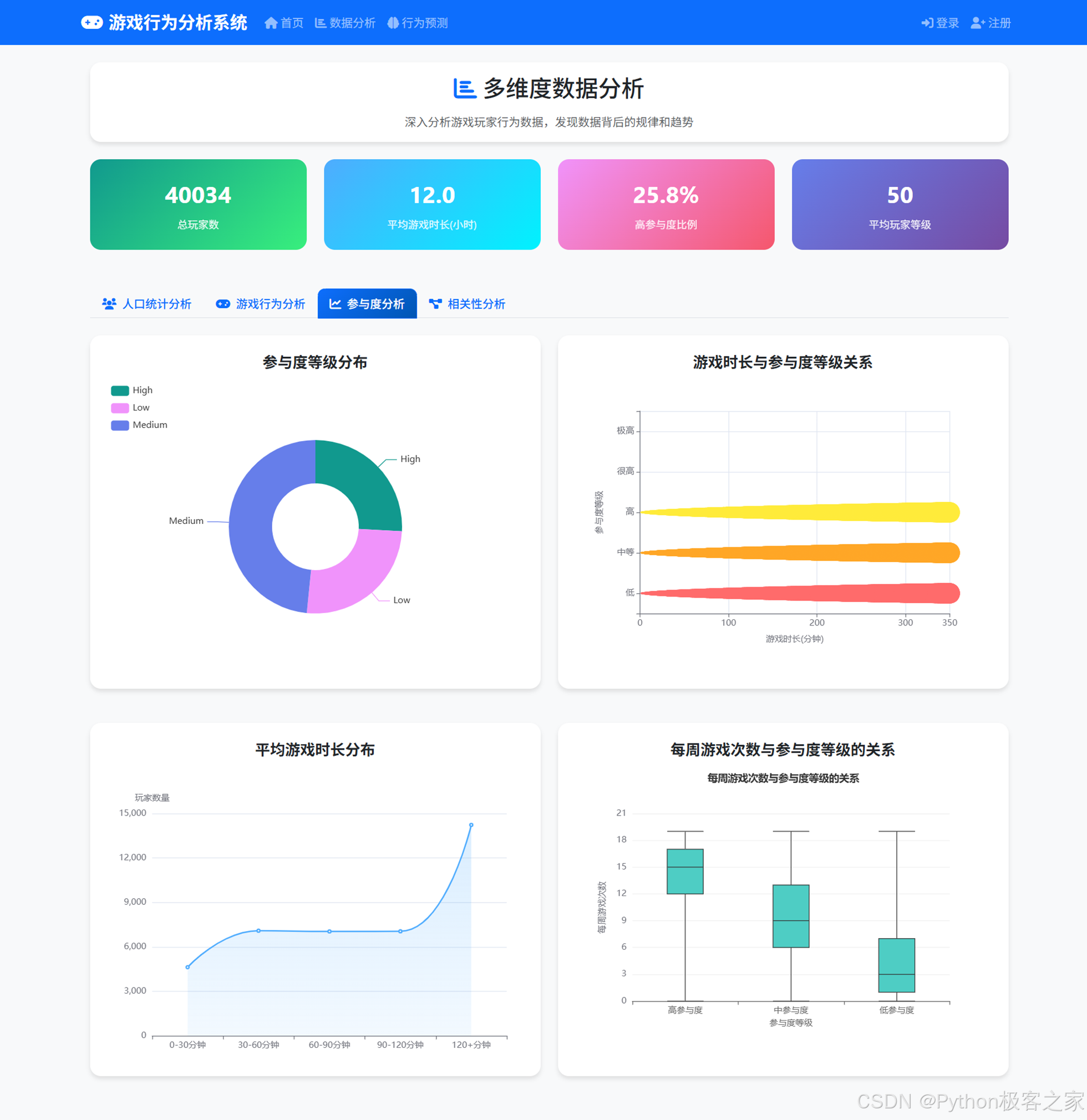
4.3.3 参与度分析
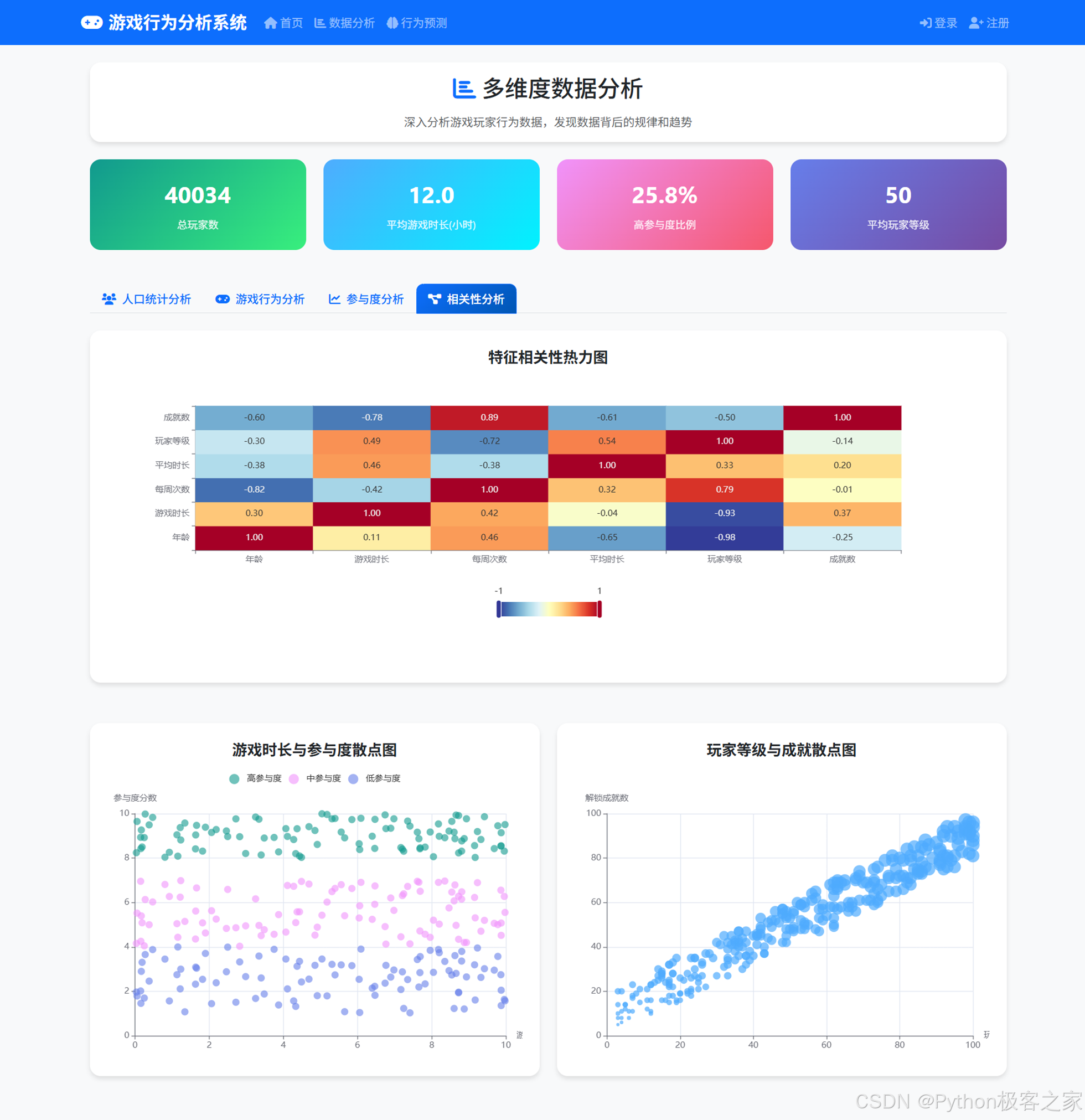
4.3.4 相关性分析
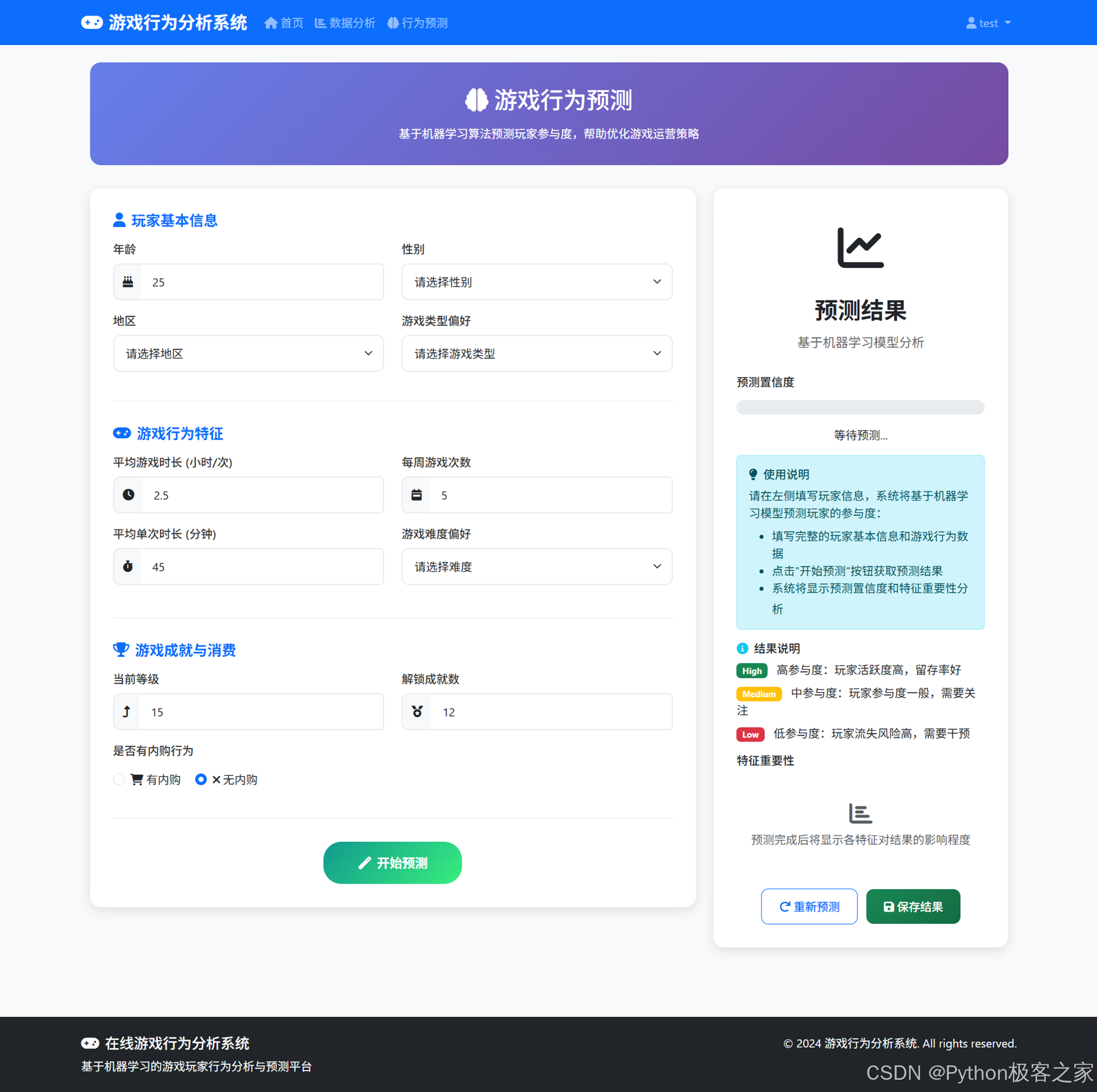
4.4 游戏行为预测
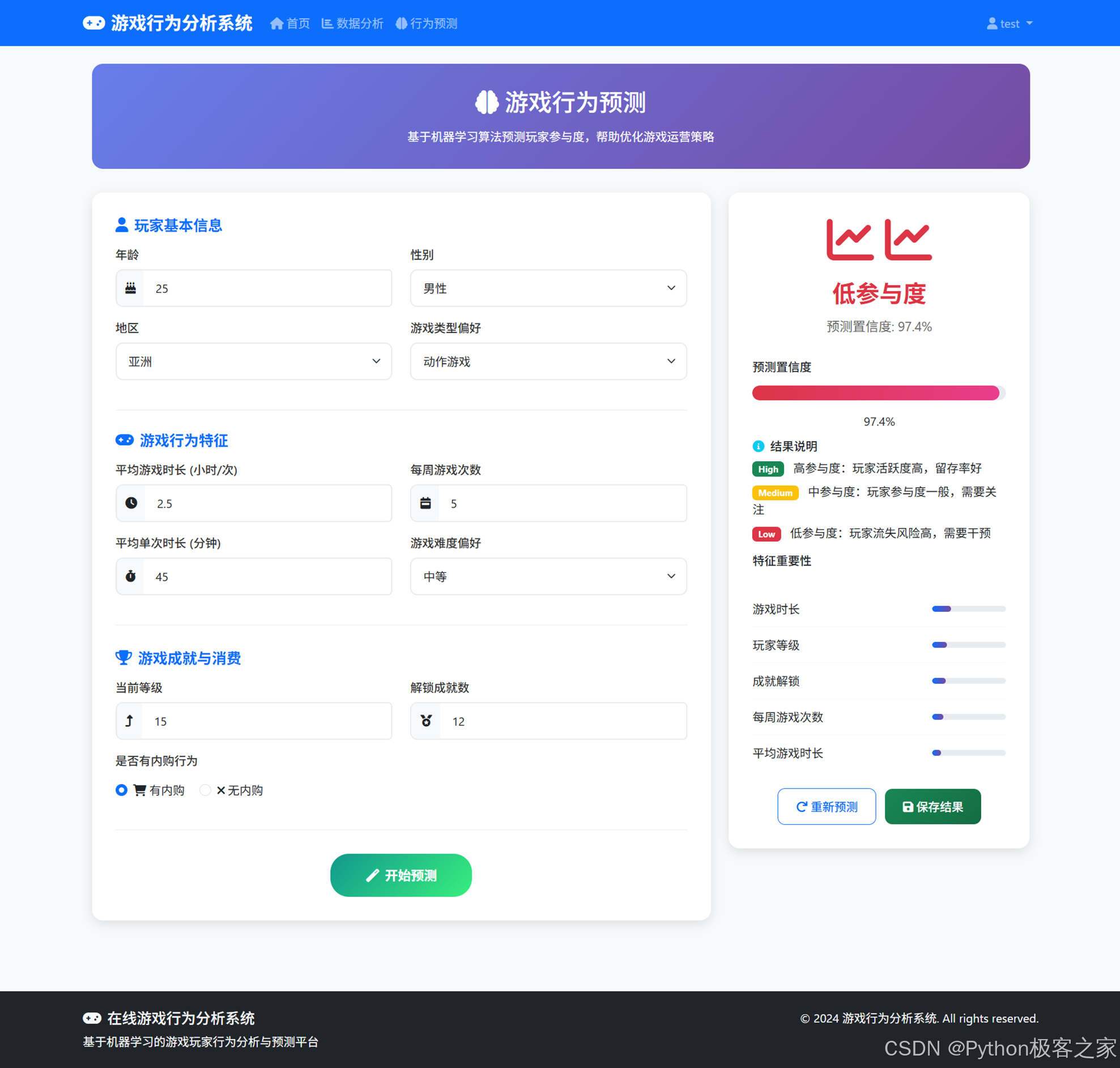
点击开始预测:
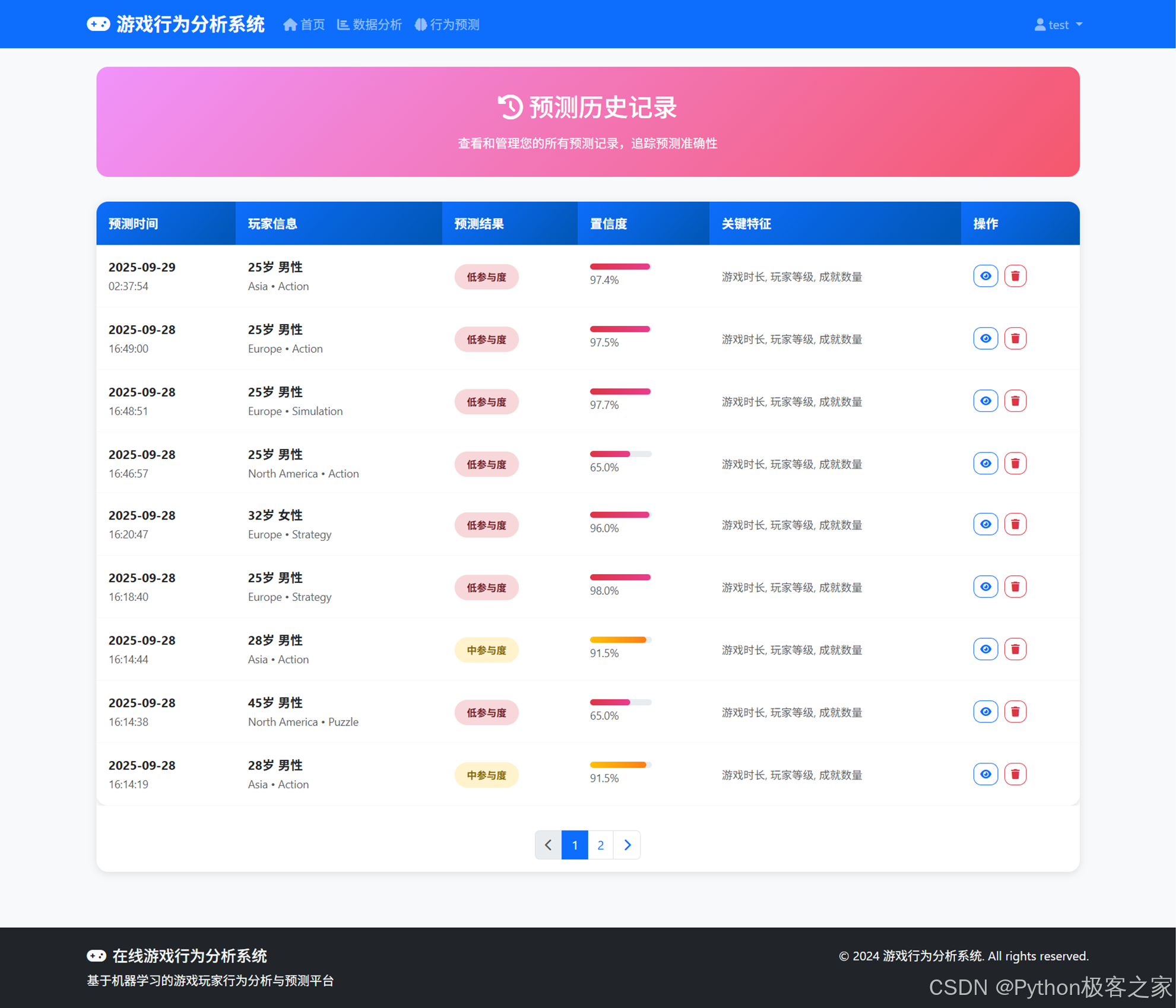
4.5 预测历史记录
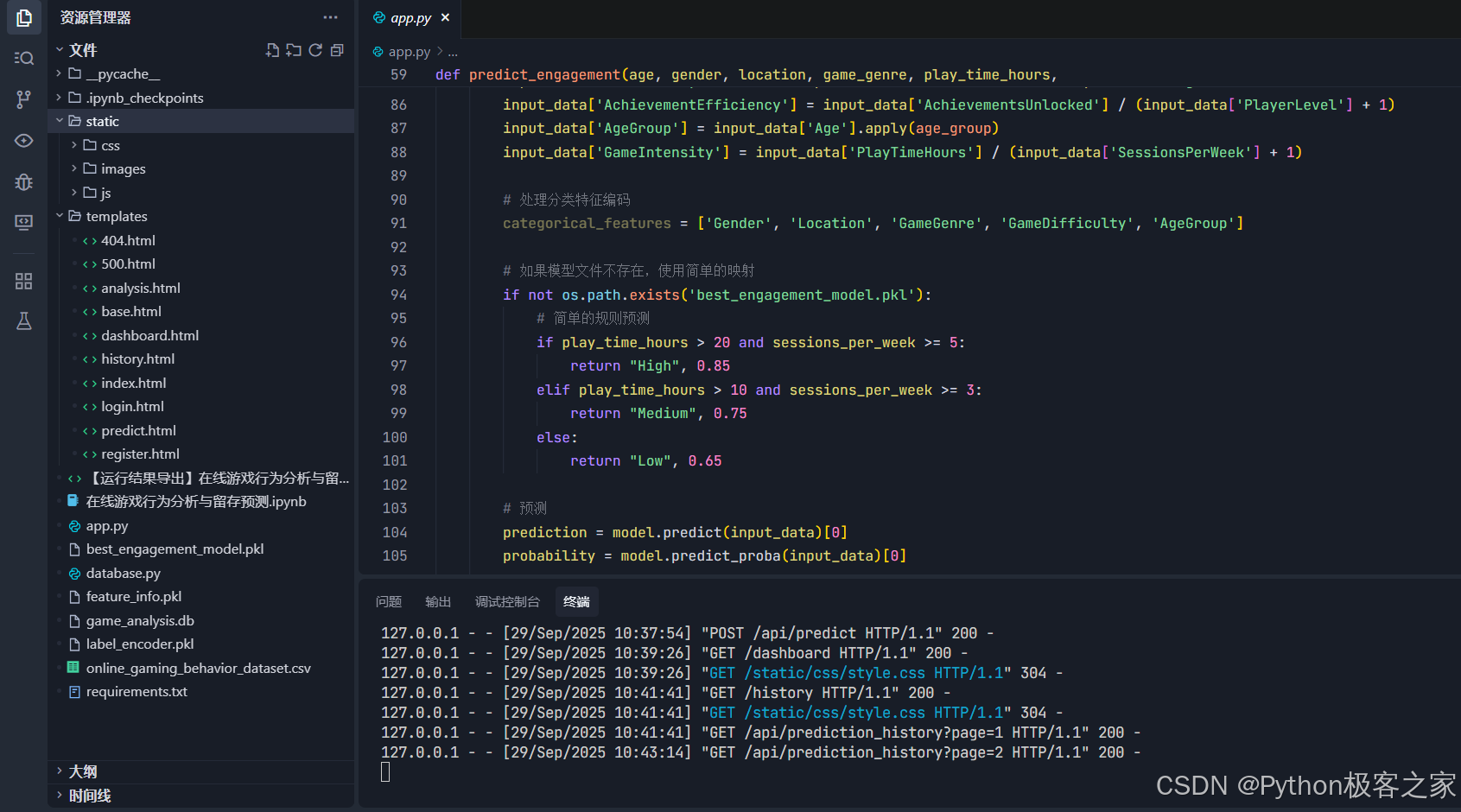
5. 代码架构
6. 总结
本项目旨在开发一个基于数据挖掘的在线游戏行为分析预测系统,利用先进的算法对玩家的行为数据进行分析,预测玩家的行为模式,并提供相应的优化建议。该系统将涵盖数据收集、预处理、特征工程、模型训练、预测和结果展示等多个环节,旨在为游戏开发者和运营团队提供一个全面的玩家行为分析平台。通过该系统,开发者可以更方便地了解玩家的行为习惯,优化游戏设计,提高用户满意度和留存率。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
1. Python 精品项目—数据挖掘篇
2. Python 精品项目—深度学习篇
3. Python 精品项目—管理系统篇
