Django小说个性化推荐系统 双算法(基于用户+物品) 评论收藏 书架管理 协同过滤推荐算法(源码+文档)✅
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机专业毕业设计选题大全(建议收藏)✅
1、项目介绍
- 技术栈:Django框架、双推荐算法(基于用户+基于物品)、书架、评论收藏、小说阅读、MySQL数据库、后台管理
- 这个项目的研究背景:当前数字阅读市场中,小说资源呈海量增长,但传统阅读平台多依赖简单分类推荐,难以精准匹配用户个性化需求,导致用户常陷入“找书难”的困境。同时,用户的阅读记录、收藏偏好等数据未被有效挖掘利用,推荐内容同质化严重,无法满足用户多样化阅读需求,亟需一套整合智能推荐与便捷阅读功能的系统,解决用户找书效率低、体验不佳的问题。
- 这个项目的研究意义:该系统基于Django框架构建,通过双推荐算法(基于用户+基于物品)实现精准推荐——既结合用户历史行为匹配相似偏好,又依据小说内容标签推送契合需求的作品,大幅提升推荐精准度。书架、评论收藏、自定义阅读界面等功能满足用户阅读与互动需求,MySQL保障数据安全,后台管理便于系统维护。系统不仅提升用户阅读体验与满意度,还为小说类平台开发提供技术参考,兼具实用价值与示范意义。
2、项目界面
(1)系统首页
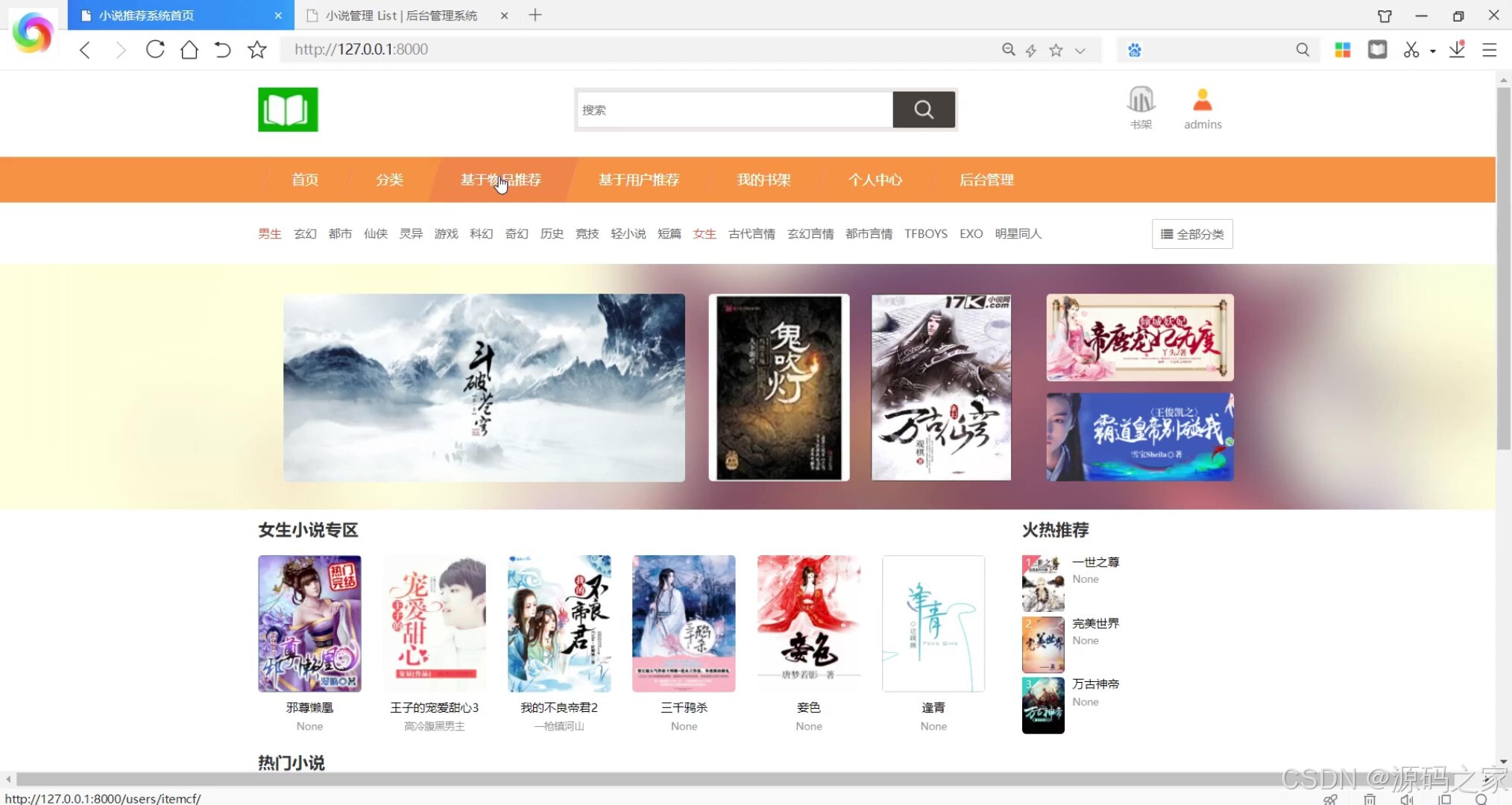
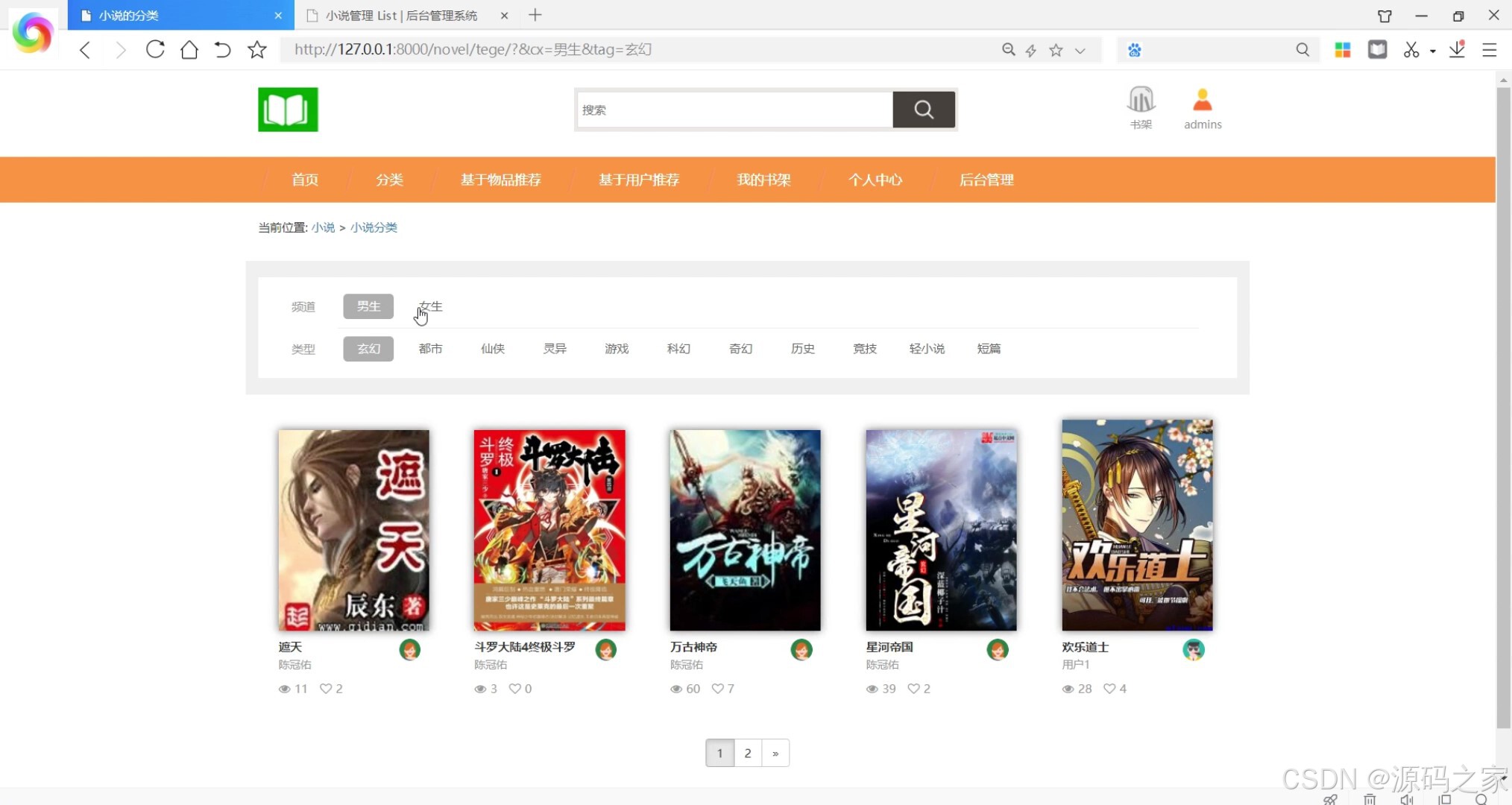
(2)小说分类浏览
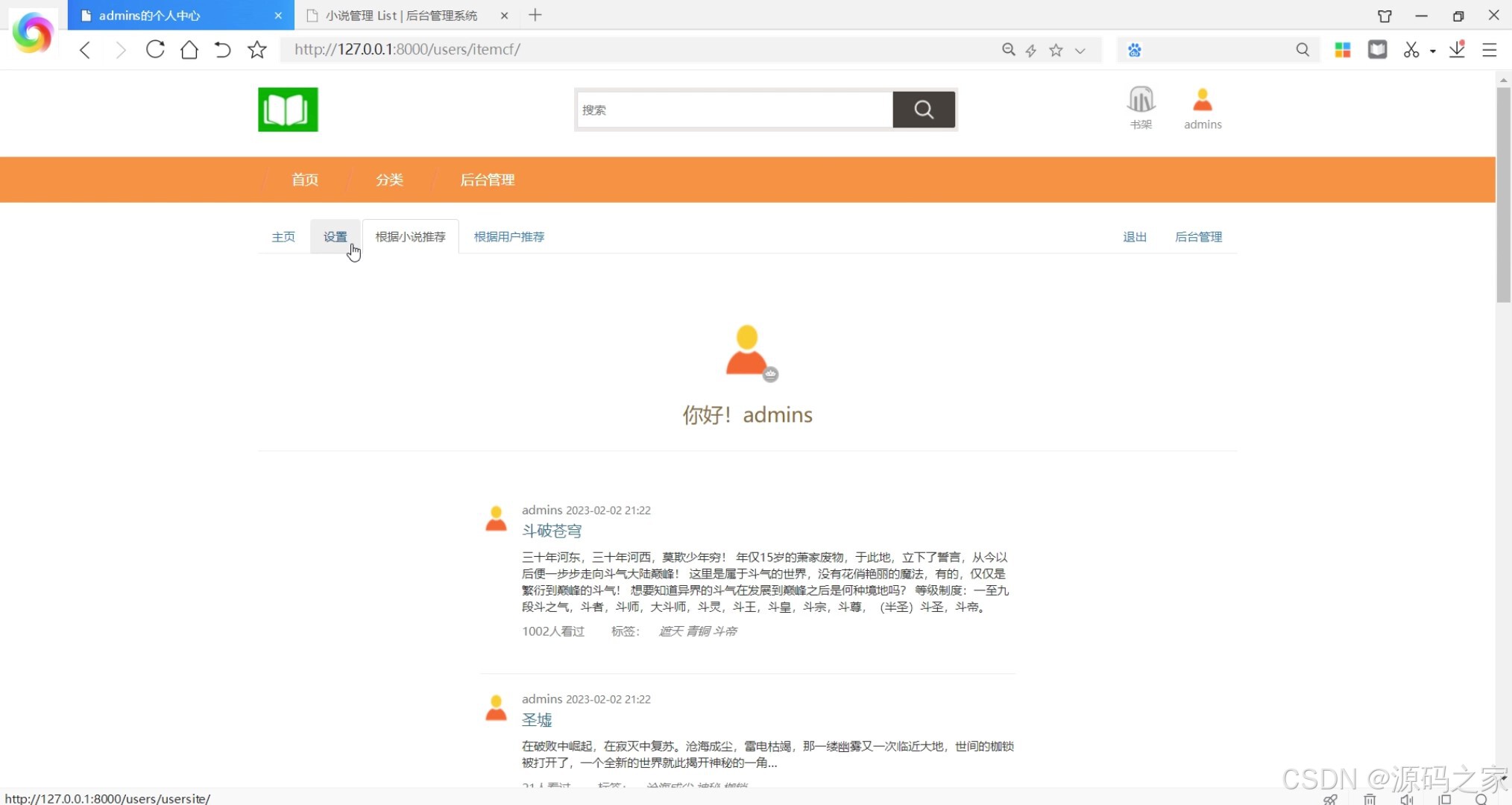
(3)根据小说推荐
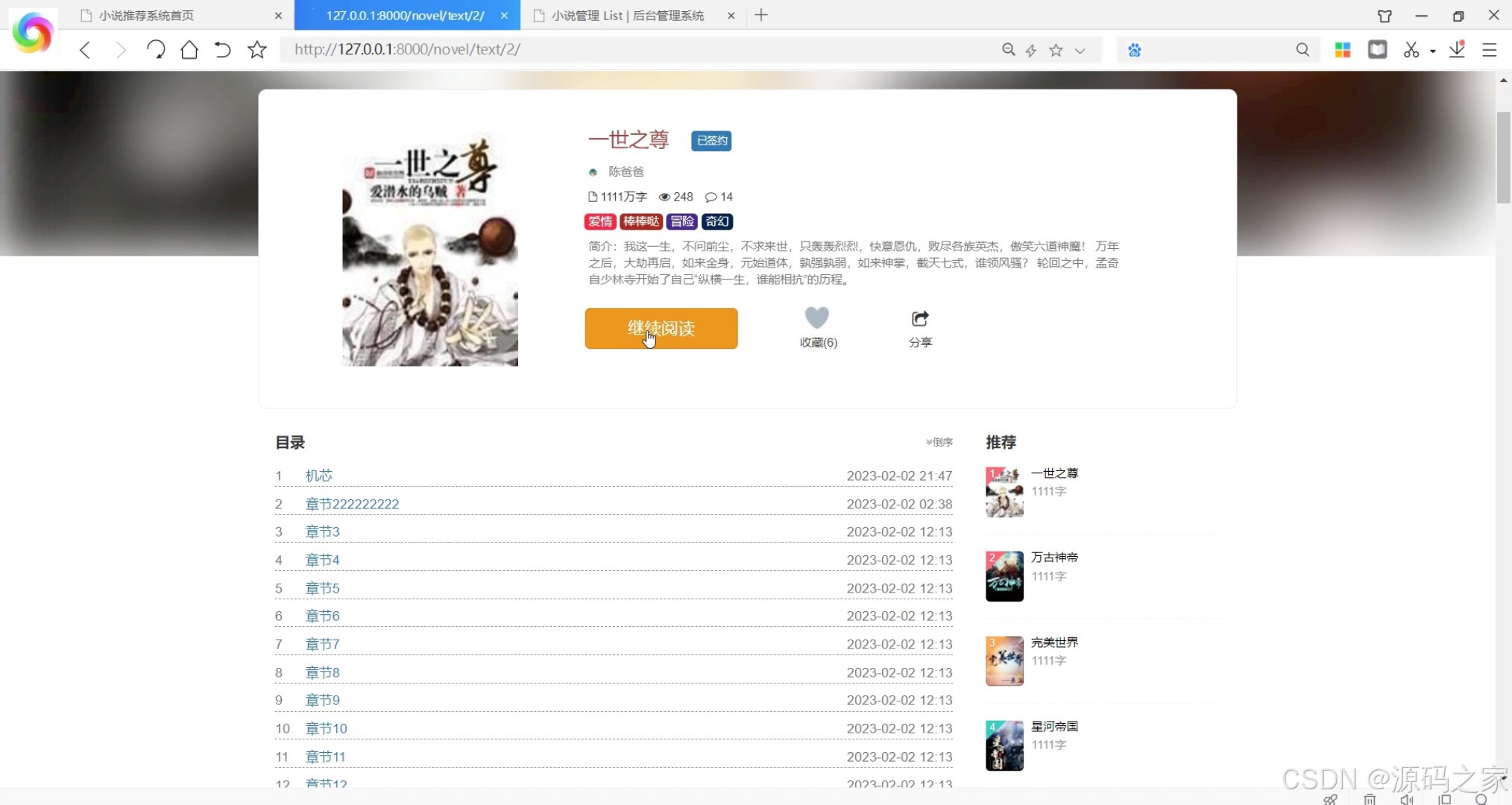
(4)小说数据详情
(5)小说浏览阅读
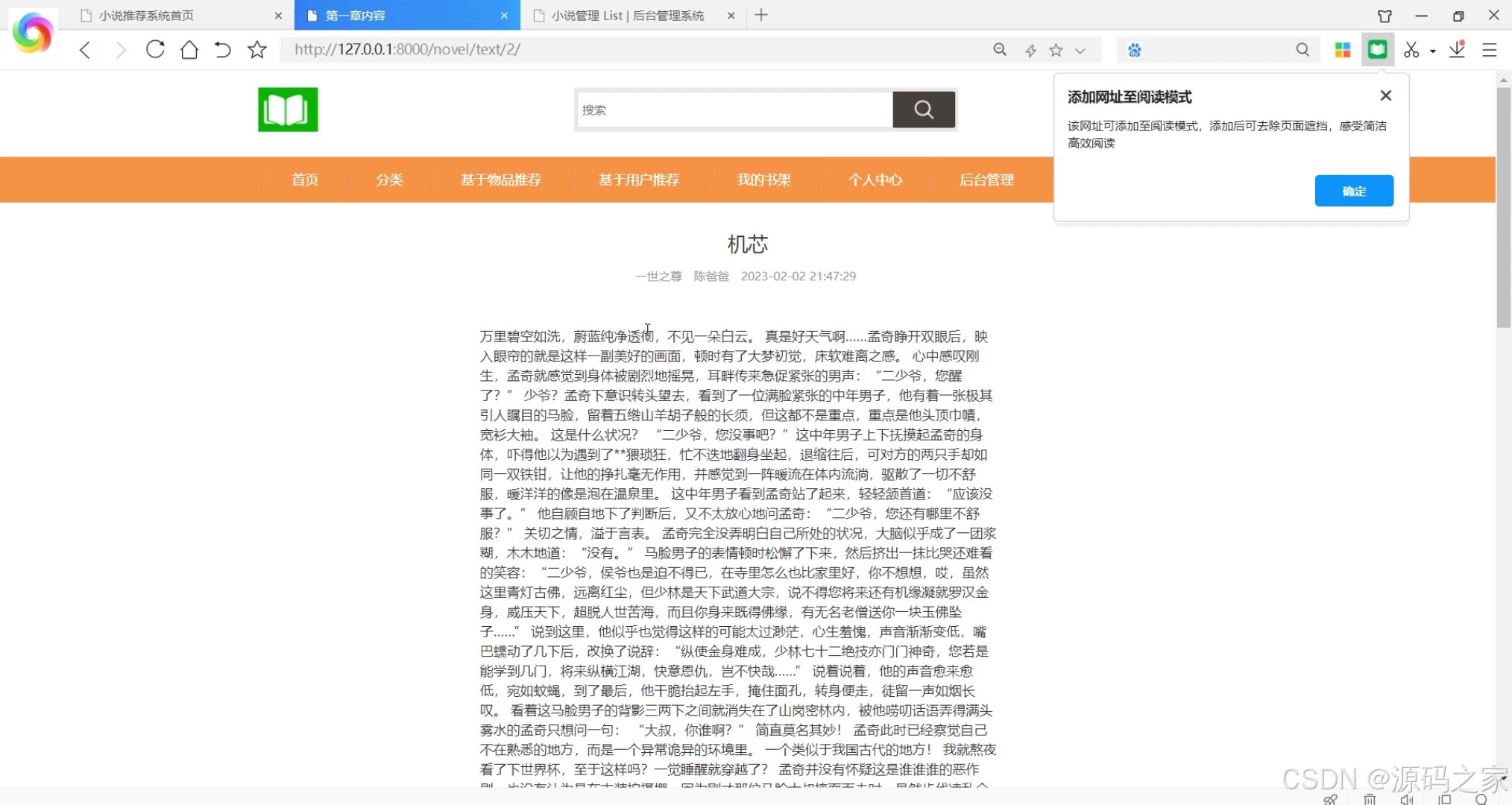
(6)阅读记录
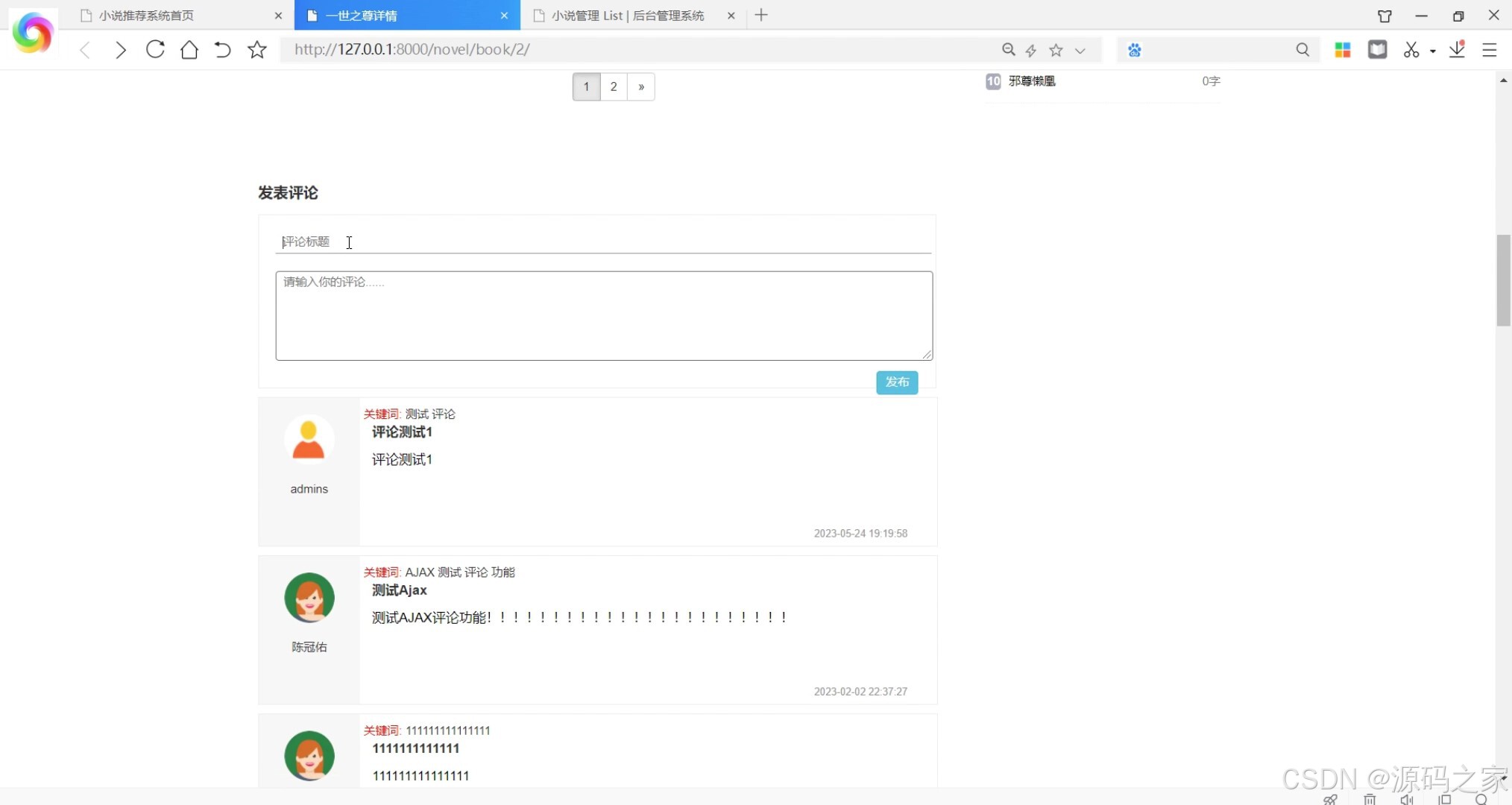
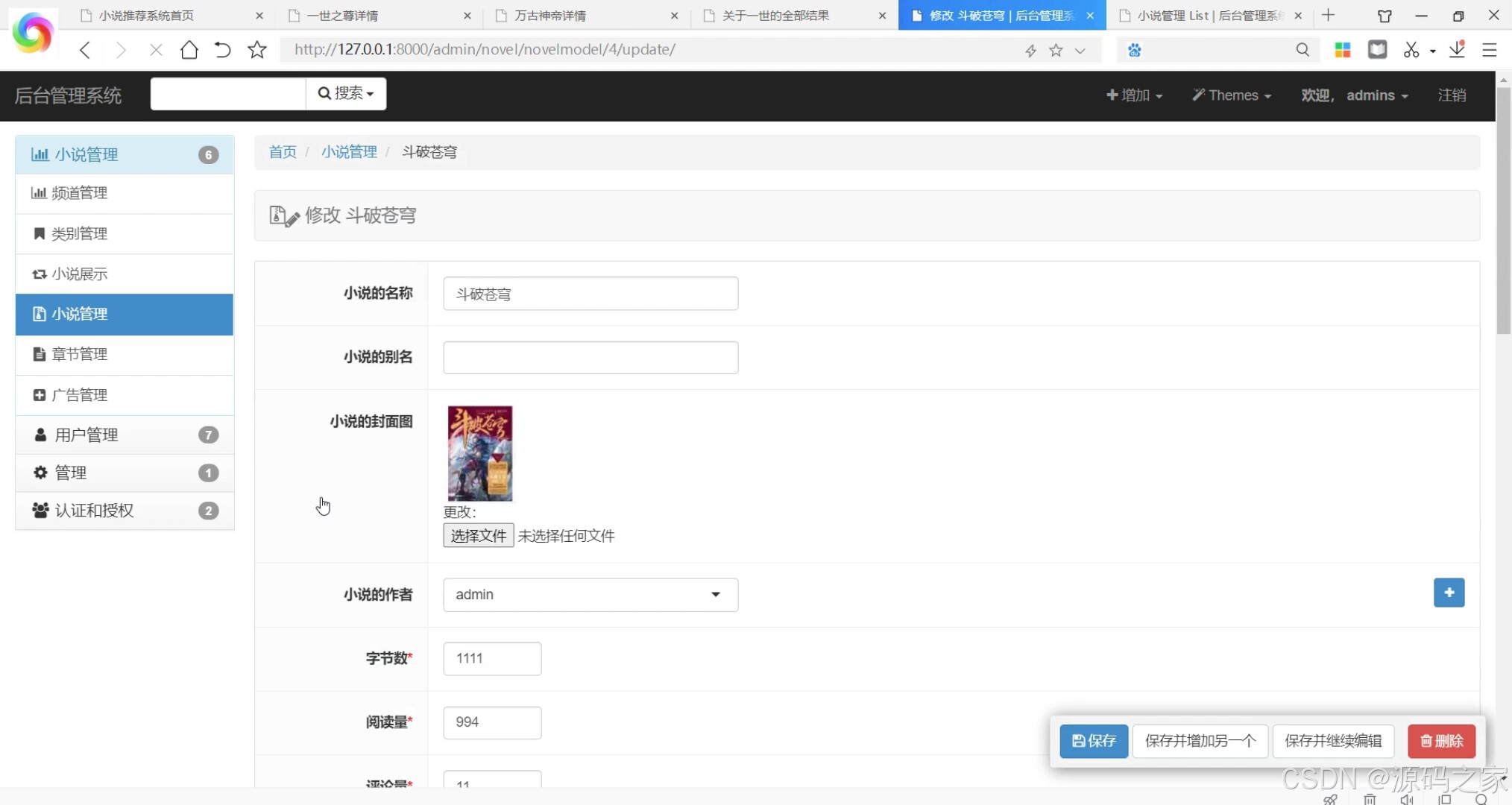
(7)后台数据管理
3、项目说明
本小说推荐系统以Django框架为开发核心,依托MySQL数据库实现数据存储,通过双推荐算法(基于用户+基于物品)构建核心推荐能力,同时整合书架、评论收藏、在线阅读及后台管理等功能,形成覆盖用户“找书-阅读-互动-管理”全流程的服务体系,旨在解决传统小说平台推荐精准度低、用户体验不佳的问题。
从用户使用场景来看,系统提供多样化的小说获取方式:用户可通过“小说分类浏览”模块按类型快速定位兴趣内容,也能接收系统的个性化推荐——基于用户的算法会分析用户历史阅读行为,推送与相似用户喜好相符的小说;基于物品的算法则依据小说内容、标签等信息,匹配用户潜在兴趣作品,双重推荐机制大幅提升内容匹配度。找到目标小说后,用户可进入“小说数据详情”页了解完整信息,随后进入“小说浏览阅读”界面在线阅读,并能根据个人偏好自定义阅读界面风格,优化阅读体验;若对小说感兴趣,可添加至“书架”方便后续随时查阅,阅读后还能发表评论或收藏他人优质评论,实现阅读互动。此外,“阅读记录”模块会留存用户阅读轨迹,便于用户回溯过往内容。
从系统管理层面,管理员可通过“后台数据管理”界面,对用户信息、小说资源进行增删改查等维护操作,确保系统数据的准确性与小说资源的时效性;MySQL数据库则稳定存储用户的书架、评论、收藏、阅读记录等数据,保障信息安全不丢失。
整体而言,该系统通过技术与功能的深度融合,既解决了用户在海量小说中精准找书的核心痛点,又通过便捷的阅读与互动功能提升用户粘性,同时为平台运营提供高效的管理工具,具备较强的实际应用价值。
4、核心代码
#!/usr/bin/env python
#-*-coding:utf-8-*-import math
import pdb
#基于小说物品推荐
class ItemBasedCF:def __init__(self):self.readData()# print(self.train)def readData(self):from connect_mysql import ConnectMysql# root 后面 修改自己的密码con = ConnectMysql('localhost', 3306, 'root', '123456', 'novel_recommend')# 查询# 收藏sql = 'SELECT * FROM Collections;'shoucang = con.query(sql, None)# 阅读sql = 'SELECT * FROM ReadNovel;'read = con.query(sql, None)# 评论CommentModelssql = 'SELECT * FROM CommentModels;'comment = con.query(sql, None)############################### 开始统计用户评分id表# 收藏5 阅读 3 评论(1多个) 比例# 统计用户iduser_item = {}for i in shoucang: # 3 2if str(i[3]) not in user_item.keys():user_item[str(i[3])] = {}user_item[str(i[3])][str(i[2])] = 5else:user_item[str(i[3])][str(i[2])] = user_item[str(i[3])].get(str(i[2]), 0) + 5for i in read: # 1 2if str(i[1]) not in user_item.keys():user_item[str(i[1])] = {}user_item[str(i[1])][str(i[2])] = 3else:user_item[str(i[1])][str(i[2])] = user_item[str(i[1])].get(str(i[2]), 0) + 3for i in comment:if str(i[1]) not in user_item.keys():user_item[str(i[1])] = {}user_item[str(i[1])][str(i[2])] = 1else:user_item[str(i[1])][str(i[2])] = user_item[str(i[1])].get(str(i[2]), 0) + 1self.train = user_itemdef ItemSimilarity(self):#建立物品-物品的共现矩阵cooccur = dict() #物品-物品的共现矩阵buy = dict() #物品被多少个不同用户购买Nfor user,items in self.train.items():for i in items.keys():buy.setdefault(i,0)buy[i] += 1cooccur.setdefault(i,{})for j in items.keys():if i == j : continuecooccur[i].setdefault(j,0)cooccur[i][j] += 1#计算相似度矩阵self.similar = dict()for i,related_items in cooccur.items():self.similar.setdefault(i,{})for j,cij in related_items.items():self.similar[i][j] = cij / (math.sqrt(buy[i] * buy[j]))return self.similar#给用户user推荐,前K个相关用户,前N个物品def Recommend(self,user,K=10,N=10):rank = dict()action_item = self.train[user] #用户user产生过行为的item和评分for item,score in action_item.items():sortedItems = sorted(self.similar[item].items(),key=lambda x:x[1],reverse=True)[0:K]for j,wj in sortedItems:if j in action_item.keys():continuerank.setdefault(j,0)rank[j] += score * wjreturn dict(sorted(rank.items(),key=lambda x:x[1],reverse=True)[0:N])#声明一个ItemBasedCF的对象
# item = ItemBasedCF()
# item.ItemSimilarity()
# recommedDict = item.Recommend("3")#参数为用户id
# for k,v in recommedDict.items():
# print(k,"\t",v)🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻