数据结构 排序(3)---交换排序
交换排序
交换排序的基本思想
所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置
交换排序的特点是:将值较大的向序列的尾部移动,值较小的向序列的前部移动
交换排序的核心思想是通过比较元素键值的大小,交换不符合顺序的元素位置,从而逐步将数据排列成有序序列。它的核心逻辑围绕“交换”操作展开,典型的两种实现是冒泡排序和快速排序,我们可以从这两种算法来深入理解交换排序的思想。
简单来说,交换排序就像在整理一堆打乱的积木,要么“相邻积木两两比对,把大的往后挪”(冒泡),要么“先选一个参照积木,把小的放左边、大的放右边,再分别整理左右两堆”(快排),最终让所有积木按顺序排列。
冒泡排序
冒泡排序的思想是相邻元素两两比较,若顺序不符则交换,每一轮都会让一个“较大的元素”像气泡一样“浮”到数组尾部。
以升序为例,第1轮遍历数组,比较相邻元素(如 a[0] 和 a[1] 、 a[1] 和 a[2] ……),若前一个元素大于后一个,就交换它们的位置。这一轮结束后,数组中最大的元素会被移动到最后一位;第2轮遍历剩下的元素(不包含已排好的最后一位),重复上述过程,将第二大的元素移动到倒数第二位……以此类推,直到所有元素有序。通过相邻元素的直接交换,把“大元素”逐步推到正确位置,每一轮确定一个元素的最终位置。
void swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}
void BubbleSort(int* a, int n)
{int exchange = 0;for (int i = 0; i < n; i++){for (int j = 0; j <n-i-1 ; j++){if (a[j] > a[j + 1]){exchange = 1;swap(&a[j] , &a[j + 1]);}}if (exchange == 0){break;}}
}1. 变量与循环结构
- exchange 变量:用于标记某一轮是否发生了元素交换。如果某一轮没有交换,说明数组已经有序,可以提前终止排序,优化效率。
- 外层循环 for (int i = 0; i < n; i++) :控制排序的轮数。每一轮会将一个较大的元素“冒泡”到数组末尾,因此轮数最多为 n 次(但实际常因提前有序而终止)。
- 内层循环 for (int j = 0; j < n - i - 1; j++) :控制每一轮中相邻元素的比较次数。随着轮数 i 的增加, n - i - 1 会减小,因为每一轮结束后,数组末尾已经有 i 个元素是有序的,无需再比较。
2. 比较与交换逻辑
- if (a[j] > a[j + 1]) :比较当前元素 a[j] 和下一个元素 a[j + 1] ,如果前者大于后者,说明顺序不符合升序要求。
- 当满足上述条件时,将 exchange 设为 1 (表示本轮发生了交换),并通过 swap 函数交换 a[j] 和 a[j + 1] 的位置,让较大的元素向后移动。
3. 提前终止优化
- 内层循环结束后,判断 exchange 是否为 0 。如果为 0 ,说明本轮没有发生任何交换,数组已经整体有序,因此可以通过 break 语句直接跳出外层循环,提前结束排序过程。
时间复杂度
- 最坏情况:数组完全逆序。此时每一轮都需要进行比较和交换,时间复杂度为 O(n^2)。
- 最好情况:数组已经有序。此时内层循环中不会发生交换, exchange 变量保持为 0,外层循环只执行 1 轮就提前终止,时间复杂度为 O(n)。
- 平均情况:需要对各种可能的输入情况取平均,最终时间复杂度为 O(n^2)。
空间复杂度
- 冒泡排序是原地排序,仅使用了常数个额外变量(如 exchange 、循环变量 i 和 j 等),因此空间复杂度为 O(1)。
简单总结:冒泡排序的时间复杂度在最坏和平均情况下是 O(n^2),最好情况是 O(n);空间复杂度是 O(1)。
总结来说,这段代码的思路是“多轮相邻比较-交换”+“提前终止优化”:每一轮让相邻的大元素逐步“冒泡”到末尾,同时通过 exchange 标记避免对已有序数组的无效遍历,最终实现数组的升序排列。
快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
快速排序是交换排序中更高效的算法,它结合了分治思想和基准交换策略:
执行过程:
- ① 选基准:从数组中选一个元素作为“基准值”(如选第一个元素、最后一个元素或随机元素);
- ② 分区交换:将数组中小于基准值的元素移到基准值左边,大于基准值的元素移到右边(过程中通过交换实现位置调整);
- ③ 递归处理:对基准值左右两个子数组,重复步骤①和②,直到子数组长度为1(天然有序)。
核心逻辑体现:通过一次分区交换,将基准值放到最终位置,并把数组分成“左小右大”的两个子区间,再递归处理子区间,实现高效排序。
//快速排序
void QuickSort(int* a, int left, int right)
{if (left >= right) {return;}//_QuickSort用于按照基准值将区间[left,right)中的元素进行划分int meet = _QuickSort(a, left, right);QuickSort(a, left, meet - 1);QuickSort(a, meet + 1, right);
}要理解这个快速排序的主框架,我们可以逐行拆解其逻辑:
1. 函数定义与边界条件
void QuickSort(int* a, int left, int right)
{if (left >= right) {return;}
- QuickSort 是快速排序的入口函数,参数 a 是待排序数组, left 和 right 是当前排序区间的左右边界(闭区间)。
- 边界条件 if (left >= right) :当区间内只有1个元素( left == right )或无元素( left > right )时,无需排序,直接返回。
2. 分区操作与递归排序
int meet = _QuickSort(a, left, right);QuickSort(a, left, meet - 1);QuickSort(a, meet + 1, right);
}
- _QuickSort 分区函数:它的作用是选一个基准元素,把区间 [left, right] 里的元素分成两部分——左边都小于等于基准,右边都大于等于基准,最后返回基准元素的最终位置 meet 。(这一步是快速排序的核心,常见实现有“挖坑法”“前后指针法”“左右指针法”等)
- 递归处理子区间:
- 对基准左边的区间 [left, meet - 1] 递归调用 QuickSort ;
- 对基准右边的区间 [meet + 1, right] 递归调用 QuickSort ;
直到所有子区间都被排序,整个数组就有序了。
快速排序的核心思想总结 :
- 快速排序是分治法的典型应用:先选一个“基准”,把数组分成“小的在左、大的在右”的两个子数组,再对这两个子数组递归做同样的操作,最终让整个数组有序。这个主框架清晰地体现了“分区 + 递归”的核心逻辑,而具体的分区规则则由 _QuickSort 函数的实现细节决定。
将区间中的元素进行划分的_QuickSort方法主要有以下几种实现方式 , 我们先来看第一种找基准值的方案:
版本一 : hoare版本
算法思路:
- 创建左右指针,确定基准值
- 从右向左找出比基准值小的数据,从左向右找出比基准值大的数据,左右指针数据交换,进入下次循环
代码:
int _QuickSort1(int* arr, int left, int right)
{int keyi = left;++left;while (left <= right){//right:从右往左走,找比基准值要小的while (left <= right && arr[right] > arr[keyi]){right--;}//left:从左往右走,找比基准值要大的while (left <= right && arr[left] < arr[keyi]){left++;}//right left if (left <= right){Swap(&arr[left++], &arr[right--]);}}Swap(&arr[keyi], &arr[right]);return right;
}1. 变量与初始化
- keyi = left :选择区间最左侧的元素作为基准值 key , keyi 是其索引。
- ++left :左指针从基准值的下一个位置开始扫描(因为基准值已经作为比较的“参照”,无需再扫描自己)。
2. 外层循环:控制分区的范围
- while (left <= right) :只要左指针 left 不超过右指针 right ,就持续进行“找元素+交换”的操作,直到区间被分割完毕。
3. 内层两个 while 循环:双指针扫描
右指针扫描:while (left <= right && arr[right] > arr[keyi]) { right--; }
- 右指针 right 从右往左找第一个小于基准值 arr[keyi] 的元素。如果 arr[right] 大于基准值,就继续左移 right 。
左指针扫描:
while (left <= right && arr[left] < arr[keyi]) { left++; }
- 左指针 left 从左往右找第一个大于基准值 arr[keyi] 的元素。如果 arr[left] 小于基准值,就继续右移 left 。
4. 交换元素与循环终止
if (left <= right) { Swap(&arr[left++], &arr[right--]); }
- 当左右指针都找到符合条件的元素(右小、左大),就交换这两个元素的位置,然后 left 右移、 right 左移,继续下一轮扫描。
- 当 left > right 时,外层循环终止。此时执行 Swap(&arr[keyi], &arr[right]); ,将基准值 arr[keyi] 与 right 位置的元素交换,让基准值归位到“左区全≤基准、右区全≥基准”的分界点。
- return right; :返回基准值的最终索引,用于后续递归调用(对 [left, right-1] 和 [right+1, 原right] 区间继续快速排序)。
通过双指针交替扫描+交换的方式,将数组区间 [原left, 原right] 分割为“左半区≤基准值、右半区≥基准值”的两部分,并让基准值落在分界点上。整个过程体现了快速排序“分治+分区”的核心思想,是 Hoare 版本分区逻辑的经典实现
问题1:为什么跳出循环后right位置的值一定不大于key?
- 当left > right时,即right走到left的左侧,而left扫描过的数据均不大于key,因此right此时指向的数据一定不大于key
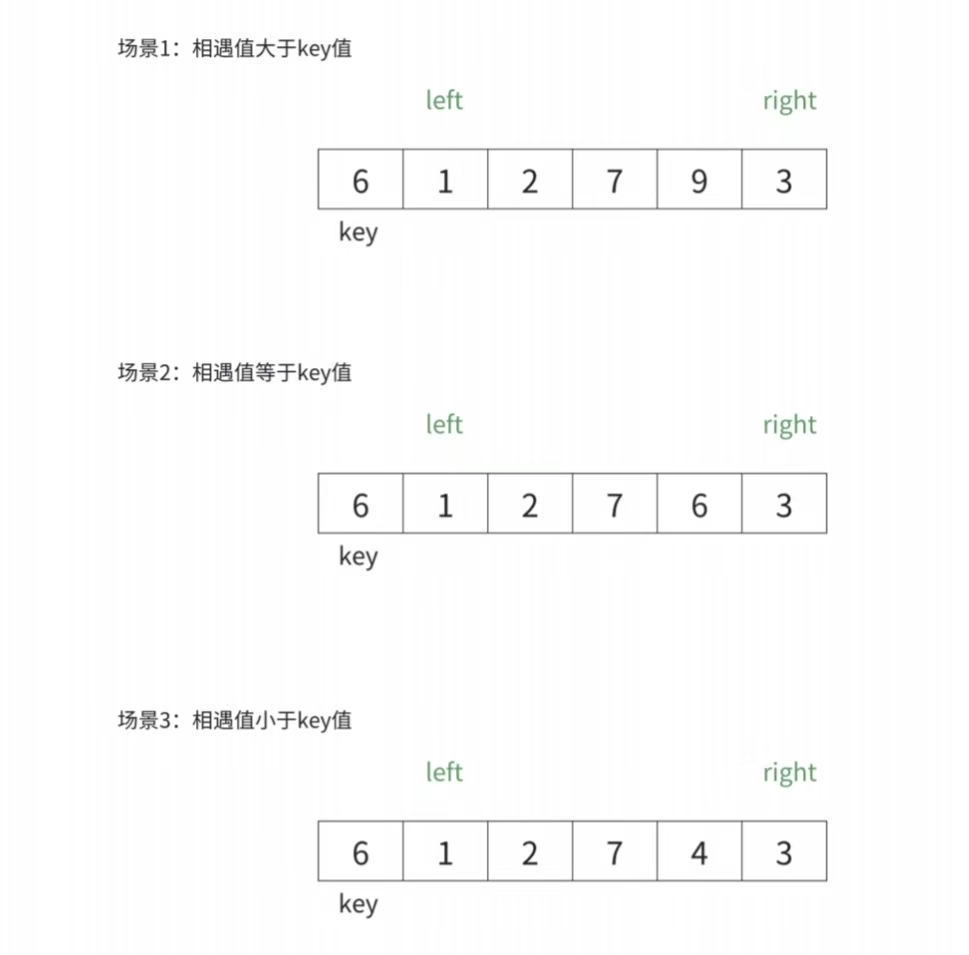
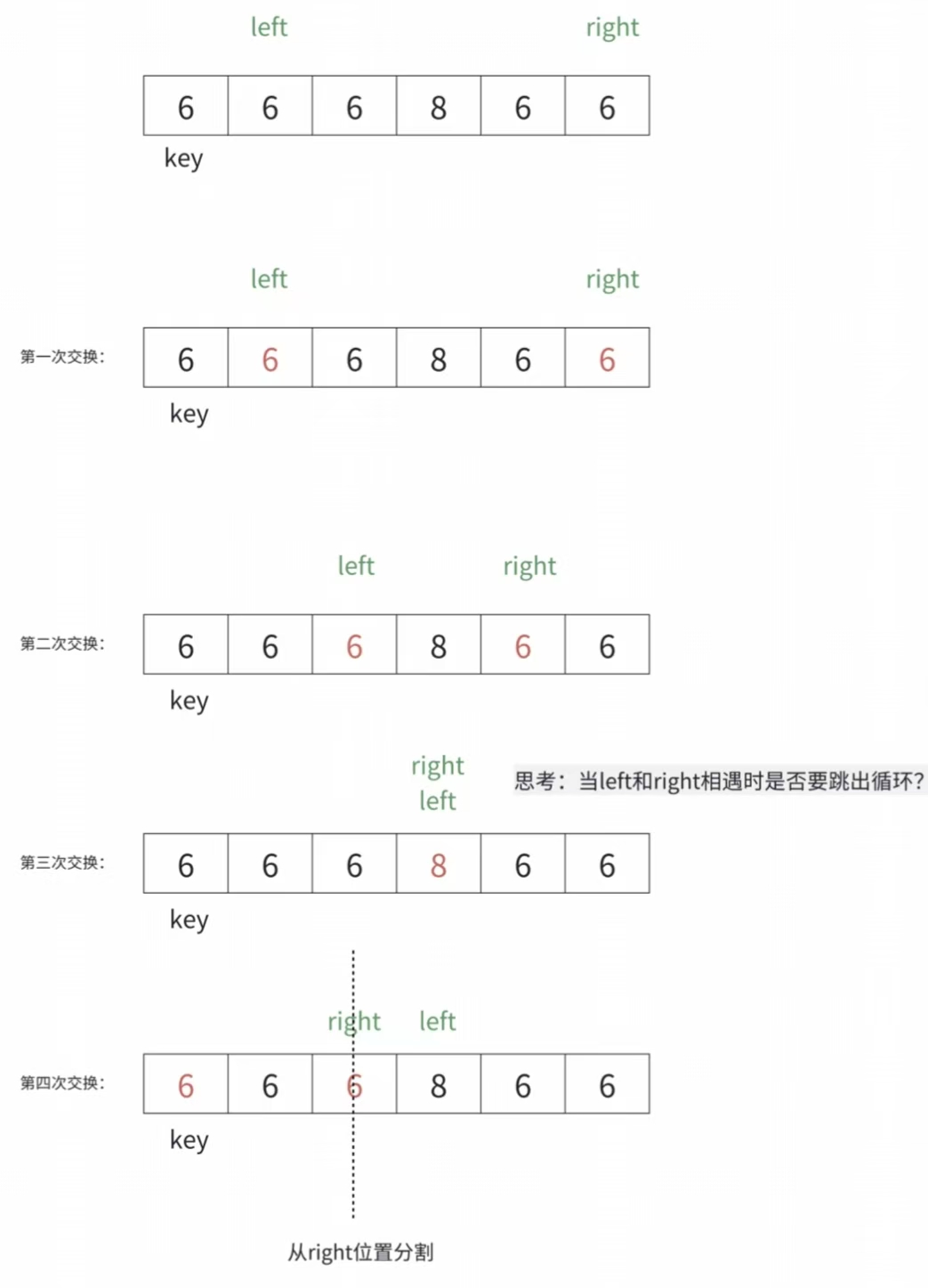
问题2:为什么left和right指定的数据和key值相等时也要交换?
- 相等的值参与交换确实有一些额外消耗。实际还有各种复杂的场景,假设数组中的数据大量重复时,无法进行有效的分割排序。
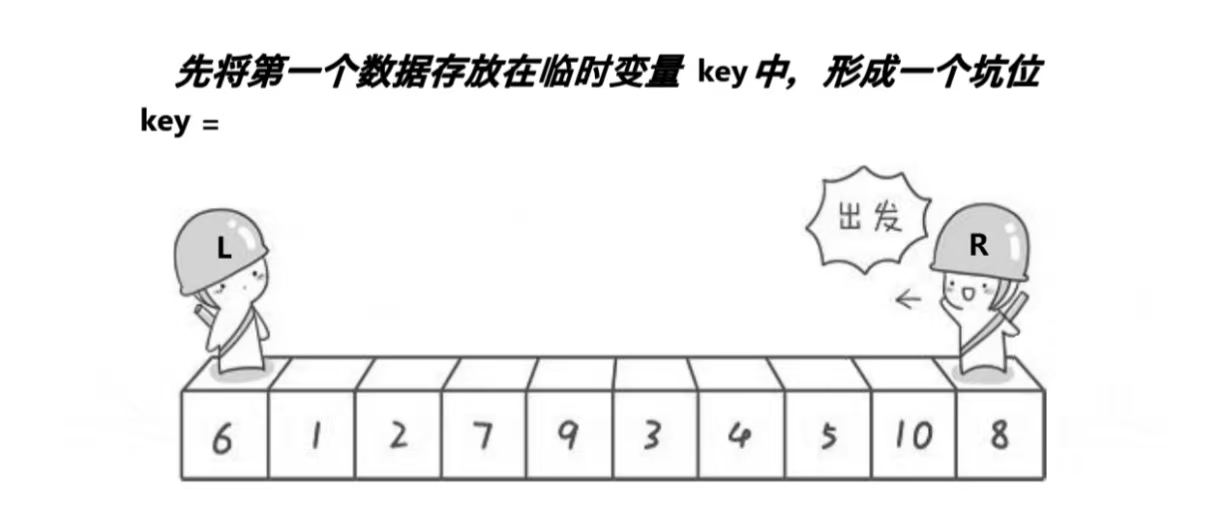
版本二 : 挖坑法
思路:
- 创建左右指针。首先从右向左找出比基准小的数据,找到后立即放入左边坑中,当前位置变为新的"坑",然后从左向右找出比基准大的数据,找到后立即放入右边坑中,当前位置变为新的"坑",结束循环后将最开始存储的分界值放入当前的"坑"中,返回当前"坑"下标(即分界值下标)
挖坑法的本质是通过“挖空-填坑-形成新坑”的循环,将数组划分为“左≤基准,右≥基准”的两个区域。具体来说:
- 先把基准值“挖走”(存在临时变量),形成第一个“坑”;
- 从右往左找小于基准的元素,填入左边的坑,右边形成新坑;
- 从左往右找大于基准的元素,填入右边的坑,左边形成新坑;
- 循环直到左右指针相遇,将基准值填入最终的坑,完成分区。
int _QuickSort(int* a, int left, int right)
{int mid = a[left]; // 存储基准值(也可直接用key,这里命名为mid更直观)int hole = left; // 初始“坑”的位置:基准值的原始位置int key = a[hole]; // 把基准值存入key,相当于“挖走”基准,hole变为空坑while (left < right) // 只要左右指针不相遇,就持续分区{// 右指针左移:找小于key的元素while (left < right && a[right] >= key){--right;}// 找到后,把右指针的元素填入“坑”中,right位置变成新的“坑”a[hole] = a[right];hole = right;// 左指针右移:找大于key的元素while (left < right && a[left] <= key){++left;}// 找到后,把左指针的元素填入“坑”中,left位置变成新的“坑”a[hole] = a[left];hole = left;}// 循环结束(left==right),将基准值key填入最终的“坑”a[hole] = key;return hole; // 返回基准值的最终位置,用于后续递归
}示例(以数组 [6, 1, 2, 7, 9, 3, 4, 5, 10, 8] 为例)
- 1. 初始状态: key=6 (基准值), hole=0 (第一个坑), left=0 , right=9 。
- 2. 右指针找小: right 从9左移,找到 a[5]=3 (小于6),将 a[5] 填入 hole=0 ,数组变为 [3, 1, 2, 7, 9, 3, 4, 5, 10, 8] ,新坑 hole=5 。
- 3. 左指针找大: left 从0右移,找到 a[3]=7 (大于6),将 a[3] 填入 hole=5 ,数组变为 [3, 1, 2, 7, 9, 7, 4, 5, 10, 8] ,新坑 hole=3 。
- 4. 循环继续:右指针从5左移,找到 a[2]=2 (小于6),填入 hole=3 ,新坑 hole=2 ;左指针从3右移,找到 a[4]=9 (大于6),填入 hole=2 ,新坑 hole=4 ……
- 5. 最终归位:当 left==right 时,将 key=6 填入最终的坑,数组被划分为 [3, 1, 2, 5, 4, 6, 7, 9, 10, 8] ,基准值6的位置 hole=5 就是分区的分界点。
挖坑法的逻辑更直观(通过“坑”的转移可视化分区过程),且在实现时不需要额外的交换函数(直接通过“填坑”完成元素移动),是快速排序分区的经典方法之一。
版本三 : lomuto前后指针法
创建前后指针,从左往右找比基准值小的进行交换,使得小的都排在基准值的左边。

int _QuickSort(int* arr, int left, int right)
{int keyi = left;int prev = left, cur = prev + 1;while (cur <= right){if (arr[cur] < arr[keyi] && ++prev != cur){Swap(&arr[prev], &arr[cur]);}cur++;}Swap(&arr[keyi], &arr[prev]);return prev;
}1. 指针与基准值定义
- keyi = left :选择区间最左侧的元素作为基准值 key , keyi 是其索引。
- prev = left : prev 指针初始指向区间起始位置,用于标记“小于基准值的区域边界”。
- cur = prev + 1 : cur 指针从 prev 的下一个位置开始扫描,负责遍历整个区间。
2. 循环逻辑:遍历并分区
while (cur <= right) : cur 指针从左到右遍历整个区间 [left+1, right] ,过程中通过判断和交换,将“小于基准值的元素”聚集到 prev 指针左侧。
- 条件判断 if (arr[cur] < arr[keyi] && ++prev != cur) :
- 若 arr[cur] < arr[keyi] (当前元素小于基准值),则 prev 右移一位( ++prev ),标记新的“小于区域”边界。
- 若 ++prev != cur (说明 prev 和 cur 不重叠,即存在“大于基准值的元素”在中间),则交换 arr[prev] 和 arr[cur] ,将“小于基准的元素”移到 prev 左侧。
- cur++ : cur 指针继续右移,遍历下一个元素。
3. 基准值归位
循环结束后, prev 指针指向“小于基准值的区域的最右端”。此时执行 Swap(&arr[keyi], &arr[prev]) ,将基准值 arr[keyi] 与 prev 位置的元素交换,使得:
- 基准值左边的元素全部小于基准值;
- 基准值右边的元素全部大于等于基准值。
Lomuto版本通过 prev (边界指针)和 cur (遍历指针)的配合,在一次遍历中完成分区: cur 负责扫描元素, prev 负责标记“小于基准值的区域边界”,最终让基准值归位到正确的分界点。这种方法逻辑简洁,是快速排序分区的经典实现之一
复杂度总结:
时间复杂度
- 最优情况:每次分区都能将数组均匀分成两部分,时间复杂度为 O(nlog n) 。此时递归树的深度为 log2 n ,每层需要遍历 n 个元素,总操作次数为 nlog n 量级。
- 最差情况:数组完全有序或完全逆序,每次分区只能将数组分成“1个元素”和“ n-1 个元素”两部分,时间复杂度退化为 O(n^2) 。例如对已排序数组 [1,2,3,4,5] 以最左元素为基准时,每次递归仅减少1个元素,总操作次数为 n+(n-1)+......+1 = (n(n+1))/2。
- 平均情况:基于随机化基准选择(或三数取中等优化),时间复杂度稳定为 O(nlog n) ,这也是快速排序在实际应用中高效的核心原因。
空间复杂度
- 快速排序的空间复杂度由递归调用栈的深度决定:
- 最优/平均情况:递归树深度为 log n ,空间复杂度为 O(\log n) 。
- 最差情况:递归树退化为单链,深度为 n ,空间复杂度为 O(n) 。
若采用非递归实现(借助栈模拟递归),空间复杂度与递归深度一致,结论同上。
版本四 : 非递归版本的快速排序
非递归版本的快速排序需要借助数据结构: 栈
//非递归版本的快速排序——栈
void QuicSortNoR(int* arr, int left, int right)
{ST st;StackInit(&st);StackPush(&st, left);StackPush(&st, right);while (!StackEmpty(&st)){//取栈顶两次int end = StackTop(&st);StackPop(&st);int begin = StackTop(&st);StackPop(&st);//[begin,end]找基准值int keyi = begin;int prev = begin, cur = prev + 1;while (cur <= end){if (arr[cur] < arr[keyi] && ++prev != cur){Swap(&arr[prev], &arr[cur]);}cur++;}Swap(&arr[keyi], &arr[prev]);keyi = prev;//begin keyi end//左序列:[begin,keyi-1] 右序列:[keyi+1,end];if (keyi + 1 < end){StackPush(&st, keyi + 1);StackPush(&st, end);}if (begin < keyi - 1){StackPush(&st, begin);StackPush(&st, keyi - 1);}}StackDestroy(&st);
}
1. 栈的作用
用栈存储待排序区间的左右边界( begin 和 end ),替代递归调用时的函数栈帧,从而实现“分治”排序。
2. 代码步骤拆解
(1)初始化与压栈
ST st;
StackInit(&st);
StackPush(&st, left);
StackPush(&st, right);- 初始化栈,并将初始排序区间的 left 和 right 压入栈(注意压栈顺序:先压左边界,再压右边界,后续弹出时需对应取)。
(2)循环取区间并排序
while (!StackEmpty(&st))
{int end = StackTop(&st);StackPop(&st);int begin = StackTop(&st);StackPop(&st);- 循环取出栈中的区间边界 begin (左)和 end (右),确定当前待排序的区间 [begin, end] 。
(3)单趟分区(Lomuto前后指针法)
int keyi = begin;
int prev = begin, cur = prev + 1;
while (cur <= end)
{if (arr[cur] < arr[keyi] && ++prev != cur){Swap(&arr[prev], &arr[cur]);}cur++;
}
Swap(&arr[keyi], &arr[prev]);
keyi = prev;- 以区间最左元素 arr[keyi] 为基准,用 prev (边界指针)和 cur (遍历指针)遍历区间:
- 若 arr[cur] < 基准值 ,则 prev 右移,并交换 arr[prev] 和 arr[cur] ,将“小于基准的元素”聚集到 prev 左侧;
- 遍历结束后,交换基准值与 prev 位置的元素,使基准值归位(左边全≤基准,右边全≥基准)。
(4)压入子区间
if (keyi + 1 < end)
{StackPush(&st, keyi + 1);StackPush(&st, end);
}
if (begin < keyi - 1)
{StackPush(&st, begin);StackPush(&st, keyi - 1);
}- 若基准值右侧存在子区间 [keyi+1, end] ,将其边界压入栈;
- 若基准值左侧存在子区间 [begin, keyi-1] ,将其边界压入栈。
(5)销毁栈
StackDestroy(&st);- 排序完成后,销毁栈以释放内存。
3. 核心优势与适用场景
- 优势:避免了递归可能导致的“栈溢出”问题,在对递归深度敏感的场景(如大规模数据排序)中更稳定。
- 复杂度:时间复杂度与递归版一致(平均 O(nlog n) );空间复杂度由栈的深度决定(平均 O(log n) )。
这段代码通过“栈模拟递归+Lomuto分区”的组合,完整实现了快速排序的非递归版本,是理解“递归→非递归转化”和快速排序工程化实现的典型案例。
总结:
交换排序是排序算法中的一种基本方法,通过比较和交换元素实现排序。主要包括冒泡排序和快速排序两种典型算法。冒泡排序通过相邻元素比较和交换,逐步将最大元素移到数组末尾,时间复杂度为O(n²)。快速排序采用分治思想,选取基准值将数组划分为左右子区间,递归排序,平均时间复杂度为O(nlogn)。快速排序有多个实现版本,包括Hoare版本、挖坑法、前后指针法等,非递归实现可使用栈来模拟递归过程。交换排序的核心在于通过元素交换实现排序,不同算法在效率和实现方式上各有特点。
感谢大家的观看!