Web开发 20
1 把这些过滤后的评论返回给前端

1. 标题:TODO-3: GET /api/comment solution
GET:这是 HTTP 协议里的一种请求方法。你可以理解为 “获取”,比如你去图书馆 “获取” 一本书,用GET就是从服务器 “获取” 数据。/api/comment:这是一个接口地址(也叫 “路由”)。想象成你家的门牌号,服务器通过这个 “门牌号”,知道你要找 “评论” 相关的数据。solution:意思是 “解决方案”,说明这行代码是完成 “通过GET /api/comment获取评论” 这个任务的方法。
2. 核心代码部分:const filteredComments = data.comments.filter(...)
const filteredComments:const是声明变量的关键字,意思是 “常量”,也就是这个变量一旦赋值,后面不能再改它的值了。filteredComments是变量名,你可以把它想成一个 “盒子”,专门用来装 “过滤后的评论”。
data.comments:- 假设
data是一个 “大对象”,里面存了很多数据。就像一个 “抽屉柜”,comments是这个柜子里的一个 “抽屉”,这个抽屉里装着所有的评论数据(可能是很多条评论组成的数组)。 filter方法:- 这是 JavaScript 里数组的一个方法,作用是 “过滤” 数组里的元素。比如你有一堆水果(数组),用
filter可以选出 “所有苹果”(过滤条件:是苹果)。 - 它需要接收一个 “函数” 作为参数,这个函数用来定义 “过滤的规则”—— 哪些元素要留下来,哪些要被过滤掉。
- 这是 JavaScript 里数组的一个方法,作用是 “过滤” 数组里的元素。比如你有一堆水果(数组),用
3. 过滤规则的函数:(comment) => comment.parent == req.query.parent
- 这是一个箭头函数(也叫 “胖箭头函数”),是 JavaScript 里定义函数的一种简洁方式。
(comment):- 这里的
comment是函数的 “参数”。你可以理解为,filter方法会把data.comments里的每一条评论,依次传给这个箭头函数,就像老师发试卷,把每一张试卷(每条评论)递给你(箭头函数)。
- 这里的
=>:箭头函数的标志,左边是参数,右边是 “函数要做的事”(函数体)。comment.parent == req.query.parent:这是过滤的 “条件”—— 只有满足这个条件的评论,才会被留在filteredComments里。comment.parent:表示当前这条评论(comment)的 “父评论 ID”(假设parent字段存的是父评论的标识)。req.query.parent:req是 “request” 的缩写,代表 “请求”—— 也就是前端(比如网页、APP)发给服务器的请求。query是 “查询参数”,就是请求里带的一些 “额外信息”。比如你访问http://xxx.com/api/comment?parent=123,这里的?parent=123就是查询参数,req.query.parent拿到的就是123。- 所以整体意思是:只保留 “父评论 ID” 等于 “请求里带的父评论 ID” 的那些评论。
4. 下面的英文解释:get just the comments whose parent is equal to req.query.parent
- 翻译过来就是:“只获取那些
parent(父评论 ID)等于req.query.parent(请求里带的父评论 ID)的评论”。和代码的作用是完全对应的,帮你用更直白的语言理解代码要做什么。
5. 最后的注意事项:Note: we use == instead of === because req.query returns type string, and to compare type int to type string we use ==
==和===的区别:===是 “严格相等”,不仅要值相等,类型也要一样。比如123(数字类型)和"123"(字符串类型),用===比较的话,结果是false(不相等)。==是 “宽松相等”,会自动做类型转换后再比较。比如123(数字)和"123"(字符串),用==比较的话,会把字符串转成数字,然后比较,结果是true(相等)。
- 为什么用
==:- 因为
req.query里拿到的parent是字符串类型(比如请求里是?parent=123,req.query.parent就是"123")。 - 而
comment.parent可能是数字类型(比如数据库里存的父评论 ID 是数字123)。 - 这时候如果用
===,123(数字)和"123"(字符串)类型不一样,就会判断为 “不相等”,导致过滤不到想要的评论。所以用==,让它自动转类型后比较,才能正确匹配。
- 因为
总结一下,这段代码的作用就是:当前端通过 GET /api/comment 这个接口,带着 “父评论 ID” 的查询参数来请求时,服务器从所有评论里,把 “父评论 ID” 符合要求的那些评论过滤出来,放到 filteredComments 这个变量里,后续可能会把这些过滤后的评论返回给前端。
2 API路由未找到

这段代码是在处理API 路由未找到的情况,属于后端开发中接口路由管理的范畴。
一、逐行解释核心代码(假设用的是 Express 框架,router 是路由实例)
router.all("*", (req, res) => {console.log(`API Route not found: ${req.method} ${req.url}`);res.status(404).send({ message: "API Route not found" });
});
router.all("*", ...)router:是路由对象,用来管理一组相关的 API 接口(比如所有/api/开头的接口都由这个router处理)。all:表示 “匹配所有 HTTP 请求方法”(比如 GET、POST、PUT、DELETE 等,不管前端用哪种方法请求,都能匹配到)。"*":是通配符,意思是 “匹配所有未被其他路由明确定义的路径”。比如如果服务器定义了/api/user和/api/post两个路由,但前端请求了/api/order(没定义过的路径),就会走到这个通配符路由里。
回调函数
(req, res) => { ... }req:是 “请求对象”,包含前端请求的所有信息(比如请求方法、请求路径、携带的参数等)。res:是 “响应对象”,用来给前端返回数据、设置状态码等。
console.log(API Route not found: ${req.method} ${req.url});- 作用:在服务器的控制台打印日志,告诉开发者 “有一个未找到的 API 路由请求”。
- 举例:如果前端请求了
GET /api/abc(没定义的路由),控制台会打印API Route not found: GET /api/abc,方便开发者排查问题。
res.status(404).send({ message: "API Route not found" });res.status(404):设置HTTP 状态码为 404(404 是约定俗成的 “资源未找到” 状态码)。send({ message: "API Route not found" }):给前端返回一个 JSON 格式的响应,内容是{ "message": "API Route not found" },让前端知道 “这个接口不存在”。
二、扩展:为什么要 “把这个路由放在所有其他 API 路由的下面”?
代码下方的提示 IMPORTANT: Put this route below all other API routes... 非常关键,原因和 路由的 “匹配顺序” 有关:
- 路由匹配是 **“从上到下依次判断”** 的。
- 假设把这个通配符路由放在最上面,那么所有请求都会先匹配到它(因为 “*” 能匹配一切),哪怕是有效路由(比如
/api/user),也会被当成 “未找到” 处理。 - 正确做法是:先定义 “明确的路由”(比如
/api/user、/api/post),最后再放这个 “兜底的通配符路由”。这样,有效路由会被先匹配到,只有 “真的没定义过的路由” 才会落到通配符路由里。
举个例子:
// 先定义有效路由
router.get("/api/user", (req, res) => {res.send("用户接口");
});router.post("/api/post", (req, res) => {res.send("文章接口");
});// 最后放兜底的“未找到”路由
router.all("*", (req, res) => {res.status(404).send({ message: "API Route not found" });
});
这样,请求 /api/user 会走到 get("/api/user") 里;
请求 /api/abc(没定义)才会走到 all("*") 里返回 404。
三、实际场景中的作用
这个 “兜底路由” 主要是为了增强接口的健壮性和可调试性:
- 对前端来说:如果写错了接口路径,能收到明确的 “404 + 提示信息”,方便排查问题(比如知道是 “路径写错了”,而不是 “服务器内部错误”)。
- 对后端来说:控制台的日志能实时提醒 “有无效请求”,便于开发者发现接口设计的遗漏(比如忘记定义某个必要的路由)。
简单总结:这段代码是给 API 做 “兜底防护”—— 所有没被明确定义的接口请求,都会被它捕获,然后返回 “接口未找到” 的提示,同时在服务器日志里留下记录。
3 API 路由中处理 POST 请求(针对 /api/comment)
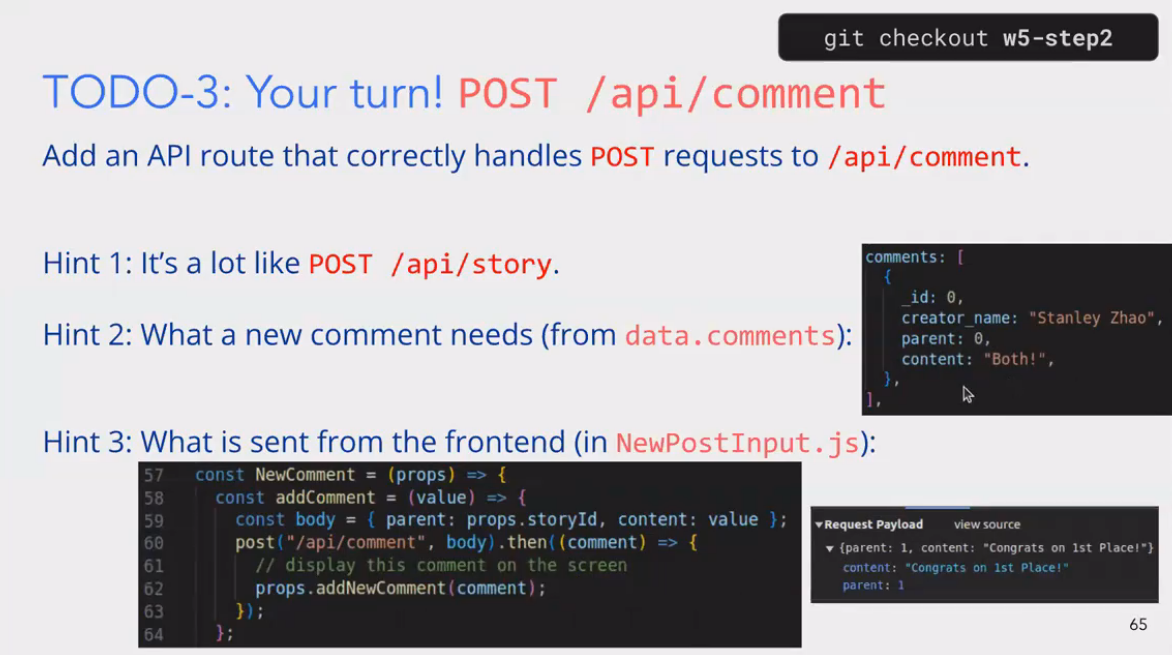
这张图主要围绕API 路由中处理 POST 请求(针对 /api/comment)的任务展开,涉及后端路由设计、前后端数据交互等知识点,以下是详细解析:
1. 任务核心:添加处理 POST /api/comment 的 API 路由
目标是创建一个后端接口,能正确接收并处理前端发送到 /api/comment 的 POST 请求,实现 “新增评论” 的功能。
2. 提示 1:参考 POST /api/story 的逻辑
说明 “处理评论的 POST 路由” 与 “处理故事(story)的 POST 路由”逻辑相似。通常这类路由的流程是:
- 接收前端发送的请求体(包含数据)。
- 对数据进行校验、处理(如存入数据库、生成唯一标识等)。
- 返回处理后的结果(如新增的评论对象)给前端。
3. 提示 2:新评论需要的字段(从 data.comments 结构推断)
右侧代码片段展示了 data.comments 中一条评论的结构:
comments: [{_id: 0,creator_name: "Stanley Zhao",parent: 0,content: "Both!"},// ... 其他评论
]
这说明新增评论需要的字段包括:
_id:评论的唯一标识(通常由后端生成,如自增 ID 或 UUID)。creator_name:评论创建者的名字(可能由用户登录态获取,或前端传递)。parent:评论所属的 “父级”(比如关联的故事 ID,或父评论 ID)。content:评论的内容。
4. 提示 3:前端(NewPostInput.js)发送的数据
下方代码和 “Request Payload” 展示了前端发送的请求体结构:
- 代码中,前端通过
post("/api/comment", body)发送请求,body的结构是{ parent: props.storyId, content: value }(props.storyId是关联的故事 ID,value是评论内容)。 - “Request Payload” 进一步验证:请求体包含
parent(如1)和content(如"Congrats on 1st Place!")。
这说明前端发送给后端的字段是 parent 和 content,而后端需要结合这些字段,补充 _id、creator_name 等信息,生成完整的评论对象。
5. 前后端交互逻辑
- 前端触发 “新增评论” 操作(如用户输入评论并提交),调用
addComment函数。 addComment中,构造请求体{ parent, content },并通过post("/api/comment", body)发送 POST 请求到后端。- 后端接收到请求后,处理数据(如生成
_id、获取creator_name),将新评论存入数据结构(如data.comments),并返回新增的评论对象。 - 前端收到后端返回的
comment后,调用props.addNewComment(comment),将新评论渲染到页面上。
总结
整个任务是前后端协作实现 “新增评论” 功能:前端负责收集并发送评论的核心数据(parent、content),后端负责接收请求、补充评论的完整字段(_id、creator_name 等)并持久化,最终将新评论返回给前端展示。这体现了 API 路由在前后端数据交互中的核心作用。
4 无数据库情况下服务端数据存储的局限性

- 当修改
server.js或api.js时,nodemon会检测到变化并重启服务器。 - 由于数据(
data)只是定义在服务器文件的顶部,仅在服务器运行期间有效,所以服务器重启后,所有新增的帖子和评论都会丢失,比如修改评论后刷新页面,故事(相关数据)就会消失。 - 右侧 “NO DATABASE?” 的表情包也突出了没有数据库来持久化存储数据的问题。
我们可以从数据存储的底层逻辑、无数据库时的替代方案、数据库的核心作用这几个维度来详细扩展:
一、无数据库时,数据 “临时存在” 的底层逻辑
在示例中,data 是直接定义在服务器文件(比如 server.js)顶部的变量,本质是内存中的数据结构(比如 JavaScript 对象、数组)。
- 当服务器运行时,内存会为这些数据分配空间,代码可以正常读写
data(比如新增评论、添加帖子)。 - 但内存的 “存储” 是临时的:一旦服务器进程停止(比如
nodemon重启服务器、服务器意外崩溃),内存会被操作系统回收,data里的内容就会被清空 —— 这就是 “新增内容重启后消失” 的根本原因。
二、无数据库时,“临时存储” 的常见替代方案(用于学习或简单场景)
如果不想用数据库,但又想让数据 “跨重启保留”,可以用文件存储临时替代,核心思路是 “把内存数据写入文件,重启时再从文件读取”。
以 Node.js 为例,简单实现如下:
// 引入 Node.js 的文件系统模块
const fs = require('fs');
// 定义数据存储的文件路径
const DATA_FILE = './data.json';// 初始化数据:优先从文件读取,文件不存在则用默认空对象
let data;
try {// 读取文件内容,转成 JavaScript 对象const fileData = fs.readFileSync(DATA_FILE, 'utf8');data = JSON.parse(fileData);
} catch (err) {// 文件不存在或解析失败,用空对象初始化data = { comments: [], stories: [] };
}// 模拟“新增评论”后,把数据写入文件
function addComment(comment) {data.comments.push(comment);// 把内存中的 data 转成 JSON 字符串,写入文件fs.writeFileSync(DATA_FILE, JSON.stringify(data), 'utf8');
}
这种方式的优缺点:
- 优点:简单易实现,适合本地学习、小型 Demo 验证逻辑。
- 缺点:
- 性能差:文件 IO(读写)比内存操作慢得多,高并发下会卡顿。
- 可靠性低:文件可能因异常(比如写入时断电)损坏;且无法高效处理 “多端同时写” 的冲突。
三、数据库的核心作用:持久化与高效管理
数据库(比如 MySQL、MongoDB、PostgreSQL 等)的核心价值,正是解决 “内存 / 文件存储” 的痛点,实现数据的 “持久化” 和 “高效管理”。
1. 持久化:数据 “永久存活”
数据库会把数据存储在硬盘(而非内存)上。硬盘的存储是 “非易失性” 的 —— 即使服务器重启、断电,硬盘里的数据也不会丢失。
比如用 MongoDB 存储评论,数据会被写入硬盘的数据库文件,服务器重启后,只要重新连接数据库,就能读取到之前的所有评论。
2. 高效管理:解决 “复杂场景” 的痛点
除了 “持久化”,数据库还提供了一系列工具,解决文件 / 内存存储搞不定的问题:
- 并发控制:多用户同时写数据时,数据库能保证数据一致(比如用 “事务” 保证一组操作要么全成功,要么全失败)。如果用文件存储,多端同时写可能导致文件内容混乱。
- 查询优化:数据库支持 “索引”,可以快速找到目标数据。比如要找 “用户 A 发布的所有评论”,数据库能通过索引直接定位,而文件存储可能需要逐行扫描,效率极低。
- 数据验证:数据库可以定义 “schema(模式)”,强制要求数据符合格式(比如评论的 “内容” 必须是字符串、“创建时间” 必须是日期类型)。文件存储则无法自动验证,容易存错数据。
四、回到示例:为什么 “重启服务器,数据就消失”?
因为示例里没有用数据库,也没有用 “文件持久化” 的替代方案 ——data 只存在于服务器进程的内存中。
- 服务器运行时,内存里的
data可以正常读写。 - 但
nodemon重启服务器时,会杀死旧的服务器进程,启动新进程 —— 旧进程的内存被回收,新进程会重新执行代码,data被初始化为 “空”(或代码里写死的默认值),所以之前的评论、帖子全没了。
简单总结:内存存储是临时的,文件存储是简陋的过渡方案,数据库才是生产环境下数据持久化、高效管理的核心工具。