【实验报告】华东理工大学随机信号处理实验报告
实验1 离散随机变量的仿真与计算
- 实验目的
掌握均匀分布的随机变量产生的常用方法。
掌握高斯分布随机变量的仿真,并对其数字特征进行估计。
- 实验步骤
- 实验准备
- 安装python环境(3.12.2版本)
- 安装第三方库:numpy,用于生成随机数和计算统计量
- 编写代码
import numpy as np
import mathdef generate_uniform(mean, variance, size=10000):"""生成指定均值和方差的均匀分布随机数均匀分布U(a,b)的均值为(a+b)/2,方差为(b-a)²/12"""# 根据均值和方差计算a和ba = mean - math.sqrt(3 * variance)b = mean + math.sqrt(3 * variance)# 生成均匀分布随机数uniform_data = np.random.uniform(a, b, size)# 理论值theoretical = {'mean': mean,'variance': variance,'min': a,'max': b}return uniform_data, theoreticaldef generate_gaussian(mean, variance, size=10000):"""生成指定均值和方差的高斯分布随机数"""# 标准差是方差的平方根std = math.sqrt(variance)# 生成高斯分布随机数gaussian_data = np.random.normal(mean, std, size)# 理论值(高斯分布没有严格的最大最小值)theoretical = {'mean': mean,'variance': variance,'min': None, # 高斯分布理论上没有最小值'max': None # 高斯分布理论上没有最大值}return gaussian_data, theoreticaldef calculate_statistics(data):"""计算数据的统计特性"""stats = {'mean': np.mean(data),'variance': np.var(data),'min': np.min(data),'max': np.max(data)}return statsdef compare_distributions(mean, variance, size=10000):"""比较均匀分布和高斯分布的统计特性"""print(f"比较均值为{mean},方差为{variance}的随机分布 (样本量: {size})")print("=" * 70)# 处理均匀分布print("\n1. 均匀分布:")uniform_data, uniform_theo = generate_uniform(mean, variance, size)uniform_stats = calculate_statistics(uniform_data)print(f" 理论均值: {uniform_theo['mean']:.6f}, 实际均值: {uniform_stats['mean']:.6f}, "f"误差: {abs(uniform_stats['mean'] - uniform_theo['mean']):.6f}")print(f" 理论方差: {uniform_theo['variance']:.6f}, 实际方差: {uniform_stats['variance']:.6f}, "f"误差: {abs(uniform_stats['variance'] - uniform_theo['variance']):.6f}")print(f" 理论最小值: {uniform_theo['min']:.6f}, 实际最小值: {uniform_stats['min']:.6f}")print(f" 理论最大值: {uniform_theo['max']:.6f}, 实际最大值: {uniform_stats['max']:.6f}")# 处理高斯分布print("\n2. 高斯分布:")gaussian_data, gaussian_theo = generate_gaussian(mean, variance, size)gaussian_stats = calculate_statistics(gaussian_data)print(f" 理论均值: {gaussian_theo['mean']:.6f}, 实际均值: {gaussian_stats['mean']:.6f}, "f"误差: {abs(gaussian_stats['mean'] - gaussian_theo['mean']):.6f}")print(f" 理论方差: {gaussian_theo['variance']:.6f}, 实际方差: {gaussian_stats['variance']:.6f}, "f"误差: {abs(gaussian_stats['variance'] - gaussian_theo['variance']):.6f}")print(f" 实际最小值: {gaussian_stats['min']:.6f}")print(f" 实际最大值: {gaussian_stats['max']:.6f}")if __name__ == "__main__":# 指定的均值和方差target_mean = 5.0target_variance = 10.0sample_size = 500000 # 样本量越大,实际值越接近理论值compare_distributions(target_mean, target_variance, sample_size)
- 程序运行
- 将编写的代码保存为suijibianliang.py文件
- 执行运行命令
- 结果记录
- 等待程序运行完成,观察终端输出的统计结果
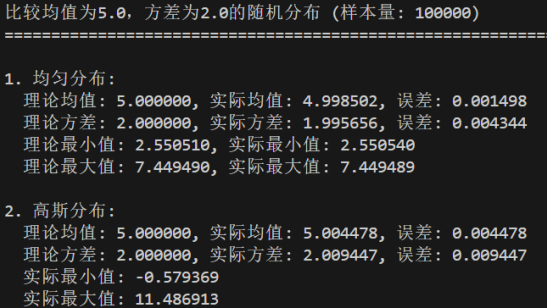
- 记录均匀分布的理论值与实际值(均值、方差、最大值和最小值)及误差
- 记录高斯分布的理论值与实际值(均值、方差、最大值和最小值)及误差
- 修改样本量参数,修改均值参数,修改方差参数,重复运行
- 记录实验结果并分析
实验原理
- 均匀分布
均匀分布 U (a, b) 是指在区间 [a, b) 内的概率密度为常数的连续概率分布:
概率密度函数:f (x) = 1/(b-a),当 a ≤ x < b
理论均值:μ = (a + b) / 2
理论方差:σ² = (b - a)² / 12
根据给定的目标均值μ和方差σ² ,可以反推出参数:
a = μ - √(3σ²)
b = μ + √(3σ²)
对应代码为:
a = mean - math.sqrt(3 * variance)
b = mean + math.sqrt(3 * variance)
np.random.uniform (a, b, size) 生成 [a, b) 区间内的均匀分布随机数
- 高斯分布
高斯分布 N (μ, σ²) 是一种常见的连续概率分布:
概率密度函数:f(x) = (1/√(2πσ²))·exp[-(x-μ)²/(2σ²)]
理论均值:μ
理论方差:σ²
np.random.normal (mean, std, size) 生成指定均值和标准差的正态分布随机数
- 统计量计算
对生成的随机数样本,计算以下统计量:
样本均值:x̄ = (1/n)·Σxᵢ
样本方差:s² = (1/n)·Σ(xᵢ - x̄)²
最小值:min(xᵢ)
最大值:max(xᵢ)
- 实验结果并分析
- 样本量大小对实际值与理论值误差的影响
修改样本量参数:sample_size分别为5000、50000、500000
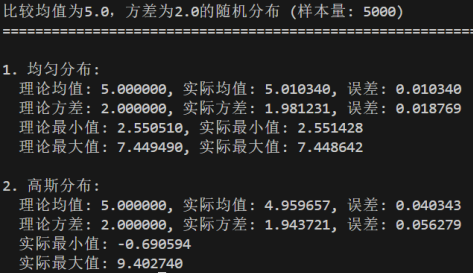
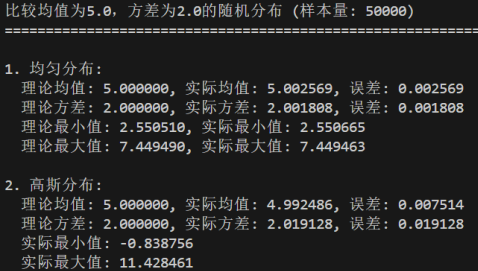
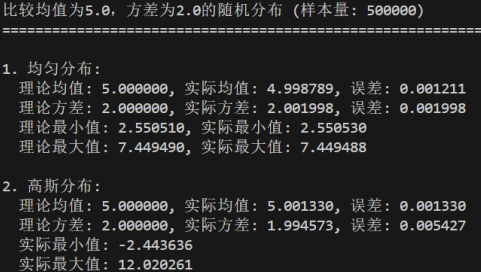
当样本量逐渐增大时,样本的统计量会逐渐趋近于总体的理论值;
样本量越大:实际统计值与理论值的误差越小;样本量越小:随机波动的影响越显著,误差较大
- 比较均匀分布和高斯分布的统计特性差异
修改均值参数:target_mean分别为0、10、20
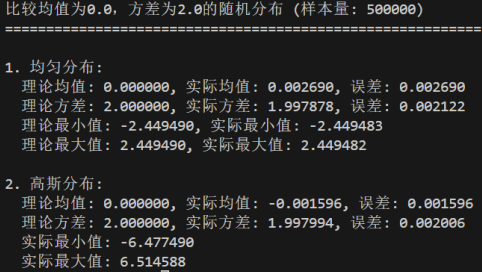
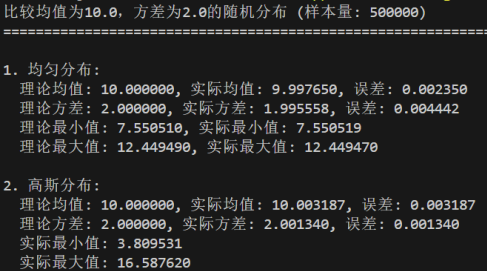
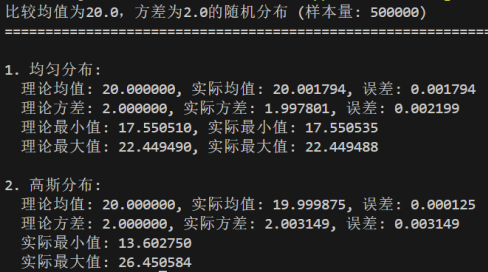
修改方差参数:target_variance分别为1、5、10
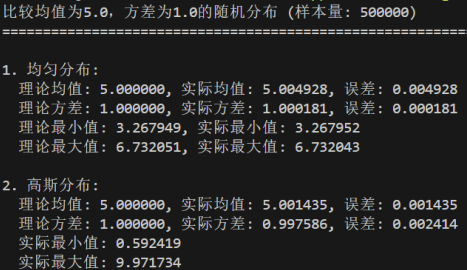
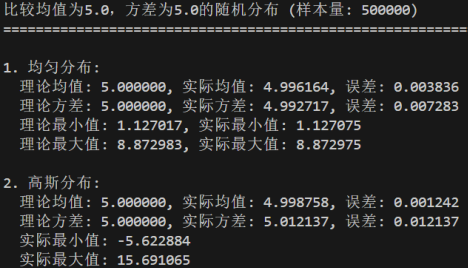
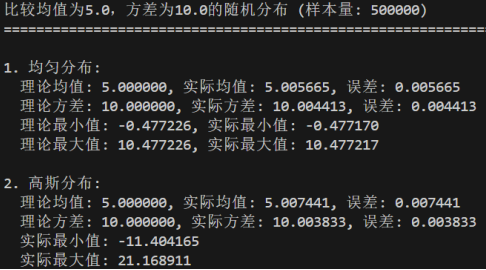
均匀分布的均值μ=(a+b)/2,位于区间正中心;方差σ²=(b-a)²/12,仅由区间长度决定
高斯分布的均值μ为分布的中心对称点;方差σ²决定分布的 "胖瘦",值越大离散度越高
- 均匀分布的实际最大值和最小值与理论值的接近程度
均匀分布 U (a,b) 的理论最小值为a,理论最大值为b,所有随机数严格落在 [a,b) 区间内;
当样本量较小时,实际最大值可能小于b,实际最小值可能大于a,与理论值有明显差距;当样本量增大时,实际最值会非常接近理论值a和b;当样本量足够大时,实际最值几乎与理论值重合
- 分析高斯分布的实际最大值和最小值的变化规律
高斯分布没有严格的理论最值,理论上随机数可取值到 ±∞,但极端值出现的概率极低;
样本量越大,实际最大值可能越大,实际最小值可能越小;标准差σ越大,实际最值的波动范围越广;相同样本量下,多次实验的实际最值会有波动,但整体围绕μ±kσ的范围波动
- 总结
- 随着样本量增加,极端值对整体统计结果的影响会被稀释,样本更能反映总体的真实特性;
- 均匀分布是平等的取值分布,而高斯分布是中心聚集的取值分布;
- 均匀分布的随机数在区间内均匀取值,样本量越大,随机数覆盖整个区间的概率越高,因此实际最值会逐渐逼近理论边界a和b;
- 高斯分布的取值范围符合“3σ原则”,概率集中在均值附近,极端值罕见,实际最值无固定边界,但随样本量增大呈现可预测的扩展趋势
实验报告要求
(1)编写Matlab或Python程序实现产生指定均值和方差的均匀分布和高斯分布的随机数;
(2)求该随机数的最大值、最小值、均值和方差,并与理论值相比较。