数据结构入门 (四):双向通行的“高速公路” —— 深入双向循环链表
目录
- 引言:打破“单行道”的束缚
- 一、双向链表的核心节点操作
- 1.插入操作
- 2.删除操作
- 二、构建双向循环链表
- 三、双向循环链表C语言实现
- 1.定义结构体与接口
- 2.初始化链表
- 3.核心辅助函数
- 4.头插法
- 5.尾插法
- 6.展示链表
- 7.删除链表中的节点
- 8.销毁链表
- 9.测试函数
- 四、总结:工程领域的“链表之王”
引言:打破“单行道”的束缚
在之前的探索中,我们已经掌握了单向链表。但它有一个无法回避的痛点:它是一条“单行道”。一旦我们从一个节点走向下一个,那么就再也无法轻松地回头。这时候,如果我们需要查找某个节点的前驱,我们只能从头开始,重新遍历一遍。
这种“一去不返”的特性,让单向链表在许多需要灵活操作的工程场景中显得力不从心。我们不禁要问:能不能为这条路开辟一条逆行车道,让数据节点可以来去自如呢?
答案是肯定的!只需在每个节点中,除了next指针外,再添加一个指向前驱节点的prev指针。这样,我们就构建了一条双向链表。
实际应用中,我们多使用双向链表,它即可往前又可往后的特点,在进行操作时非常方便,比如在删除元素的时候,它不需要像单向链表一样找前置节点,这是因为它的节点结构包含两个指针域,在这个节点上就可以找到指向上一个节点的指针。

但普通的双向链表在进行尾插操作时,依然会遇到与单向链表一样的问题:从头一步步走到尾再进行插入。所以我们效仿单向链表的解决方法,引入循环,将双向链表的头尾相连,构建出它的终极形态,也是我们这篇文章的重点——双向循环列表。它几乎是工程应用中最常用、最强大的链表形态。
一、双向链表的核心节点操作
双向链表的节点中同时包含两个指针,因此每次操作的时候,都要注意处理好这两个指针。
1.插入操作
想象一下,我们要在两个节点(节点1和节点3)之间,插入一个新的节点(new_node)。如图2。

对于插入操作,为了方便,我们首先给每个节点都放一个指针,分别为prev,new_node,next。
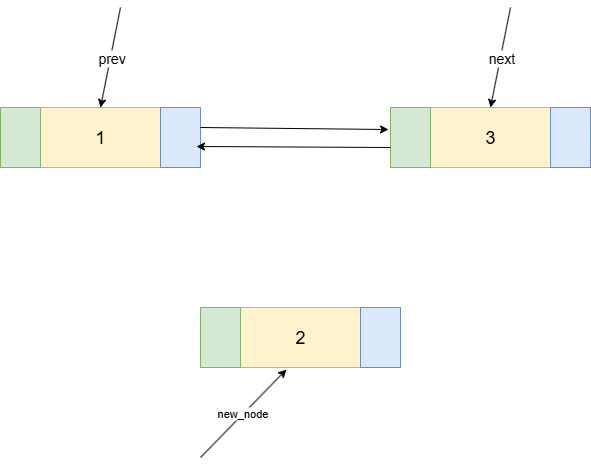
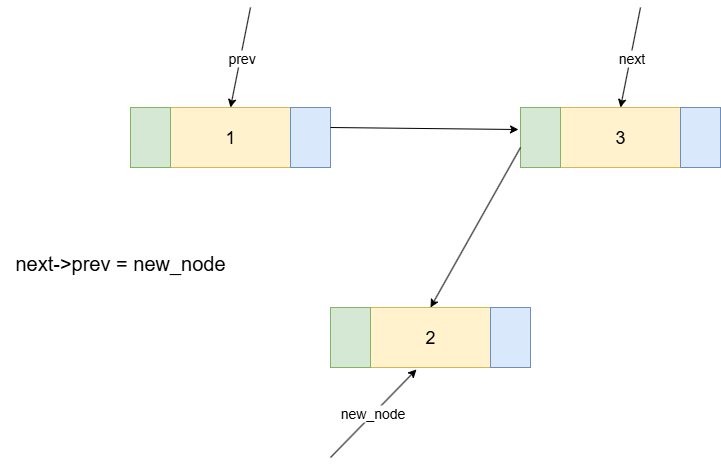
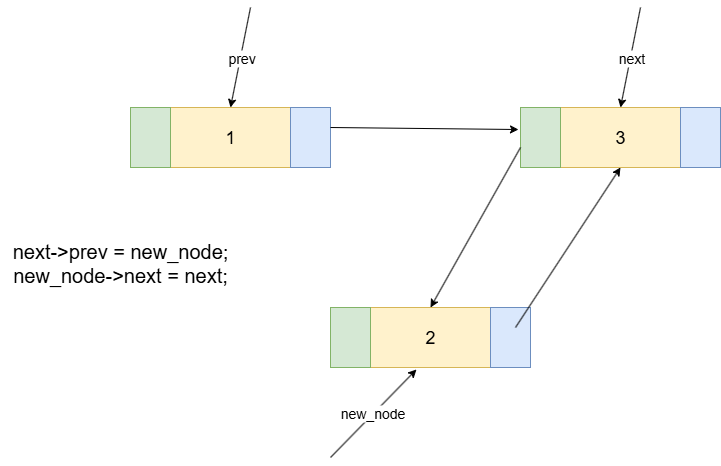
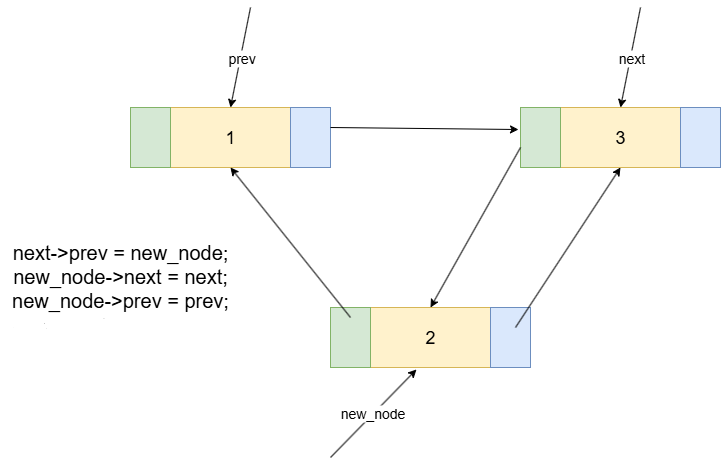
整个过程需要4个步骤来修改指针,将new_node完美地接入到链表中。一个安全且不易出错的顺序是:先处理新节点本身,再修改原有链表。
new_node->prev = prev;// 步骤①:新节点的prev指向前驱节点。new_node->next = next;// 步骤②:新节点的next指向后继节点。prev->next = new_node;// 步骤③:前驱节点的next指向新节点。next->prev = new_node;// 步骤④:后继节点的prev指向新节点。
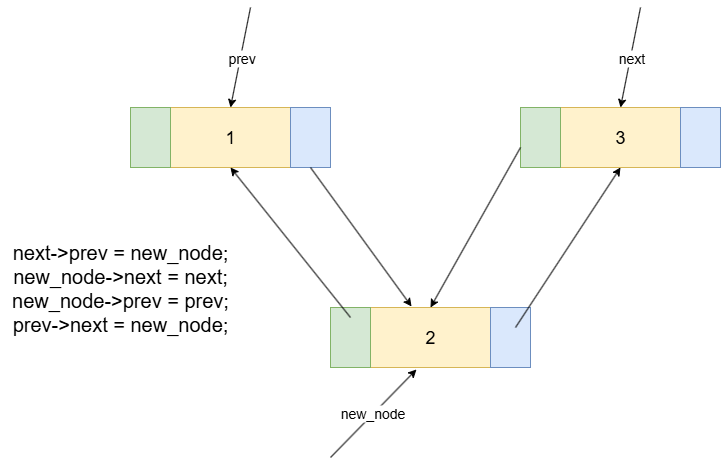
这个操作是所有插入(头插、尾插、中插)的核心。我们可以将它封装成一个函数便于调用:
static void addDNode(DNode* new_node, DNode *prev, DNode* next)
{next->prev = new_node;new_node->next = next;new_node->prev = prev;prev->next = new_node;
}
2.删除操作
对于删除一个节点(节点2)的操作则相对简单一些,只需要让它的前驱(节点1)和后继(节点3)跳过节点2,直接相连即可。
这个过程只需要2个步骤:
prev->next = next;// 步骤①:前驱的next指向后继。next->prev = prev;// 步骤②:后继的prev指向前驱。
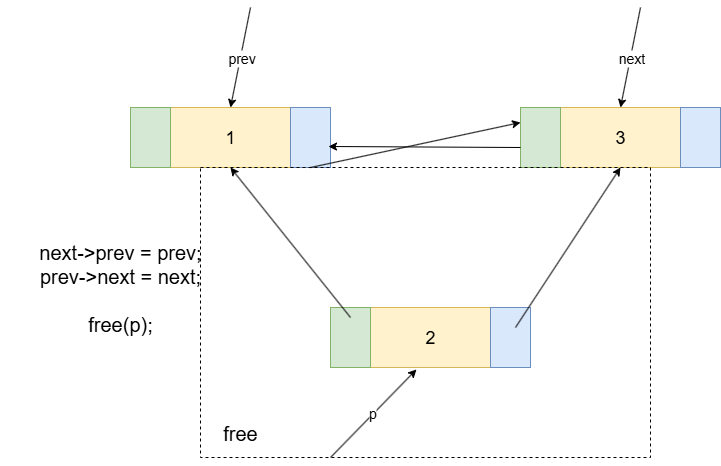
我们同样将其封装成函数:
static void delDNode(DNode* prev, DNode* next)
{next->prev = prev;prev->next = next;
}
二、构建双向循环链表
掌握了对节点的核心操作后,我们来构建一个带头节点的双向循环链表。它的空链表形态是这样的:头结点header的next和prev指针都指向它自己,形成一个最小的闭环。
双向循环链表的带头节点的空链表如下图所示。

在这个结构下,我们将用到之前封装的addDNode函数:
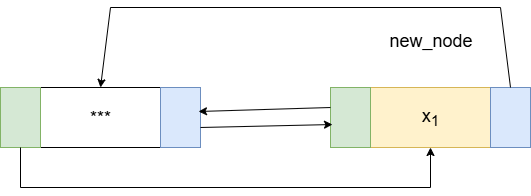
- 头插:在 header 和 header->next (原第一个节点) 之间插入新节点。
insertHead(new_node, header, header->next)
- 尾插:在 header->prev (原最后一个节点) 和 header 之间插入新节点。
insertTail(new_node, header->prev, header)
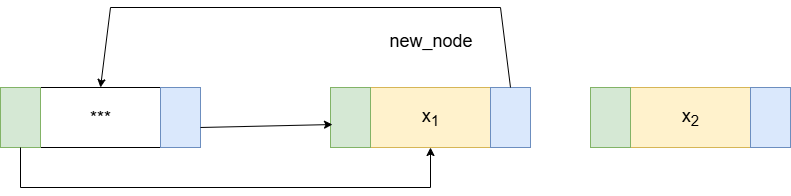
无论是头插还是尾插,我们都调用了同一个核心函数,区别只是传递不同的“前驱”和“后继”。这正是带头结点的循环结构带来的优雅与统一。
三、双向循环链表C语言实现
1.定义结构体与接口
#include <stdio.h>
#include <stdlib.h>typedef int Element;
typedef struct _node {Element val;struct _node *next;struct _node *prev;
} DNode, DList; // 我们起了两个别名防止理解错误/* 使用一个带头节点的双向循环链表,头节点让用户来管理,提供初始化接口 */
void initDList(DList *header);
void releaseDList(DList *header);// 实现头插、尾插
void insertDListHeader(DList *header, Element val);
void insertDListRear(DList *header, Element val);
// 显示链表
void showDList(const DList *header);
// 删除一个元素
void deleteDList(DList *header, Element e);
2.初始化链表
void initDList(DList* header)
{header->val = 0;header->next = header->prev = header;
}
3.核心辅助函数
// 核心插入函数 (static表示为内部使用)
static void addDNode(DNode* new_node, DNode *prev, DNode* next)
{new_node->prev = prev;new_node->next = next;prev->next = new_node;next->prev = new_node;
}// 核心删除函数 (static表示为内部使用)
static void delDNode(DNode* prev, DNode* next)
{prev->next = next;next->prev = prev;
}
4.头插法
void insertDListHeader(DList *header, Element val)
{DNode *new_node = malloc(sizeof(DNode));new_node->val = val;addDNode(new_node,header, header->next);++header->val;
}
5.尾插法
void insertDListRear(DList *header, Element val)
{DNode *new_node = malloc(sizeof(DNode));new_node->val = val;addDNode(new_node, header->prev, header);++header->val;
}
6.展示链表
void showDList(const DList *header)
{DNode *pos = header->next;printf("show:");while (pos != header){printf("%d\t", pos->val);pos = pos->next;}printf("\n");
}
7.删除链表中的节点
void deleteDList(DList *header, Element e)
{// 1.找到这个元素,就可以删除,不需要再找到前置节点DNode *pos = header->next;while (pos != header && pos->val != e){pos = pos->next;}// 2.找到没有?if (pos != header){delDNode(pos->prev, pos->next);pos->next = pos->prev = NULL;free(pos);--header->val;} else{printf("Not find %d element!\n",e);}
}
8.销毁链表
void releaseDList(DList* header)
{DNode *pos = header->next;DNode *tmp = NULL;while (pos != header){tmp = pos;delDNode(pos->prev, pos->next);pos = pos->next;free(tmp);--header->val;}
}
9.测试函数
DList stu_table; // 创建一个DList类型的全局变量stu_table
int main()
{initDList(&stu_table);for (int i = 0; i < 5; ++i){//insertDListHeader(&stu_table, i + 100);insertDListRear(&stu_table, i + 100);}insertDListHeader(&stu_table, 60);insertDListHeader(&stu_table, 80);showDList(&stu_table);printf("====================\n");deleteDList(&stu_table, 102);showDList(&stu_table);releaseDList(&stu_table);printf("num:%d\n",stu_table.val);return 0;
}
结果为:
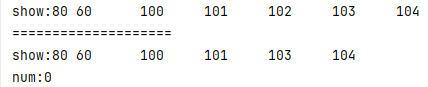
四、总结:工程领域的“链表之王”
至此,我们已经掌握了双向循环链表。虽然每个节点都增加了一个指针,带来了额外的内存开销,但它换来的是无与伦比的操作便利性:
- 双向遍历:既能从前到后,也能从后到前。
O(1)复杂度的两端操作:无论是头插、头删,还是尾插、尾删,都快如闪电。O(1)复杂度的邻居节点查找:给定任意一个节点,都能立刻找到其前驱和后驱。
正是这些强大的特性,使得双向循环链表在实际工程中备受青睐,成为许多底层库和系统的实现基础,例如著名的 Linux 内核中的list_head就是一个经典的双向循环链表实现。
我们的线性结构探索之旅,到这里就告一段落了。从最简单的顺序表,到最灵活强大的双向循环链表,我们一步步见证了数据结构为了应对不同挑战而进行的精妙演化。接下来,我们将迈入一个全新的维度,探索更加复杂和强大结构,比如“栈”和“队列”。