NeRF+3DGS——提升渲染质量与压缩模型参数

项目主页:https://wzpscott.github.io/hyrf/
本篇是港大新出的关于3DGS渲染质量与压缩的文章,借鉴了神经辐射场的思想,将高斯球的属性放到神经网络中来预测,以往也有类似用神经网络预测高斯属性的工作,但是实际出现的问题在于单个神经网络不能很好的预测出高斯属性(文章的分析是:GS这一套参数中,几何属性与颜色属性相关性不强),因此使用了解耦的两个神经网络来预测高斯属性,特别对于颜色(和渲染的方向有关系),把相机的方向做了和nerf一样的位置编码,这样,每个高斯球颜色属性就不需要原先的48位球谐函数系数,而是根据相机方向直接得到三通道rgb值(体现球谐函数的特性:各个方向颜色不一样)。对于渲染做了背景处理。
通过这样既提升了高频细节,又大量减少了高斯属性参数,文章提到模型被压缩了20倍。
abstract
3DGS作为一种强有力的 NeRF 替代方案逐渐兴起,它通过显式、可优化的三维高斯实现了实时的高质量新视角合成。然而,3DGS 依赖于逐高斯(per-Gaussian)的参数来建模视角相关效应和各向异性形状,这导致了显著的内存开销。尽管已有研究提出利用神经场对 3DGS 进行压缩,但这些方法在捕捉高斯属性的高频空间变化方面存在困难,进而导致细节重建质量下降。
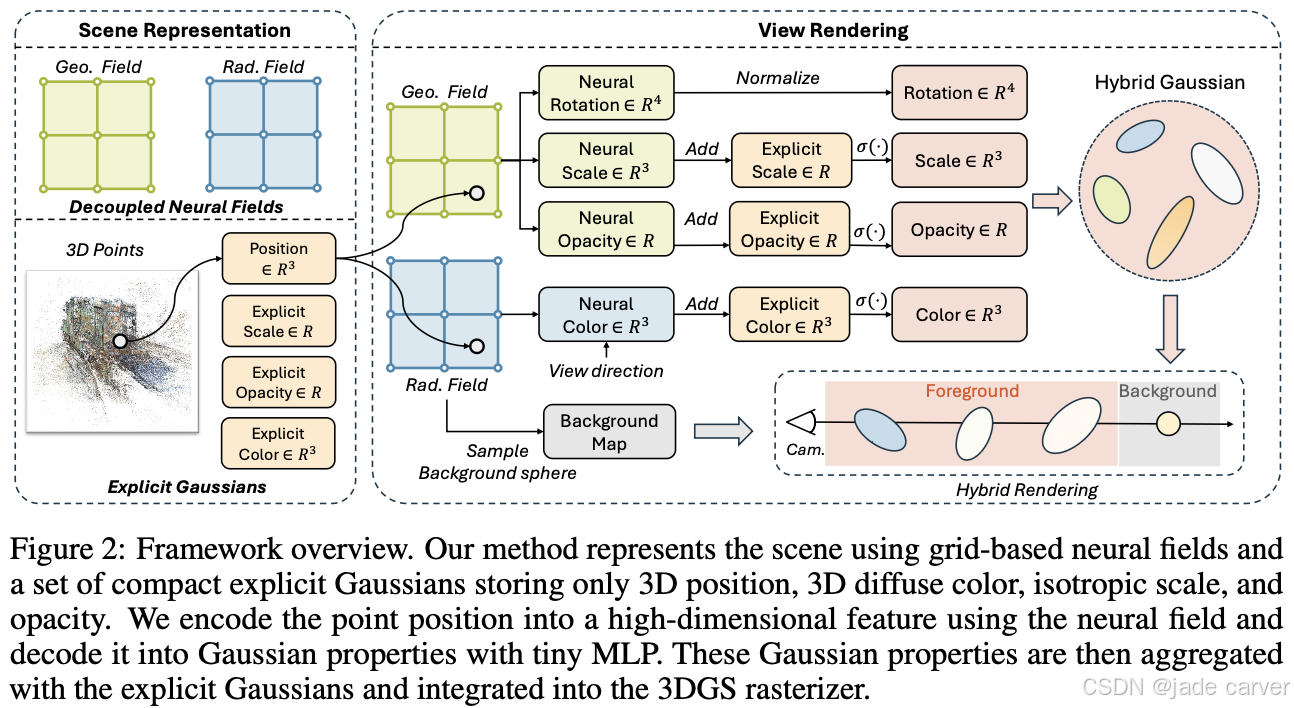
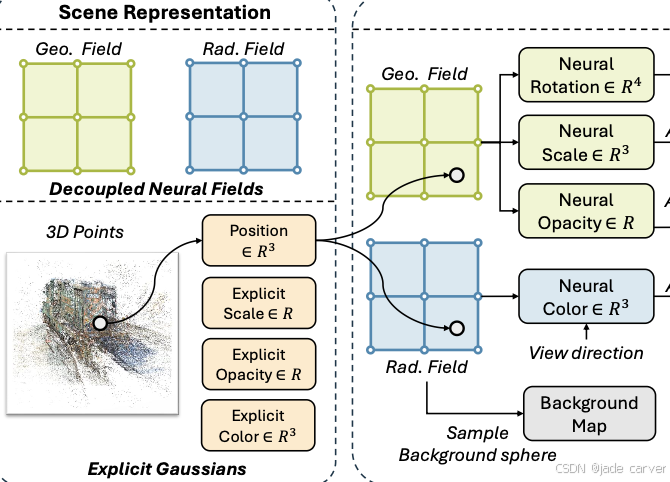
我们提出 Hybrid Radiance Fields (HyRF),一种结合显式高斯与神经场优势的新型场景表示方法。HyRF 将场景分解为两部分:(1) 一个紧凑的显式高斯集合,仅存储关键的高频参数;(2) 基于网格的神经场,用于预测其余属性。
为了增强表示能力,我们引入了一种解耦的神经场架构,分别建模几何属性(尺度、不透明度、旋转)和视角相关的颜色。此外,我们提出了一种混合渲染方案,将3dgs与神经场预测的背景进行复合,从而解决远距离场景表示的局限性。
实验结果表明,HyRF 在保持实时性能的同时,将模型大小相比 3DGS 缩小了超过 20 倍,并实现了当前最先进的渲染质量。
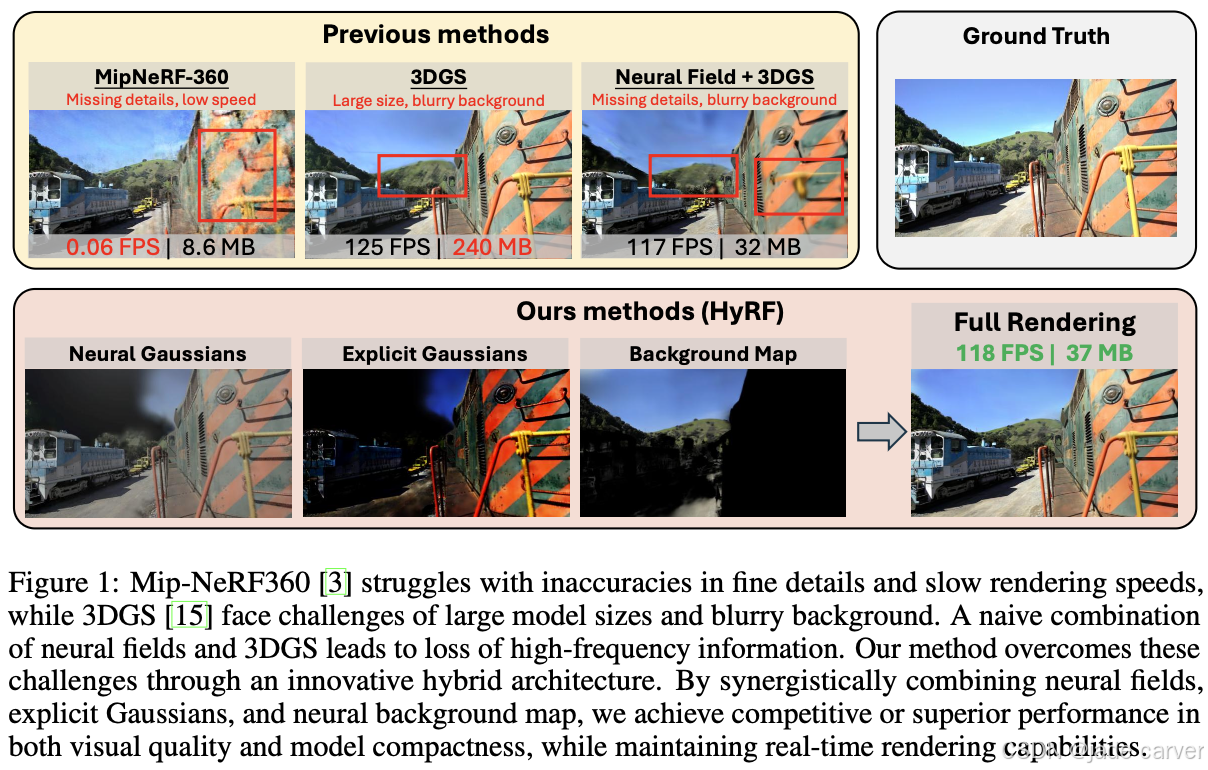
1 Introduction
Neural Radiance Fields (NeRF) [25] 已成为三维重建的核心技术之一,它通过神经网络与体渲染实现隐式场景表示,从而生成新视角图像。NeRF 方法能够以紧凑的模型大小产生高质量渲染,但受限于渲染速度较慢。
3D Gaussian Splatting (3DGS) [15] 作为 NeRF 的一种有力替代方法,能够实时渲染高分辨率的新视角。与依赖连续神经网络的 NeRF 不同,3DGS 使用一组显式、可优化的三维高斯来表示场景,并通过高效的可微分点基splatting过程 [57, 51],绕过了体渲染的计算开销,从而实现实时性能并提升渲染质量。
然而,3DGS 存在显著的内存开销问题:它需要大量参数来表示视角相关的颜色和各向异性形状。每个高斯需要 59 个参数,其中 48 个用于基于球谐函数的视角相关颜色,7 个用于各向异性尺度和旋转。这与 NeRF 方法形成鲜明对比,后者能通过网络调控高效建模视角相关效应,而无需过多参数。
一种直观的思路是将 3D 高斯的属性编码进基于网格的神经场 [48, 41],以此降低存储成本。但这种方法存在根本限制:固定分辨率的网格表示难以捕捉高斯属性的高频空间变化。这种问题在处理物体边界快速变化的透明度和尺度,或高频的视角相关效应时尤为明显。因此,简单地将高斯拟合到神经场,往往无法重建细节,比如细小的几何结构和高频颜色变化。
[41] Xiangyu Sun, Joo Chan Lee, Daniel Rho, Jong Hwan Ko, Usman Ali, and Eunbyung Park.
F-3dgs: Factorized coordinates and representations for 3d gaussian splatting. arXiv preprint arXiv:2405.17083, 2024.
[48] Minye Wu and Tinne Tuytelaars. Implicit gaussian splatting with efficient multi-level tri-plane
representation. arXiv preprint arXiv:2408.10041, 2024.1.1场景表达方法
我们提出 Hybrid Radiance Fields (HyRF),一种新型场景表示方法,它在保持低内存开销的同时,有效解决了神经高斯方法的频率限制问题。核心思想是将表示拆分为两种互补组件:
- 基于网格的神经场 —— 捕捉低频变化;
- 稀疏的显式紧凑高斯 —— 保留高频细节。
在神经场部分,我们采用解耦架构,包括两个专用神经场:
- 几何网络:建模高斯的几何属性(尺度、不透明度、旋转);
- 外观网络:预测视角相关的颜色。
通过显式地分离几何和光度学习目标,显著提升了神经场的表示能力,同时保持了参数效率。与此同时,显式高斯部分仅存储必要的属性(3D 位置、各向同性尺度、不透明度和漫反射颜色),既减少了内存开销,又能保留关键的场景细节。
1.2渲染流程
为了兼顾效率与渲染质量,我们设计了一个三阶段的混合渲染流程:
- 可见性预裁剪(视锥体):剔除视锥体外的高斯,降低神经场查询开销;
- 神经场查询与融合:对剩余可见高斯查询神经场,预测其属性,并与显式参数结合,恢复高频细节;
- 背景建模与合成:为了解决高斯表示在远距离场景的不足,神经场学习生成一个背景贴图(投影到背景球面),并通过 alpha 混合与前景高斯渲染结果融合,实现前景与远景的高质量效果。
方法主要贡献:
(i) 提出了一种显式紧凑高斯与神经场的融合方案,在减少内存开销的同时保留高频细节;
(ii) 设计了双神经场架构,将几何与视角相关效应解耦建模,提升表示能力;
(iii) 提出了混合渲染策略,有效降低计算开销并提升背景渲染质量;
(iv) 通过大量实验验证,我们的方法在保持实时性能的同时,相比 3DGS 模型大小缩减 20 倍。
| 方法 | 表示方式 | 优点 | 缺点 |
|---|---|---|---|
| NeRF | 隐式神经场(MLP + 体渲染) | - 渲染质量高- 模型紧凑(参数量小)- 高效建模视角相关效应 | - 渲染速度慢(实时性差)- 推理开销大 |
| 3DGS | 显式 3D 高斯 + Splatting 渲染 | - 实时渲染高分辨率视角- 绕过体渲染,效率高 | - 内存开销大(每个高斯 59 参数)- 依赖大量高斯存储- 难以扩展到远景场景 |
| HyRF | 神经场(低频)+ 紧凑高斯(高频)+ 混合渲染 | - 结合两者优点- 模型大小缩小 20×- 保留高频细节- 解耦结构提升表示能力- 背景合成更真实- 保持实时性能 | - 结构更复杂- 需要额外训练背景神经场 |
2 Related Work
2.1Compressed 3D Gaussian Splatting(压缩的 3DGS)
虽然 3DGS 在渲染性能上超越了 NeRF,但其显著更大的模型规模促使研究者探索紧凑表示,以在保留性能优势的同时减小存储开销。现有方法主要分为两类:
- 参数压缩技术:例如向量量化(vector quantization)[17, 28];
- 混合神经网络 + 3DGS 架构 [29, 17, 6, 41]:通过神经网络预测 3D 高斯属性,而不是显式存储。
与我们工作最接近的是 Scaffold-GS [23],它利用锚点(anchor points)和神经特征来预测局部anchor(锚点)关联的部分高斯属性,从而在保证渲染质量的前提下实现更好的紧凑性。我们的工作与之有本质区别:我们通过基于网格的神经场在全局范围内预测所有高斯属性(其实就是和原始3DGS一样),并利用显式残差高斯增强高频细节。这种架构实现了更高的压缩率和更优的视角质量。
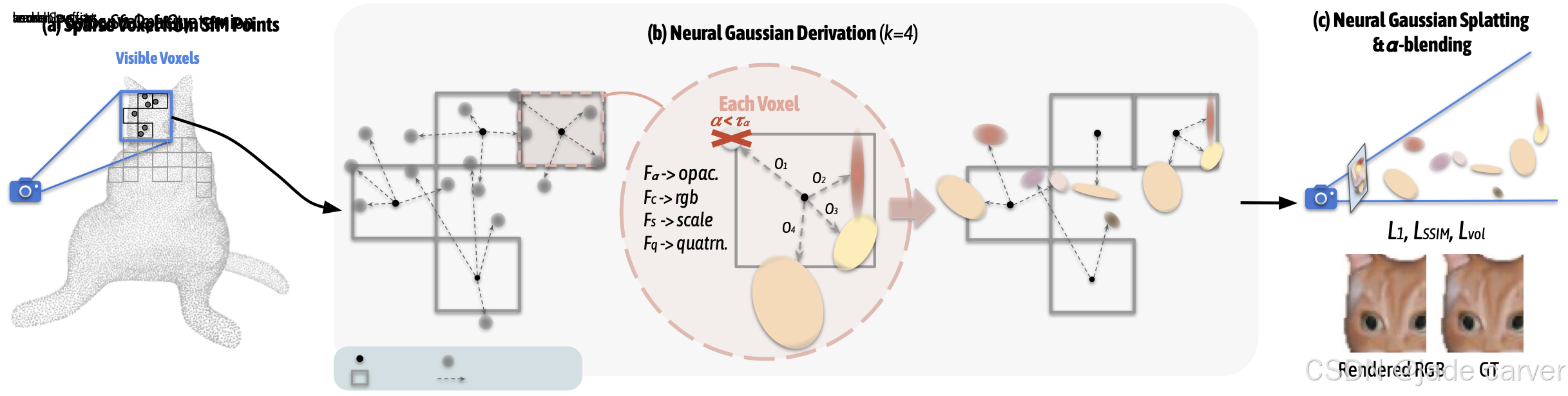
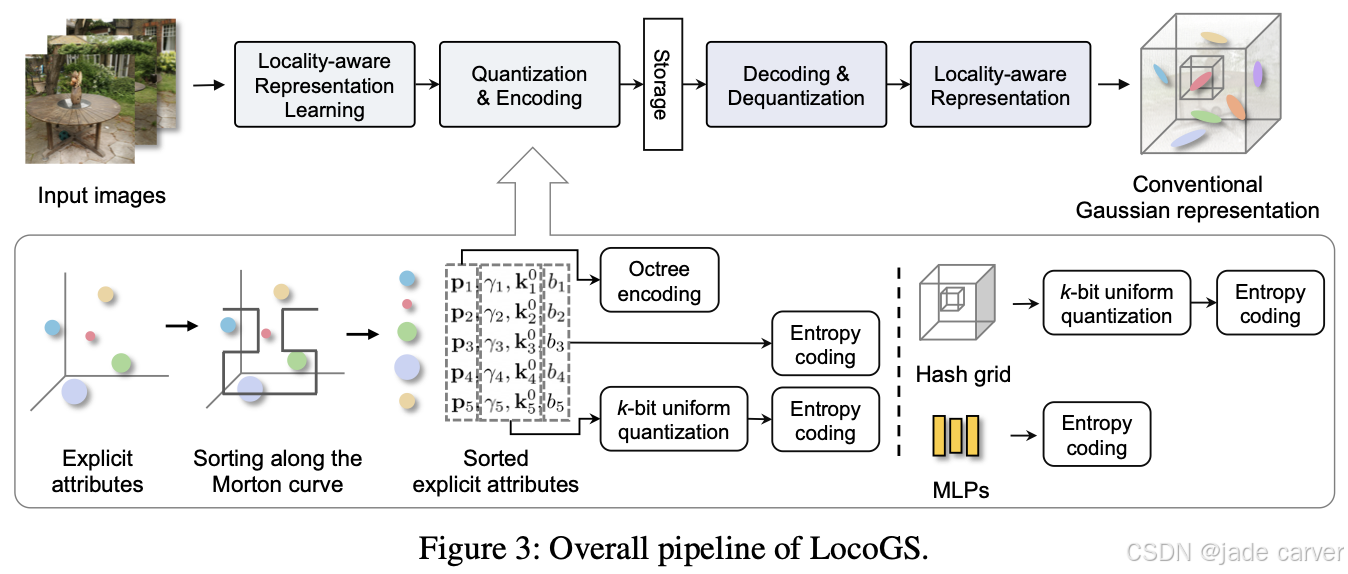
此外,我们的方法与向量量化技术兼容,因为我们的显式高斯只包含极少参数,相比传统 3DGS 表示进一步提升了效率。近期的 LocoGS [39] 也提出了一种类似思路,将高斯属性存储在神经场中。但与其不同的是,我们的方法保留了显式的高斯残差,并引入了解耦的神经场结构,从而能更好地表示场景的高频部分。
| 方法 | 优点 | 缺点 |
|---|---|---|
| NeRF | - 高质量新视角合成- 模型紧凑(参数少)- 可扩展到大场景(如 Mip-NeRF360) | - 渲染速度慢(体渲染开销大)- 训练时间长- 难以实时应用 |
| 3DGS | - 实时渲染(点基渲染效率高)- 高质量结果(媲美甚至超越 NeRF) | - 模型参数量巨大(每个高斯 ~59 个参数)- 内存开销大- 不利于移动端或大规模场景 |
| Scaffold-GS | - 引入 锚点 + 神经特征,局部预测高斯属性- 模型更紧凑 | - 仍需大量显式高斯- 高频细节保持有限 |
| LocoGS | - 将高斯属性存储到神经场,减少显式参数- 提高压缩率 | - 神经场分辨率有限,难以捕捉高频变化- 细节恢复不足(特别是边界、纹理) |
| HyRF(本文) | - 解耦神经场(几何 vs 外观)→ 提升表示能力- 显式残差高斯保留高频细节- 模型更紧凑(20× 压缩)- 保持实时性能- 提出混合渲染,改善远景/背景效果 | - 体系结构更复杂- 神经场和显式高斯需要协同优化 |
补充知识:



Instant-NGP回顾



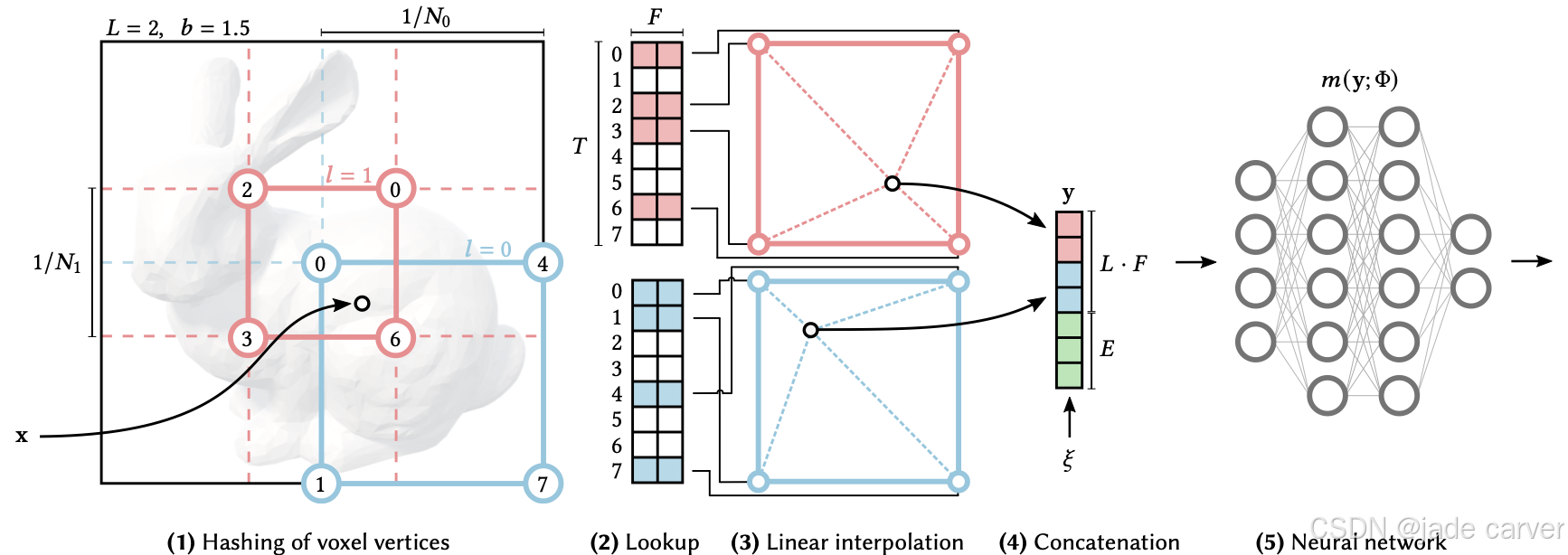
3 Methodology
3.1 Preliminary: 3DGS
3DGS 使用来自 Structure-from-Motion (SfM) 工具(如 COLMAP [37, 38])获取的三维点作为初始高斯分布,并基于累计的梯度信息进行自适应加密(densification)。在渲染过程中,三维高斯会按照深度排序,投影到二维图像平面上,并通过以下基于点的 alpha 混合(alpha-blending) 方法进行组合:
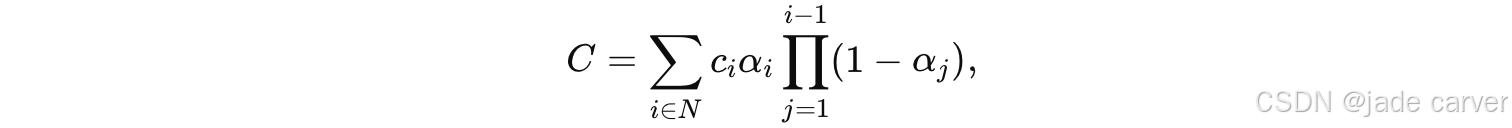
其中,C 表示最终预测的像素颜色,N 表示投影到该像素的、按深度排序后的高斯集合。
3.2 Hybrid Radiance Fields
我们的方法使用以下两部分表示一个场景:

3.2.1解耦神经场(Decoupled Neural Fields):
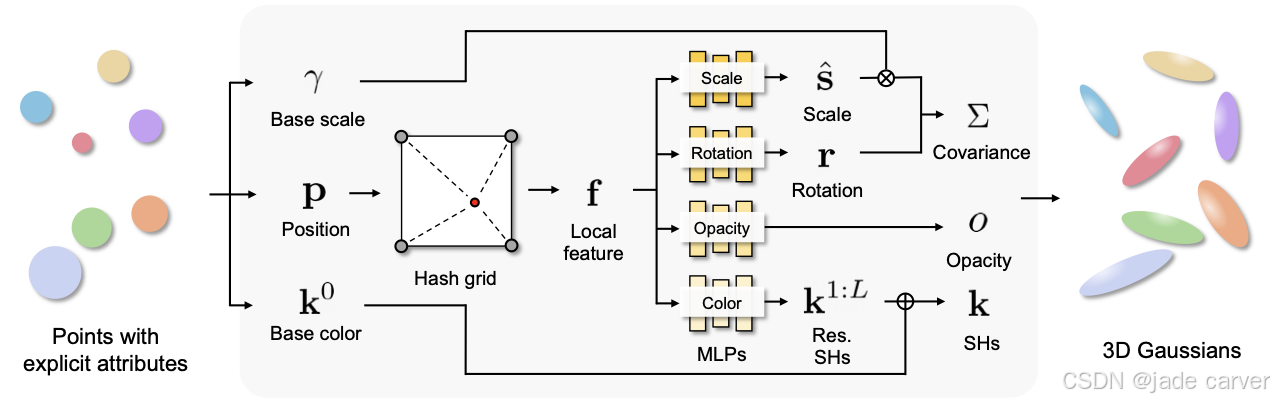
实验结果表明,通过单一神经场预测所有高斯属性无法获得令人满意的性能。我们认为其原因在于高斯的几何属性与外观属性之间相关性较弱,因此难以在单一神经场中同时学习。为解决这一问题,我们提出了解耦神经场架构:使用两个独立的神经场 ![]() 和
和 ![]() 分别预测几何属性(尺度、旋转和不透明度)和外观属性(视角依赖的颜色)。
分别预测几何属性(尺度、旋转和不透明度)和外观属性(视角依赖的颜色)。
给定 3D 点的位置 ![]() ,我们首先采用类似 MipNeRF360 [3] 的场景收缩(scene contraction)技术来约束输入坐标。我们先使用场景的轴对齐边界框(AABB)
,我们首先采用类似 MipNeRF360 [3] 的场景收缩(scene contraction)技术来约束输入坐标。我们先使用场景的轴对齐边界框(AABB)![]() 对坐标进行归一化,该边界框定义为最小与最大相机位置。然后将归一化点收缩到区间 (0,1):
对坐标进行归一化,该边界框定义为最小与最大相机位置。然后将归一化点收缩到区间 (0,1):
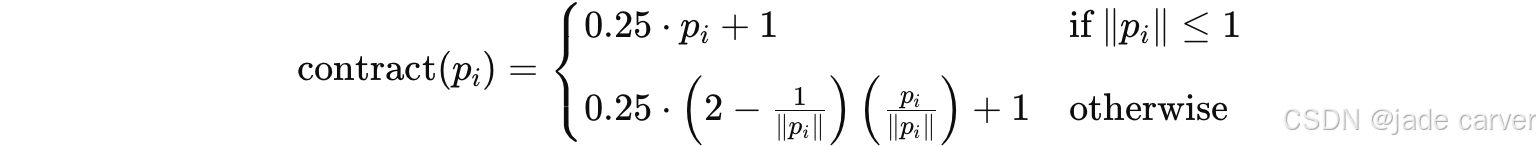
这个编码是Instant-NGP的压缩方式
然后,我们使用解耦神经场(decoupled neural fields)将其编码为两个高维特征:
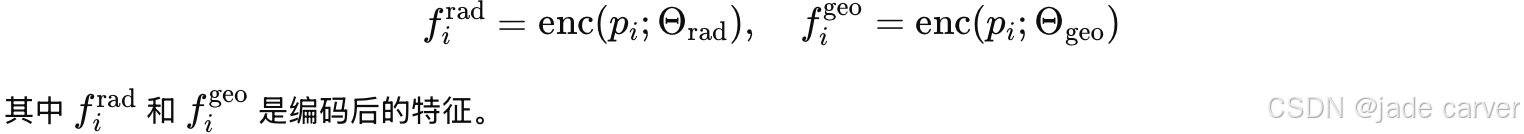

原始的3DGS各个方向的颜色是由球谐函数表达的(前面提到的高斯模型的其中 48 个用于基于球谐函数的视角相关颜色),现在为了达到压缩效果,使用nerf的处理方法,把方向提前编码到神经网络中去。
为了考虑高斯颜色的视角依赖效应,我们在 MLP 输入中加入了视角方向分量,采用与 NeRF 方法一致的位置编码技术 [27, 3]。视角方向编码计算为:

3.2.2与显式高斯函数的聚合
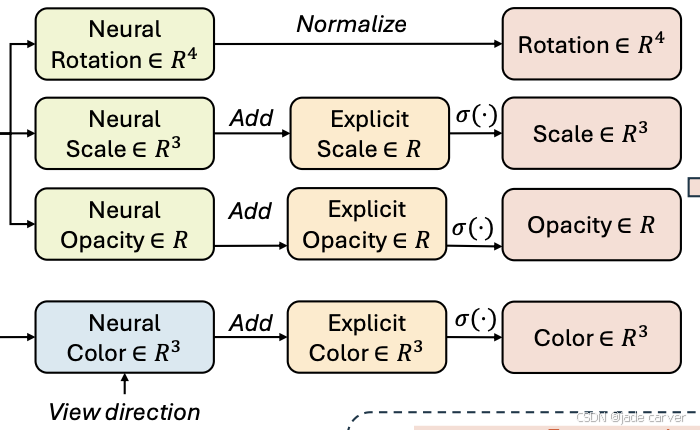
基于网格的神经场常忽略场景中的高频成分,例如固有结构。我们通过将神经场预测的属性与存储在每个高斯中的显式属性进行聚合来解决这个问题。类似于 3DGS,我们对不透明度和颜色应用 sigmoid 激活函数,对旋转使用归一化函数:

聚合后的高斯属性 (α,r,s,c)随后被送入 3DGS 光栅化器进行渲染。
3.3 Hybrid Rendering
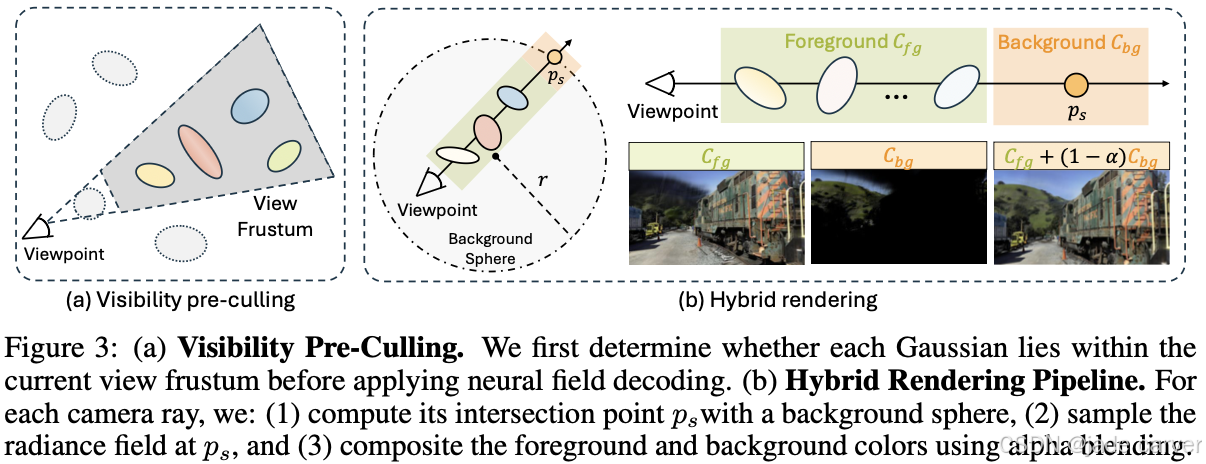
3.3.1Visibility pre-culling
为了减少查询神经场的计算开销,我们在使用神经场推导点属性之前,先剔除那些不会投影到图像平面上的点。图 3(a) 展示了可见性预裁剪的流程。
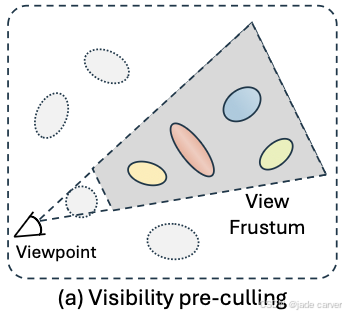
具体来说,给定一个点 pi 和相机视角,我们使用相机的旋转矩阵 R 和平移向量 t 计算点 pi 在相机空间的坐标:
![]()
只有当点投影位于图像框内时,我们才保留该点,其条件为:

3.3.2Background rendering
3D 高斯渲染(3DGS)通常难以有效密集化和优化非常远的物体,导致背景模糊。为了解决这一问题,我们提出了一种混合渲染技术,利用辐射场 ![]() 来预测背景颜色。图 3(b) 展示了背景渲染流程。
来预测背景颜色。图 3(b) 展示了背景渲染流程。
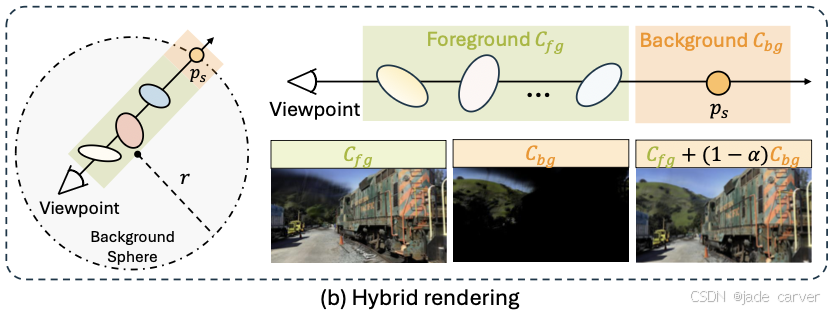
与 [18] 将背景预测为无穷远点不同,我们构建了一个半径较大的背景球。对于从给定相机视角投射的每条光线,我们计算光线与球的交点 ![]() ,然后使用辐射场和解码器预测该点的颜色。背景颜色
,然后使用辐射场和解码器预测该点的颜色。背景颜色 ![]() 结合了背景高斯球颜色与前景高斯球累积后的剩余可见性:
结合了背景高斯球颜色与前景高斯球累积后的剩余可见性:
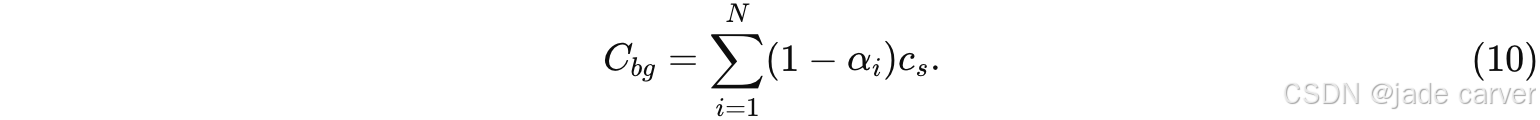
最后,像素颜色通过前景与背景颜色结合得到:
![]()
其中 Cfg 由公式 (1) 给出。在渲染阶段,我们仅对累积透射率:
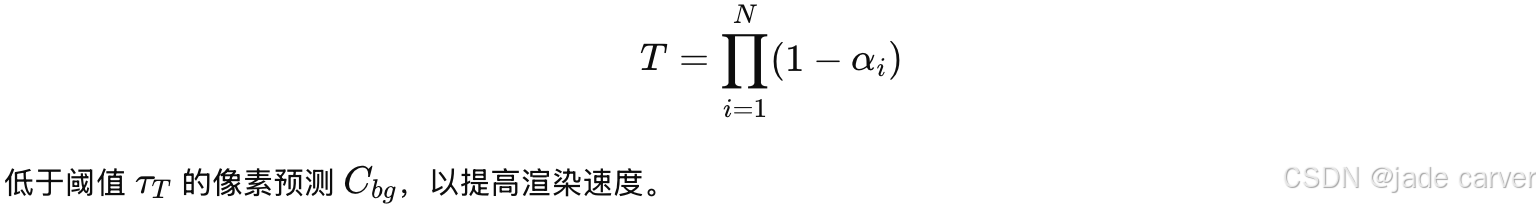
3.4 Optimization
我们的方法采用与原始3DGS相同的L1损失和SSIM损失[45]进行优化:
![]()
其中λ为SSIM损失的权重。与原始3DGS类似,我们在致密化过程中会周期性地将显式不透明度重置为较小值,并剪除不透明度较低的高斯分布。
4 Experiments
4.1 Experimental Setup
在 25 个场景 上进行实验,涵盖了 MipNeRF360、Tanks & Temples、Deep Blending、NeRF Synthetic、Mill19 和 Urbanscene3D 等多个标准与大规模数据集。在对比实验中,分别选择了 NeRF 系列方法(如 MipNeRF、Instant-NGP、MegaNeRF、SwitchNeRF) 和 3DGS 系列方法(3DGS、Scaffold-GS 及压缩方法)作为基线。
方法实现基于原始 3DGS,和instantNGP一样,采用 16 层多分辨率哈希编码(每条目特征维度为 2),哈希表大小随场景规模调整;几何场哈希表大小为辐射场的一半。解码器使用两层、每层 64 神经元的 全融合 MLP,背景渲染设置 τT=0.2、r=100。其余超参数与 3DGS 保持一致,实验在 单张 NVIDIA 3090 GPU 上运行。评估指标包括 PSNR、SSIM、LPIPS(图像质量),以及 FPS 和模型大小(效率与紧凑性)。
4.2 Results and Evaluation
在标准真实场景和合成数据集上的实验结果表明,我们的方法在渲染质量上显著优于现有方法,并在保持实时性能的同时大幅缩小模型规模。与 3DGS 相比,模型大小减少超过 12 倍且质量更高;与 Scaffold-GS 相比,不仅渲染更精细,而且模型更紧凑、速度更快。在大规模真实场景中,我们的方法同样展现出更好的细节建模与光照适应能力,而 Scaffold-GS 和 3DGS 往往出现模糊和伪影。
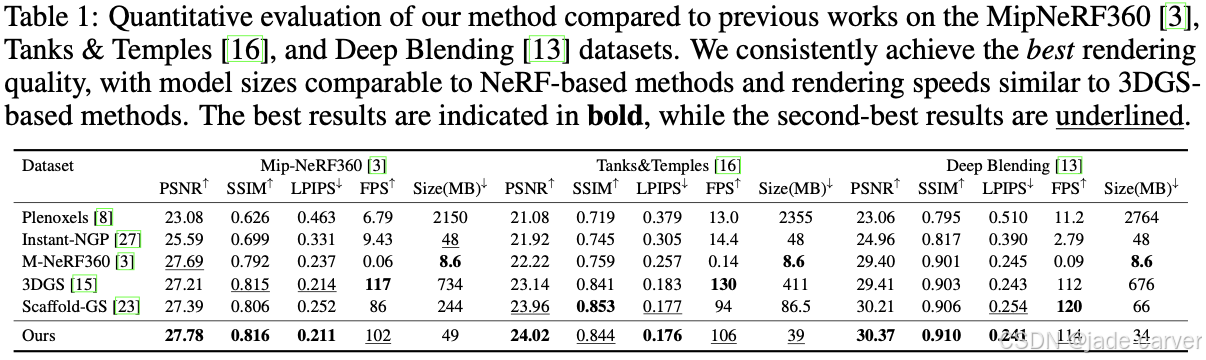

此外,我们的表示形式天然更紧凑,并兼容现有压缩方法。结合半精度存储、残差量化与 Huffman 编码后,我们在压缩结果上依然保持领先,不同于传统方法在存储效率与渲染质量之间的权衡。整体而言,该方法在渲染质量、模型紧凑性和速度上都实现了更优的平衡。
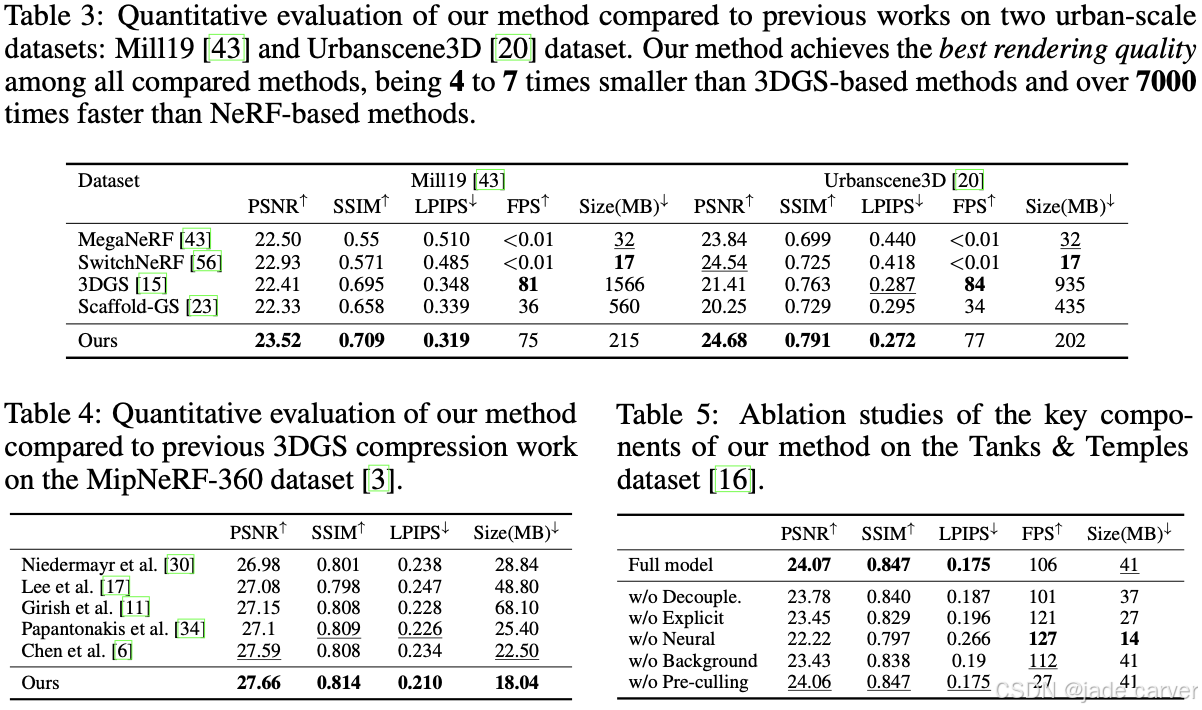
4.3 Model Analysis
解耦神经场(Decoupled Neural Fields):我们对比了使用解耦神经场与单一神经场预测所有高斯参数的效果。为保证公平性,单一神经场的最大哈希表大小设置为 2¹⁸,参数略多于解耦架构。结果(表 5)显示,单一神经场在所有图像质量指标上都有下降,这主要是因为单网络同时表示几何与外观属性存在困难,导致渲染精度下降和几何错误,如间隙和空洞(图 5)。

混合渲染(Hybrid Rendering):我们对比了混合渲染管线与传统 3DGS 光栅化方法。表 5 的定量结果表明,禁用背景渲染虽略微加快速度,但会显著降低视觉质量。这说明标准 3DGS 方法难以有效密化远景对象。定性分析(图 6)进一步显示,背景渲染对于保持远景高频细节至关重要,例如云的细节结构。

神经高斯(Neural Gaussians):我们的方法利用神经场预测 3D 高斯的各向异性形状和视角依赖颜色。若去掉这些神经组件,模型退化为各向同性高斯并采用漫反射渲染,表示能力有限,从而在新视角合成中出现明显质量下降(表 5)。
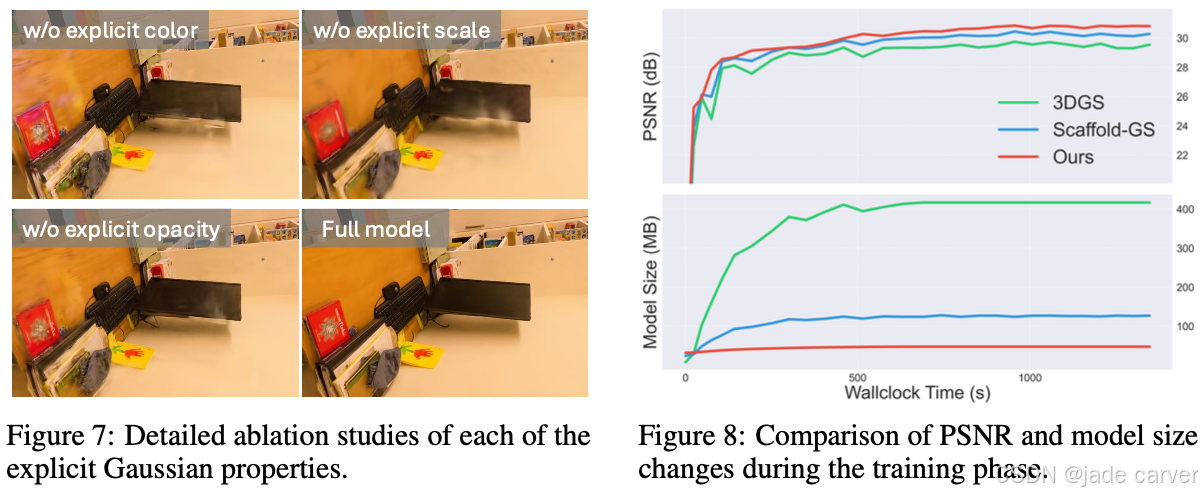
训练时间(Training Time):如图 8 所示,我们的方法在保持模型紧凑性的前提下,实现了明显更快的收敛速度。
显式高斯(Explicit Gaussians):我们通过消融实验评估了各显式高斯属性的贡献,仅保留位置用于神经场查询。结果表明,去掉显式颜色会导致光照建模困难和不自然的颜色;缺失显式尺度会严重影响细结构重建,并可能导致训练不稳定;缺失显式不透明度会产生悬浮物(floaters),降低输出质量(表 5、图 7)。
5 Conclusion
本方法在渲染速度上具备明显优势,为从虚拟制作到自动驾驶等依赖高质量新颖视图合成的应用提供了实用化解决方案,标志着向实时神经渲染迈出了关键一步。然而,该方法仍存在一些局限:它继承了原始3DGS的固有缺陷,如未能完全解决渲染走样问题,且表面重建精度有待进一步提升。此外,其高性能目前依赖于高端GPU的并行计算能力,如何在下游轻量化平台(如网页端或集成显卡)实现高效部署仍是未来需要探索的方向。