自然语言处理——情感分析 <下>
在上一篇博客《深度学习【项目】自然语言处理 —— 情感分析 <上>》中,我们完成了微博评论数据的预处理工作,包括评论文本固定长度处理、词表生成、数据集切分(训练集 / 验证集 / 测试集)。本文作为续篇,将聚焦数据打包、模型定义、训练测试函数实现、主函数调用四大核心环节,完整搭建基于 TextRNN(文本循环神经网络)的情感分析系统,实现对微博评论 “喜悦、愤怒、厌恶、低落” 四种情绪的自动识别。
https://blog.csdn.net/2302_76756558/article/details/152051387?spm=1001.2014.3001.5501
一、项目回顾与文件结构
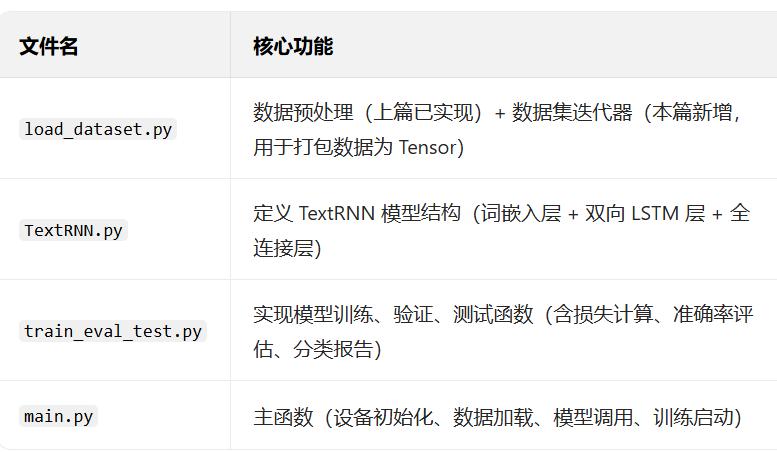
在开始前,先明确项目的整体文件结构(便于后续代码调用和管理)。截至目前,我们已准备好核心数据集 simplifyweibo_4_moods.csv(微博四分类情感数据)和预训练词向量 embedding_Tencent.npz(腾讯 AI Lab 开源的中文词嵌入模型),后续需创建 4 个 Python 文件实现完整流程:
二、核心模块实现
2.1 数据打包:实现 DatasetIterater(写入load_dataset.py)
上一篇我们得到了train_data、dev_data、test_data(格式为[(评论文本索引列表, 情感标签, 文本长度), ...]),但 PyTorch 训练需要批量(batch)Tensor 数据,且需适配 GPU/CPU 设备。因此,我们定义DatasetIterater类,实现数据的批量切分、Tensor 转换和设备分配。
import torch
from torch.utils.data import Dataset# 上篇已实现的函数(此处省略,包括load_dataset、build_vocab、pad_sequence等)
# ...# 本篇新增:数据集迭代器类
class DatasetIterater(object):"""数据集迭代器:将数据切分为指定batch_size的批次,转换为Tensor并分配到指定设备参数:batches: 预处理后的数据集(如train_data,格式为[(text_idx, label, seq_len), ...])batch_size: 每个批次的样本数量(此处设为128,平衡速度与显存)device: 计算设备(cuda/cpu/mps)"""def __init__(self, batches, batch_size, device):self.batch_size = batch_sizeself.batches = batchesself.n_batches = len(batches) // batch_size # 完整批次数self.residue = False # 是否存在剩余样本(无法凑满一个batch)# 检查是否有剩余样本if len(batches) % self.n_batches != 0:self.residue = Trueself.index = 0 # 当前迭代到的批次索引self.device = devicedef _to_tensor(self, datas):"""私有方法:将一批数据转换为PyTorch Tensor,并移动到指定设备"""# 提取评论文本索引(datas中每个元素的第0项)x = torch.LongTensor([_[0] for _ in datas]).to(self.device)# 提取情感标签(datas中每个元素的第1项)y = torch.LongTensor([_[1] for _ in datas]).to(self.device)# 提取文本实际长度(用于后续动态padding,datas中每个元素的第2项)seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)return (x, seq_len), y # 返回格式:(文本Tensor, 长度Tensor), 标签Tensordef __next__(self):"""迭代器核心方法:获取下一个批次的数据"""# 1. 处理剩余样本(最后一个不完整的batch)if self.residue and self.index == self.n_batches:batches = self.batches[self.index * self.batch_size : len(self.batches)]self.index += 1batches = self._to_tensor(batches)return batches# 2. 迭代结束:重置索引并抛出停止迭代异常elif self.index > self.n_batches:self.index = 0raise StopIteration# 3. 正常获取完整批次else:batches = self.batches[self.index * self.batch_size : (self.index + 1) * self.batch_size]self.index += 1batches = self._to_tensor(batches)return batchesdef __iter__(self):"""使类实例成为可迭代对象(支持for循环遍历)"""return selfdef __len__(self):"""返回迭代器的总批次数(含剩余样本批次)"""if self.residue:return self.n_batches + 1else:return self.n_batches关键说明:
_to_tensor方法将文本索引、标签、文本长度分别转换为LongTensor,并移动到指定设备(GPU/CPU),符合 PyTorch 训练要求;- 处理 “剩余样本” 避免数据浪费(如总样本 1000,batch_size=128,最后会有 8 个剩余样本,单独作为一个批次);
- 实现
__iter__和__next__方法,支持用for texts, labels in train_iter直接遍历批次数据。
2.2 模型定义:搭建 TextRNN(新建TextRNN.py)
情感分析的核心是捕捉文本的序列依赖关系(如 “虽然今天下雨,但我很开心” 中的转折关系),而 LSTM(长短期记忆网络)能有效解决传统 RNN 的梯度消失问题,适合处理文本数据。本项目采用双向 LSTM(同时从左到右、从右到左处理文本,捕捉更全面的上下文信息),模型结构如下:词嵌入层(Embedding)→ 双向LSTM层 → 全连接层(FC)→ 分类输出
import torch
import torch.nn as nnclass Model(nn.Module):"""TextRNN模型:用于文本情感分类参数:embedding_pretrained: 预训练词向量(None表示随机初始化)n_vocab: 词表大小(词汇总数)embed: 词向量维度(如200)num_classes: 情感类别数(此处为4:喜悦/愤怒/厌恶/低落)"""def __init__(self, embedding_pretrained, n_vocab, embed, num_classes):super(Model, self).__init__()# 1. 词嵌入层(Embedding Layer)if embedding_pretrained is not None:# 使用预训练词向量(如腾讯词嵌入),冻结与否根据需求设置(freeze=False表示可微调)self.embedding = nn.Embedding.from_pretrained(embedding_pretrained, padding_idx=n_vocab - 1, # padding符号的索引(词表最后一位)freeze=False)else:# 随机初始化词向量(n_vocab个词,每个词embed维)self.embedding = nn.Embedding(n_vocab, embed, padding_idx=n_vocab - 1)# 2. 双向LSTM层(Bi-LSTM Layer)self.lstm = nn.LSTM(input_size=embed, # 输入维度(词向量维度)hidden_size=128, # 隐藏层单元数(单向)num_layers=3, # LSTM层数(3层堆叠提升特征提取能力)bidirectional=True, # 启用双向LSTM(输出维度=128*2)batch_first=True, # 输入格式:(batch_size, seq_len, embed)(默认是seq_len在前)dropout=0.3 # dropout正则化(防止过拟合,仅中间层生效))# 3. 全连接层(Fully Connected Layer):将LSTM输出映射到类别数self.fc = nn.Linear(128 * 2, num_classes) # 双向LSTM输出维度=128*2def forward(self, x):"""前向传播函数:定义数据在模型中的流动路径参数:x: 输入数据(格式:(text_tensor, seq_len_tensor),来自DatasetIterater)返回:out: 模型预测输出(格式:(batch_size, num_classes),每个类别的概率得分)"""# 提取文本Tensor(忽略长度Tensor,LSTM会自动处理padding)x, _ = x # 词嵌入:(batch_size, seq_len) → (batch_size, seq_len, embed)out = self.embedding(x) # LSTM前向传播:out为所有时间步的隐藏状态,_为最后一个时间步的隐藏状态和细胞状态out, _ = self.lstm(out) # 取最后一个时间步的隐藏状态(双向拼接):(batch_size, seq_len, 256) → (batch_size, 256)out = out[:, -1, :] # 全连接层分类:(batch_size, 256) → (batch_size, num_classes)out = self.fc(out) return out关键说明:
- 词嵌入层使用
padding_idx确保 padding 符号(填充的 0)不参与梯度更新,避免影响模型; - 双向 LSTM 的输出维度是
hidden_size * 2(128*2=256),因为需要拼接 “正向” 和 “反向” 的隐藏状态; - 取
out[:, -1, :](最后一个时间步的输出)是因为文本的情感倾向通常由结尾的语义决定(如 “但是” 后的内容更关键)。
2.3 训练与测试:实现核心函数(新建train_eval_test.py)
该模块包含三个核心函数:
evaluate:验证 / 测试模型(计算损失、准确率、分类报告);test:加载最优模型,对测试集进行最终评估;train:模型训练主逻辑(梯度下降、参数更新、早停机制)。
import torch
import torch.nn.functional as F
import numpy as np
import time
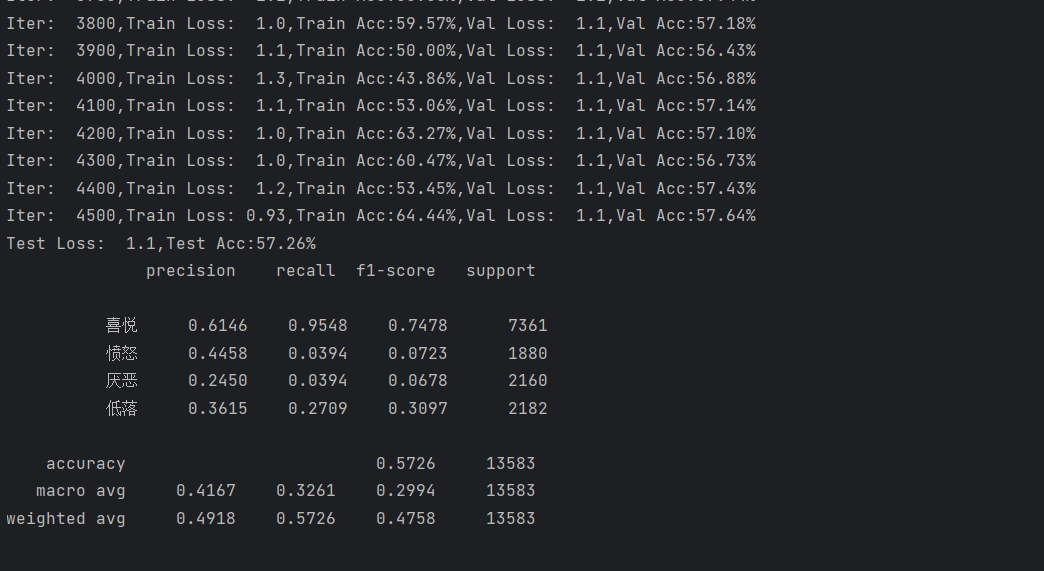
from sklearn import metricsdef evaluate(class_list, model, data_iter, test=False):"""模型评估函数(用于验证集和测试集)参数:class_list: 情感类别列表(如['喜悦','愤怒','厌恶','低落'])model: 待评估的模型data_iter: 评估数据集迭代器(dev_iter或test_iter)test: 是否为测试模式(测试模式需输出分类报告)返回:acc: 准确率avg_loss: 平均交叉熵损失report: 分类报告(仅测试模式返回,含precision/recall/f1)"""model.eval() # 切换为评估模式(禁用dropout)loss_total = 0 # 总损失predict_all = np.array([], dtype=int) # 所有预测标签labels_all = np.array([], dtype=int) # 所有真实标签# 禁用梯度计算(评估阶段无需更新参数,节省显存)with torch.no_grad():for texts, labels in data_iter:outputs = model(texts) # 模型预测:(batch_size, num_classes)loss = F.cross_entropy(outputs, labels) # 计算交叉熵损失(多分类常用)loss_total += loss.item() # 累加损失(注意.item()转换为Python数值)# 转换为numpy数组(便于后续用sklearn计算指标)labels_np = labels.data.cpu().numpy()# 取概率最大的索引作为预测标签(torch.max返回(values, indices))predict_np = torch.max(outputs.data, 1)[1].cpu().numpy()# 拼接所有样本的标签labels_all = np.append(labels_all, labels_np)predict_all = np.append(predict_all, predict_np)# 计算准确率(正确预测数/总样本数)acc = metrics.accuracy_score(labels_all, predict_all)avg_loss = loss_total / len(data_iter) # 平均损失(总损失/批次数)# 测试模式:输出分类报告(precision/recall/f1-score)if test:report = metrics.classification_report(labels_all, predict_all,target_names=class_list, # 类别名称(使报告更易读)digits=4 # 保留4位小数)return acc, avg_loss, reportreturn acc, avg_lossdef test(model, test_iter, class_list):"""测试函数:加载最优模型并评估测试集"""# 加载训练过程中保存的最优模型权重(TextRNN.ckpt)model.load_state_dict(torch.load('TextRNN.ckpt'))model.eval() # 切换为评估模式start_time = time.time()# 调用evaluate函数获取测试集指标test_acc, test_loss, test_report = evaluate(class_list, model, test_iter, test=True)# 打印测试结果print("=" * 50)print(f"Test Time: {time.time() - start_time:.2f}s")msg = "Test Loss: {0:>5.2f}, Test Accuracy: {1:>6.2%}"print(msg.format(test_loss, test_acc))print("\nTest Classification Report:")print(test_report)print("=" * 50)def train(model, train_iter, dev_iter, test_iter, class_list):"""模型训练函数参数:model: 待训练的模型train_iter: 训练集迭代器dev_iter: 验证集迭代器test_iter: 测试集迭代器class_list: 情感类别列表"""model.train() # 切换为训练模式(启用dropout)# 优化器:Adam(自适应学习率,训练效果优于SGD)optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # 学习率1e-3# 训练超参数与监控变量total_batch = 0 # 总批次数(用于监控训练进度)dev_best_loss = float('inf') # 验证集最优损失(初始设为无穷大)last_improve = 0 # 最后一次提升的批次数(用于早停机制)flag = False # 是否停止训练的标志epochs = 2 # 训练轮数(可根据数据量调整,此处为演示设为2)print("Start Training...")for epoch in range(epochs):print(f"\nEpoch [{epoch + 1}/{epochs}]")# 遍历训练集批次for i, (trains, labels) in enumerate(train_iter):outputs = model(trains) # 模型预测loss = F.cross_entropy(outputs, labels) # 计算损失optimizer.zero_grad() # 梯度清零(避免梯度累积)loss.backward() # 反向传播(计算梯度)optimizer.step() # 参数更新(根据梯度)# 每100个批次打印一次训练/验证效果if total_batch % 100 == 0:# 计算训练集当前批次的准确率predict = torch.max(outputs.data, 1)[1].cpu()train_acc = metrics.accuracy_score(labels.data.cpu(), predict)# 计算验证集指标dev_acc, dev_loss = evaluate(class_list, model, dev_iter)# 若验证集损失下降,更新最优损失并保存模型if dev_loss < dev_best_loss:dev_best_loss = dev_losstorch.save(model.state_dict(), 'TextRNN.ckpt') # 保存最优模型last_improve = total_batch # 更新最后提升批次# 打印日志msg = "Iter: {0:>6}, Train Loss: {1:>5.2f}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2f}, Val Acc: {4:>6.2%}"print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc))model.train() # 恢复训练模式(evaluate会切换为eval)total_batch += 1# 早停机制:若10000批未提升,停止训练(避免过拟合)if total_batch - last_improve > 10000:print("No optimization for a long time, auto-stopping...")flag = Truebreakif flag:break# 训练结束后,用测试集评估最优模型test运行结果如下: