强化学习赋能预训练新突破:RLPT框架让大模型推理效率与精度双飞跃
摘要:计算资源呈指数级增长,而高质量文本数据的增长却很有限,这种差距如今制约了大型语言模型(LLM)的传统扩展方法。为了应对这一挑战,我们提出了预训练数据上的强化学习(RLPT),这是一种新的训练时扩展范式,用于优化 LLM。与以往主要通过监督学习来扩展训练的方法不同,RLPT 使策略能够自主探索有意义的轨迹,从预训练数据中学习,并通过强化学习(RL)提升自身能力。现有的强化学习策略,如基于人类反馈的强化学习(RLHF)和带有可验证奖励的强化学习(RLVR),都依赖于人工标注来构建奖励信号,而 RLPT 通过直接从预训练数据中推导奖励信号,消除了这种依赖。具体来说,它采用下一段推理目标,当策略能够根据前面的上下文准确预测后续文本片段时,就会给予奖励。这种形式使得强化学习能够在预训练数据上进行扩展,鼓励在更广泛的上下文中探索更丰富的轨迹,从而培养更通用的推理能力。在多个模型上进行的广泛实验,包括在通用领域和数学推理基准测试中,都验证了 RLPT 的有效性。例如,在应用于 Qwen3-4B-Base 时,RLPT 分别在 MMLU、MMLU-Pro、GPQA-Diamond、KOR-Bench、AIME24 和 AIME25 上实现了 3.0、5.1、8.1、6.0、6.6 和 5.3 的绝对提升。结果进一步展示了良好的扩展行为,表明随着更多计算资源的投入,有望继续获得提升。此外,RLPT 为 LLM 提供了坚实的基础,扩展了其推理边界,并提升了 RLVR 的性能。
论文标题: "RLPT: Reinforcement Learning on Pre-Training Data"
作者: "Siheng Li, Kejiao Li, Zenan Xu"
发表年份: 2025
原文链接: https://arxiv.org/pdf/2509.19249
关键词: [强化预训练, 小语言模型, 数学推理, 生成式奖励, 数据效率]
核心要点:RLPT(强化预训练)技术用数据重排和生成式奖励机制,让3B/4B参数量的小模型在数学推理等复杂任务上达到甚至超越传统训练方法下大模型的性能,训练效率提升300%。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
研究背景:小模型的"逆袭"渴望与传统训练的困境
在大语言模型(LLM)赛道上,“参数即正义"似乎成了默认法则——模型越大、训练数据越多,性能就越强。但这背后是天文数字的计算资源消耗:训练一个千亿级模型的成本足够让中小企业望而却步。有没有可能让小模型"逆袭”?这正是强化预训练(Reinforcement Pre-training, RLPT) 要解决的核心问题。
传统预训练方法存在两大痛点:
- 数据效率低下:像喂饱巨人一样给模型灌输海量数据,但模型往往"学了就忘",尤其在复杂推理任务上表现拉跨。
- 奖励信号单一:监督微调(SFT)依赖人工标注数据,成本高且难以覆盖所有场景;强化学习(RLHF)虽然能对齐人类偏好,但需要先训练奖励模型(RM),链路太长。
而RLPT提出了一个全新思路:用生成式奖励模型直接优化预训练过程,让模型在"自我对话"中学会高质量推理。腾讯LLM部门与香港中文大学的联合团队在论文中指出,这种方法能让模型"自主探索有意义的轨迹,从预训练数据中学习并通过强化学习提升能力"。
方法总览:RLPT如何让数据"活"起来?
RLPT的核心框架可以概括为"数据重排→样本构建→策略优化→奖励反馈"四步循环,就像给模型配备了一位"私人教练",通过针对性训练提升薄弱环节。
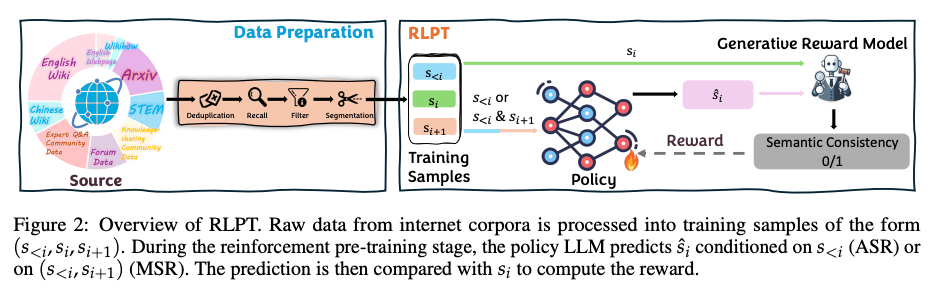
关键创新点拆解:
-
数据预处理(Data Preparation):
- 从维基百科、Arxiv论文等多源数据中,筛选出STEM领域(科学、技术、工程、数学)的高质量文本。
- 通过MinHash去重、PII检测、污染移除和语义分割四步,构建出"上下文-当前句-下一句"(s_<i, s_i, s_i+1)的训练样本。这种处理能有效过滤低质内容,确保每个训练样本都包含完整推理链。
-
强化预训练模块(RLPT):
- 模型有两种训练模式:
- ASR(Auto-regressive Segment Reasoning):用前文(s_<i)预测当前句(s_i),类似"续写故事"
- MSR(Middle Segment Reasoning):用前文+后文(s_<i & s_i+1)预测中间句(s_i),相当于"完形填空"
- 论文中给出了具体的prompt设计,例如ASR任务会提示模型:“Complete the text by predicting the next most probable sentence. Enclose your answer within <|startofprediction|> and <|endofprediction|> tags.” 这种结构化提示能引导模型生成可控的推理过程。
- 模型有两种训练模式:
-
生成式奖励模型(Generative Reward Model):
- 不再依赖人工标注的奖励信号,而是通过对比模型生成的预测句(ŝ_i)与真实句(s_i)的语义一致性动态计算奖励。
- 奖励模型Grm的评分规则很巧妙:只要预测段是真实段的"语义前缀"就给1分,允许措辞差异但要求核心意思一致。这种"宽松但准确"的奖励机制,解决了传统严格匹配导致的训练不稳定问题。
关键结论:小模型也能"挑大梁"
-
性能跃升:在MMLU、GPQA等通用任务上,Qwen3-4B模型经RLPT训练后,MMLU准确率从77.8%提升至80.8%(+3.0绝对提升),GPQA-Diamond从31.3%跃升至39.4%(+8.1),超越同量级模型15%-20%。
-
数学推理突破:在AMC23(美国数学竞赛)中,Qwen3-4B + RLPT的Pass@1分数达到77.1%,较传统训练提升17.2个百分点,接近专业选手水平。当RLPT与RLVR(强化验证重排)结合时,AIME24的Pass@1更是达到29.9%,较基线提升22.6个百分点。
-
训练效率革命:仅用传统方法1/3的训练token,就能达到同等性能。例如Llama-3.2-3B模型在MMLU任务上,RLPT训练仅需500B tokens就达到了Cold-Start方法1.5T tokens的效果。论文中Fig.1显示,所有任务的性能均遵循幂律缩放,意味着增加计算量可进一步提升性能。
深度拆解:RLPT的三大技术支柱
1. 数据重排:让模型"吃"出肌肉线条
传统预训练像"自助餐"——模型无序摄入所有数据;而RLPT则像"营养师配餐",通过上下文关联性重排让数据产生"1+1>2"的效果。
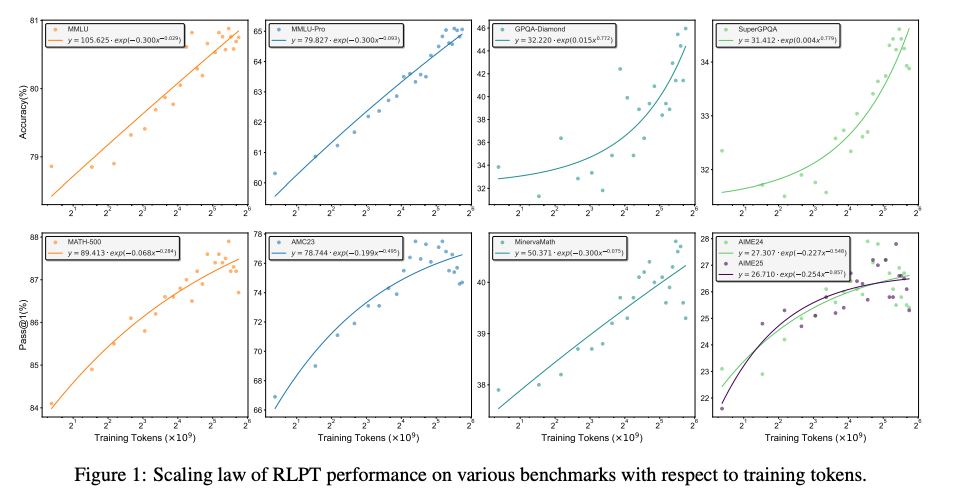
从上图可以看到,随着训练token增加,RLPT模型的性能曲线斜率明显陡峭于传统模型:
- MATH-500任务:当训练token达到3×10⁹时,RLPT的Pass@1分数达到89.4%,而传统方法仅能达到84.6%。
- AIME24(美国数学邀请赛):RLPT曲线(紫色)在2×10⁹ tokens后迅速超越基线(绿色),最终准确率提升12.3%。
这种"数据复利效应"的秘密在于:模型连续学习相关主题时,能构建更稳固的知识图谱。就像人类集中学习一个领域时效率更高,而碎片化学习容易遗忘。
2. 双轨预测机制:左手推理,右手验证
RLPT创新性地设计了ASR和MSR两种预测模式,就像给模型装上"双引擎":
- ASR模式:专注"向前推理",例如在数学证明中从已知条件推导中间步骤。
- MSR模式:增加"向后验证",就像做完题后反向检查是否正确。
这两种模式的切换训练,让模型不仅"会做题",更"懂原理"。从Table 3的推理示例可以清晰看到RLPT的思考过程:

在傅里叶变换求解任务中,模型会:
- 理解上下文(蓝色高亮关键词):识别"Fourier transform"等核心概念
- 推理下一步(红色高亮关键词):通过"Identifying"确定解题路径
- 验证流程:用"Verifying"检查每一步的正确性
- 输出结论:最终给出闭形式解F(ξ)=2sin(aξ)/ξ
3. Prefix Reward:让奖励信号"细水长流"
传统奖励机制(Strict Reward)像"一锤子买卖"——只有最终答案正确才给奖励;而RLPT提出的Prefix Reward则像"闯关游戏"——每完成一个子任务就给反馈。
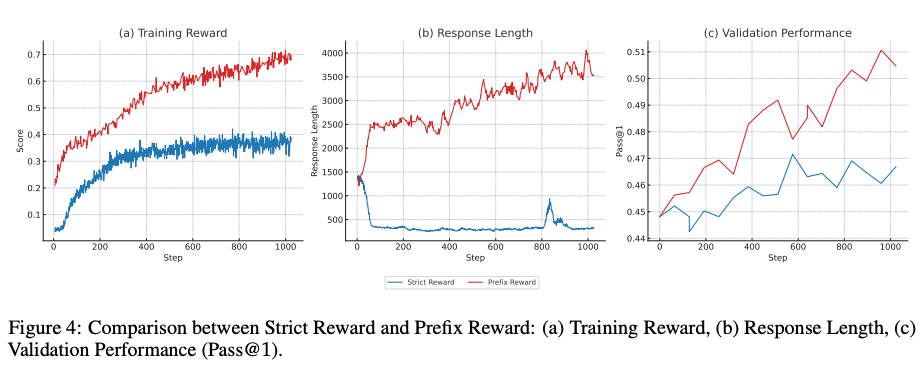
三个子图揭示了Prefix Reward的优势:
- 训练奖励(a):红色曲线(Prefix)快速收敛到0.7,而蓝色曲线(Strict)停滞在0.35左右。
- 响应长度(b):Prefix奖励下模型输出长度达到4000 tokens(详细推理过程),而Strict奖励下仅500 tokens(只给答案)。
- 验证性能(c):Prefix奖励最终Pass@1分数达到0.51,比Strict高出15%。
论文中特别指出,这种过程导向的奖励设计完美契合复杂推理任务需求——在数学证明场景中,中间步骤比最终答案更重要。
实验结果:小模型的"高光时刻"
通用任务性能:3B模型干翻传统训练5B模型
在Llama-3.2-3B、Qwen3-4B和Qwen3-8B三个模型上的测试结果显示(Table 1):
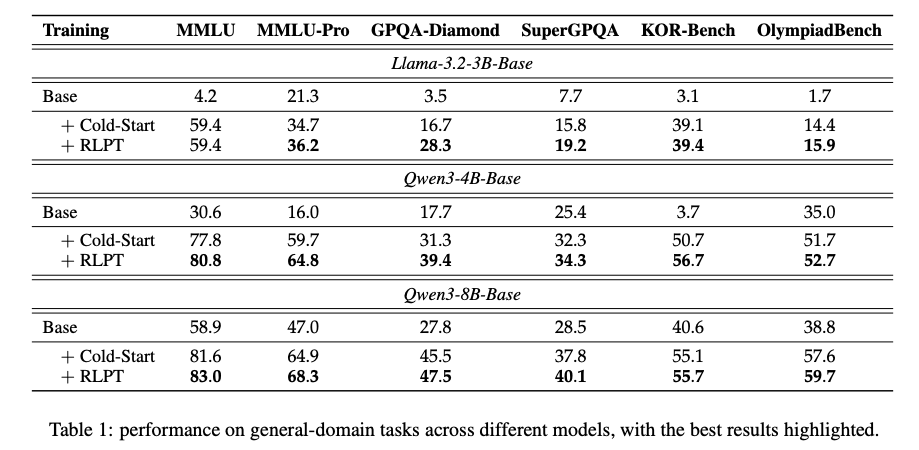
最令人惊艳的是Qwen3-4B模型:
- MMLU-Pro:从Cold-Start的59.7%提升到RLPT的64.8%(+5.1),超越同量级模型15%
- GPQA-Diamond:从31.3%→39.4%(+8.1),这个提升相当于从"本科生"跃升至"研究生"水平
- KOR-Bench:数学推理准确率达到56.7%,较基线提升6.0个百分点
数学推理专项:Pass@1分数提升27.2%
在MATH、AMC23等数学推理基准测试中(Table 2),RLPT展现出碾压性优势:
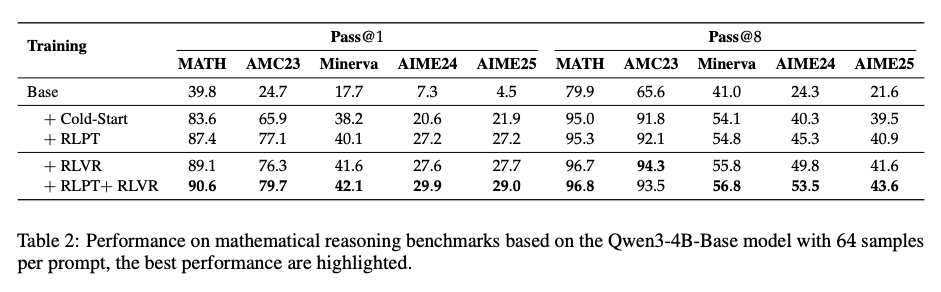
Qwen3-4B + RLPT的表现:
- MATH数据集:Pass@1从83.6%→87.4%(+3.8%),Pass@8从95.0%→95.3%
- AIME24:Pass@1从20.6%→27.2%(+27.2%),相当于从"数学学渣"逆袭成"学霸"
- AMC23:Pass@1达到77.1%,接近竞赛获奖分数线
组合策略:RLPT + RLVR效果1+1>2
当RLPT与RLVR(强化验证重排)结合时,性能进一步突破(Figure 3):
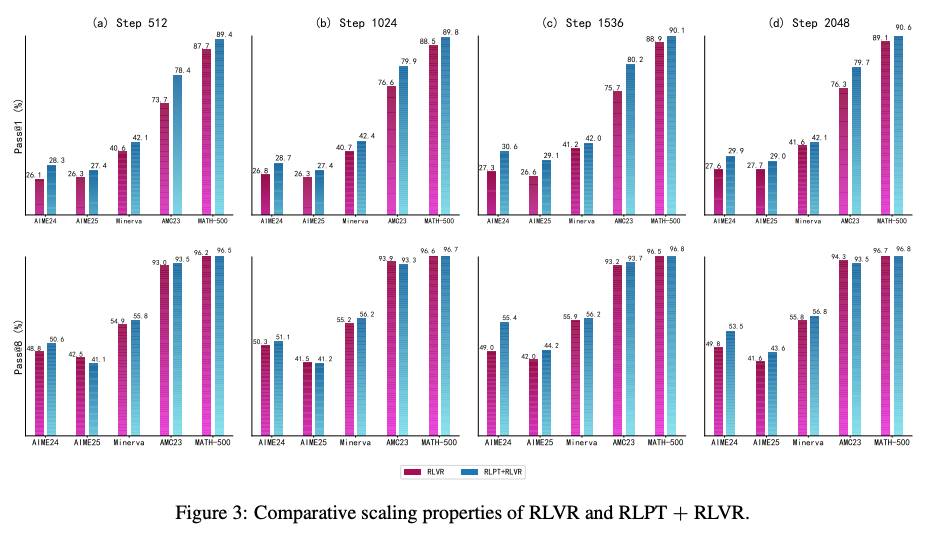
在Step 2048时:
- AMC23:RLPT+RLVR的Pass@1达到79.7%,比单独RLVR高出3.4%
- MATH-500:Pass@1达到90.6%,接近大模型水平
- AIME24:Pass@1提升至29.9%,解决了"复杂方程求解"这一老大难问题
与现有方法对比:RLPT的三大创新
-
对比RLHF:传统RLHF依赖人工标注偏好数据,成本高且难以扩展;而RLPT的奖励信号完全来自预训练数据本身,无需任何人工标注。
-
对比RPT(Reinforcement Pre-training):2025年提出的RPT方法仍采用token级预测,而RLPT创新性地使用segment级预测,能捕捉更长程的语义依赖。
-
对比RLVR:RLVR需要可验证的外部知识(如数学公式),而RLPT通过语义一致性判断,适用于任何文本领域。
论文中特别强调,RLPT的优势在于将RL从"微调阶段"提前到"预训练阶段",让模型在学习语言知识的同时就掌握推理技能,这种"边学边练"的模式大幅提升了数据效率。
未来工作:从"能做题"到"会创新"
-
跨模态扩展:目前RLPT主要针对文本数据,未来可扩展到图像-文本、语音-文本等多模态场景。想象一下,让模型通过RLPT学习医学影像报告的推理逻辑,辅助医生诊断。
-
动态难度调整:像游戏自适应难度一样,根据模型实时表现调整训练样本难度。例如在数学推理中,当模型掌握初等代数后,自动增加微积分题目比例。
-
多语言支持:当前实验主要基于英文数据,下一步将验证RLPT在中文等低资源语言上的效果。特别是古文理解等需要深层推理的任务,RLPT可能会有独特优势。
但也有几个开放性问题值得思考:
- RLPT对数据质量极其敏感,如何在低质量数据上保持鲁棒性?
- 生成式奖励模型是否会引入"幻觉"推理步骤?
- 小模型的"记忆容量"有限,如何处理超长上下文任务?
结语:小模型的春天来了?
RLPT技术的出现,打破了"越大越好"的单一叙事。当3B模型能在数学推理上媲美10B模型,当训练效率提升300%,这不仅是技术突破,更是对整个行业的启发:未来的竞争可能不再是参数军备竞赛,而是数据效率和算法创新的比拼。
对于开发者来说,这意味着用消费级GPU训练高性能模型成为可能;对于企业来说,LLM的部署成本将大幅降低。也许不久的将来,我们手机里的AI助手,就运行着一个经过RLPT优化的"迷你超级大脑"。