Removal of Hallucination on Hallucination: Debate-Augmented RAG(ACL 2025)
研究方向:Image Captioning
1.论文介绍
本文提出了辩论增强的RAG(DRAG),一个无需训练的框架,它将多智能体辩论(MAD)机制整合到RAG的检索和生成阶段。
在检索中,DRAG采用支持检索策略的支持者、质疑查询充分性的反对者和评估完整性的裁判之间的结构化辩论来提高检索质量并确保事实可靠性。
在生成中,DRAG引入了非对称信息角色和对抗性辩论,增强了推理的鲁棒性并减轻了事实不一致性,提高了检索可靠性,减少了RAG引起的幻觉。
注:MAD引入多个独立的大型语言模型智能体参与结构化辩论,通过批判性评估和多智能体验证迭代精炼他们的回应,提高事实一致性并在推理中增强了鲁棒性。此外,通过为智能体分配不同的角色,MAD促进了观点多样性,从而减轻了单一智能体方法中出现的偏见。
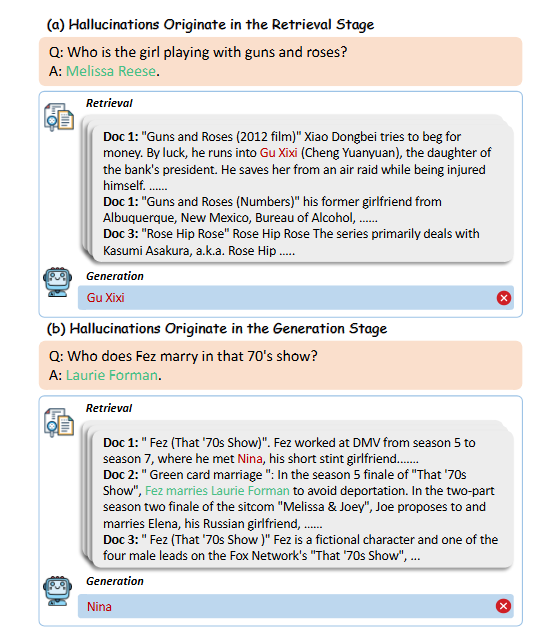
上图为检索增强生成中的幻觉演示:
- 在第一个例子中,错误源于检索了一部同名电影的信息,而不是正确的实体(乐队)。
- 在第二个例子中,尽管检索到了准确的信息,但检索噪声仍然会导致错误的响应。
2.方法介绍
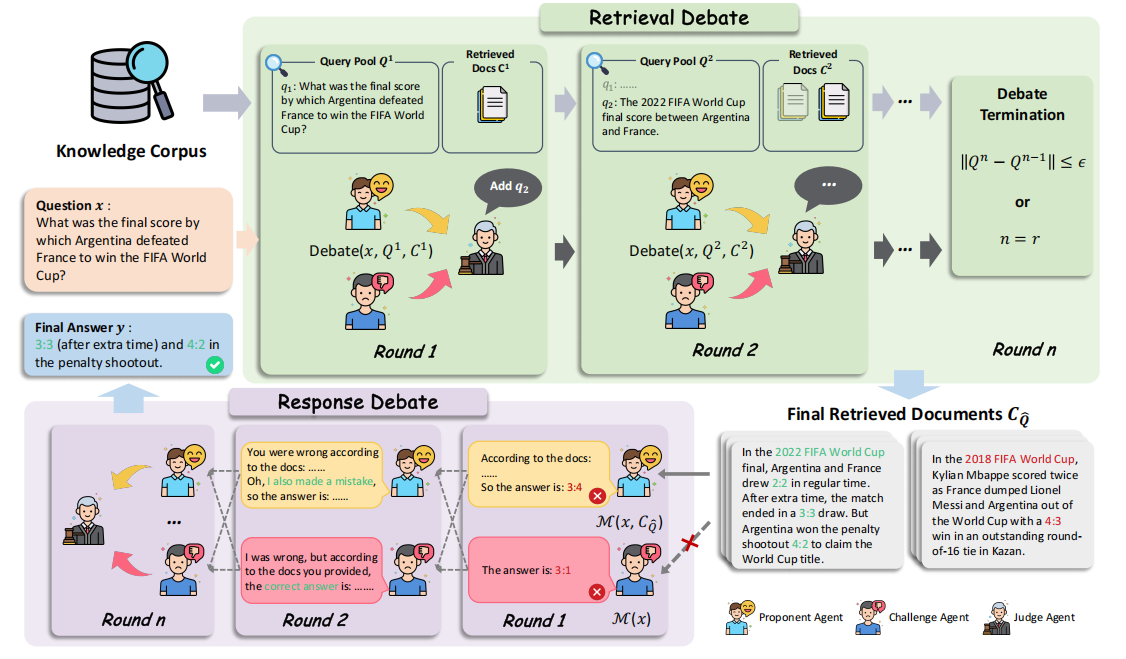
给定一个问题,检索器
(E5-base-v2)从知识语料库
(Wikipedia dump (Dec 2018))中检索出
-
(3)个支持段落
:
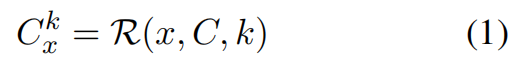
检索结束后,检索到的段落 和问题
用于提示大型语言模型(Llama-3.1-8B-Instruct)
,然后生成答案
:
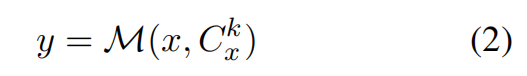
2.1 检索辩论
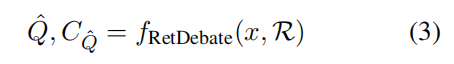
代表针对问题x的n个查询构成的最优查询池,而
表示对于
里的每一个 query,用检索器 R 去知识库里取 top-k 文档,把这些文档合并得到的证据集合。
在m个不同代理之间就优化检索池Q的多轮辩论,第
轮辩论:
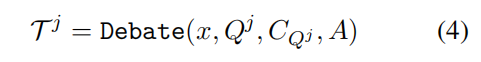
支持者代理:保持 不变,需要提供理由来支持当前查询
是合理的,并且检索到的结果
是充分的。
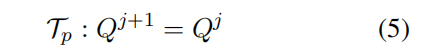
挑战者代理:对 进行批评,提出对不合理查询的修改或发起新的检索查询,以满足进一步的知识需求。因此挑战者代理坚持对查询池
进行精细化操作:
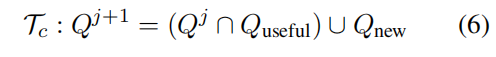
表示挑战者代理认为必须保留的
中的查询子集。
是挑战者代理引入的额外查询,用以补充信息或提升检索质量。
裁判代理:
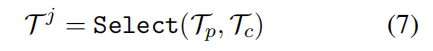
更新查询池:初始查询集 开始,每轮辩论后,根据裁判代理的决定,查询池
会进行迭代细化,并得到
。
辩论过程迭代进行,直到满足收敛标准:
当
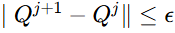 时,查询集收敛,其中 ϵ(0)是预定义的阈值,确保最小的查询修改。
时,查询集收敛,其中 ϵ(0)是预定义的阈值,确保最小的查询修改。达到最大辩论轮数 r(3,过多会导致问题漂移)。
一旦辩论结束,最终查询集 将用于检索,形成下一阶段响应辩论的证据集
。
2.2 响应辩论
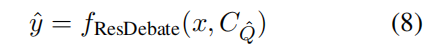
用代理之间的直接交互对话、并通过信息不对称的角色分配来对证据集合进行逐步验证与稳健化,从而减少幻觉中的幻觉。
支持者代理:
第一轮:基于检索到的证据集合 给出初始答案:
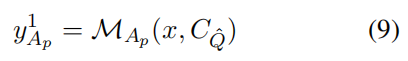
第 轮(
> 1):在自己历史回答和挑战者代理上一轮回答的基础上改进自己的答案:
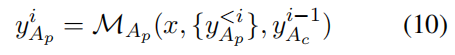
注:支持者代理始终依赖检索证据集合 + 对手的质疑来修正答案。
挑战者代理:
第一轮:完全基于内部知识(不看检索证据)给出初始答案:
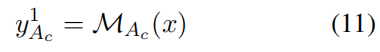
第 轮(
> 1):结合自己的历史回答与支持者代理上一轮答案来修正:
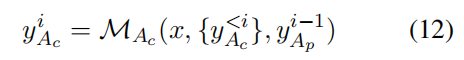
注:挑战者代理扮演一个独立思考者,不会被检索证据集合直接绑架,能指出检索证据中的错误或缺陷。
裁判代理:
在达到最大辩论轮数 (3,过多会导致问题漂移)后,裁判代理会比较两个最终候选答案得出最终输出:
![]()

3. 局限性
- 在检索和响应阶段引入的多代理辩论增加了计算开销。尽管检索阶段使用了一个裁判代理动态地在收集到足够证据时提前终止,但响应阶段目前使用固定数量的辩论轮次,这可能导致不必要的LLM调用,尤其是在简单的单跳任务中。
- 问题漂移,过度推理增加了不必要的复杂性,并在直接场景中降低了有效性。尽管DRAG很好地适应了检索深度,但其响应阶段缺乏这种灵活性。