人事处网站开发文献综述深圳公司有哪些
微调
网络架构
- 一个神经网络一般可以分成两块
- 特征抽取将原始像素变成容易线性分割的特性
- 线性分类器来做分类
微调
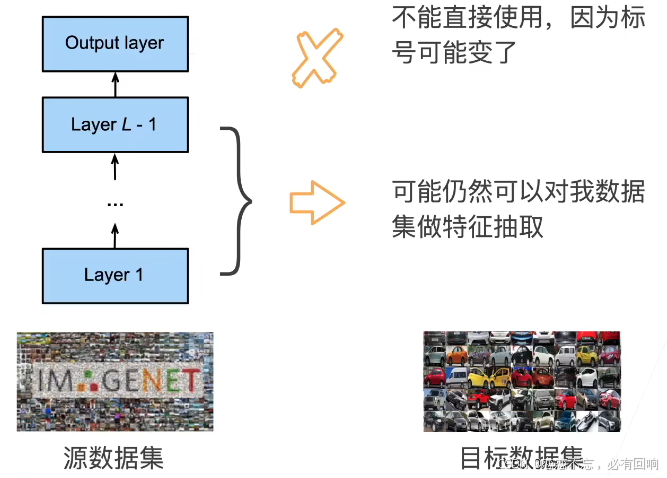
微调中的权重初始化
假设在原数据集上训练好了一个模型(Pre-train),然后要训练自己的模型的时候,使用一个和 Pre-train 架构一样的模型。则模型的初始化不是随机的了,而是从 Pre-train 中将特征提取模块复制过来,作为初始化模型,使得起始时还能做到不错的特征表达。最后一层可能由于标号不一样,因此可以随机初始化。
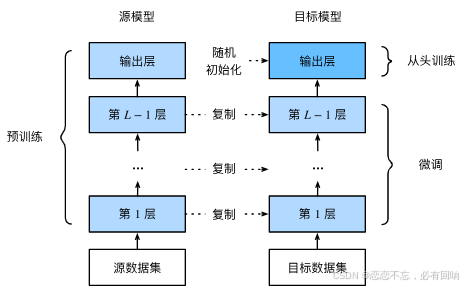
训练
- 是一个目标数据集上的正常训练任务,但使用更强的正则化
- 使用更小的学习率
- 使用更少的数据迭代
- 源数据集远复杂于目标数据,通常微调效果更好
重用分类器权重
- 源数据集可能也有目标数据中的部分标号
- 可以使用预训练好模型分类器中对应标号对应的向量来做初始化
固定一些层
- 神经网络通常学习有层次的特征表示
- 低层次的特征更加通用
- 高层次的特征则更跟数据集相关
- 可以固定底部一些层的参数,不参与更新
- 更强的正则
总结
- 微调通过使用在大数据上得到的预训练好的模型来初始化模型权重来完成提升精度
- 预训练模型质量很重要
- 微调通常速度更快、精度更高
代码实现
首先导入必要的库:
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
下面使用的是热狗数据集,该数据集来源于网络:
#@save
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')data_dir = d2l.download_extract('hotdog')train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
可以看一下数据集的部分数据,发现图像的大小和纵横比各有不同:
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);

数据增广:
# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 因为在 ImageNet 上训练的模型做了这个normalizetrain_augs = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(224),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor(),normalize])test_augs = torchvision.transforms.Compose([torchvision.transforms.Resize([256, 256]),torchvision.transforms.CenterCrop(224),torchvision.transforms.ToTensor(), normalize])
定义和初始化模型:
pretrained_net = torchvision.models.resnet18(pretrained=True)pretrained_net.fc

finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2) # 将标号改为 2
nn.init.xavier_uniform_(finetune_net.fc.weight);
微调模型
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
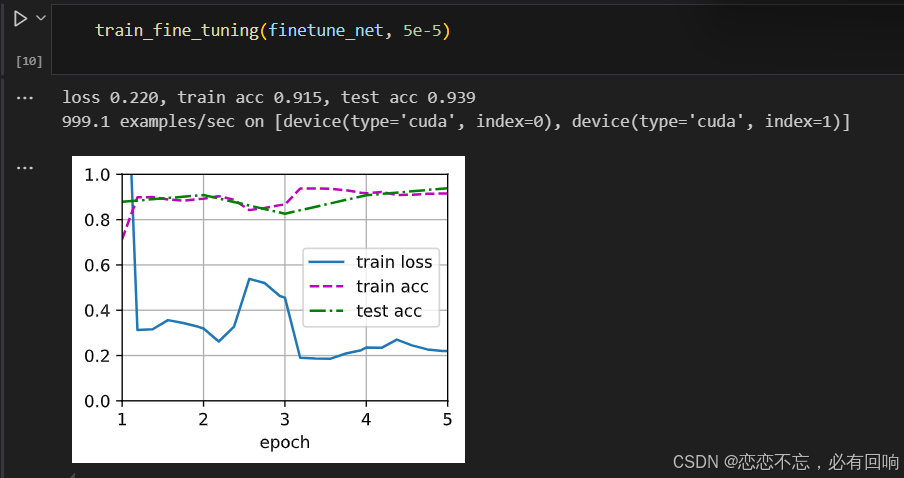
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,param_group=True):train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),batch_size=batch_size, shuffle=True)test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),batch_size=batch_size)devices = d2l.try_all_gpus()loss = nn.CrossEntropyLoss(reduction="none")if param_group:params_1x = [param for name, param in net.named_parameters()if name not in ["fc.weight", "fc.bias"]]trainer = torch.optim.SGD([{'params': params_1x},{'params': net.fc.parameters(),'lr': learning_rate * 10}],lr=learning_rate, weight_decay=0.001)else:trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0.001)d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)
使用较小的学习率
测试精度高于训练精度,使其一开始正确率就比较高了,后续有些抖动,但是没有关系。
为了进行比较,所有模型参数初始化为随机值
这里的学习率可能过低了,可以适当的调大一些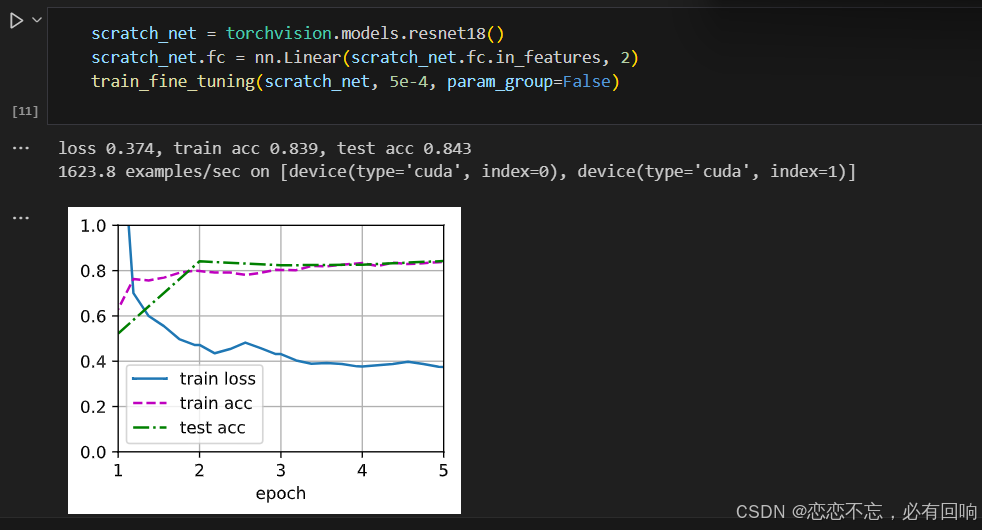
建议从微调开始,不要从 0 开始训练。
QA思考
Q1:微调这部分是意味着,神经网络进行不同的目标检测,前面层的网络进行特征提取是通用的么?
A1:是的,越是接近输入,特征越通用。
Q2:重用标号的话,对于无关的标号是直接删除吗,原始模型中没有的标号怎么加进去呢?
A2:有的标号就拿出来,没有的就随机。
Q3:微调的话,源数据集中的样本是否必须包含目标数据集里的类别?
A3:不需要,只需要类似就可以,但是源数据集和目标数据集差异不能很大,例如我是在 ImageNet 上训练的模型,我现在作用于医学上面,这样还不如随机初始化参数进行训练。
后记
写了一段类似的代码,但是还没有运行,不知道结果如何,有时间再运行:
import hashlib
import os
import tarfile
import zipfile
import time
import numpy as np
import requests
import torch
import torchvision
from torch.utils import data
from tqdm import tqdm
from torch.nn import functional as F
from torch import nn
from matplotlib import pyplot as plt
from PIL import Image# 数据加载和处理模块
class DataHandler:DATA_HUB = {'hotdog': ('http://d2l-data.s3-accelerate.amazonaws.com/hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')}DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'def __init__(self, cache_dir=os.path.join('..', 'data')):self.cache_dir = cache_dirdef download(self, name):"""下载一个DATA_HUB中的文件,返回本地文件名"""assert name in self.DATA_HUB, f"{name} 不存在于 {self.DATA_HUB}"url, sha1_hash = self.DATA_HUB[name]os.makedirs(self.cache_dir, exist_ok=True)fname = os.path.join(self.cache_dir, url.split('/')[-1])if os.path.exists(fname):sha1 = hashlib.sha1()with open(fname, 'rb') as f:while True:data = f.read(1048576)if not data:breaksha1.update(data)if sha1.hexdigest() == sha1_hash:return fname # 命中缓存print(f'正在从{url}下载{fname}...')r = requests.get(url, stream=True, verify=True)with open(fname, 'wb') as f:f.write(r.content)return fnamedef download_extract(self, name, folder=None):"""下载并解压zip/tar文件"""fname = self.download(name)base_dir = os.path.dirname(fname)data_dir, ext = os.path.splitext(fname)if ext == '.zip':fp = zipfile.ZipFile(fname, 'r')elif ext in ('.tar', '.gz'):fp = tarfile.open(fname, 'r')else:assert False, '只有zip/tar文件可以被解压缩'fp.extractall(base_dir)return os.path.join(base_dir, folder) if folder else data_dirdef load_hotdog_data(self):data_dir = self.download_extract('hotdog')train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))return train_imgs, test_imgs# 图像显示模块
class ImageDisplayer:def set_image_display_size(self):plt.figure(figsize=(8, 6))def load_image(self, img_path):return Image.open(img_path)def show_single_image(self, img):plt.imshow(img)plt.axis('on')plt.show()def show_images(self, imgs, num_rows, num_cols, titles=None, scale=1.5):figsize = (num_cols * scale, num_rows * scale)_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):ax.imshow(img.numpy())else:ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])return axesdef apply_augmentation(self, img, aug, num_rows=2, num_cols=4, scale=1.5):Y = [aug(img) for _ in range(num_rows * num_cols)]self.show_images(Y, num_rows, num_cols, scale=scale)# 模型评估和训练辅助模块
class TrainingUtils:def accuracy(self, y_hat, y):"""计算准确率"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())def train_batch_ch13(self, net, X, y, loss, trainer, devices):if isinstance(X, list):X = [x.to(devices[0]) for x in X]else:X = X.to(devices[0])y = y.to(devices[0])net.train()trainer.zero_grad()pred = net(X)l = loss(pred, y)l.sum().backward()trainer.step()train_loss_sum = l.sum()train_acc_sum = self.accuracy(pred, y)return train_loss_sum, train_acc_sumdef try_all_gpus(self):"""尝试获取所有可用的GPU"""devices = [torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())]return devices if devices else [torch.device('cpu')]# 训练过程可视化和计时模块
class TrainingVisualizer:def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), figsize=(3.5, 2.5)):if legend is None:legend = []self.xlabel = xlabelself.ylabel = ylabelself.legend = legendself.xlim = xlimself.ylim = ylimself.xscale = xscaleself.yscale = yscaleself.fmts = fmtsself.figsize = figsizeself.X, self.Y = [], []def add(self, x, y):if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)def show(self):plt.figure(figsize=self.figsize)for x_data, y_data, fmt in zip(self.X, self.Y, self.fmts):plt.plot(x_data, y_data, fmt)plt.xlabel(self.xlabel)plt.ylabel(self.ylabel)if self.legend:plt.legend(self.legend)if self.xlim:plt.xlim(self.xlim)if self.ylim:plt.ylim(self.ylim)plt.xscale(self.xscale)plt.yscale(self.yscale)plt.grid()plt.show()class Timer:def __init__(self):self.times = []self.start()def start(self):self.tik = time.time()def stop(self):self.times.append(time.time() - self.tik)return self.times[-1]def sum(self):return sum(self.times)def avg(self):return sum(self.times) / len(self.times)def cumsum(self):return np.array(self.times).cumsum().tolist()class Accumulator:def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]# 模型定义模块
class Residual(nn.Module):def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels,kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels,kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)self.relu = nn.ReLU(inplace=True)def forward(self, X):Y = F.relu((self.bn1(self.conv1(X))))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu((Y))def resnet18(num_classes, in_channels=1):def resnet_block(in_channels, out_channels,num_residuals, first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(in_channels, out_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(out_channels, out_channels))return nn.Sequential(*blk)net = nn.Sequential(nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64),nn.ReLU())net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))net.add_module("resnet_block2", resnet_block(64, 128, 2))net.add_module("resnet_block3", resnet_block(128, 256, 2))net.add_module("resnet_block4", resnet_block(256, 512, 2))net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1, 1)))net.add_module("fc", nn.Sequential(nn.Flatten(),nn.Linear(512, num_classes)))return netdef init_weights(m):if type(m) in [nn.Linear, nn.Conv2d]:nn.init.xavier_uniform_(m.weight)# 模型训练模块
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices=TrainingUtils().try_all_gpus()):timer, num_batches = Timer(), len(train_iter)animator = TrainingVisualizer(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],legend=['train loss', 'train acc', 'test acc'])net = nn.DataParallel(net, device_ids=devices).to(devices[0])epoch_times = []for epoch in range(num_epochs):epoch_start_time = time.time()metric = Accumulator(4)with tqdm(train_iter, desc=f'Epoch {epoch + 1}/{num_epochs}', unit='batch') as pbar:for i, (features, labels) in enumerate(pbar):timer.start()utils = TrainingUtils()l, acc = utils.train_batch_ch13(net, features, labels, loss, trainer, devices)metric.add(l, acc, labels.shape[0], labels.numel())timer.stop()train_loss = metric[0] / metric[2]train_acc = metric[1] / metric[3]pbar.set_postfix({'train_loss': train_loss, 'train_acc': train_acc})if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_loss, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))epoch_end_time = time.time()epoch_time = epoch_end_time - epoch_start_timeepoch_times.append(epoch_time)print(f'Epoch {epoch + 1} training time: {epoch_time:.2f} seconds')print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')total_time = sum(epoch_times)print(f'Total training time for {num_epochs} epochs: {total_time:.2f} seconds')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')animator.show()def evaluate_accuracy_gpu(net, data_iter, device=None):if isinstance(net, nn.Module):net.eval()if not device:device = next(iter(net.parameters())).devicemetric = Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)utils = TrainingUtils()metric.add(utils.accuracy(net(X), y), y.numel())return metric[0] / metric[1]def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,param_group=True):data_handler = DataHandler()normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(224),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor(),normalize])test_augs = torchvision.transforms.Compose([torchvision.transforms.Resize([256, 256]),torchvision.transforms.CenterCrop(224),torchvision.transforms.ToTensor(), normalize])train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_handler.cache_dir, 'hotdog', 'train'), transform=train_augs),batch_size=batch_size, shuffle=True)test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_handler.cache_dir, 'hotdog', 'test'), transform=test_augs),batch_size=batch_size)loss = nn.CrossEntropyLoss(reduction="none")if param_group:params_1x = [param for name, param in net.named_parameters()if name not in ["fc.weight", "fc.bias"]]trainer = torch.optim.SGD([{'params': params_1x},{'params': net.fc.parameters(),'lr': learning_rate * 10}],lr=learning_rate, weight_decay=0.001)else:trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0.001)train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs)if __name__ == "__main__":# 使用较小的学习率finetune_net = torchvision.models.resnet18(pretrained=True)finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)nn.init.xavier_uniform_(finetune_net.fc.weight)train_fine_tuning(finetune_net, 5e-5)# 将所用模型参数初始化为随机值scratch_net = torchvision.models.resnet18()scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)train_fine_tuning(scratch_net, 5e-4, param_group=False)