【MySQL体系】第2篇:MySQL索引类型和原理
引言
第 1 节 索引类型
1.1 普通索引
1.2 唯一索引
1.3 主键索引
1.4 复合索引
1.5 全文索引
第 2 节 索引原理
2.1 二分查找法
2.2 Hash 结构
2.3 B+Tree 结构
2.4 聚簇索引和辅助索引
引言
在 MySQL 数据库的日常使用中,索引是提升查询效率的 “利器”。想象一下,没有索引的数据库就像一本没有目录的厚书,想要找到特定内容只能逐页翻阅,效率极低。而索引就如同书的目录,能快速定位到目标数据。本文将从索引类型和索引原理两大维度,全方位拆解 MySQL 索引的核心知识。
第 1 节 索引类型
MySQL 提供了多种类型的索引,不同索引适用于不同的业务场景,理解各类索引的特性是合理使用索引的基础。
1.1 普通索引
普通索引是 MySQL 中最基础的索引类型,其唯一的作用就是加速数据的查询,没有任何其他限制条件。它允许在索引列中插入重复值和 NULL 值。
使用场景:适用于大多数普通的查询场景,例如查询用户的基本信息、商品的详情等。
示例:假设存在一张user表,包含id、name、age字段,为name字段创建普通索引:
CREATE INDEX idx_user_name ON user(name);
创建索引后,执行SELECT * FROM user WHERE name = '张三';查询时,MySQL 会通过idx_user_name索引快速定位到name为 ' 张三 ' 的记录,避免全表扫描。
1.2 唯一索引
唯一索引与普通索引的最大区别在于,它要求索引列的值必须是唯一的,不允许重复值,但允许 NULL 值(可以有多个 NULL 值,因为 NULL 不等于任何值)。这种索引在保证数据唯一性的同时,也能加速查询。
使用场景:常用于需要保证数据唯一性的字段,如用户的邮箱、手机号等。
示例:为user表的email字段创建唯一索引:
CREATE UNIQUE INDEX idx_user_email ON user(email);
此时,如果尝试插入两条email相同的记录,MySQL 会抛出错误,从而保证email字段的唯一性。同时,执行SELECT * FROM user WHERE email = '``zhangsan@163.com``';查询时,也能通过索引快速找到目标记录。
1.3 主键索引
主键索引是一种特殊的唯一索引,它要求索引列的值既唯一又非 NULL。一张表只能有一个主键索引,因为主键是表中记录的唯一标识。在 InnoDB 存储引擎中,主键索引与表的数据物理存储紧密关联(后续在聚簇索引中详细说明)。
使用场景:每张表都应该设置主键索引,用于唯一标识表中的每条记录,如用户表的id字段、订单表的order_id字段等。
示例:创建user表时指定id字段为主键:
CREATE TABLE user (id INT NOT NULL AUTO_INCREMENT,name VARCHAR(50) NOT NULL,age INT,PRIMARY KEY (id)
);
此时,MySQL 会自动为id字段创建主键索引。当执行SELECT * FROM user WHERE id = 1;查询时,能以极高的效率定位到记录。
1.4 复合索引
复合索引(也叫联合索引)是由多个字段组合而成的索引。与单个字段的索引相比,复合索引能更精准地定位数据,但在使用时需要遵循 “最左前缀原则”。
最左前缀原则:指在使用复合索引进行查询时,MySQL 只会使用索引中从最左边开始的连续字段。如果查询条件中不包含最左边的字段,或者跳过了中间的字段,索引将无法被有效使用。
使用场景:适用于经常根据多个字段组合进行查询的场景,例如经常查询 “年龄为 25 岁且姓名为张三的用户”,就可以为age和name字段创建复合索引。
示例:为user表的age和name字段创建复合索引:
CREATE INDEX idx_user_age_name ON user(age, name);
有效使用索引的查询:
SELECT * FROM user WHERE age = 25;(使用了索引的age字段)SELECT * FROM user WHERE age = 25 AND name = '张三';(使用了索引的age和name字段)
无法有效使用索引的查询:
SELECT * FROM user WHERE name = '张三';(未使用索引的最左字段age,索引失效)SELECT * FROM user WHERE age > 25 AND name = '张三';(age使用了范围查询,后续的name字段无法使用索引)
1.5 全文索引
全文索引主要用于对文本类型的字段进行全文搜索,它能快速定位包含特定关键词的文本记录。MySQL 中的 MyISAM 和 InnoDB(5.6 版本及以上)存储引擎支持全文索引,仅适用于CHAR、VARCHAR、TEXT类型的字段。
使用场景:适用于博客、新闻、论坛等需要对文章内容进行关键词搜索的场景。
示例:创建article表并为content字段创建全文索引:
CREATE TABLE article (id INT NOT NULL AUTO_INCREMENT,title VARCHAR(100) NOT NULL,content TEXT,PRIMARY KEY (id),FULLTEXT INDEX idx_article_content (content)
);
使用全文索引进行查询:
SELECT * FROM article WHERE MATCH(content) AGAINST('MySQL 索引' IN NATURAL LANGUAGE MODE);
该查询会快速返回content字段中包含 “MySQL” 或 “索引” 关键词的文章记录。
第 2 节 索引原理
了解了索引的类型后,我们还需要深入底层,探究索引是如何实现快速数据定位的。MySQL 中索引的实现基于不同的数据结构,常见的有二分查找法、Hash 结构和 B+Tree 结构,其中 B+Tree 结构是目前应用最广泛的。
2.1 二分查找法
二分查找法是一种基础的查找算法,其前提是数据必须是有序的。它的核心思想是:将有序数据序列分成两部分,与中间元素比较,如果目标值小于中间元素,则在左半部分继续查找;如果大于中间元素,则在右半部分继续查找,重复此过程,直到找到目标值或确定目标值不存在。
原理示例:假设有一个有序数组[1,3,5,7,9,11,13],要查找值为7的元素。
数组的中间位置为 3(索引从 0 开始),中间元素为
7,与目标值相等,查找成功。如果要查找值为5的元素:中间元素为
7,5 < 7,在左半部分[1,3,5]中查找;左半部分的中间位置为 1,中间元素为
3,5 > 3,在右半部分[5]中查找;中间元素为
5,与目标值相等,查找成功。
在 MySQL 中的应用局限:虽然二分查找法的时间复杂度为 O (logn),效率较高,但它仅适用于有序的线性数据结构。而数据库中的数据经常需要进行插入、删除操作,维护一个有序的线性结构会导致大量的数据移动,效率极低。因此,二分查找法并不是 MySQL 索引的实际实现方式,更多的是作为一种基础查找思想存在。
2.2 Hash 结构
Hash 索引是基于哈希表实现的,其核心原理是:通过哈希函数将索引列的值映射为一个哈希码,哈希码对应哈希表中的一个位置,该位置存储着指向数据行的指针。
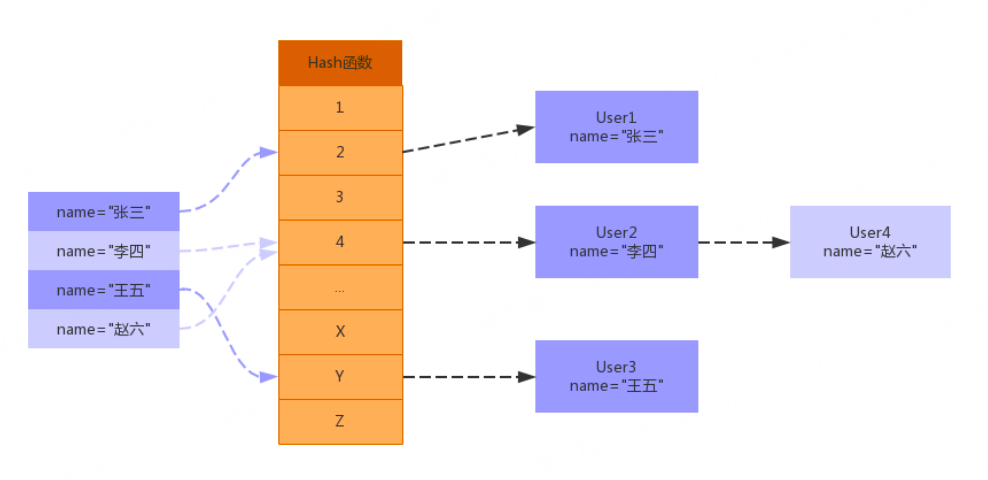
查询过程:当执行查询时,MySQL 会对查询条件中的索引列值计算哈希码,根据哈希码快速定位到哈希表中的位置,然后通过指针找到对应的数据行。
特点:
等值查询效率极高:由于哈希表的查找时间复杂度接近 O (1),对于
WHERE column = value这样的等值查询,Hash 索引的效率非常高。不支持范围查询:哈希码是随机分布的,无法通过哈希码确定数据的有序性,因此无法支持
WHERE column > value、WHERE column BETWEEN a AND b等范围查询。不支持排序:同样因为数据无序,无法利用 Hash 索引进行排序操作。
存在哈希冲突:不同的索引列值可能通过哈希函数计算出相同的哈希码,此时需要通过链表等方式解决冲突,会影响查询效率。
在 MySQL 中的应用:MySQL 中的 Memory 存储引擎支持 Hash 索引,而 InnoDB 和 MyISAM 存储引擎不支持显式创建 Hash 索引(InnoDB 有自适应哈希索引,但由系统自动管理)。由于 Hash 索引的局限性,其应用场景相对狭窄,仅适用于频繁进行等值查询且无范围查询、排序需求的场景。
2.3 B+Tree 结构
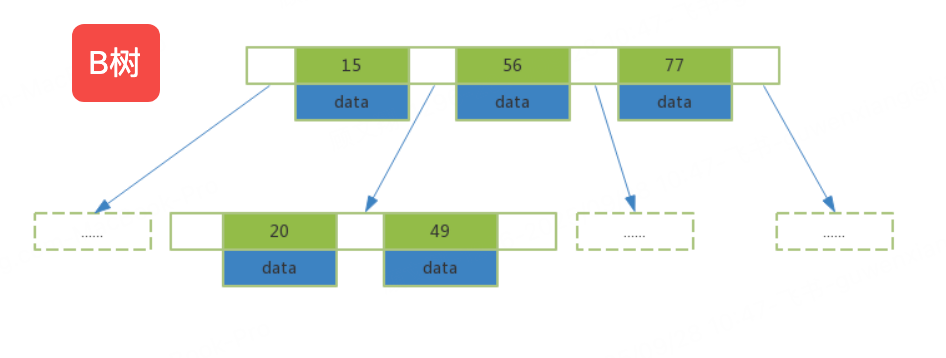
B+Tree 是一种平衡多路查找树,是 MySQL 中 InnoDB 和 MyISAM 存储引擎默认的索引数据结构。它在 B 树的基础上进行了优化,更适合数据库的读写操作。
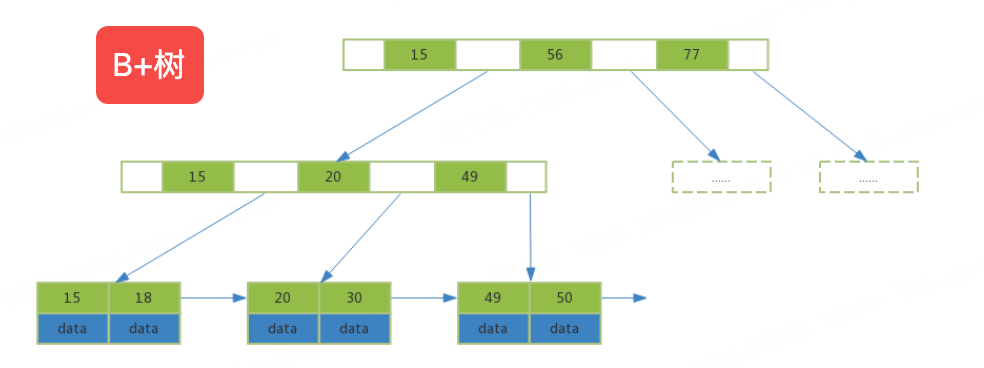
B+Tree 的结构特点
层级结构:B+Tree 由根节点、叶子节点和非叶子节点组成,层级通常较低(一般为 3-4 层),即使数据量很大,也能通过少数几次 IO 操作找到目标数据。
非叶子节点:仅存储索引值,不存储数据行指针,这样每个非叶子节点能容纳更多的索引值,减少树的层级。
叶子节点:存储所有的索引值和对应的 data 指针(指向数据行的地址),并且叶子节点之间通过双向链表连接,形成一个有序的链表结构。
B+Tree 的查询过程
假设一棵 3 层的 B+Tree,根节点有 2 个索引值10和20,分别指向两个子节点。第一个子节点包含索引值1-9,第二个子节点包含索引值11-19,第三个子节点包含索引值21-30,叶子节点之间通过双向链表连接。
查询id = 15的记录:
从根节点开始,
15 > 10且15 < 20,定位到第二个子节点;在第二个子节点中,
15介于11-19之间,定位到对应的叶子节点;在叶子节点中找到
id = 15的索引值,通过其对应的 data 指针找到数据行。
B+Tree 相比 B 树的优势
查询效率稳定:无论查询哪个数据,都需要遍历到叶子节点,查询路径长度相同,效率稳定。
支持范围查询:由于叶子节点是有序的双向链表,进行范围查询时,只需找到范围的起始和结束位置,通过链表即可快速获取所有符合条件的记录。例如查询
id BETWEEN 12 AND 18,找到12和18对应的叶子节点后,直接遍历两者之间的链表节点即可。存储效率更高:非叶子节点仅存储索引值,节省了存储空间,能容纳更多索引项,降低树的高度,减少 IO 操作。
2.4 聚簇索引和辅助索引
在 InnoDB 存储引擎中,索引分为聚簇索引和辅助索引,两者的实现方式和作用有所不同。
聚簇索引
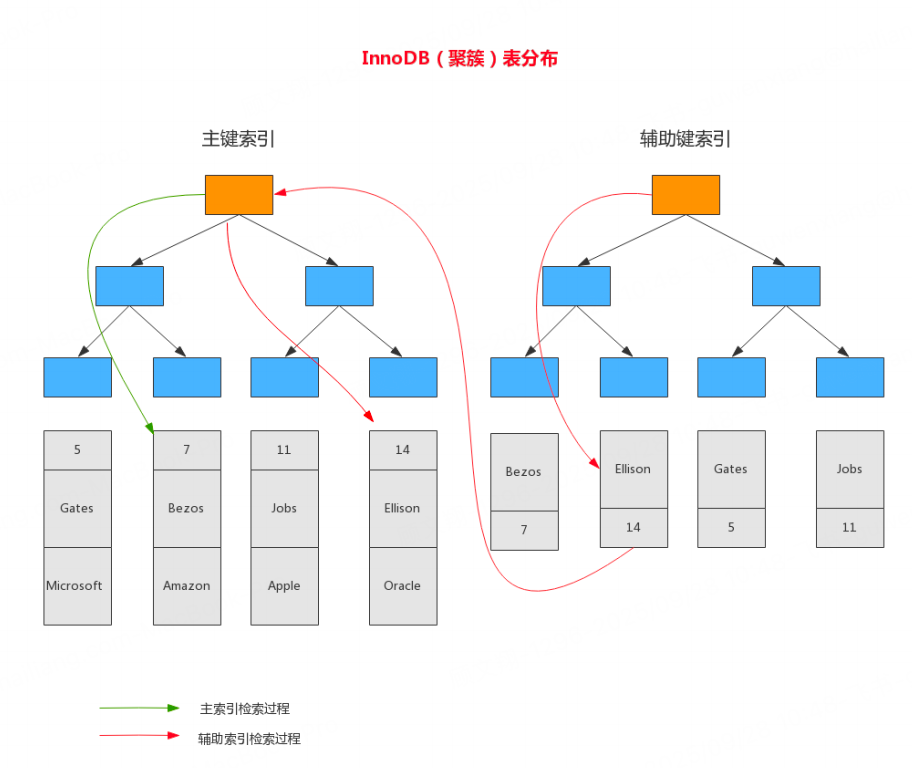
聚簇索引(Clustered Index)是将数据与索引存储在一起的索引,即索引的叶子节点直接存储数据行。InnoDB 存储引擎会默认以主键索引作为聚簇索引;如果表没有主键,则会选择一个唯一索引作为聚簇索引;如果既没有主键也没有唯一索引,InnoDB 会自动生成一个隐藏的自增列作为聚簇索引。
特点:
数据的物理存储顺序与索引的逻辑顺序一致,查询聚簇索引时,找到索引节点就找到了对应的数据,无需额外的 IO 操作。
一张表只能有一个聚簇索引,因为数据的物理存储顺序只有一种。
示例:user表以id为主键,聚簇索引的叶子节点存储着id、name、age等完整的用户数据。执行SELECT * FROM user WHERE id = 5;查询时,通过聚簇索引找到id = 5的叶子节点,即可直接获取用户的所有信息。
辅助索引
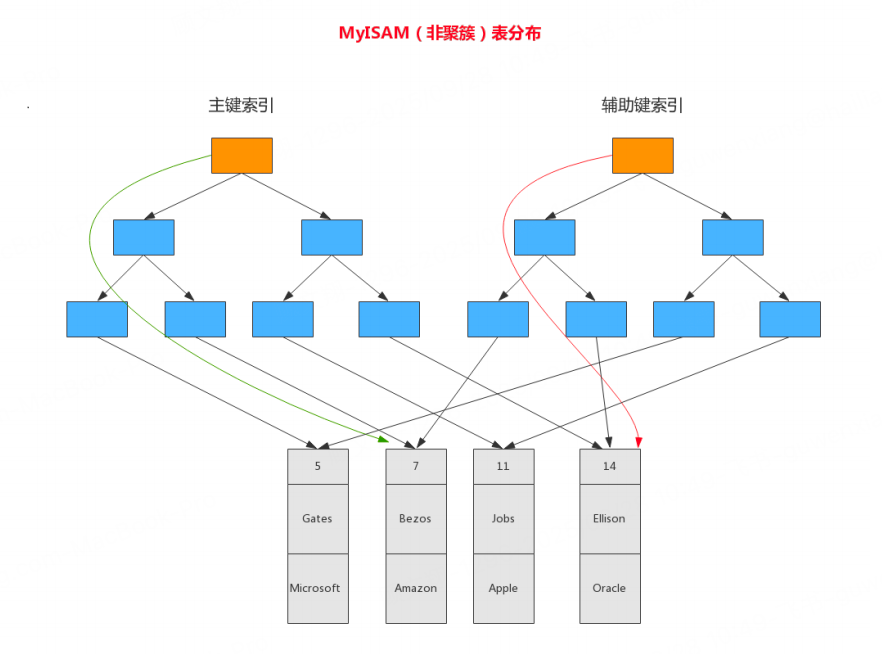
辅助索引(Secondary Index)也叫非聚簇索引,其叶子节点不存储完整的数据行,而是存储聚簇索引的键值(即主键值)。当通过辅助索引查询数据时,需要先通过辅助索引找到对应的主键值,再通过聚簇索引找到完整的数据行,这个过程称为 “回表”。
特点:
一张表可以有多个辅助索引,因为辅助索引不影响数据的物理存储顺序。
查询时需要进行回表操作,相比聚簇索引,查询效率略低。
示例:user表的name字段创建了辅助索引,该辅助索引的叶子节点存储着name值和对应的id值。执行SELECT * FROM user WHERE name = '张三';查询时:
通过辅助索引
idx_user_name找到name = '张三'对应的id值(假设为 3);以
id = 3为条件查询聚簇索引,找到对应的叶子节点,获取完整的用户数据。
注意:如果查询的字段刚好是辅助索引包含的字段(即覆盖索引),则不需要回表。例如SELECT id, name FROM user WHERE name = '张三';,由于辅助索引已经包含id和name字段,直接从辅助索引中即可获取数据,无需回表,查询效率会大幅提升。