RISE论文阅读

2023.9
1.摘要
background
该论文研究领域泛化(Domain Generalization, DG)问题。其核心挑战是,在一个或多个相关但不同的“源域”上训练的机器学习模型,需要很好地泛化到一个在训练时从未见过的“目标域”。现有模型的一大痛点是它们容易学习到与特定领域强相关的特征(domain-specific features),例如照片的背景、艺术画的笔触等,这导致模型在新领域上性能急剧下降。因此,研究的核心动机是如何学习一种领域不变(domain-invariant)的表示,以提升模型的泛化能力。
innovation
为了解决上述问题,本文提出了一个名为 RISE (Regularized Invariance with Semantic Embeddings) 的新方法,其核心创新点如下:
1.利用语言作为“锚点”进行知识蒸馏:论文创新性地提出,利用一个大型的、预训练好的视觉-语言模型(特指 CLIP)作为“教师模型”,来指导一个更小的“学生模型”的学习。
2.图文跨模态对齐:与传统的知识蒸馏仅仅对齐教师和学生的图像特征不同,RISE 的关键洞见在于,它强制要求学生模型学习到的 图像表示,去逼近教师模型从相应 文本描述 中学到的 文本表示。
3.为什么有效:作者认为,文本描述(如“一只狗”)能够高度浓缩和概括一个物体的核心语义信息,这种信息本质上是领域无关的。相比之下,图像像素包含了大量与领域相关的冗余细节(如背景、光照、风格)。因此,将文本表示作为学习目标,可以为学生模型提供一个更鲁棒、更具泛化性的监督信号。
4.具体实现:为了实现这一目标,论文设计了两种新的损失函数:绝对距离损失 (Absolute Distance Loss) 和 相对距离损失 (Relative Distance Loss),从不同角度引导学生模型的图像表示向教师的文本表示空间对齐。
2. 方法 Method
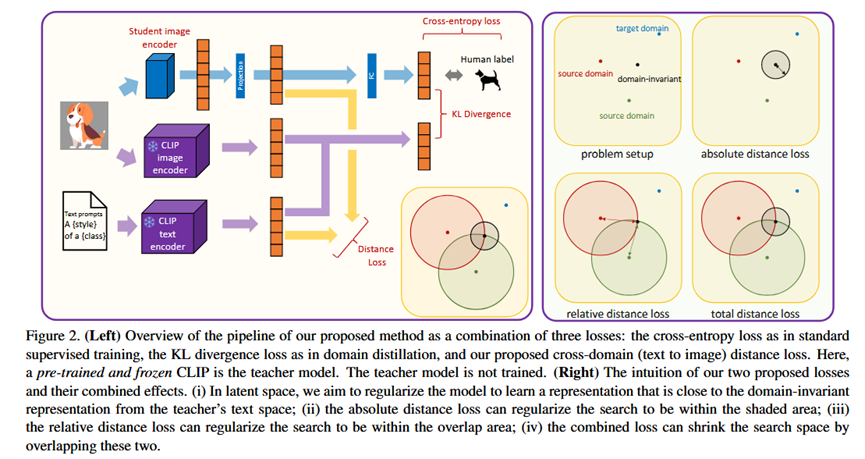
该方法的总体流程 (Pipeline) 是训练一个学生模型(如 ResNet),其总损失函数由三部分加权组成:标准的监督学习损失、传统的知识蒸馏损失,以及本文提出的核心——跨域距离损失。
整体框架 (Pipeline)
输入:一张来自源域的图片 x 及其类别标签 y。
模型:
学生模型 f(·):一个标准的图像分类网络(如 ResNet),需要从头开始训练。
教师模型:一个预训练好且被冻结的 CLIP 模型,它包含一个图像编码器 h(·) 和一个文本编码器 g(·)。
输出:学生模型对输入图片的类别预测。
总损失:L_total = L_监督 + λ_distill * L_蒸馏 + λ_text * L_文本引导
各部分细节
1.监督与蒸馏
监督损失 (ERM Loss):标准的交叉熵损失,用于保证模型在源域上的分类准确性。输入是学生模型的预测和真实标签 y。
知识蒸馏损失 (Hint Loss):标准的知识蒸馏,使用 KL 散度来对齐学生模型和教师模型 图像编码器 所输出的类别概率分布。这部分让学生模仿老师对图片的“看法”。
2.核心:语言引导正则化 (Regularization with Language)
目标文本表示的生成:为了获得一个足够通用、不受特定领域(如“照片”)偏见影响的文本表示,作者没有简单地使用 "a photo of a {class}" 这样的提示。而是使用了 CLIP 官方推荐的80个文本模板(如 "an art of {}", "a drawing of {}" 等),将一个类别代入所有模板,然后将生成的80个文本特征向量取平均,得到一个泛化能力更强的类别文本表示 e_z(i)。
绝对距离损失 (Absolute Distance Loss):
作用:直接将学生模型对图片 x 提取的图像特征 f_I(x),拉近到其对应类别的目标文本表示 e_z(i)。
输入:学生图像特征 f_I(x) 和 教师文本特征 e_z(i)。
输出:两者之间的距离(如余弦距离)。
相对距离损失 (Relative Distance Loss):
作用:为了更精确地“定位”目标,该损失函数引入了额外的“锚点”。这些锚点是为不同领域生成的文本特征(例如 "a sketch of a dog", "a painting of a dog")。该损失函数要求,学生图像特征 f_I(x) 与这些“锚点”的相对位置关系,应该和通用文本特征 e_z(i) 与这些“锚点”的相对位置关系保持一致。这在几何上约束了学生特征必须落入一个更精确的潜在空间区域。
输入:学生图像特征、教师通用文本特征、以及多个教师领域锚点文本特征。
输出:两组相对距离之间的差异。
3. 实验 Experimental Results
实验数据集
使用了领域泛化研究中四个标准的基准数据集:PACS, VLCS, OfficeHome, 和 Terra Incognita。
实验结论
1.与 SOTA 方法对比:
实验目的:证明 RISE 方法的有效性和先进性。
结论:在 ResNet18 和 ResNet50 骨干网络上,RISE 均显著优于之前的 SOTA 方法。即使只使用简单的知识蒸馏(ERM+Hint),性能已经很有竞争力,而加入本文提出的绝对距离(AD)和相对距离(RD)损失后,性能得到进一步的巨大提升。
2.消融实验:文本 vs. 图像作为监督信号:
实验目的:验证本文的核心假设——使用文本表示作为监督信号优于使用图像表示。
结论:实验结果明确显示,无论是在绝对距离损失还是相对距离损失中,使用 CLIP 的文本嵌入作为监督目标,其性能都稳定地优于使用 CLIP 的图像嵌入,证实了文本在提供领域不变信息上的优越性。
3.消融实验:各损失函数组件的影响:
实验目的:分析方法中每个部分(蒸馏损失、绝对距离、相对距离)的贡献。
结论:与仅使用交叉熵的基线模型相比,每个组件都能带来显著的性能提升。将所有组件组合在一起时,模型性能达到最佳,证明了设计的合理性。
4.消融实验:提示工程 (Prompt Engineering) 的影响:
实验目的:验证使用80个模板取平均的方式是否优于使用单个模板(如 "a photo of a {class}")。
结论:使用模板集成(Ensemble template)比单个模板效果更好,生成的文本表示更鲁棒。
5.消融实验:多教师模型 (Mix Teacher) 的影响:
实验目的:探究使用不同结构的多个教师模型(CLIP ViT + CLIP ResNet)进行集成蒸馏的效果。
结论:集成多个教师模型可以进一步提升学生模型的性能,达到最佳结果。这表明不同结构的教师模型可能存在不同的领域偏见,集成它们可以为学生提供更全面的知识。
4. 总结 Conclusion
本文的核心信息是:语言可以作为一种强大的正则化工具来提升模型的泛化能力。通过将大型视觉-语言模型(CLIP)的文本知识蒸馏给一个小型图像模型,可以有效地引导后者学习到更加抽象、鲁棒和领域无关的特征表示,从而在领域泛化任务上取得当前最优的性能。