17-Language Modeling with Gated Convolutional Networks
目录
摘要:
主要公式:
GTU
实验结果:
计算成本:
门控:
非线性:
与CNN方法的区别:
详细解释
1. 目标根本不同:序列建模 vs. 特征提取
2. 因果卷积:最重要的区别
3. 门控机制:性能强大的关键
4. 与RNN/LSTM的对比视角(文中背景)
总结
摘要:
本文提出了gated CNN 网络,gated linear units通过提供一个线性通道降低了梯度消失问题,并且保持非线性能力。
主要公式:
本文通过函数f对输入进行卷积,, 此过程将根据前面的单词数量计算每个上下文。与LSTM相比,context的大小是有限的,本文证实了无限的context大小是不必要的,该模型可以表示足够大的context。
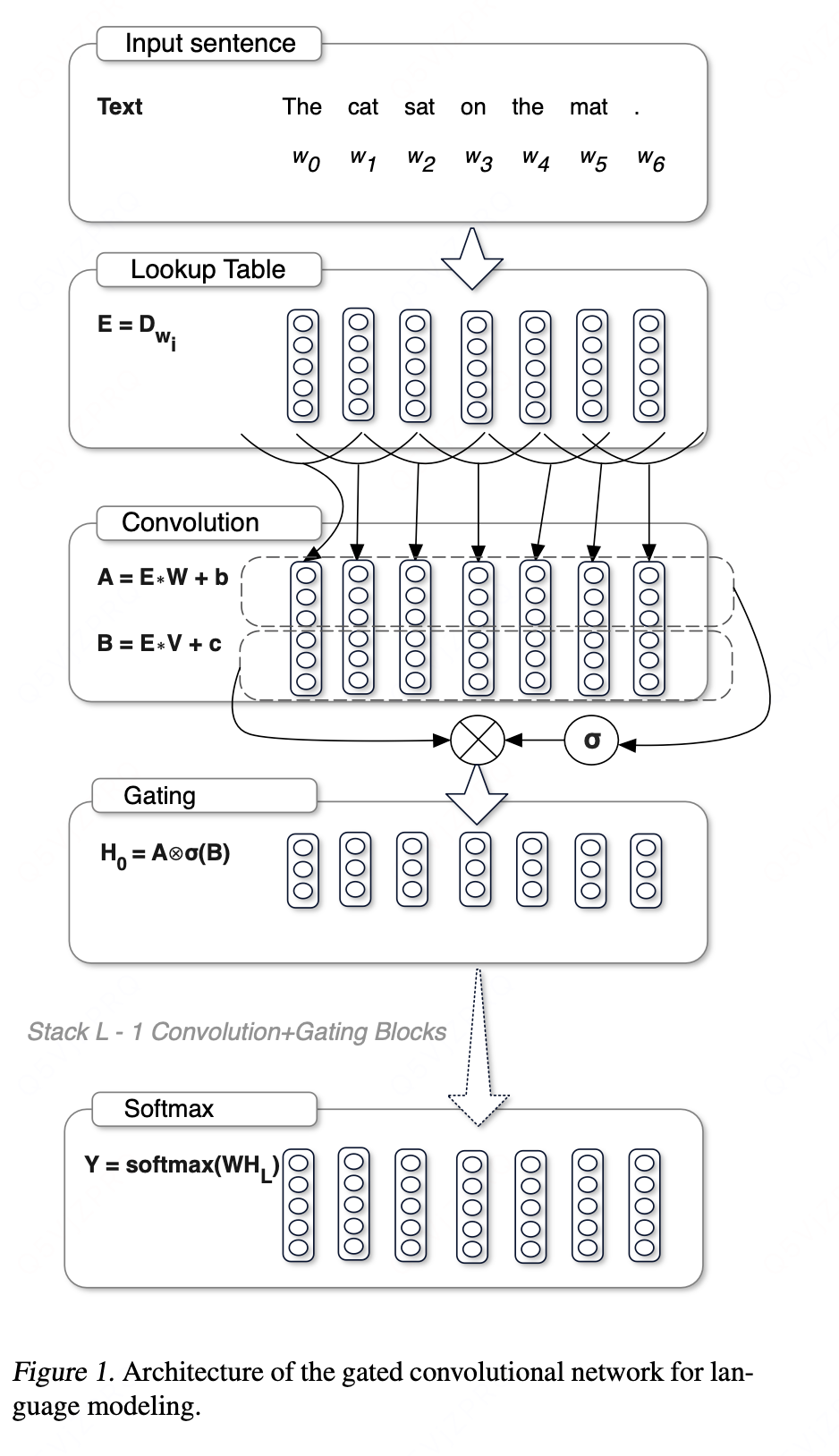
卷积公式:
每层的输出是线性映射乘以gate:
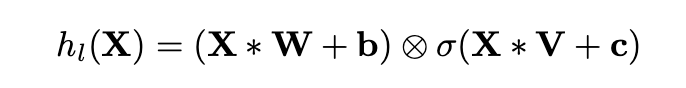
通过对输入E堆叠多层得到每个word的context表示:
我们将卷积和门控线性单元包裹在一个预激活残差块中,这些块具有计算效率的瓶颈结构,每个块最多有5层。
具体参数:其中k可以理解为卷积核的大小,

LSTM由输入门和遗忘门独立控制,使得信息能够无阻碍地跨越多个时间步长进行传递。CNN不会面临梯度消失问题,它们不需要遗忘门。
因此,我们专注于研究仅配备输出门的模型结构。这种设计使网络能够精准控制信息在层级间的传递内容。研究表明,该机制在语言建模任务中具有重要价值,因为它使模型能够自主筛选与下一词预测相关的关键词语或特征。
与我们研究同步的是,Oord等人(2016b)证实了形如tanh(X∗W+b)⊗σ(X∗V+c)的LSTM风格机制在图像卷积建模中的有效性。随后,Kalchbrenner等人(2016)通过增加门控单元扩展了该机制,将其成功应用于机器翻译和字符级语言建模任务。
GTU
门控线性单元是一种简化的门控机制,其理论基础源于Dauphin和Grangier(2015)提出的非确定性门控研究。该机制通过将线性单元与门控耦合,有效缓解了梯度消失问题。这种设计既保留了网络层的非线性能力,又允许梯度通过线性单元无损地进行传播。
相比之下,我们将其称为门控tanh单元(GTU)的LSTM风格门控梯度则随着层堆叠梯度逐渐消失(由于tanh(x)和sigmoid(x)):
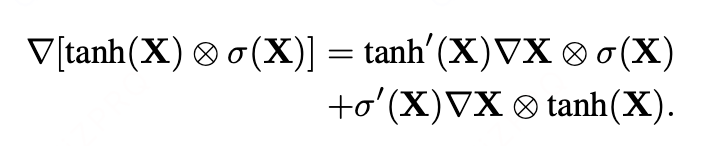
本文GLU的梯度为:
![]()
存在一条梯度路径∇X ⊗σ(X),该路径不会对σ(X)中已激活的门控单元进行缩放。这可以视为一种乘性跳跃连接,有助于梯度在网络层间流动。
实验结果:
长短期记忆网络(LSTM)与循环神经网络(RNN)能够捕捉长期依赖关系,正迅速成为自然语言处理领域的基石技术。在本节中,我们将文献中表现强劲的LSTM和RNN模型与我们基于门控卷积的方法在两个数据集上进行比较。
-
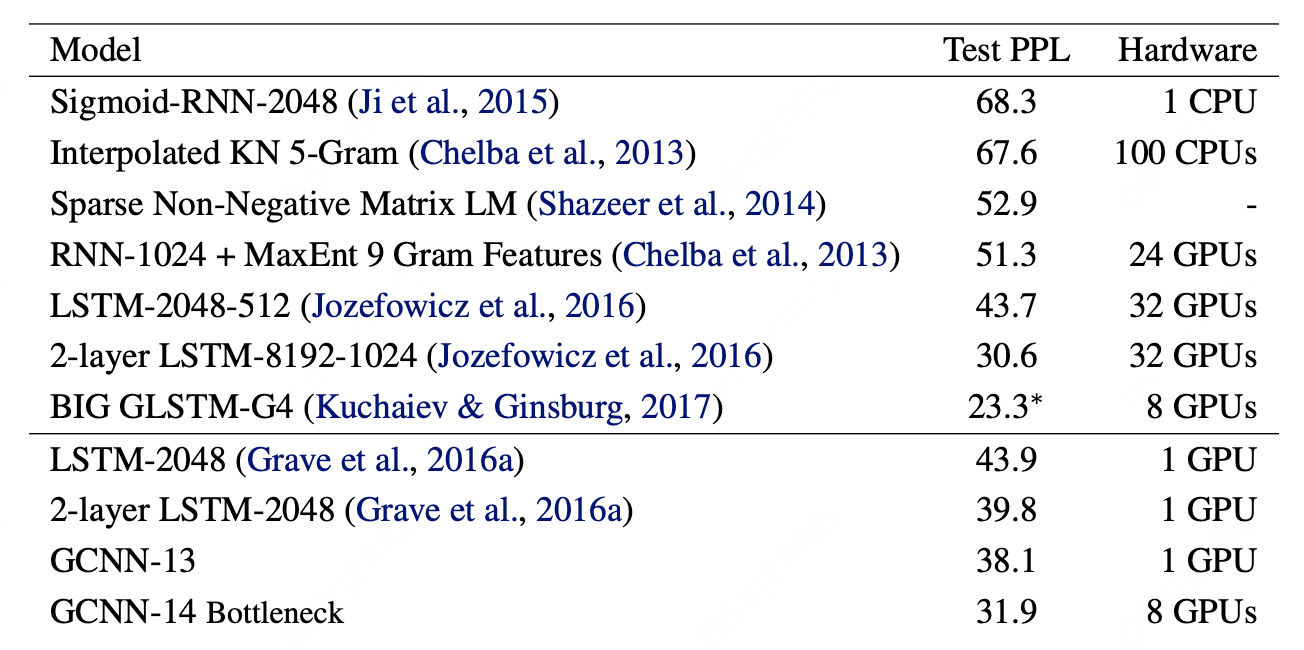
性能对比:在严格控制变量(GPU数量、输出层结构)的条件下,GCNN在语言建模任务(Google Billion Words数据集)上的性能(困惑度38.1)优于 与之相当的LSTM模型(困惑度39.8)。
-
核心优势:GCNN具有显著更高的计算效率。它结合自适应softmax,用少得多的计算量就能达到与其他模型使用完整softmax时相近甚至更好的性能。
-
顶尖对比:与一个需要更多资源(32 GPU, 3周)的、规模更大的顶尖LSTM模型相比,GCNN(8 GPU, 2周)在性能(困惑度31.9 vs 30.6)上略有差距,但资源效率极高。
-
改进潜力:文中指出,通过集成学习或专家混合模型等方法,GCNN的结果还有提升空间。
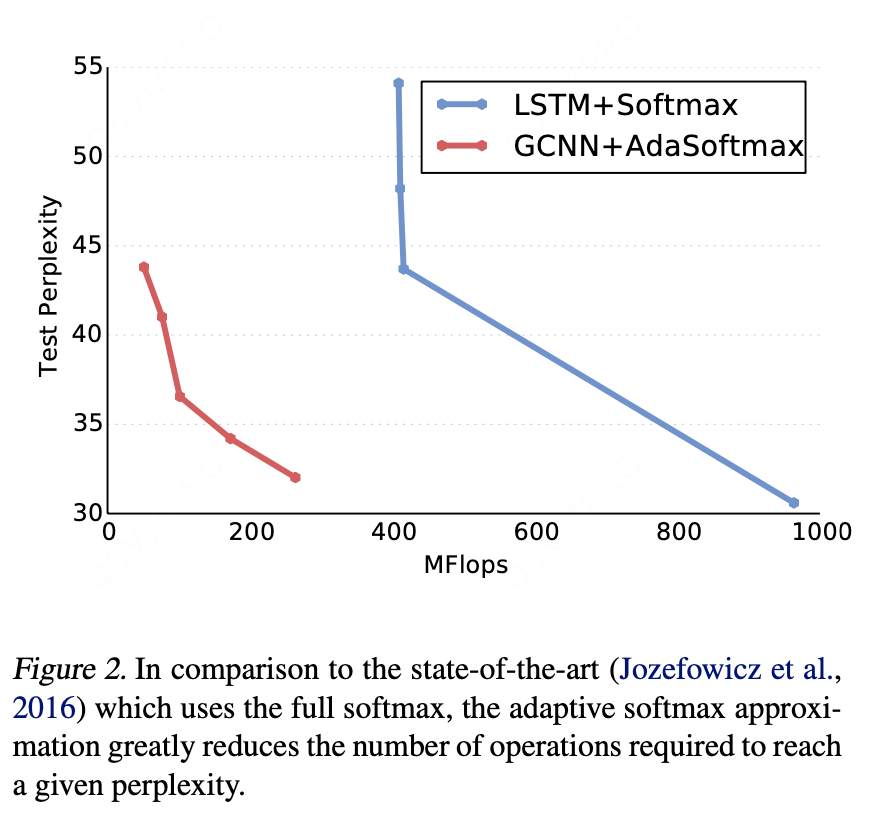
-
长序列建模能力:在包含长文档(平均4000词)的WikiText-103数据集上,GCNN继续优于LSTM,证明其固定上下文窗口足以有效建模长距离依赖。
-
与其他架构对比:在Gigaword数据集上,GCNN(困惑度29.4)显著优于全连接网络(困惑度55.6),凸显了其架构优势。
-
小数据集上的局限性:在较小的Penn Tree Bank数据集上,当句子独立处理时,GCNN与LSTM性能相当。但GCNN更容易过拟合,表明其优势在大规模数据上更能体现。
-
结论:GCNN被证明是一种强大且高效的架构,特别适合大规模自然语言处理任务。其在长序列建模上的成功挑战了人们可能对卷积方法上下文限制的担忧。
计算成本:
计算成本是语言模型的一个重要考量因素。根据具体应用场景,需要权衡多项指标。我们将模型的吞吐量定义为每秒能处理的词元数量。通过并行处理大量句子来分摊序列化操作的开销,可以最大化吞吐量。相反,响应速度(responsiveness)则是指按顺序逐个词元处理输入的速度。
吞吐量之所以重要,是因为它决定了处理一个文本语料库所需的总时间;而响应速度则反映了处理完一个句子所需的时间。一个模型可以通过批处理同时评估许多句子,从而实现低响应速度但高吞吐量。在这种情况下,该模型处理单个句子的速度较慢,但能以良好的速率并行处理大量句子。
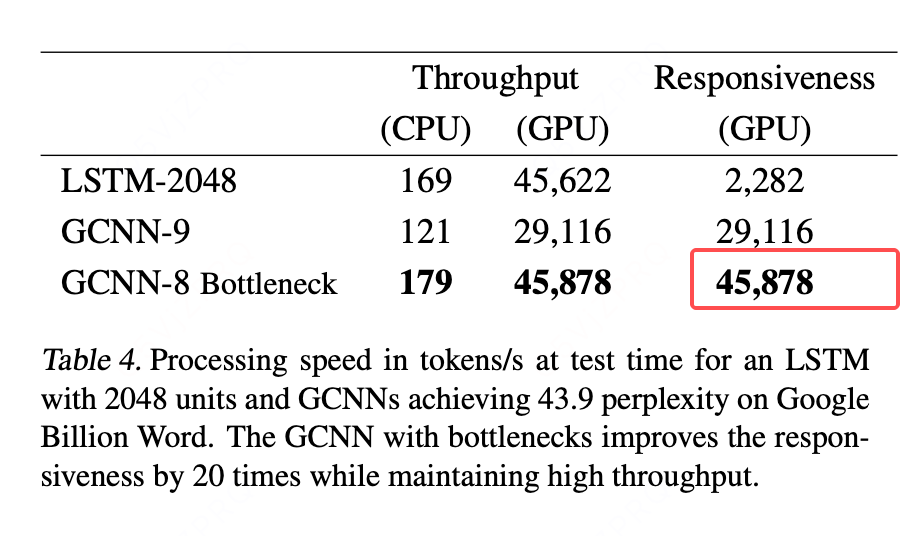
我们在达到相近性能(Google Billion Word 基准测试上困惑度约为 43.9)的模型上评估了其吞吐量和响应速度。我们对比了以下模型:表2中具有2048个单元的LSTM、一个带有7个具有瓶颈结构的Resnet块的GCNN-8Bottleneck,以及一个无瓶颈结构的GCNN-8。瓶颈块的设计是在两个k=1卷积层之间加入一个k>1的卷积层,通过先用k=1降维、进行卷积、再用k=1升维的方式,来降低计算成本。我们的结果表明,使用瓶颈块对于保持计算效率至关重要。
LSTM的吞吐量是通过使用大批次(750个长度为20的序列,即每批次15,000个词元)来测量的。响应速度是处理一个包含15,000个连续词元的序列的平均速度。表4显示,LSTM和GCNN的吞吐量相近。LSTM在GPU上表现非常好,因为750的大批次大小使得不同句子之间可以实现高度并行化。这是因为LSTM的实现经过了充分优化并使用了cuDNN,而cuDNN中对卷积的实现并未针对我们模型中使用的二维卷积进行优化。我们相信通过更高效的二维cuDNN卷积可以实现更好的性能。
与LSTM不同,GCNN的并行化可以在两个维度上进行:跨句子并行,以及在每个句子内部的词元间并行。这使得GCNN的响应速度比LSTM快了20倍。
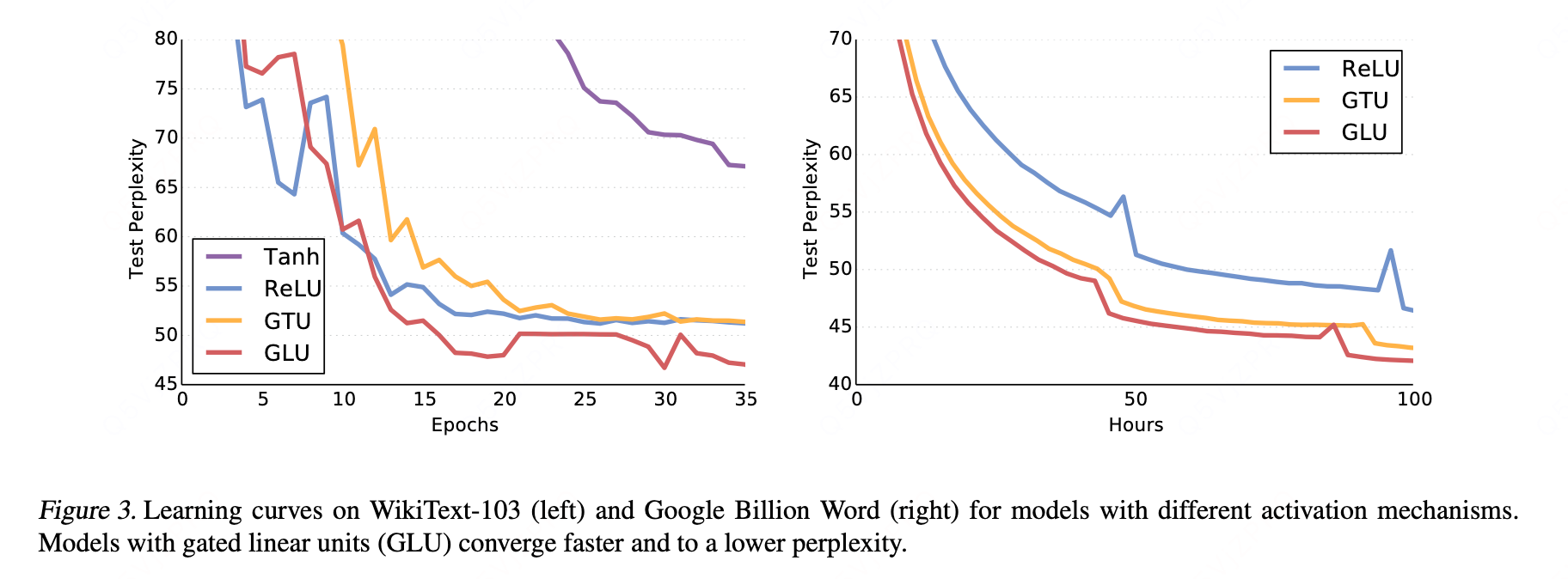
门控:
-
GLU的核心优势:其线性路径(梯度高速公路)有效缓解了梯度消失问题,导致收敛速度更快,并达到更低的最终困惑度。
-
与GTU对比:GTU(如LSTM的门控)因
tanh和sigmoid均会饱和而导致梯度易被切断,性能较差。实验证明门控机制本身(GTU vs. Tanh)对性能提升至关重要。 -
与ReLU对比:ReLU虽也有线性路径(正区间)利于梯度传播,但GLU的显式门控提供了更强大的建模能力,因此在性能上(困惑度)显著优于ReLU(差距约5点)。
-
结论:GLU在效率和性能上取得了最佳平衡,其优势在不同规模的数据集上均得到验证。它与ReLU的性能差距,堪比LSTM相对于传统RNN的改进幅度,凸显了其有效性。
非线性:
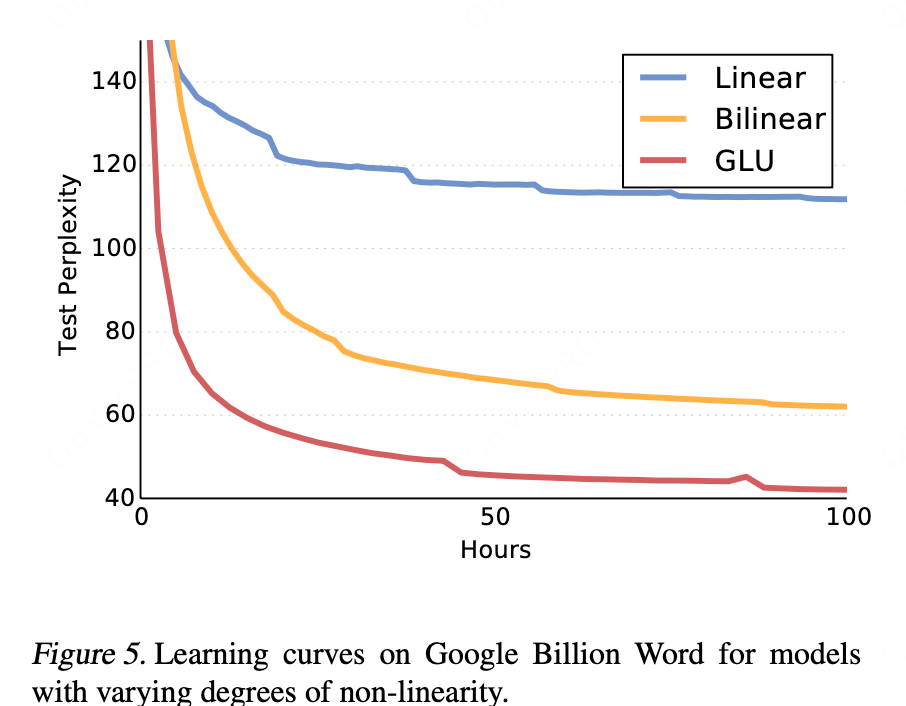
-
实验目的:量化评估GLU中非线性路径(由门控引入)的实际贡献,方法是与纯线性和双线性模型对比。
-
性能排序:GLU > 双线性层 > 纯线性层。性能差距巨大,GLU相比双线性层有约20个困惑度的显著提升。
-
线性模型的失败:深度线性卷积网络(理论上可捕捉更多上下文)表现甚至不如传统的Kneser-Ney 5-gram模型,说明非线性建模能力对神经语言模型至关重要。
-
双线性的启示:仅引入简单的双线性交互(一种较弱的非线性)就能显著超越传统n-gram和早期神经网络模型,证明了引入参数化交互的重要性。
-
GLU的成功关键:实验结果强有力地支持了GLU的成功源于其独特的结构:它同时拥有确保梯度顺畅传播的线性路径,以及负责复杂模式学习的非线性路径(门控)。二者缺一不可,共同作用产生了最佳效果。
与CNN方法的区别:
详细解释
1. 目标根本不同:序列建模 vs. 特征提取
-
GCNN:它的任务是理解一个序列(如一句话),根据上文预测下一个词。它关心的是顺序和依赖关系。
-
经典CNN:它的任务是理解一张图片,识别其中的模式。它关心的是空间局部相关性。
2. 因果卷积:最重要的区别
这是GCNN用于序列建模的灵魂所在。
输入序列: [x1, x2, x3, x4, x5, ...]
-
卷积核大小k=3计算输出y3时,只能看到: [x1, x2, x3] 计算输出y4时,只能看到: [x2, x3, x4] 计算输出y5时,只能看到: [x3, x4, x5]
-
为什么需要因果性? 在生成句子时,模型在预测第
t个词时,是不可能知道第t+1个词是什么的。因果卷积严格模拟了这一现实,确保了模型在训练和推理时行为一致。
3. 门控机制:性能强大的关键
文中反复强调GLU的优势。
-
在深层网络中,梯度容易消失。GLU提供了一条线性路径
(X * W + b),让梯度可以无衰减地直接传播,这大大改善了训练稳定性。 -
相比之下,经典CNN通常使用ReLU,虽然简单,但在处理序列这种复杂依赖时,建模能力不如门控机制。
4. 与RNN/LSTM的对比视角(文中背景)
理解GCNN,一定要放在它作为RNN/LSTM的替代方案这个背景下。
-
RNN/LSTM:天然具有顺序性,但无法并行计算,速度慢。
-
GCNN:通过因果卷积模拟顺序性,但卷积操作本身可以高度并行(同一序列内的所有位置可以同时计算),因此训练速度极快。它用深度来换取并行度和长程依赖能力。
总结
你可以这样理解:
-
经典CNN 是处理空间问题(如图像)的利器。
-
文中的门控卷积方法(GCNN) 是专门为处理时间序列问题(如自然语言)而设计的CNN变体。它通过因果卷积来保证顺序性,通过门控机制来提升模型能力和训练稳定性,从而在语言建模等任务上达到甚至超过了RNN/LSTM的性能,同时获得了巨大的速度优势。
简而言之,GCNN是CNN的思想在序列建模领域的一次成功改造和专门化应用。