Scikit-learn Python机器学习 - 聚类分析算法 - Agglomerative Clustering(凝聚层次聚类)
锋哥原创的Scikit-learn Python机器学习视频教程:
https://www.bilibili.com/video/BV11reUzEEPH
课程介绍

本课程主要讲解基于Scikit-learn的Python机器学习知识,包括机器学习概述,特征工程(数据集,特征抽取,特征预处理,特征降维等),分类算法(K-临近算法,朴素贝叶斯算法,决策树等),回归与聚类算法(线性回归,欠拟合,逻辑回归与二分类,K-means算法)等。
Scikit-learn Python机器学习 - 聚类分析算法 - Agglomerative Clustering(凝聚层次聚类)
Agglomerative Clustering(凝聚层次聚类)是一种自底向上的层次聚类方法,属于无监督学习的一种。它通过逐步将最相似的样本合并成一个簇(cluster),最终得到一个包含所有样本的簇,形成一个层次结构(树状图)。与其他聚类方法(如K-means)不同,凝聚层次聚类不需要事先指定簇的数量。
算法原理
凝聚层次聚类的核心思想是基于距离(或相似度)度量来逐步合并样本或簇。
步骤
-
初始化: 每个样本初始化为一个簇。
-
计算距离: 计算每对簇之间的距离(或相似度)。距离计算方法可以有不同的选择,常见的有:
-
单链接(Single Linkage): 两个簇之间的最小距离(即簇间最近的两个样本之间的距离)。
-
完全链接(Complete Linkage): 两个簇之间的最大距离(即簇间最远的两个样本之间的距离)。
-
均值链接(Average Linkage): 两个簇之间的平均距离。
-
中心链接(Centroid Linkage): 两个簇之间的中心点距离。
-
-
合并最近的簇: 选择距离最小的两个簇,合并成一个新的簇。
-
重复步骤2和3: 不断计算簇间距离并合并,直到所有样本合并为一个簇或达到预设的簇数。
-
树状图(Dendrogram): 最终生成的聚类结果可通过树状图表示,显示了不同样本和簇的合并顺序。
凝聚层次聚类的数学公式


我们看一个示例:
假设我们有以下二维数据点:
| 样本 | xx | yy |
|---|---|---|
| A | 1 | 2 |
| B | 1.5 | 1.8 |
| C | 5 | 8 |
| D | 8 | 8 |
| E | 1 | 1 |
步骤1: 计算每一对数据点之间的距离(例如使用欧几里得距离)。
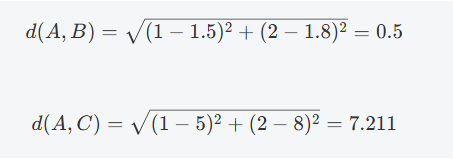
...(继续计算其他距离)
步骤2: 找到距离最小的两个点或簇。假设 AA 和 BB 之间的距离最小,我们首先将 AA 和 BB 合并为一个簇。
步骤3: 计算新簇与其他数据点的距离,并重复步骤2和3直到所有数据点合并为一个簇。
API介绍
在Scikit-learn中,AgglomerativeClustering 类可以实现凝聚层次聚类。
AgglomerativeClustering(n_clusters=2, # 最重要的参数:聚类数量*, # 后面必须使用关键字参数metric='euclidean', # 距离度量方法linkage='ward', # 链接准则distance_threshold=None, # 距离阈值(替代n_clusters)compute_full_tree='auto', # 是否计算完整树compute_distances=False # 是否计算距离
)核心参数介绍:
-
n_clusters- 聚类数量
-
作用:指定最终要形成的簇的数量
-
类型:int
-
默认值:2
-
metric- 距离度量
-
作用:定义数据点之间的距离计算方法
-
常用选项:
-
'euclidean':欧几里得距离(默认) -
'manhattan':曼哈顿距离 -
'cosine':余弦距离
-
-
linkage- 链接准则
-
作用:定义簇与簇之间的合并策略
-
常用选项:
-
'ward':沃德法(默认,最小化方差) -
'complete':全链接(最大距离) -
'average':平均链接 -
'single':单链接(最小距离)
-
-
distance_threshold- 距离阈值
-
作用:当簇间距离超过此值时停止合并
-
类型:float 或 None
-
注意:设置此参数时,
n_clusters必须为 None
具体示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score
import scipy.cluster.hierarchy as sch# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 生成示例数据
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)# 应用凝聚层次聚类
agg_clustering = AgglomerativeClustering(n_clusters=4, linkage='ward')
y_pred = agg_clustering.fit_predict(X)# 评估聚类效果
silhouette_avg = silhouette_score(X, y_pred)
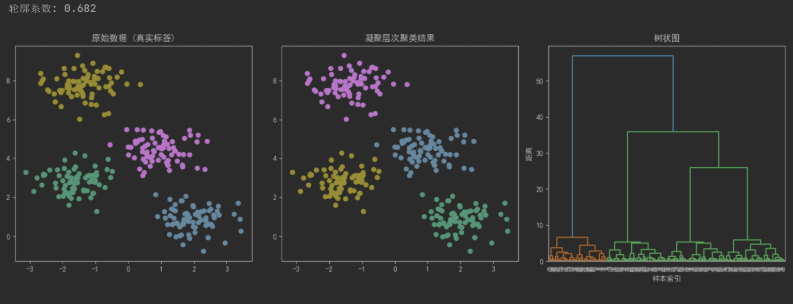
print(f"轮廓系数: {silhouette_avg:.3f}")# 可视化结果
plt.figure(figsize=(15, 5))# 原始数据
plt.subplot(1, 3, 1)
plt.scatter(X[:, 0], X[:, 1], c=y_true, cmap='viridis')
plt.title('原始数据 (真实标签)')# 聚类结果
plt.subplot(1, 3, 2)
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis')
plt.title('凝聚层次聚类结果')# 树状图
plt.subplot(1, 3, 3)
dendrogram = sch.dendrogram(sch.linkage(X, method='ward'))
plt.title('树状图')
plt.xlabel('样本索引')
plt.ylabel('距离')plt.tight_layout()
plt.show()运行结果: