【手撕机器学习 02】手撕算法的基石:精通NumPy与Pandas向量化思维
摘要:在上一篇构建了机器学习的世界观后,本文将为你锻造亲手实现算法的“神兵利器”——NumPy与Pandas。我们将告别低效的Python原生
for循环,带你领略“向量化计算”的惊人速度与优雅。你将精通这两个库的核心操作,为后续手撕所有机器学习算法铺平道路。
前言:从“自行车”到“超级跑车”
在上一篇 【手撕机器学习 01】 中,我们绘制了一张宏伟的机器学习世界地图。现在,是时候为我们的探索之旅准备交通工具了。
你可能会想:“我们有自行车(Python列表),为什么还需要超级跑车(NumPy/Pandas)?” 当你要进行一场横跨大陆的比赛(大规模数学运算)时,答案不言而喻。
让我们来看一个简单的任务:将两个列表的对应元素相加。
# --- 🚲 自行车模式:Python原生for循环 ---
list_a = [1, 2, 3]
list_b = [4, 5, 6]
result = []
for i in range(len(list_a)):result.append(list_a[i] + list_b[i])
# result -> [5, 7, 9]
用for循环处理大规模数据,将会变得极其缓慢和冗长。而机器学习的本质,就是大规模的数学运算。
核心思想:向量化 (Vectorization)。即把循环操作,转换成对整个数据集合(数组或矩阵)的“一次性”操作。这正是“超级跑车”的引擎轰鸣!

一、Numpy:科学计算的“核动力引擎”
Numpy (Numerical Python) 的核心是ndarray (n-dimensional array) 对象,一个强大的N维数组。
安装:
pip install numpy
1.1 从列表到ndarray的“升维”
import numpy as nparray_a = np.array([1, 2, 3])
array_b = np.array([4, 5, 6])# --- 🚀 超级跑车模式:向量化加法! ---
result_array = array_a + array_b
print(f"向量化加法的结果: {result_array}") # [5 7 9]
看到了吗?没有for循环,代码简洁且运行速度快了几个数量级。
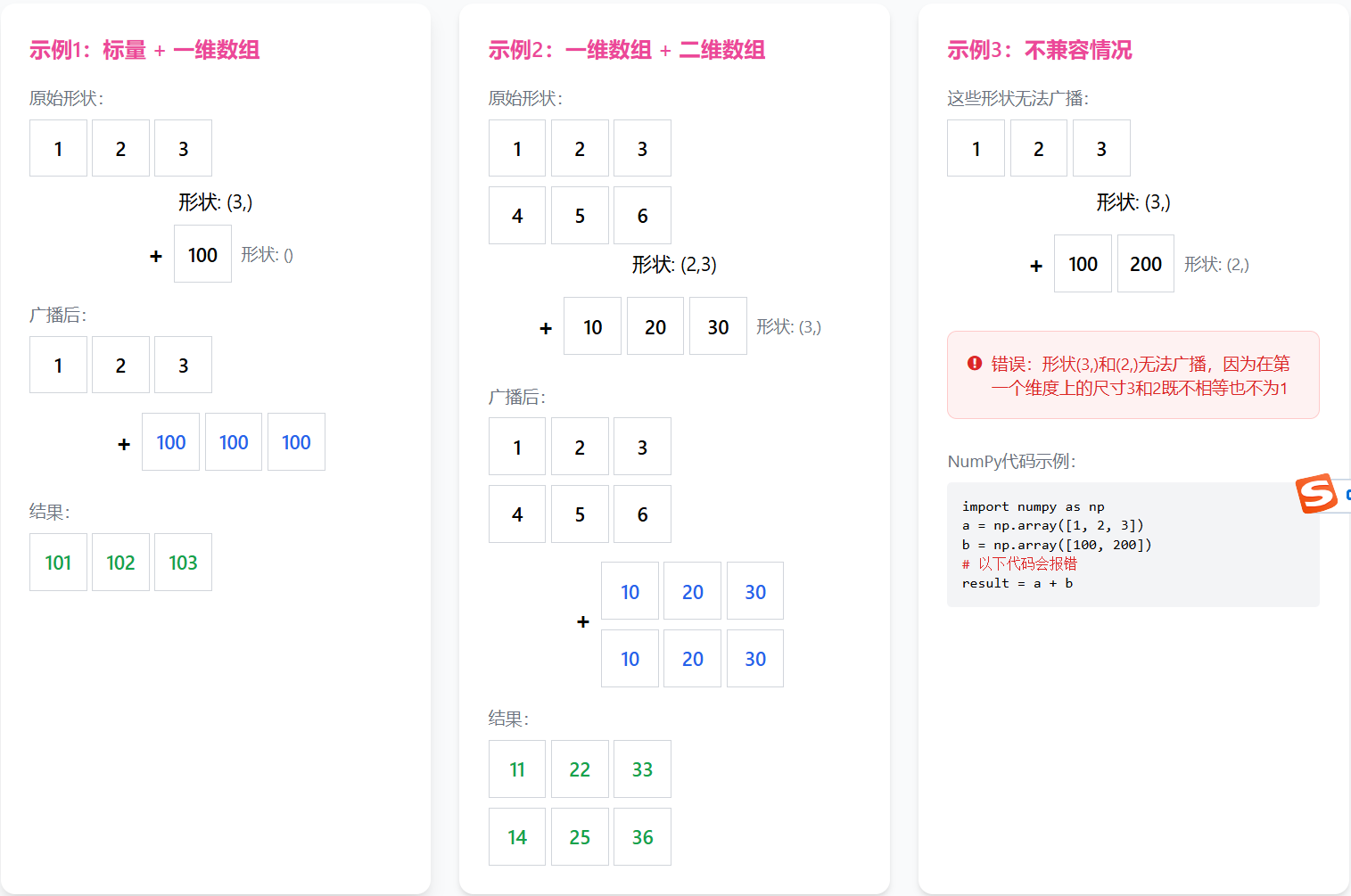
1.2 核心特性:广播 (Broadcasting)
广播是Numpy最强大的特性之一。它允许Numpy在执行算术运算时,自动“扩展”较小数组的形状。
array = np.array([1, 2, 3])# 标量与数组的运算
result = array + 100
print(f"数组加标量: {result}") # [101 102 103]
💡 手撕算法为何需要它?
在梯度下降中,我们经常需要用一个标量(学习率)去更新整个参数矩阵。广播机制让这一切变得无比简单。
1.3 索引、切片与形状操作
- 索引与切片:与Python列表类似,但更强大。
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 条件索引 (极其重要):获取所有大于5的元素
greater_than_5 = matrix[matrix > 5]
print(f"大于5的元素: {greater_than_5}") # [6 7 8 9]
- 形状操作 (Shape Manipulation):手写算法的必备技能。
vector = np.arange(6) # [0 1 2 3 4 5]
# .reshape():重塑数组形状
matrix_3x2 = vector.reshape((3, 2)) # 变成3行2列
print(f"重塑后的3x2矩阵:\n{matrix_3x2}")
# .T:转置矩阵 (行变列,列变行)
matrix_2x3 = matrix_3x2.T
print(f"转置后的2x3矩阵:\n{matrix_2x3}")
💡 手撕算法为何需要它?
线性代数中大量的矩阵乘法,都对矩阵的形状有严格要求。.reshape()和.T是我们进行数据对齐的“整形手术刀”。
二、Pandas:数据江湖的“瑞士军刀”
如果说NumPy是处理纯数字的“引擎”,那么Pandas就是处理结构化数据(带标签的表格数据)的“超级总成”。它的核心是DataFrame。
安装:
pip install pandas
2.1 DataFrame:我们的“主力战舰”
DataFrame是一个二维的、带标签的数据结构,就像一个Excel表格。这是我们在机器学习中打交道最多的对象。
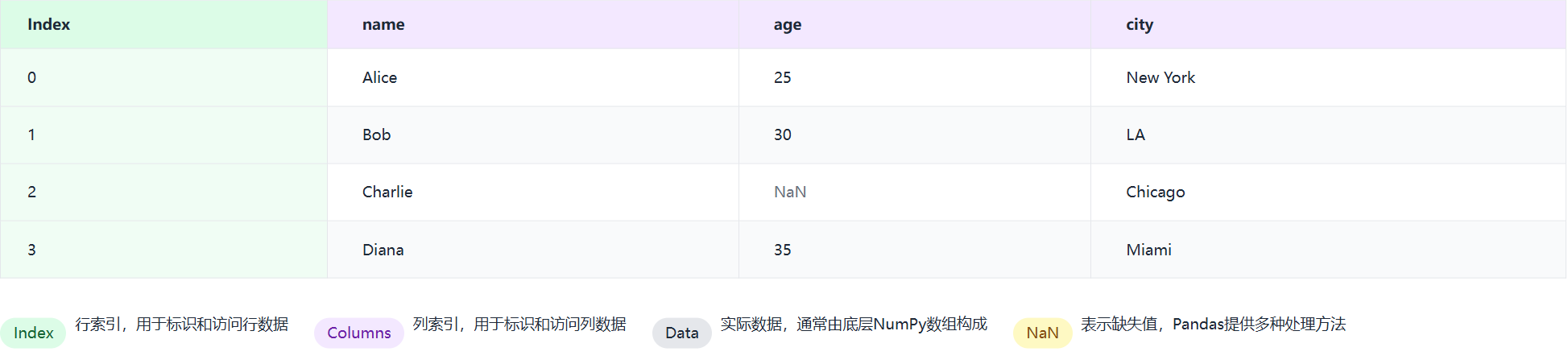
import pandas as pd
import numpy as npdata = {'name': ['Alice', 'Bob', 'Charlie', 'David'],'age': [25, 30, np.nan, 35], # np.nan 是表示缺失值的标准方式'city': ['New York', 'Los Angeles', 'Chicago', np.nan]
}
df = pd.DataFrame(data)
print(f"这是一个DataFrame:\n{df}")
2.2 核心操作
2.2.1 查看与选择数据
# 查看前几行
print(f"前两条数据:\n{df.head(2)}")
# 选择'name'和'city'两列
subset = df[['name', 'city']]
print(f"\n姓名和城市列:\n{subset}")
# 条件筛选:筛选出年龄大于28岁的人
older_people = df[df['age'] > 28]
print(f"\n年龄大于28的人:\n{older_people}")
2.2.2 处理缺失值 (必会!)
这是数据预处理中最常见、最重要的一步。
💡 手撕算法为何需要它?
绝大多数机器学习算法都无法处理NaN这样的缺失值,喂给它们之前必须进行“净化”。
print("\n--- 处理缺失值 ---")
# 检查哪些单元格是缺失值
print(f"缺失值检查:\n{df.isnull()}")# 策略一:删除包含任何缺失值的行
df_dropped = df.dropna()
print(f"\n删除缺失值后的DataFrame:\n{df_dropped}")# 策略二:填充缺失值 (更常用)
mean_age = df['age'].mean()
df_filled = df.copy() # 创建副本以避免修改原始df
df_filled['age'] = df_filled['age'].fillna(mean_age)
print(f"\n填充缺失值后的DataFrame:\n{df_filled}")
三、总结:思维的跃迁
NumPy和Pandas不仅仅是工具,它们代表着一种从“迭代思维”到“向量化思维”的跃迁。
- NumPy (
ndarray): 是我们进行纯数学计算的基石,提供了速度与简洁性。 - Pandas (
DataFrame): 是我们进行数据预处理和探索的利器,提供了结构与便利性。
从现在开始,请努力用向量化的思维来替代for循环。当你能自然地写出array.reshape((3,2))和df['age'].fillna(mean_age)时,你就已经为手撕所有机器学习算法,做好了最充分的准备。
如果觉得这篇文章让你对NumPy和Pandas有了全新的认识,请一定记得 👍 点赞、⭐ 收藏、💬 评论三连支持一下,这对我真的非常重要!
预告:【手撕机器学习 03】从“生数据”到“黄金特征”:机器学习项目中价值最高的一步