20252803《Linux内核原理与分析》第三周作业
作业要求
阅读学习教材「庖丁解牛Linux 操作系统分析 」第3章,有问题优先使用chatgpt等AI工具。或者到蓝墨云班课中提问,24小时内回复,鼓励解答别人问题,提问前请阅读「如何提问」。
教材深入学习关注豆列「Linux内核及安全」。
学习蓝墨云班课中第三周视频「操作系统是如何工作的?」,并完成实验楼上配套实验二。,注意从下往上看。基于树莓派或其他平台完成ARM相关内容。
作业标题 “学号《Linux内核原理与分析》第X周作业”,重点是遇到的问题和解决方案内容涵盖教材学习和视频,提交格式用Markdown,同时提交转换的 PDF(VSCode 有相关插件)。
实验二
完成一个简单的时间片轮转多道程序内核代码
一、目标
学习mykernel 实验指导(操作系统是如何工作的)
二、实验前置操作
各步操作在蓝桥的实验楼平台上进行
实验前置操作是实验给出的已有代码。大概是使用了一个自定义的Linux内核来测试构建和启动。首先,它删除任何先前构建的内核相关文件,然后用一个补丁文件来修改内核源代码。随后它配置内核选项,接着编译内核。最后,它使用QEMU虚拟机来启动新编译的内核。但是QEMU后会发现,该处进入死循环(只有计时器中断处理函数在不断运行),因此需要自行修改代码,实现时间片轮转和多道程序轮转运行。现在介绍前置操作:
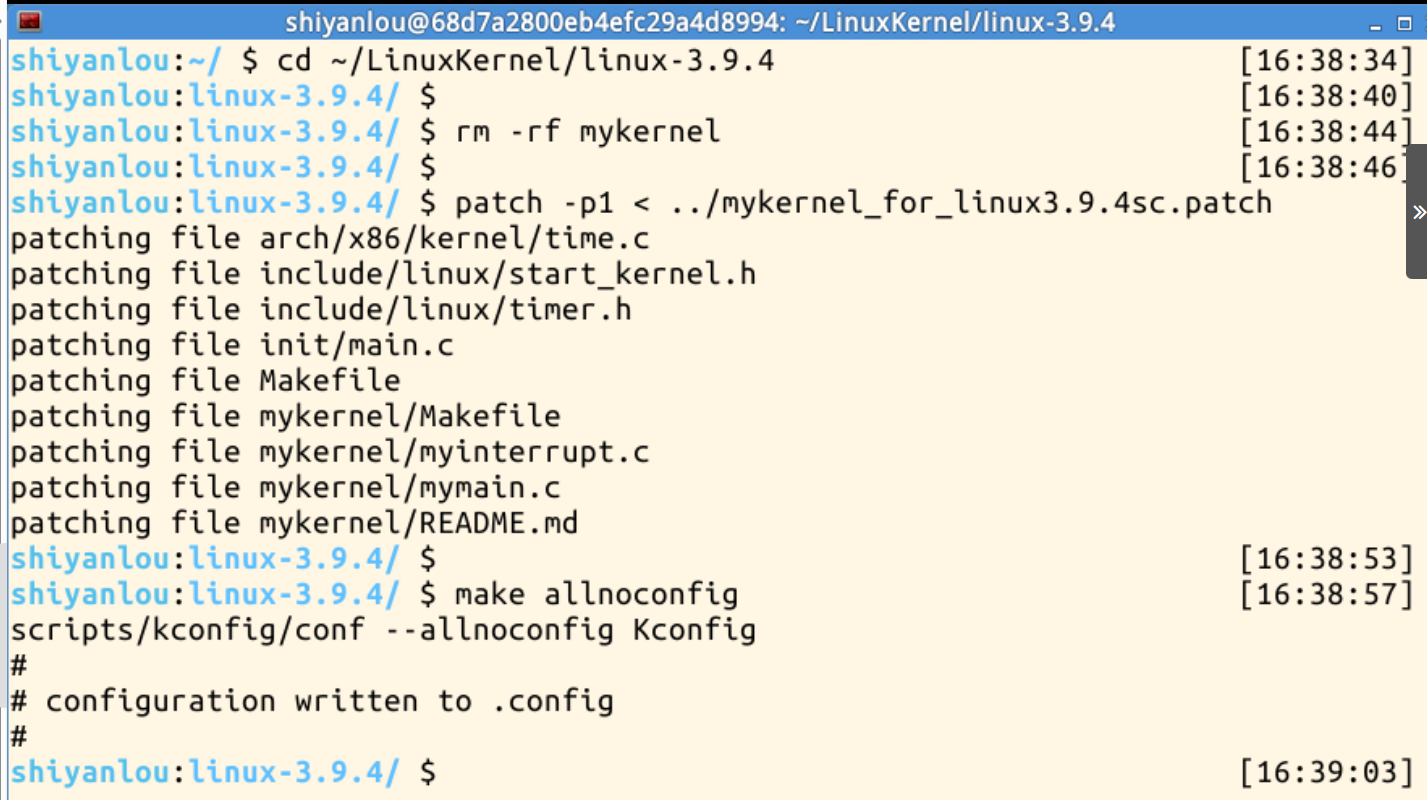
1、对内核进行最小化配置,代码如下:
# 切换到Linux内核源代码目录(此处为用户主目录下的LinuxKernel/linux-3.9.4)
$ cd ~/LinuxKernel/linux-3.9.4# 删除已存在的mykernel目录(如果有),确保补丁应用在干净的环境中
$ rm -rf mykernel# 应用补丁文件,-p1参数表示忽略补丁路径中的第一个目录层级
# 补丁文件位于当前目录的上一级,文件名为mykernel_for_linux3.9.4sc.patch
$ patch -p1 < ../mykernel_for_linux3.9.4sc.patch# 生成内核配置文件,allnoconfig表示禁用所有可选配置(仅保留必要功能)
# 这会生成一个最小化的内核配置,适合快速编译和测试
$ make allnoconfig
具体操作如下:
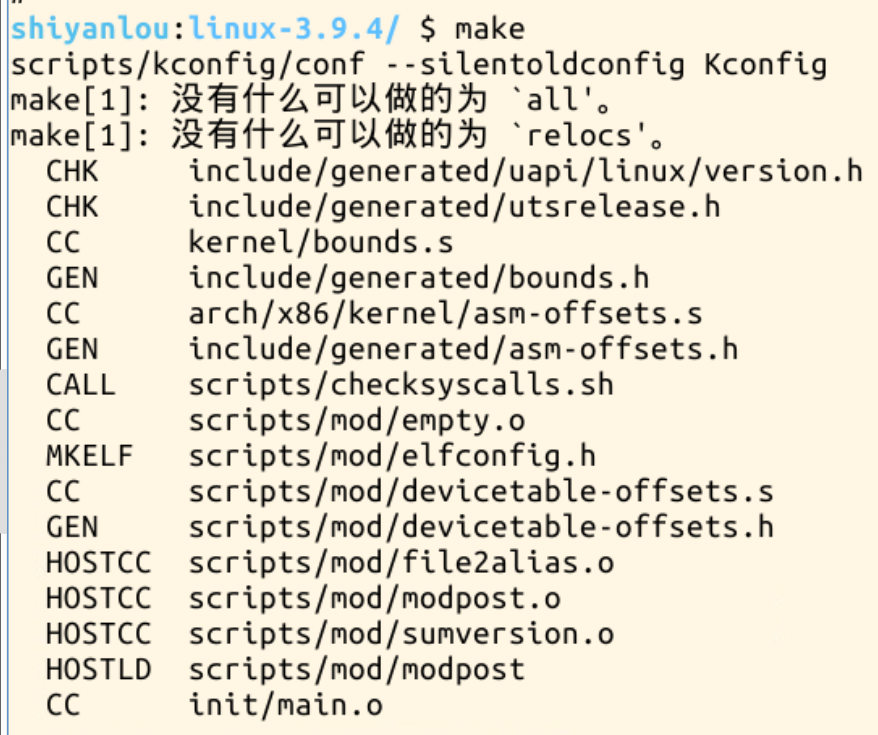
2、编译内核,代码如下:
# 编译内核,此过程会根据配置文件编译内核及相关组件
# 注意:编译大型内核需要较长时间,请耐心等待(具体时间取决于硬件性能)
$ make
具体操作如下:
3、使用qemu模拟器启动编译好的内核,代码如下:
# -kernel参数指定要启动的内核镜像,此处为arch/x86/boot/bzImage(32位x86架构的压缩内核镜像)
$ qemu -kernel arch/x86/boot/bzImage
操作效果如下:
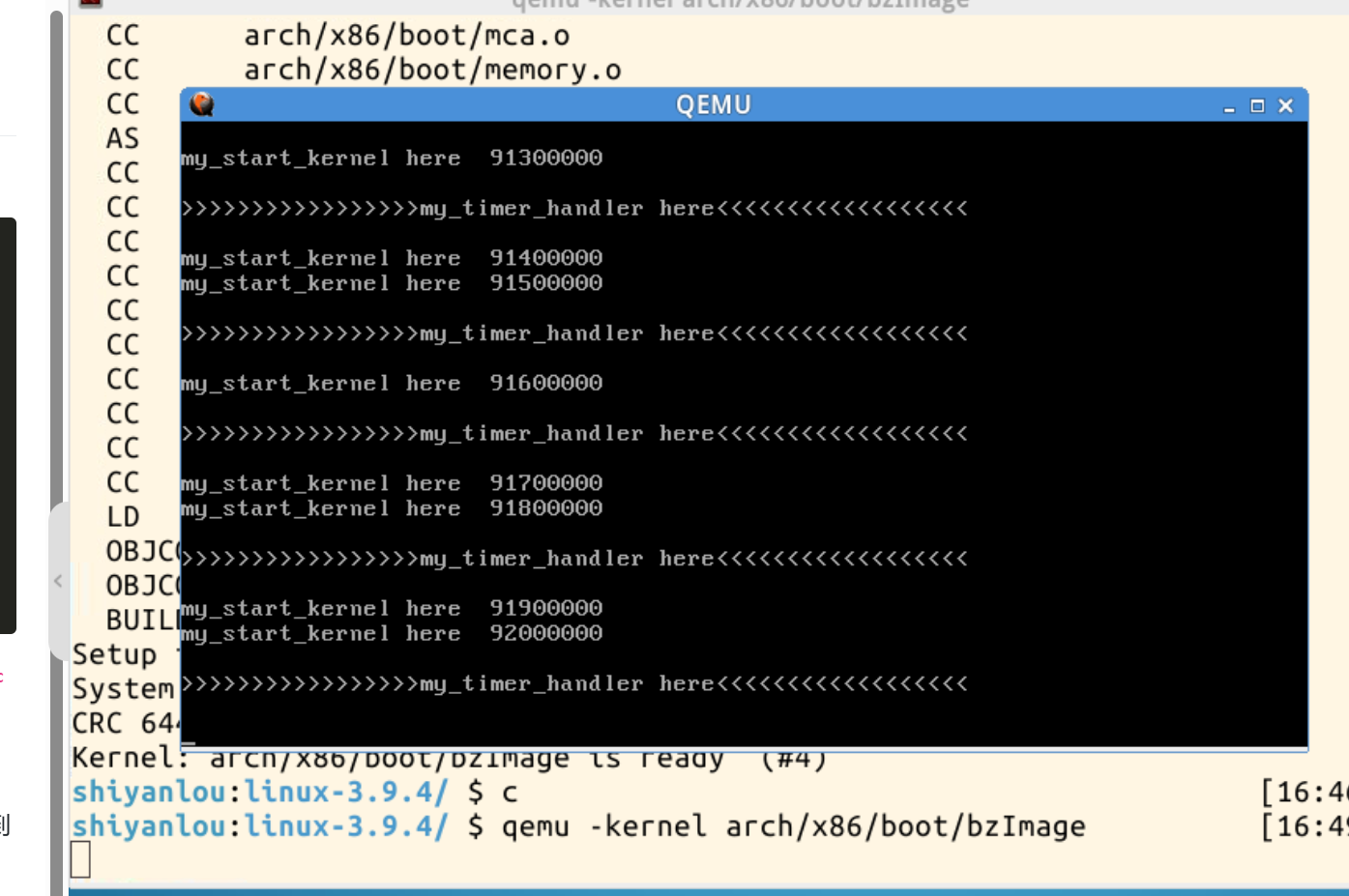
以上命令主要用于在 Linux 系统中编译并运行一个打了 mykernel 补丁的 3.9.4 版本内核。
三、完成一个简单的时间片轮转多道程序内核代码
根据前置代码可知,这个自定义的Linux内核在时间片轮转方面不够完善,需要根据以下步骤修改。
1、进入mykernel:
cd mykernel
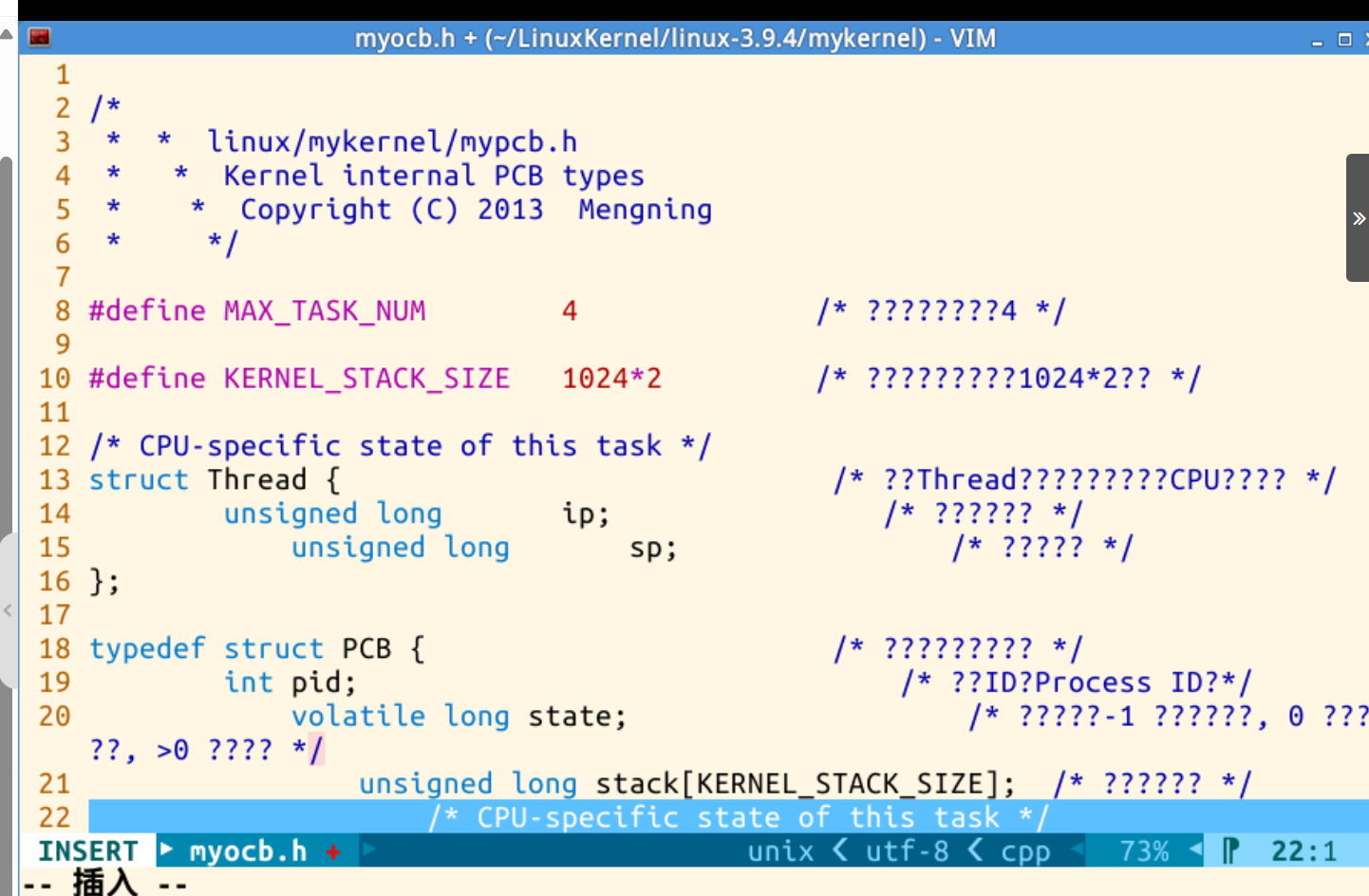
2、创建mypcb.h文件,编写进程控制块,通过多道程序在感官上同时运行,提高系统的响应速度和用户体验。代码如下:
/** linux/mykernel/mypcb.h* Kernel internal PCB types* Copyright (C) 2013 Mengning*/#define MAX_TASK_NUM 4 /* 定义最大任务数为4 */#define KERNEL_STACK_SIZE 1024*2 /* 定义内核堆栈大小为1024*2字节 *//* CPU-specific state of this task */
struct Thread { /* 定义Thread结构体,表示任务的CPU相关状态 */unsigned long ip; /* 存储指令指针 */unsigned long sp; /* 存储栈指针 */
};typedef struct PCB { /* 定义进程控制块参数 */int pid; /* 进程ID(Process ID)*/volatile long state; /* 进程状态:-1 表示不可运行, 0 表示可运行, >0 表示停止 */unsigned long stack[KERNEL_STACK_SIZE]; /* 存储内核堆栈 *//* CPU-specific state of this task */struct Thread thread; /* 存储任务的CPU相关状态 */unsigned long task_entry; /* 存储任务的入口地址 */struct PCB *next; /* 存储下一个进程控制块的指针,用于构建链表 */
} tPCB;void my_schedule(void); /* 声明调度函数my_schedule() */
操作过程如下,编辑mypch.h文件:

3、编辑mymain.c文件并修改,实现内核代码的入口,初始化内核的各个组成部分。代码如下:
/** linux/mykernel/mymain.c*/#include "mypcb.h" // 包含自定义的进程控制块头文件
#include <linux/tty.h>tPCB task[MAX_TASK_NUM]; // 定义一个tPCB类型的数组,存储任务控制块
tPCB *my_current_task = NULL; // 指向当前运行任务的指针
volatile int my_need_sched = 0; // 表示是否需要进行进程调度的标志void my_process(void); // 声明my_process函数void __init my_start_kernel(void) // 内核初始化函数
{int pid = 0;int i;/* 初始化进程0 */task[pid].pid = pid;task[pid].state = 0; /* -1 不可运行, 0 可运行, >0 停止 */task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process; // 设置进程0的入口地址task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE - 1]; // 设置进程0的栈指针task[pid].next = &task[pid]; // 初始化进程0的next指针,形成循环链表/* 复制进程0的状态来创建更多进程 */for (i = 1; i < MAX_TASK_NUM; i++){memcpy(&task[i], &task[0], sizeof(tPCB));task[i].pid = i; // 初始化进程IDtask[i].state = -1; // 设置状态为不可运行task[i].thread.sp = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE - 1]; // 初始化堆栈指针task[i].next = task[i - 1].next; // 更新next指针,构建进程链表task[i - 1].next = &task[i];}/* 启动进程0 */pid = 0;my_current_task = &task[pid]; // 设置当前任务为进程0asm volatile("movl %1,%%esp\n\t" /* 将栈顶指针指向进程0的栈底 */"pushl %1\n\t" /* 压入栈底地址 */"pushl %0\n\t" /* 压入入口地址 */"ret\n\t" /* 返回到入口地址 */"popl %%ebp\n\t" /* 弹出栈底地址到ebp寄存器 */:: "c"(task[pid].thread.ip), "d"(task[pid].thread.sp) // 输入操作数);
}void my_process(void)
{int i = 0;while (1){i++;if (i % 10000000 == 0){printk(KERN_NOTICE "this is process %d -\n", my_current_task->pid); // 打印当前进程的信息if (my_need_sched == 1){my_need_sched = 0;my_schedule(); // 调用进程调度函数}printk(KERN_NOTICE "this is process %d +\n", my_current_task->pid); // 打印当前进程的信息}}
}
具体操作过程如下:
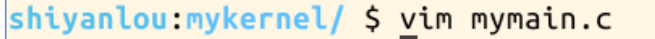
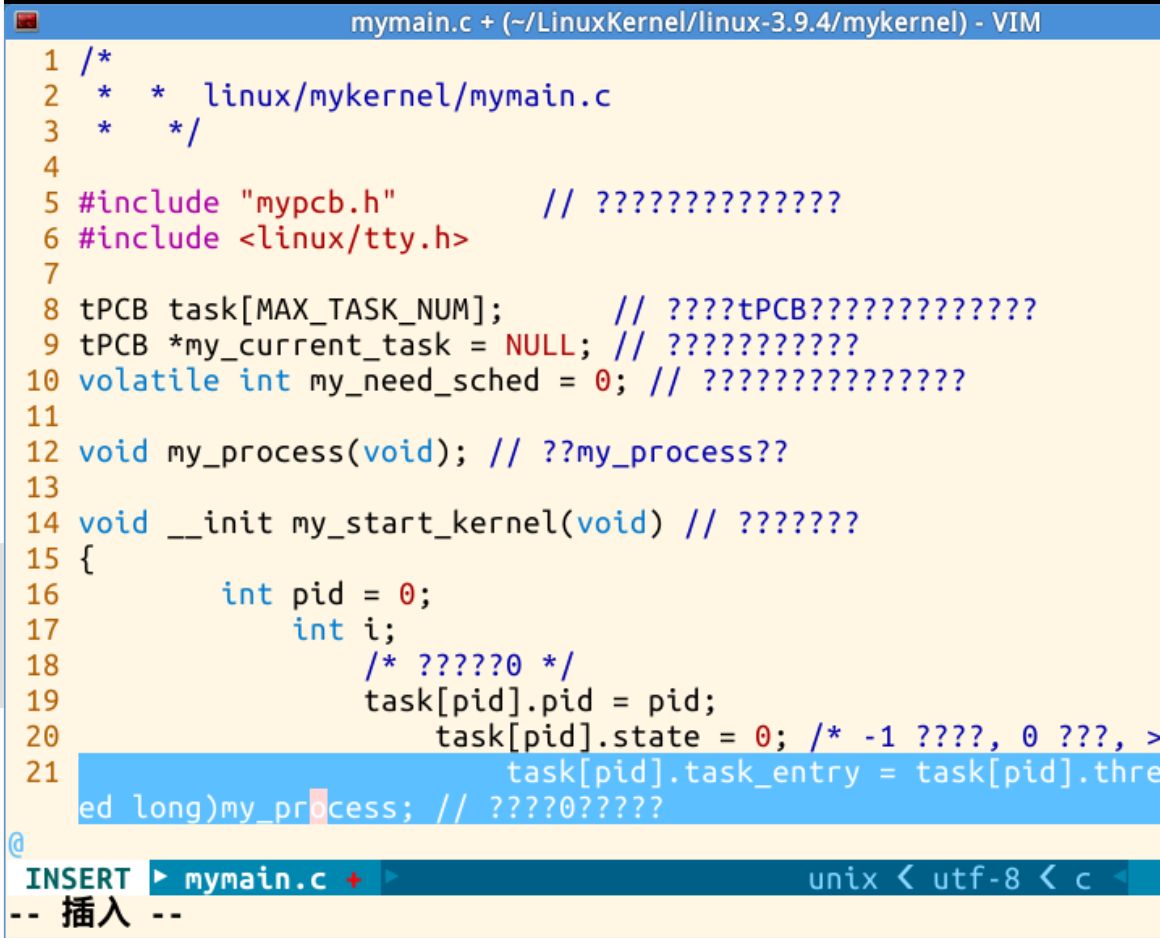
4、编辑myinterrupt.c文件,实现中断控制,增加了对进程切换时的my_schedule函数。代码如下:
/** linux/mykernel/myinterrupt.c*/#include "mypcb.h" // 包含自定义的进程控制块头文件
#include <linux/types.h>
#include <linux/string.h>
#include <linux/ctype.h>
#include <linux/tty.h>
#include <linux/vmalloc.h>extern tPCB task[MAX_TASK_NUM]; // 外部声明,引用来自其他文件的全局变量
extern tPCB *my_current_task;
extern volatile int my_need_sched;
volatile int time_count = 0;/** 当定时器中断被调用时执行的处理函数。*/
void my_timer_handler(void)
{if (time_count % 1000 == 0 && my_need_sched != 1){printk(KERN_NOTICE ">>>my_timer_handler here<<<\n"); // 打印调试信息my_need_sched = 1; // 设置需要进行进程调度的标志}time_count++;return;
}/** 进程调度函数*/
void my_schedule(void)
{tPCB *next;tPCB *prev;// 检查当前任务和下一个任务是否有效if (my_current_task == NULL || my_current_task->next == NULL){return;}printk(KERN_NOTICE ">>>my_schedule<<<\n"); // 打印调度信息/* 进行任务切换 */next = my_current_task->next; // 获取下一个任务prev = my_current_task; // 获取当前任务if (next->state == 0) /* -1 不可运行, 0 可运行, >0 停止 */{my_current_task = next; // 切换到下一个任务printk(KERN_NOTICE ">>>switch %d to %d<<<\n", prev->pid, next->pid); // 打印任务切换信息/* 执行任务切换 */asm volatile("pushl %%ebp\n\t" /* 压栈当前任务的值 */"movl %%esp,%0\n\t" /* 将当前栈指针保存到当前任务的tPCB结构中 */"movl %2,%%esp\n\t" /* 切换到下一个任务的栈指针 */"movl $1f,%1\n\t" /* 将标签1的地址保存到当前任务的thread.ip中 */"pushl %3\n\t" /* 将下一个任务的thread.ip压栈 */"ret\n\t" /* 返回,实现任务切换 */"1:\t" /* 标签1,用于返回时跳转 */"popl %%ebp\n\t": "=m"(prev->thread.sp), "=m"(prev->thread.ip): "m"(next->thread.sp), "m"(next->thread.ip));}else{next->state = 0; // 设置下一个任务的状态为可运行my_current_task = next; // 切换到下一个任务printk(KERN_NOTICE ">>>switch %d to %d<<<\n", prev->pid, next->pid); // 打印任务切换信息/* 执行任务切换 */asm volatile("pushl %%ebp\n\t" /* 压栈当前任务的值 */"movl %%esp,%0\n\t" /* 将当前栈指针保存到当前任务的tPCB结构中 */"movl %2,%%esp\n\t" /* 切换到下一个任务的栈指针 */"movl %2,%%ebp\n\t" /* 切换到下一个任务的栈底指针 */"movl $1f,%1\n\t" /* 将标签1的地址保存到当前任务的thread.ip中 */"pushl %3\n\t" /* 将下一个任务的thread.ip压栈 */"ret\n\t" /* 返回,实现任务切换 */"1:\t" /* 标签1,用于返回时跳转 */"popl %%ebp\n\t": "=m"(prev->thread.sp), "=m"(prev->thread.ip): "m"(next->thread.sp), "m"(next->thread.ip));}return;
}具体操作如下:
5、回到上级目录,重新用make编译内核,编译过程如下:
6、使用qemu命令运行内核,代码如下:
qemu -kernel arch/x86/boot/bzImage
具体操作如下,输入该指令:
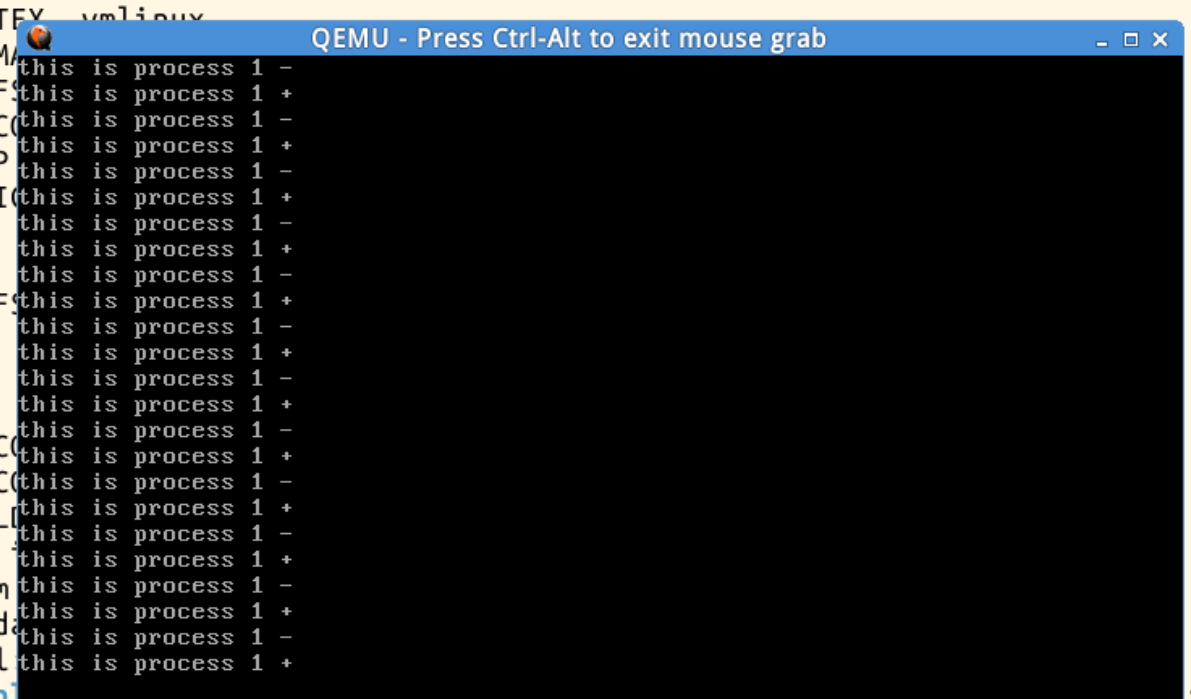
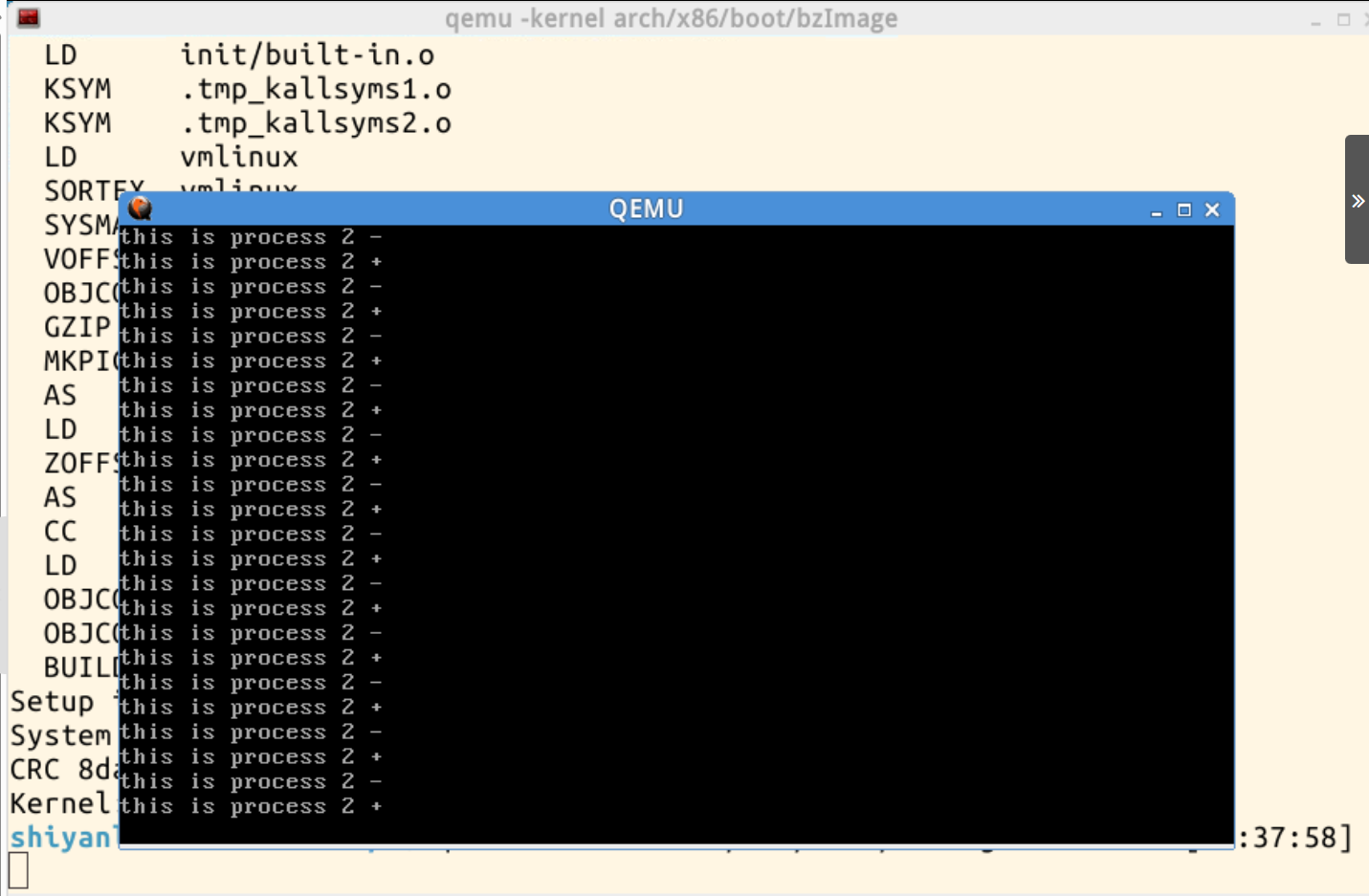
指令执行后可以看到程序在切换:
五、总结
本次实验聚焦操作系统领域,成功实现自定义Linux内核与基于时间片轮转的多道程序运行,让我深度掌握了Linux内核多进程运行原理,为后续学习筑牢基础。时间片轮转作为关键调度策略,优势显著:它通过让多个进程按小时间片交替执行,既能避免死锁、大幅提升CPU、内存等系统资源利用率,又能保障各就绪进程获得公平的运行机会,有效防止饥饿现象;同时,其短响应特性适配交互式应用需求,还能支持多用户环境下多个用户任务的正常处理,显著优化系统响应速度与用户体验。
六、豆包工具学习知识
1、了解时间片轮转的概念

2、时间片轮转的优化方向
