从零起步学习Redis || 第二章:Cache Aside Pattern(旁路缓存模式)以及优化策略

前言:
今天继续我们的Redis学习,主要讲解一下Cache Aside Pattern(旁路缓存模式)
概念:
Cache Aside Pattern,又称 Lazy Loading(懒加载)模式,是一种典型的 应用程序主动去操作缓存 的策略。
核心思想是:应用程序先从缓存中读取数据,如果缓存中没有,再去数据库加载,并把数据写入缓存。
换句话说,缓存是“旁路”式的,数据的来源仍然是数据库,缓存只是辅助,应用程序负责管理缓存。
工作原理
读取数据流程:
应用程序尝试从缓存中读取数据。
如果缓存命中(cache hit),直接返回数据。
如果缓存未命中(cache miss):
从数据库中读取数据。
将数据写入缓存(可设置 TTL,防止缓存永久存在)。
返回数据给客户端。
写入数据流程:
当数据更新时,先更新数据库。
再删除缓存中对应的数据(或直接更新缓存)。
下次读取时,会重新加载最新数据到缓存。
关键点:应用程序负责控制缓存和数据库的数据一致性。
重点:
前面这些可以看到都非常简单易懂,那么我的问题来了:
为什么要先操作数据库,再操作缓存?
答:
场景设定:高并发下的数据更新
- 数据 X:初始值
X=10(保存在数据库和缓存中)。 - 请求 A (写请求):要将
X更新为20。 - 请求 B (读请求):在 A 的更新操作过程中读取
X。 - 目标状态:数据库
X=20,缓存X=20(或缓存无X,下次读时回填)。
分类讨论一下:
错误顺序剖析:先删缓存,再更新数据库 (删除Cache -> 更新DB)
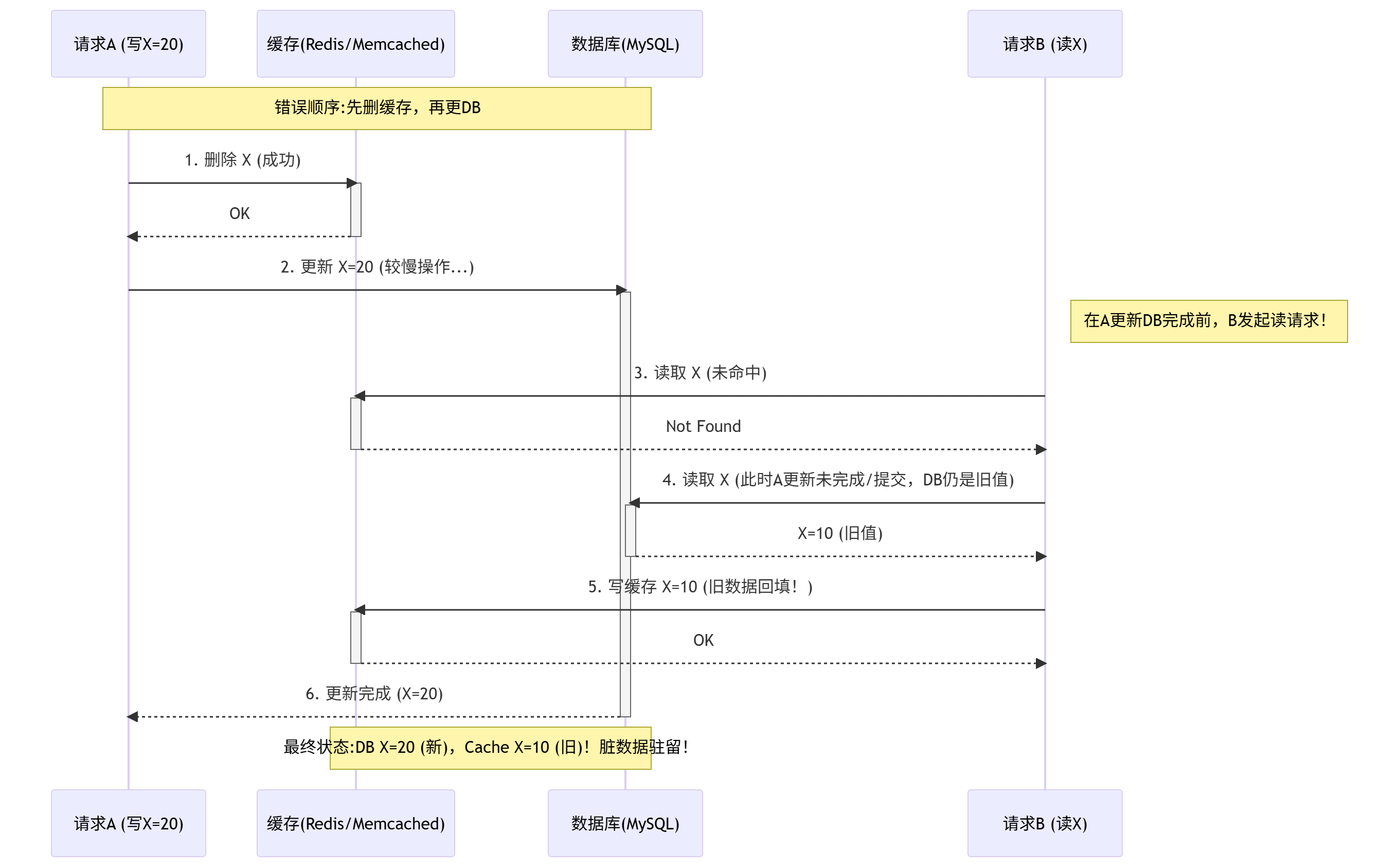
关键步骤解读(错误顺序):
- A (写) 删缓存: 请求 A 成功删除了缓存中的
X。此时缓存为空。 - A (写) 开始更新DB(慢): 请求 A 开始执行数据库更新操作(这通常涉及网络I/O、磁盘I/O、事务处理等,相对较慢)。
- B (读) 读缓存(未命中): 在 A 的数据库更新完成之前,请求 B 来读取
X。发现缓存中没有X(因为被 A 删了)。 - B (读) 读DB(读到旧值): 请求 B 转而查询数据库。关键点来了:此时请求 A 的
UPDATE操作可能还在进行中(未提交事务),或者虽然开始了但还没执行到X所在的记录。因此,数据库返回给 B 的仍然是旧值X=10。 - B (读) 回填缓存(写入旧值!): 请求 B 遵循“读未命中则回填缓存”的原则,将从数据库读到的旧值
X=10写入了缓存。 - A (写) 完成DB更新: 请求 A 终于完成了数据库更新,将
X成功设置为20。 - 最终状态:
- 数据库:
X=20(新值,正确)。 - 缓存:
X=10(旧值!严重错误!)。
- 数据库:
- 严重后果: 缓存中的旧数据
X=10会一直存在,直到这个缓存项因为过期(TTL)被清除,或者下次有成功的写操作再次触发删除缓存(或下一次写操作再次触发删除缓存(或下一次读请求在缓存过期后触发回填)。在这段时间内,所有读取X的请求都会拿到错误的旧值10!这就是脏数据长期驻留缓存问题。缓存完全失去了意义,甚至起到了反作用。
正确顺序剖析:先更新数据库,再删除缓存 (更新DB -> 删除Cache)
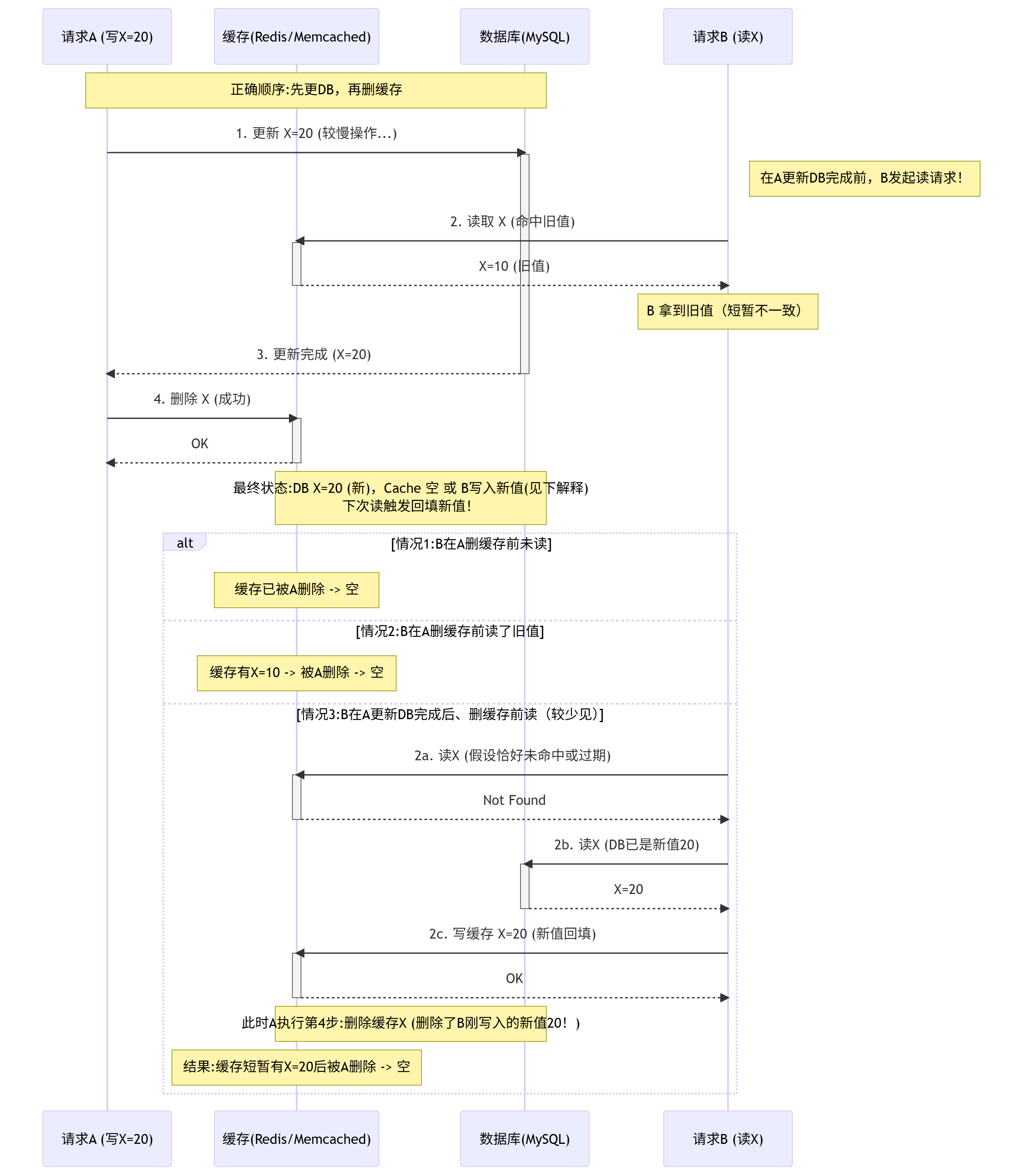
关键步骤解读(正确顺序):
- A (写) 更新DB(慢): 请求 A 开始执行数据库更新操作(慢)。
- B (读) 读缓存(命中旧值): 在 A 的数据库更新完成之前,请求 B 读取
X。此时缓存中还有未被删除的旧值X=10,B 直接命中缓存拿到旧值。这是一个短暂的(通常只有几毫秒到几十毫秒)不一致窗口。 - A (写) 完成DB更新: 请求 A 成功将数据库中的
X更新为20。 - A (写) 删除缓存: 请求 A 立刻删除缓存中的
X。这是最关键的一步! - 处理并发读 (B):
- 情况1 (B在A删缓存前读取完毕): B 已拿到旧值
10,流程结束。缓存随后被A删除。下次读会触发回填新值20。 - 情况2 (最常见 - B已读完旧值): 缓存中可能还有B读过的旧值
10,但被A在第4步强制删除掉了! - 情况3 (罕见 - B在DB更新后、缓存删除前读):
- B读缓存未命中(可能刚好被其他操作清掉,或TTL到期)。
- B读数据库,此时DB已是新值
20(因为A的更新已经完成)。 - B将**新值
20**回填到缓存。 - 紧接着,A执行第4步删除缓存的操作,将B刚写入的新值
20也删除了!
- 情况1 (B在A删缓存前读取完毕): B 已拿到旧值
最终状态&自我修复
- 无论B在A的操作过程中做了什么,在A成功执行完第4步
删除缓存之后,缓存中关于X的数据一定是不存在的(被删除了)。 - 数据库的状态是确定的新值
X=20。 - 后续任何一个读请求过来:
- 读缓存:未命中(因为X已被删除)。
- 读数据库:拿到新值
20。 - 回填缓存:将新值
20写入缓存。
- 系统达成最终一致: 数据库
X=20,缓存X=20。之前的短暂不一致(B读到旧值)或缓存短暂存放新值后被删除,都被后续的正常读流程自动修复了。不会出现旧数据长期污染缓存的情况!
为什么正确顺序更好?核心优势总结表
| 特性 | 错误顺序:删缓存 -> 更新DB | 正确顺序:更新DB -> 删缓存 | 优势说明 |
|---|---|---|---|
| 脏数据驻留缓存风险 | 极高 | 极低 | 错误顺序导致旧数据被读请求回填并长期留存;正确顺序通过后续删除和读回填确保缓存最终是新数据或空。 |
| 不一致持续时间 | 长 (直到下次写/缓存过期) | 短 (通常毫秒级,直到下次读请求回填) | 正确顺序下不一致窗口仅限于并发读写重叠且读在DB更新后、缓存删除前的极短时间 + 下次读请求的处理时间。 |
| 操作失败后果 | 严重 (删缓存成功+更新DB失败:缓存空+DB旧值) | 相对可控 (更新DB成功+删缓存失败:DB新值+缓存旧值) | DB有正确的新值是底线。缓存旧值可通过重试删除、TTL过期或下次触发删除修复。缓存空+DB旧值会导致数据丢失错觉。 |
| 设计理念符合度 | 低 (直接干预缓存作为写入口) | 高 (缓存是副本,写只操作数据源DB,失效缓存副本) | 逻辑更清晰,职责分离。 |
| 并发写影响 | 可能导致缓存与DB都错乱 | 无额外影响 | 正确顺序只涉及DB并发写(DB自身事务保证)和独立的缓存删除。 |
如果最后缓存中还是有旧数据,可以怎么继续进行优化?
答:
常见优化方案(按复杂度递增)
双删(Double Delete)
做法:事务提交后删一次缓存,稍微
sleep几十毫秒,再删一次。作用:避免并发线程把旧值写回缓存。
缺点:依赖
sleep,效果不稳定,算是“土办法”。
更新缓存(而不是删除)
在 DB 提交成功后,直接
set(key, newValue)。优点:减少旧值回写缓存的机会。
缺点:需要处理并发写入的覆盖问题(可能要用版本号/CAS 机制)。
版本号 / 时间戳机制
缓存中存储一个
version字段,每次更新时带上版本号。写缓存时只在
newVersion > oldVersion时才覆盖。优点:能有效防止旧值覆盖新值。
缺点:实现复杂度稍高。
分布式锁(针对热点 Key)
在回填缓存时对 Key 加分布式锁(如 Redis 的
SETNX)。确保同一时刻只有一个线程能写入缓存,避免并发覆盖。
缺点:增加延迟,适合少量热点 Key,不适合全局使用。
事件驱动(消息队列同步)
DB 更新成功后,发消息到 MQ,各个服务节点订阅并失效本地缓存。
优点:在分布式场景下保持多实例缓存一致性。
缺点:引入 MQ,系统架构更复杂。
总结:
基本原则:
先写数据库,再操作缓存(删除或更新),因为数据库是权威数据源。
这样可以避免缓存中长期存在脏数据。
仍然可能的问题:
在高并发下,缓存中仍可能被旧数据覆盖(短暂不一致)。
常见优化手段:
双删(double delete):DB 提交后删一次缓存,再延迟一小段时间再删一次。
更新缓存而不是删除:直接把新值写入缓存,减少 cache miss。
版本号 / 时间戳:缓存数据携带版本,只有新版本才能覆盖旧版本。
分布式锁:对热点 key 加锁,避免多个线程同时写缓存。
事件驱动(消息队列):DB 更新后发事件,多个服务节点订阅,统一删除/更新缓存。
取舍建议:
大部分业务:用「先 DB → 再删缓存」足够。
高并发热点场景:结合版本号/锁/事件驱动,保证缓存更强一致性。
最后非常感谢大家的关注和支持,有任何问题都可以在评论区提出,我一定会认真解答!