地平线机器人具身导航快慢推理新探索!FSR-VLN:基于分层多模态场景图快慢推理的视觉语言导航
- 作者: Xiaolin Zhou1^{1}1, Tingyang Xiao1^{1}1, Liu Liu1^{1}1, Yucheng Wang1^{1}1, Maiyue Chen1^{1}1, Xinrui Meng2^{2}2, Xinjie Wang1^{1}1, Wei Feng1^{1}1, Wei Sui2^{2}2, Zhizhong Su1^{1}1
- 单位:1^{1}1地平线机器人,2^{2}2D-Robotics机器人
- 论文标题:FSR-VLN: Fast and Slow Reasoning for Vision-Language Navigation with Hierarchical Multi-modal Scene Graph
- 论文链接:https://arxiv.org/pdf/2509.13733
主要贡献
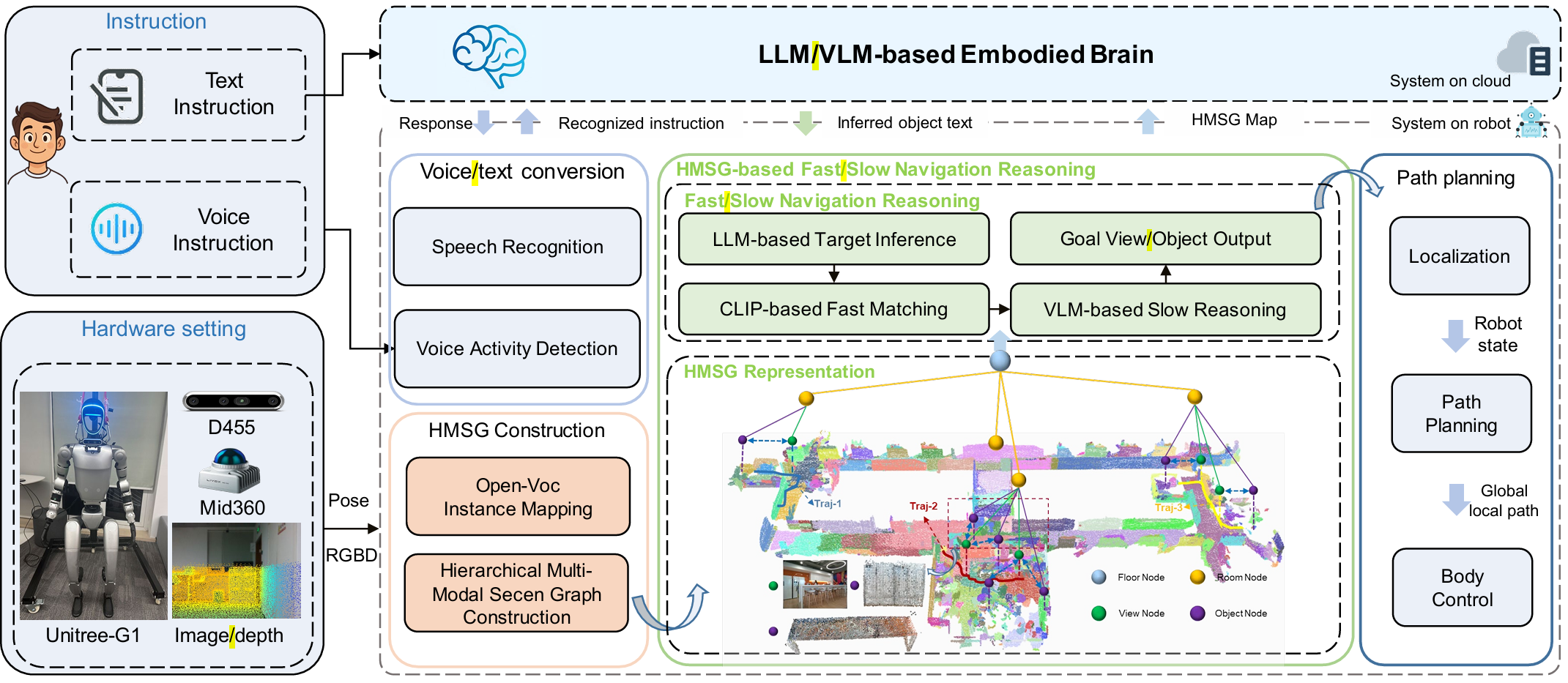
- 提出了分层多模态场景图(HMSG)地图表示方法,将分层场景图用于长距离导航的优势与图像拓扑图用于细粒度推理的优势相结合,能够实现从粗粒度导航线索到精确目标定位的渐进检索,同时保留多模态信息,确保在真实环境中的鲁棒性和高成功率。
- 引入了快速到慢速导航推理系统(FSR),受人类认知的双重加工理论启发,该系统分为两个阶段。快速、直观的匹配步骤检索候选视图和对象,然后在慢速、深思熟虑的推理阶段,利用大型语言模型/视觉语言模型(LLM/VLM)进行验证和细化最终目标,显著提高了真实世界长距离导航的成功率。
- 在四个由人形机器人收集的室内数据集上,使用87条涵盖多种对象类别的指令进行评估,FSR-VLN实现了最先进的(SOTA)性能,比HOVSG高出77%的成功率,比MobilityVLA高出167%,并且与基于VLM的方法相比,通过仅在快速直觉失败时激活慢速推理,将响应时间减少了82%。
- 构建了完整的人形机器人导航系统,将FSR-VLN与语音交互、规划和控制模块集成在Unitree-G1人形机器人上,实现了自然语言交互和实时导航,展示了该系统在真实世界应用中的潜力。
研究背景
- 视觉语言导航(VLN)是机器人系统中的一个基础挑战,对于在真实世界环境中部署具身智能体具有广泛的应用前景。尽管在无地图VLN研究和为机器人配备视觉语言推理方面取得了显著进展,但现有方法在长距离空间认知方面仍存在局限性,尤其是在长距离导航任务中,表现为成功率低和推理延迟高。
- 现有的空间记忆方法虽然能够提供几何一致性和语义信息,但依赖于预先提取的视觉特征,缺乏与视觉语言模型(VLM)的直接交互,并且对几何噪声敏感,限制了其对多样化用户指令和复杂真实世界导航的适应性。
- 图像拓扑导航方法虽然在图像级导航中成功率高,但缺乏显式的三维几何结构,通常依赖于视频字幕,这在长序列推理中效率低下。
方法
分层多模态场景图表示
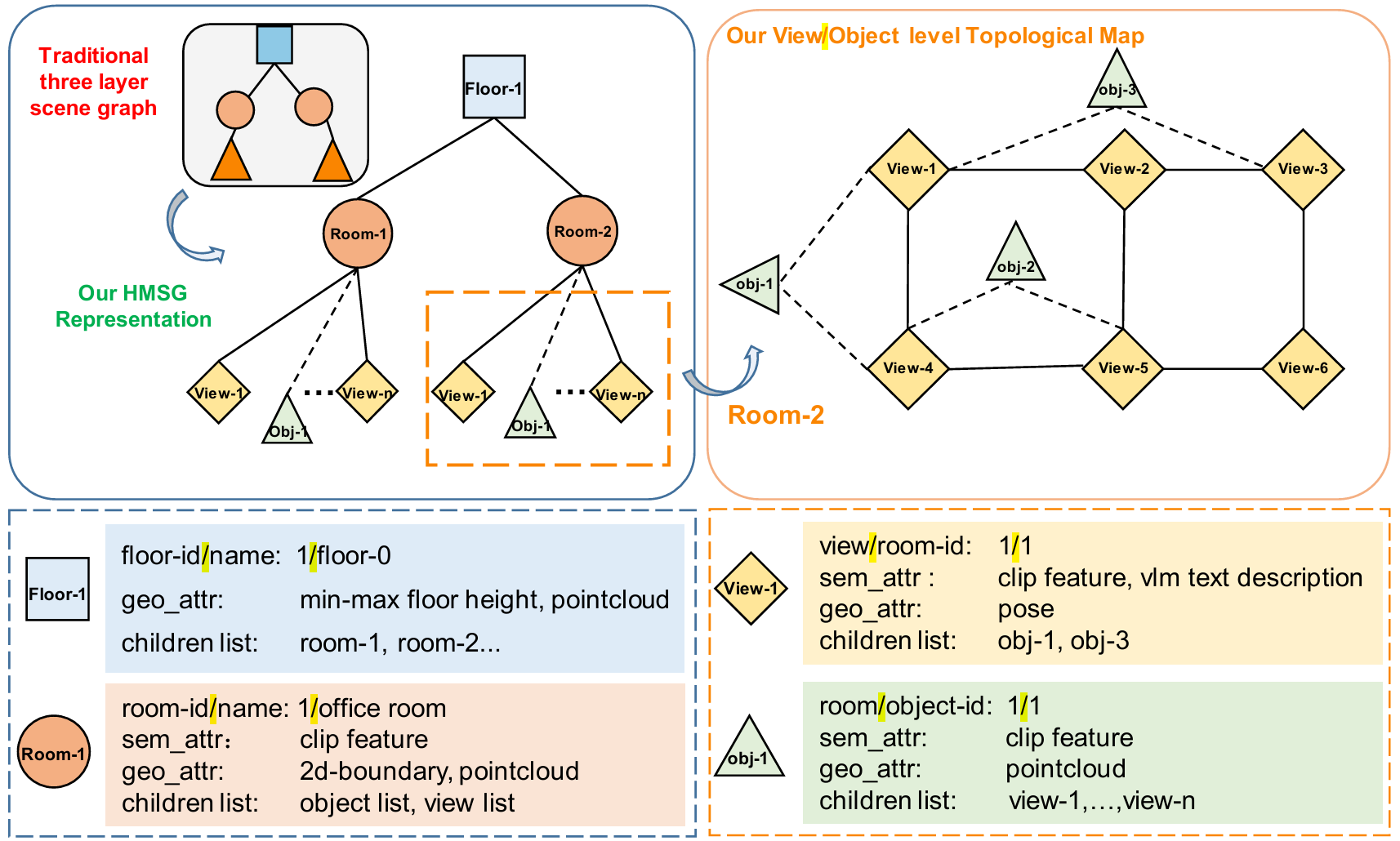
- 分层结构:提出的HMSG分为四个分层:楼层(floor)、房间(room)、视图(view)和对象(object)节点。这种分层结构支持分层检索,从粗粒度的导航线索到细粒度的目标定位。
- 节点特征:
- 楼层节点:记录楼层标识符、名称、几何属性(如最小/最大高度、点云)以及包含的房间引用。
- 房间节点:存储房间ID、2D多边形边界、点云、语义属性(名称、CLIP嵌入)以及与视图和对象节点的链接。
- 对象节点:表示房间内的离散实例,包含几何属性(3D边界框、点云)、语义嵌入以及与父房间节点和图像视图的链接。
- 视图节点:代表房间内的特定视觉视角,存储CLIP嵌入、VLM生成的描述作为语义特征,以及相机姿态作为几何属性。它们与可见对象节点相连,编码可见性关系,支持多视图感知和图像或对象级定位。
- 优势:与传统方法相比,HMSG不仅包含几何和语义信息,还通过视图节点引入了图像拓扑图的优势,使得机器人能够在图像级导航中选择上下文相关的视图,同时增强对象级导航能力。
分层多模态场景图构建
- 输入与输出:以楼层-房间-对象布局和带姿态的图像视图为输入,输出一个有向图G,其中节点代表语义实体(楼层、房间、视图、对象),边编码结构关系(如房间在楼层中、对象在房间中)。
- 构建过程:
- 初始化空图G。
- 依次添加楼层节点,并为每个楼层添加房间节点,建立楼层与房间的连接。
- 对于每个房间中的图像视图,添加视图节点并与房间节点相连。
- 对于房间中的每个对象,添加对象节点并与房间节点相连。
- 遍历房间中每个视图可见的对象,添加对象与视图之间的边,并计算对象在每个可见视图中的平均深度,选择深度最小(最近的外观)的视图作为对象的代表性视图。
- 特点:与HOVSG类似,FSR-VLN利用GPT-4o从图像视图中推断房间名称,并为每个视图关联CLIP嵌入、VLM生成的字幕和相机姿态。最终构建的HMSG编码了分层拓扑和多模态特征,包括语义、几何和可见性信息,为快速到慢速推理提供了基础。
基于大模型和多模态特征的快慢导航推理
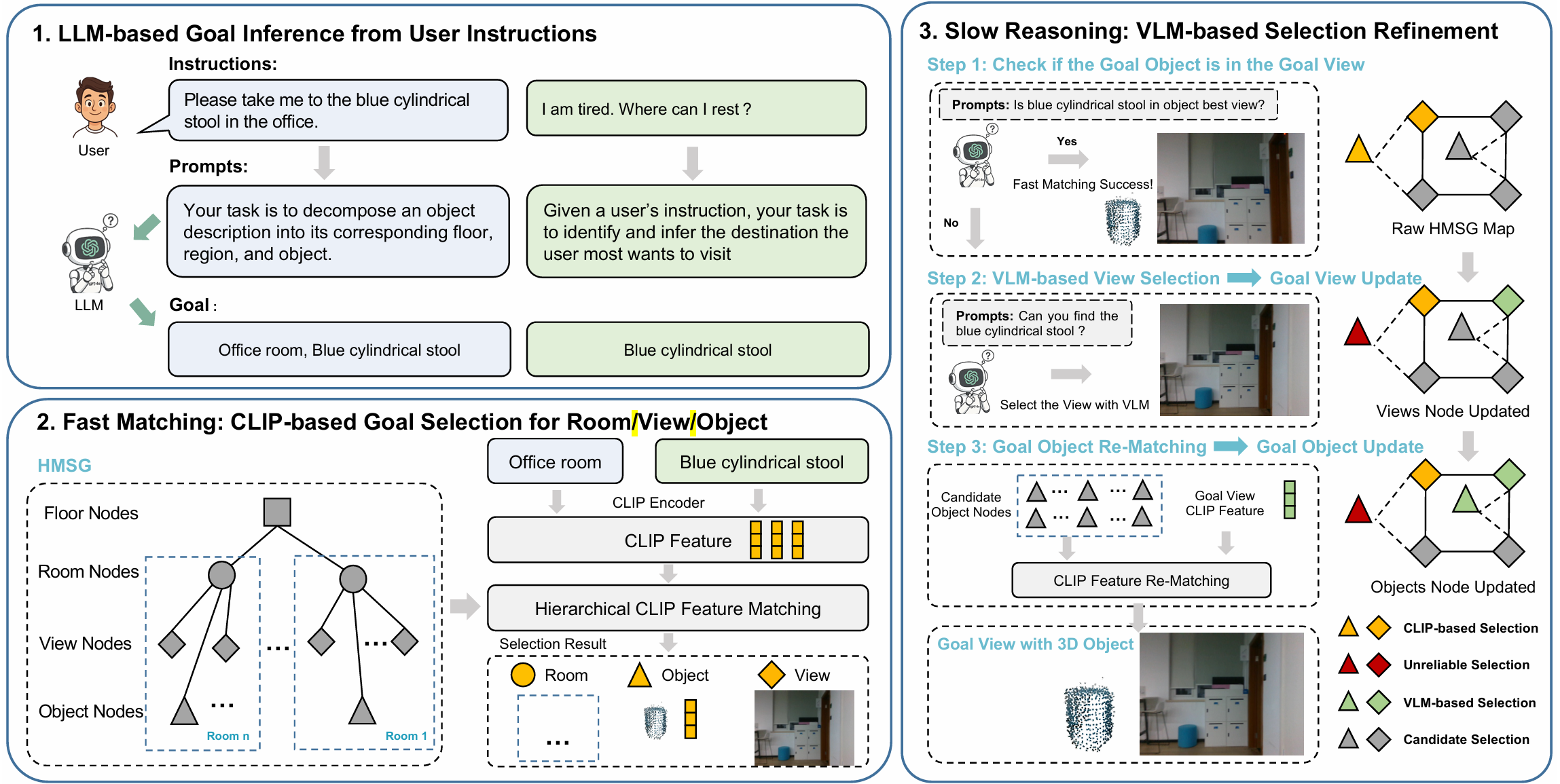
- LLM基于的用户指令理解:
- 处理空间明确和隐含的自然语言指令。对于空间指令,LLM作为分层概念解析器,将输入分解为结构化组件(如楼层、区域、对象),直接映射到分层场景图的节点,实现精确定位。
- 对于非空间指令,LLM作为目标推断智能体,根据用户意图识别最相关的对象或区域,然后通过场景图将对象级语义解析为空间目标。这种提示框架支持对多样化用户表达的泛化,促进真实环境中的人机交互。
- 快速匹配:
- 如果指令中提供了房间名称,则首先匹配房间,然后在该房间内进行视图和对象匹配。利用图像视图节点和LLM解析的文本查询,基于CLIP的快速匹配在查询文本和HMSG视图层嵌入之间进行,以识别目标视图。同时,通过匹配查询文本和对象嵌入之间的CLIP特征来确定对象级位置,具有最高相似性的对象被认为是潜在目标。
- 尽管快速匹配可以快速定位目标视图和对象实例,但由于CLIP模型的匹配能力限制,可能会出现错误匹配。因此,在基于CLIP的快速匹配基础上,进一步引入基于VLM的慢速推理,以获得更精确的目标视图和对象。
- 慢速推理:
- 在快速匹配后,获得目标视图、目标对象以及其他候选视图。利用VLM的推理能力,使用GPT-4o验证从快速匹配步骤中匹配到的对象的最佳视图中是否出现了目标对象。由于HMSG地图中的对象保证在其对应的最佳视图中出现,如果GPT-4o确定在匹配对象的最佳视图中没有出现解释的对象,则认为匹配的对象不可靠。
- 尽管快速匹配可能失败,但正确的目标视图可能仍然存在于匹配视图或未匹配候选视图中。为了应对这种情况,重新应用LLM和VLM推理来识别最佳目标图像。具体来说,首先使用LLM对HMSG中未匹配视图的文本描述进行推理,选择语义上最一致的图像作为view-1。然后,将快速匹配的视图与视图1进行比较,并应用VLM推理以确定最终的最佳目标图像。一旦确定了最终的目标图像,通过遍历其在HMSG中的对象列表并重新计算查询文本与每个对象之间的CLIP相似性来更新目标对象。
实验
实验设置
- 使用Unitree-G1人形机器人在具有长走廊和多个房间的长距离办公环境中收集激光雷达-相机数据,构建了四个房间的数据集。
- 为了评估系统的泛化能力,收集了87条用户指令,分为推理自由(RF)、推理要求(RR)、小目标(SO)和空间目标(ST)四个类别,涵盖了23、18、15和14个对象类别。
- 评估指标包括成功率(SR)和检索成功率(RSRtop-n@k),其中RSR定义为至少有一个top-n预测(n∈1,5)位于真实值k米(欧几里得距离)范围内的查询百分比。
- 与几种基于不同地图表示的SOTA ObjNav方法进行比较,包括基于CLIP的3D体素地图(OK-Robot)、基于CLIP的3D场景图(HOVSG)和基于图像的拓扑图(MobilityVLA)。
基准测试结果

- FSR-VLN在所有数据集上均实现了最高的平均成功率(SR)92%,相较于MobilityVLA、OK-Robot和HOVSG分别提高了167%、51%和77%。在RSR@Top1指标上,FSR-VLN在不同距离阈值下均表现出色,尤其在4-5米时达到了96.6%,表明其强大的长距离检索能力。
- MobilityVLA由于缺乏3D空间线索,导致语义与几何信息不匹配,在短距离RSRtop-1@k(k=1,2米)上表现最低,但在较大距离容差(3-5米)下排名第二,反映了其在图像序列推理方面的优势。
- OK-Robot和HOVSG均受限于CLIP类模型,缺乏对匹配对象的空间验证,导致导航失败率较高。而FSR-VLN利用HMSG表示,编码了楼层、房间、视图和对象之间的几何、语义和拓扑关系,并在此基础上通过VLM驱动的FSR机制,先进行快速特征匹配检索候选视图和对象,再进行VLM推理验证,当检测到不匹配时,慢速推理会细化最终选择,从而提高了整体导航性能。
定性分析

- 展示了FSR-VLN在Room4中对不同类型指令的目标视图和对象检索结果,证明了其在长距离室内环境中能够成功检索目标视图和对象。
运行时分析
- MobilityVLA需要大约30秒来推理图像视图序列,而OK-Robot和HOVSG仅需0.2秒即可计算文本-对象相似性。FSR-VLN仅依赖于目标推断和快速匹配时平均响应时间为1.5秒,当包含慢速推理时为5.5秒。通过仅在快速匹配失败时调用慢速推理,并将VLM细化应用于候选视图而不是整个序列,FSR-VLN与MobilityVLA相比将平均响应时间减少了82%,同时提高了成功率。
消融分析
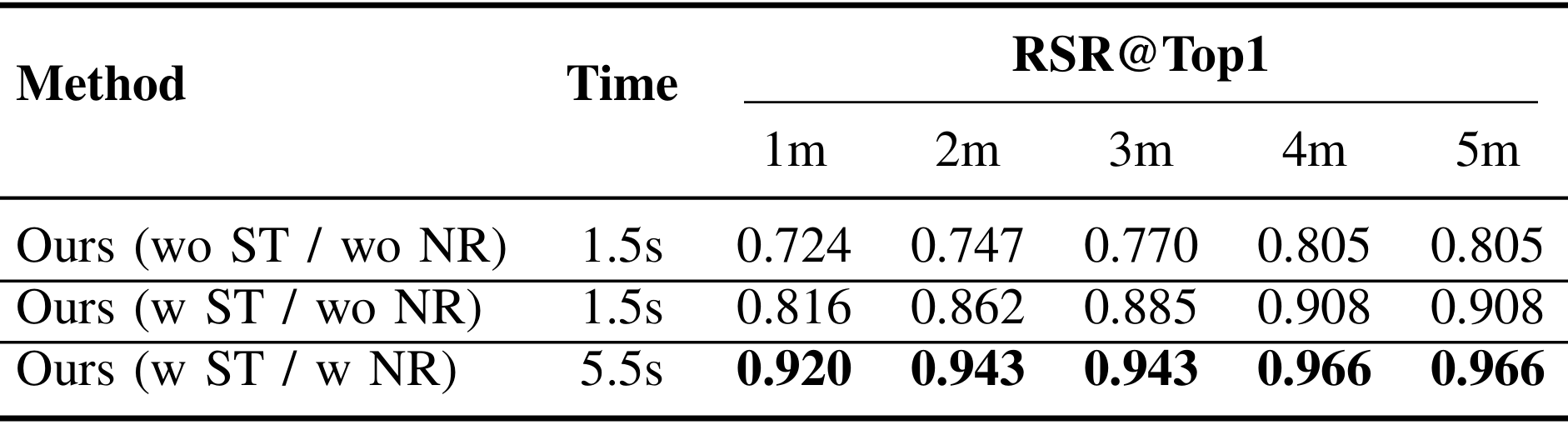
- 通过对比不同设置下的FSR-VLN性能,验证了空间指令和FSR过程的有效性。结果表明,空间目标(ST)指令通过将对象搜索限制在目标房间内,减少了全局匹配错误,提高了RSR。而导航推理(NR)则允许FSR验证快速匹配的正确性,并通过VLM驱动的选择细化进一步提高RSR。
结论与未来工作
- 结论:
- FSR-VLN通过将分层多模态场景图(HMSG)与快速到慢速导航推理(FSR)相结合,为具身智能体在真实世界长距离导航任务中提供了一种有效的解决方案。
- HMSG能够编码几何、语义和拓扑关系,支持FSR快速检索候选目标并进行细化,从而实现更鲁棒的导航。
- 实验结果表明,FSR-VLN在成功率方面优于现有的SOTA基线方法,即使在严格的房间空间约束下也能表现出色。
- 然而,FSR-VLN也存在一些局限性。HMSG的构建过程耗时较长,使其不适合实时制图,并且该方法假设环境是静态的,限制了其在动态环境中的适用性。
- 未来工作:
- 未来将致力于提高场景图构建的效率,增强系统对动态环境的鲁棒性,并整合探索性导航能力,以处理新环境或模糊指令下的导航任务。
