【自然语言处理与大模型】LlamaIndex快速入门①
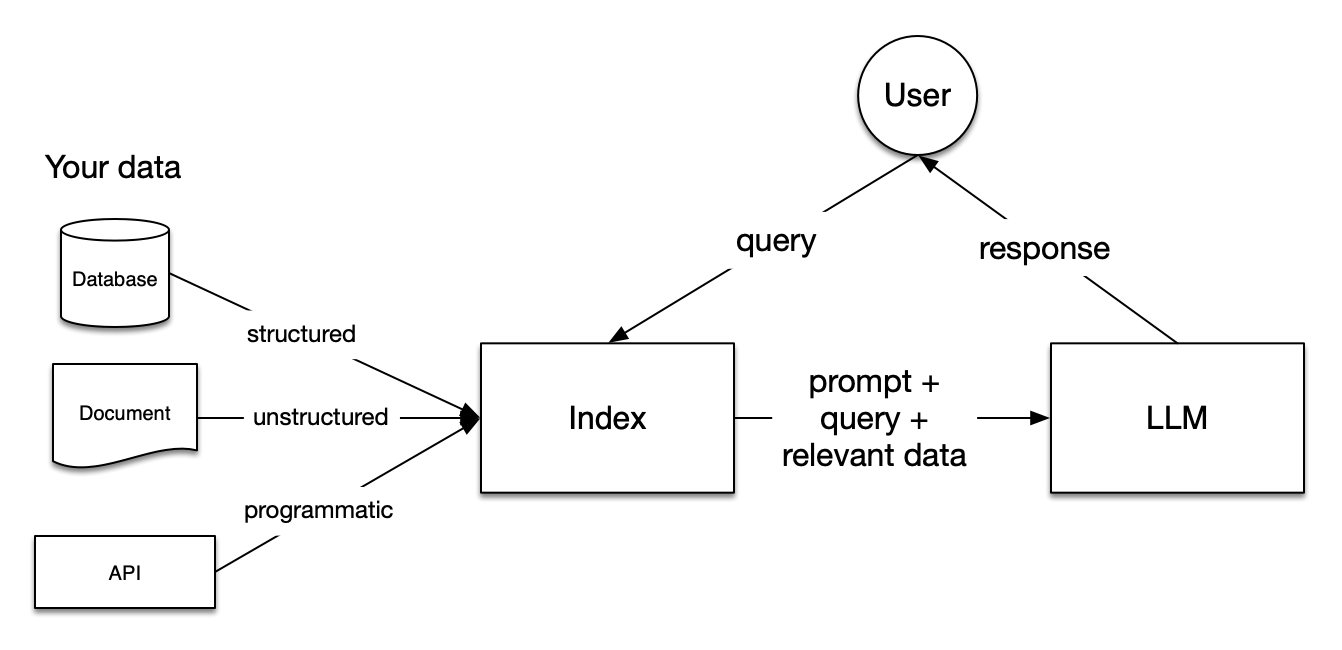
LlamaIndex是一个基于大型语言模型(LLM)的数据应用开发框架,专注于连接私有数据与LLM,实现高效的知识检索、问答及智能分析。它简化了从非结构化数据(如文档、网页)中提取、索引和利用信息的流程,帮助开发者快速构建具备领域知识的AI应用。
LlamaIndex 有 Python 和 Typescript 两个版本,Python 版的文档相对更完善。
Python 文档地址:https://docs.llamaindex.ai/en/stable/
Python API 接口文档:https://docs.llamaindex.ai/en/stable/api_reference/
TS 文档地址:https://ts.llamaindex.ai/
Github 链接:https://github.com/run-llama
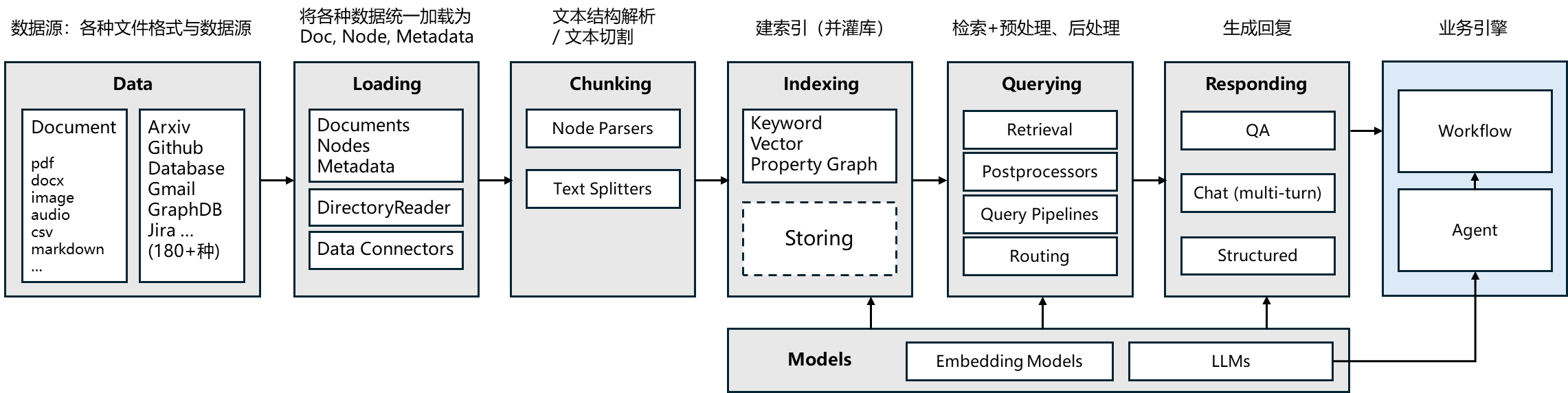
其核心模块包括:
- 数据连接器(Connectors),支持从多种数据源(PDF、数据库、API等)高效导入数据;
- 数据索引(Indices),通过向量索引、树结构等方式组织数据,提升检索效率;
- 查询引擎(Query Engines),将自然语言查询转化为数据检索逻辑,并结合LLM生成精准回答;
- 智能体(Agents),支持多步骤推理和工具调用,实现复杂任务自动化。这些模块协同工作,为LLM应用提供从数据处理到智能交互的全流程支持。
LlamaIndex四行代码实现一个简单的RAG
# pip install llama-index llama-index-llms-dashscope llama-index-embeddings-dashscopeimport os # 导入os模块,用于与操作系统进行交互,如获取环境变量
from llama_index.core import Settings # 从llama_index.core导入Settings类,用于配置全局设置
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels # 导入DashScope和DashScopeGenerationModels,用于接入DashScope的LLM服务
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels # 导入DashScopeEmbedding和DashScopeTextEmbeddingModels,用于接入DashScope的Embedding服务
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader # 导入VectorStoreIndex和SimpleDirectoryReader,用于创建索引和读取文档# 设置全局的LLM为DashScope的QWEN_MAX模型,使用环境变量中的API_KEY
Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))# 将LlamaIndex默认使用的Embedding模型替换为DashScope的TEXT_EMBEDDING_V1模型,同样使用环境变量中的API_KEY
Settings.embed_model = DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1,api_key=os.getenv("DASHSCOPE_API_KEY")
)# 读取"./data"目录下的文档数据
documents = SimpleDirectoryReader("./data").load_data()
# 使用读取的文档创建向量存储索引
index = VectorStoreIndex.from_documents(documents)
# 从索引创建查询引擎,用于执行查询
query_engine = index.as_query_engine()
# 使用查询引擎查询"deepseek v3有多少参数?"的问题
response = query_engine.query("deepseek v3有多少参数?")# 打印查询结果
print(response)