go资深之路笔记(六)坑点
一、 接口(Interface)的内部表示与 nil 的陷阱
interface的内部是有两部分构成,它是一个二元组 (动态类型, 动态值),这样就会出现一个问题,当他赋值一个 nil值时,有类型但是无值,这个接口就不是nil
代码:
func Test22(t *testing.T) {var a anyfmt.Println(a == nil) // true // a是的内部二元组是(nil, nil)var m map[string]intfmt.Println(m == nil) // truea = mfmt.Println(a == nil) // false, 因为 a是的内部二元组是(map[string]int, nil)
}
当 需要返回一个接口的时候,如果它本身的值是nil,那应该直接返回nil,而不是接口
func Resp() any {var res anyvar a map[string]int{}...res = a
// return res // 错误return nil //正确
}二、defer 参数传递
defer 函数 传递的是值时,不会受变量修改影响,而传递的是指针就会受变量修改影响。
package mainimport "fmt"func Print(p *int) {fmt.Println("Print value:", *p) // 解引用指针p
}func main() {x := 10xx := &x // xx是指向x的指针// 示例1:defer fmt.Println("Defer value:", *xx)defer fmt.Println("Defer value:", *xx) // 打印 10// 示例2:defer Print(xx)defer Print(xx) // 打印 20// 修改x的值(xx指向x,所以*xx会变化)x = 20
}
本质: defer 的运行机制本质上是 “声明时求值参数,退出时执行函数”
三、切片赋值问题
问题一:切片赋值是共享底层数组的,新切片修改值也会影响到初始切片
问题二:但是新切片触发扩容的话将不会是同一个切片
代码:
func TestSlice(t *testing.T) {s1 := []int{1, 2, 3}s2 := s1[:3] // s1 和 s2 共享底层数组 [1, 2, 3, 4, 5]fmt.Printf("%p,%p\n", &s1[0], &s2[0]) // // 指针一致s1[1] = 555fmt.Println(s1, s2) // [1 555 3] [1 555 3] 问题一:同步修改// s2 的容量足够追加,不会扩容,直接在原数组上修改s2 = append(s2, 100)fmt.Println(cap(s1), cap(s2))fmt.Printf("%p,%p\n", &s1[0], &s2[0]) // 问题二:指针不一致(扩容了)fmt.Println(s1, s2) // [1 555 3] [1 555 3,100]
}
执行结果:
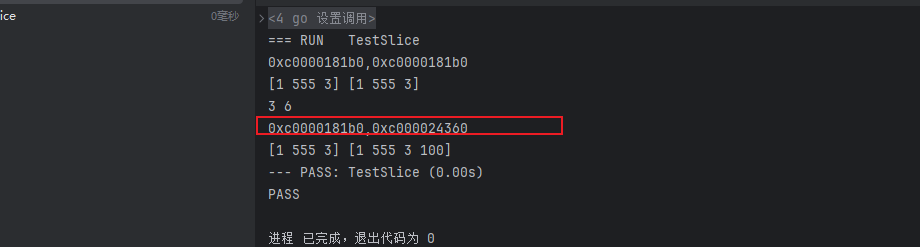
解决方法:
问题1:
// 使用 copy
s2 := make([]int, 3) // 新开辟内存空间,保证互不影响
copy(s2, s1[:3]) // 这里是值传递(ps:如果是 *int,那就要一个个取了)
问题2:
int n = 9999 // 预设一个足够的值,这个根据实际需求,定s1 := make([]int, n)...s2 := s1[:3]
对于问题2其实尽量不考虑新切片扩容还要保持一致的问题,既然是新切片那就应该是值传递的。那么说,其实问题1的方法也能解决问题2。
四、 slice 和map初始化
“引用”类型的变量定义后是nil, 对其操作会报错
var s []int // s== nil
var m map[int]int // m== nil
fmt.Println(s[0]) // panic 指针错误
fmt.Println(m[0])
通过make之后才开始分配内存空间
s := make([]int,3)
fmt.Println(s[0])
m := make(map[int]int)
fmt.Println(m[0])
但是有一点比较特殊的是, append对切片做了封装:
var s []int
s = append(s,10)
fmt.Println(s[0]) // 打印10
//大概原理是 append 会判断 s是否nil 然后给它初始化,它还有自动扩容的功能
// 不清楚这个原理的程序员,写 struct字段里有 切片和map的,有时就会疑惑,为什么同样切片没事,但是map有事。
五、嵌入重名
type A struct {Name string
}
type B struct {Name string
}
type C struct {AB
}func main() {c := C{}// c.Name = "name" // 编译错误:ambiguous selector c.Namefmt.Println(c.A.Name) // 必须显式指定嵌入类型的名字
}
其实c.Name的访问只是语法糖而已,如果没有重复的话,那就不需要指定嵌入类型。
六、字符串(string)与字节切片([]byte)的转换开销
str := "Hello World"
bytes := []byte(str) // 可能发生一次内存分配和复制
str2 := string(bytes) // 同样可能发生一次内存分配和复制
原因是他们底层结构不一样, string 相当于一个数组,不可变;切片容量可变
// string 的底层结构(reflect.StringHeader)
type StringHeader struct {Data uintptr // 第1个字段:指向字节数组的指针Len int // 第2个字段:长度(字节数)
}// []byte 的底层结构(reflect.SliceHeader)
type SliceHeader struct {Data uintptr // 第1个字段:指向字节数组的指针(与 StringHeader.Data 位置相同)Len int // 第2个字段:长度(与 StringHeader.Len 位置相同)Cap int // 第3个字段:容量(string 不需要这个字段)
}
其实一般业务代码怎么写是完全没有问题的,但是如果对性能要求特别可以采用类型转化的方式
import "unsafe"func StringToBytes(s string) []byte {return *(*[]byte)(unsafe.Pointer(&struct {stringint}{s, len(s)}))
}func BytesToString(b []byte) string {return *(*string)(unsafe.Pointer(&b))
}
// 警告:使用此方法后,绝对不能再修改原始的 []byte,否则会破坏 string 不可变的约定。(string底层是数组)
StringToBytes讲解:
unsafe.Pointer(&struct {stringint}{s, len(s)}
底层表示
struct.string = StringHeader(uintptr+int)
+struct.int
//相当于
SliceHeader = (uintptr+int+int)
所以这个结构体就满足 了转化成 SliceHeader 的结构。
BytesToString讲解
SliceHeader(uintptr+int+int)
// 转化成
StringHeader(uintptr+int)
//不需要做额外处理,已经满足了(uintptr+int) |多的cap int 弃用即可
七、方法接收者(Method Receiver)的选择
方法接收者一般都用指针,因为用值的话,他会拷贝一份,影响性能:
比如下面的代码两个指针的打印是不同的,就证明他们发生了深拷贝:
func Test000(t *testing.T) {a := A{Name: "lll"}fmt.Printf("%p\n", &a)a.print()
}type A struct {Name string
}func (a A) print() {println(a.Name)fmt.Printf("%p\n", &a)
}
原因: 因为方法接受者其实也是一个参数:
func (a A) print() {println(a.Name)fmt.Printf("%p\n", &a)
}
// 等价于
func print(a A){println(a.Name)fmt.Printf("%p\n", &a)
}
值传递一般用作:不修改原始数据的情况
其实指针传递也可以做到不修改原始值的情况,比如:
func (a *A) print() {a2 := *aa2.Name = "name" // 不影响原始值println(a.Name)fmt.Printf("%p\n", &a)
}
八、 time.After 可能导致的内存泄漏
time.After 一般只适用简单+单次的计时器使用,如果在循环中使用可能创建大量的 计时器,比如:
for {select {case <-time.After(5 * time.Minute): // 每次循环都创建一个新的 5min Timer!returncase <-someOtherChan:// do something}
}
为什么会创建大量的计时器:
- select 运行时就会执行 <-time.After 从而创建计时器
- <-time.After 没有取消功能,所以创建后必须到期才会销毁。
- for 会一直循环。
解决方法: 改成可复用的 time.NewTimer
// 正确的做法
timer := time.NewTimer(5 * time.Minute)
defer timer.Stop() // 确保Timer被停止,以便资源得以释放for {timer.Reset(5 * time.Minute) // 关键:在每次循环开始时重置Timerselect {case <-timer.C:returncase <-someOtherChan:// do something}
}
九、在关键函数上 defer recover
有时候创建很多子协程工作,某个子协程崩溃会导致所有协程都结束工作(传到主协程,然后终止自身和所有子协程),如果只是加打印未必能看出问题来, 因为有可能你在a协程打印出一半的内容,b协程panic了然后全部挂掉了。最好的做法就是,给关键函数加上 defer recover,然后再排查问题。之后在对容易panic的函数加 defer recover,比如:
func checkPanic(){ // 封装处理 recover的容器。if err := recover(); r!=nil{...}
}func main(){defer checkPanic()...
}
十、 切片作为函数参数时,len和cap的传递语义
直接看代码
func appendToSlice(s []int) {s = append(s, 100) // 这里可能修改 s 的底层数组,但外部的 s1 的 len 不会改变s[0] = 999 // 这个修改会影响底层数组,外部能看到
}func main() {s1 := make([]int, 1, 5) // len=1, cap=5s1[0] = 1appendToSlice(s1)fmt.Println(s1) // 输出: [999],而不是 [999, 100]// s1 的 len 仍然是 1,因为函数内对切片头部的修改是局部的
}
底层原理:
切片实际上就是三个字段组成的结构体,
type SliceHeader struct {Data uintptr // 值传递的时候Data 的值不变,指向同一块内存,所以可以做到同步修改.Len int // 这个值不是指针,所以分出来的切片不共享 lenCap int // 同上
}
解决方法:
// 方法一: 返回切片
func appendToSliceFixed(s []int) []int {return append(s, 100) // 返回新的切片头部
}
// 方法二: 切片指针
func aa(s *[]int) {*s = append(*s, 100) // 返回新的切片头部
}
十一: 使用 sync.Map 的适用场景误区
陷阱:sync.Map 并不是 map 的并发安全替代品。它针对特定场景优化:读多写少,且 key 相对稳定。在错误的场景下使用,性能可能比 map + sync.RWMutex 更差。
适用场景对比:
sync.Map 适用:大量并发读,写操作很少(如缓存预热后很少更新,常见配置)
map + sync.RWMutex 适用:读写操作相对均衡,或者需要复杂的原子操作
ps: 以上两种都是并发安全的, 而 map本身不是并发安全,如果有并发操作 map 可能会引发panic
十二: 编译器优化导致的基准测试(Benchmark)误差
陷阱:Go 编译器非常激进,如果基准测试编写不当,编译器可能会优化掉你想要测试的代码,导致结果严重失真。
// 错误的基准测试:结果会严重失真
func BenchmarkSum(b *testing.B) {numbers := make([]int, 1000)for i := range numbers {numbers[i] = i}b.ResetTimer()for i := 0; i < b.N; i++ {sum := 0for _, n := range numbers {sum += n // 编译器可能发现 sum 未被使用,直接优化掉整个循环!}}
}// 正确的基准测试:阻止编译器优化
func BenchmarkSumFixed(b *testing.B) {numbers := make([]int, 1000)for i := range numbers {numbers[i] = i}b.ResetTimer()for i := 0; i < b.N; i++ {sum := 0for _, n := range numbers {sum += n}// 阻止优化:将结果赋值给包级变量或调用 runtime.KeepAliveruntime.KeepAlive(sum)}
}
十三: 字符串长度与字节长度的区别
陷阱:len() 函数对字符串返回的是字节数,不是字符数(对于Unicode字符)。
s := "Hello, 世界"
fmt.Println("Bytes:", len(s)) // 输出: 13 (UTF-8编码的字节数)
fmt.Println("Runes:", utf8.RuneCountInString(s)) // 输出: 9 (实际字符数)// 遍历字符串时的陷阱
for i := 0; i < len(s); i++ {fmt.Printf("%c ", s[i]) // 错误:按字节遍历,会输出乱码
}
// 正确遍历方式
for _, r := range s {fmt.Printf("%c ", r) // 按rune遍历
}
十四: 初始化循环
陷阱:包级变量的初始化顺序可能导致循环依赖,编译期无法检测,运行时panic。
var a = b + 1
var b = a + 1 // 运行时panic: initialization cycle// 更隐蔽的版本
var config = loadConfig()
func loadConfig() Config {return Config{Timeout: config.Timeout} // 间接循环引用
}
原理解析:
这两个变量声明初始化过程:
var a = b + 1
var b = a + 1
- 声明 变量 a,b 并分配内存 a=0,b=0
- 初始化a = b+1,这个时候b没有初始化(注意有默认值!=初始化),先判断a依赖b
- 初始化b = a+1,这个时候a没有初始化,检查 a,b循环依赖,panic!
config 同理
解决方法:
使用init
var a,b int // 这个时候已经用默认值初始化了
func init(){a = b + 1b = a + 1
}
关于类型确定:
声明阶段,哪怕是存在循环依赖,但是知道 a,b互相依赖肯定是同一类型,会自动推导为默认类型 int
十五:接口比较的隐式Panic
陷阱: 比较两个接口值时,如果它们的动态类型不可比较(如slice、map、function),会引发运行时panic。
var x interface{} = []int{1, 2, 3}
var y interface{} = []int{1, 2, 3}
fmt.Println(x == y) // panic: runtime error: comparing uncomparable type []int
如果去掉 interface{} 编译阶段过不了,而有接口的话比较隐晦看不出来。
slice、map、function 是不可比较类型,任何包含这个三个类型的变量都不可比较
十六、comma-ok语法判断
比如:从已关闭的通道读取不会阻塞,而是立即返回零值,需要用comma-ok语法判断通道是否关闭。
ch := make(chan int, 2)
ch <- 1
ch <- 2
close(ch)for i := 0; i < 3; i++ {value, ok := <-chif !ok {fmt.Println("Channel closed!")break}fmt.Println("Received:", value)
}
// 输出:
// Received: 1
// Received: 2
// Channel closed!
除了读取通道外,还有:
- 类型断言
- map读取
- switch v := i.(type) { 这里是隐形comma-ok 断言
十七、方法值(Method Value)的延迟绑定
陷阱:方法值在创建时就绑定了接收者,后续对原变量的修改不会影响已创建的方法值。
type Counter struct{ count int }
func (c *Counter) Inc() { c.count++ }c1 := &Counter{count: 1}
c2 := &Counter{count: 2}method := c1.Inc // 绑定到c1
c1 = c2 // 改变c1的指向method() // 仍然影响原来的c1指向的对象?不,影响的是创建时绑定的对象
fmt.Println(c2.count) // 输出: 2 (未改变)
扩展:方法 method 的底层原理
当执行 method := c1.Inc 时,编译器会生成一个闭包结构体,用于存储:
原方法的函数指针(即上述 Inc 函数的地址)
绑定的接收者实例(c1 的指针)
伪代码:
// 编译器生成的闭包结构体(伪代码)
type methodValue struct {fn func(*Counter) // 原方法的函数指针(Inc)recv *Counter // 绑定的接收者(c1)
}
method()相当于:
// 调用 method() 时,编译器实际执行的逻辑(伪代码)
methodValue.fn(methodValue.recv) // 即 Inc(c1),也就是 c1.Inc()
方法值的底层实现本质是通过闭包 “捕获” 接收者,从而实现:
简化调用:调用时无需显式传递接收者(已绑定)
函数化传递:让方法可以像普通函数一样作为参数传递(例如作为回调函数)
十八:切片扩容的容量策略不确定性
陷阱:切片扩容时的新容量取决于当前容量和追加的元素数量,不同Go版本策略可能不同。
func testSlice(){s := make([]int, 1023, 1024)fmt.Println("Before:", len(s), cap(s)) // 2, 3s = append(s, 1, 2) // 需要扩容fmt.Println("After:", len(s), cap(s)) // 1025,cap可能等于1536(1.5),也可能等于 1280(1.25),或者2048(2)
}
所以代码里面千万不要根据具体扩容值来写代码,不然版本改变可能有意想不到的bug
扩容倍数历史:
1.5 扩容两倍
1.6-1.17 : <=1024 两倍>1024 1.25倍
1.18+继承 1.6做内存对齐优化
1.20+继承 1.18采取更平缓的扩容曲线
十九: 零值(Zero Value)的合理使用与误用
陷阱:Go的零值机制很实用,但有时会导致意外的行为。
type Config struct {Timeout time.DurationRetries int
}func main() {var cfg Config// cfg.Timeout是0,表示无限等待?这可能不是想要的行为if cfg.Timeout == 0 {cfg.Timeout = time.Second * 30 // 需要显式设置默认值}
// 或者if cfg.Timeout == 0 {
// ... 无限等待逻辑}
}
总结:就是对于默认零值要做特殊处理,避免直接使用的习惯。
二十: 位运算的优先级陷阱
陷阱:位运算符的优先级不同于其他语言,容易写错复杂的表达式。
// 常见的错误
x := 1 | 2 == 3 // 等价于 1 | (2 == 3),结果是 1 | false = 1
y := (1 | 2) == 3 // 正确写法,结果是 truefmt.Println(x, y) // 输出: 1 true
解决方案:不确定时多用括号。
二十一:类型断言的性能与安全
陷阱:类型断言在失败时有两种行为,选择不当会影响性能或安全性。
var i interface{} = "hello"// 方式1:安全但性能稍差(需要返回bool)
if s, ok := i.(string); ok {fmt.Println(s)
}// 方式2:不安全但简洁(失败时panic)
s := i.(string)
fmt.Println(s)// 方式3:type switch,处理多种类型
switch v := i.(type) { // 这里采用隐形 comma-ok语法判断,不会panic.
case string:fmt.Println("string:", v)
case int:fmt.Println("int:", v)
default: //断言失败fmt.Println("unknown")
}
二十一:函数参数求值顺序的不确定性
陷阱:函数参数的求值顺序在Go语言规范中是未定义的,不同编译器可能不同。
func Test000(t *testing.T) {i := 0printValues(i, i+1) //这里绝对是0,1(不管哪个表达式先求值都一样,因为i不变)// 但如果是函数调用:printValues(getValue(), getValue()) // 两个getValue()的调用顺序不确定 结果可能是2,3 也可能是3,2
}
func printValues(a, b int) {fmt.Println(a, b)
}func getValue() int {a++return a
}为什么参数表达式的计算顺序不一致:
Go 允许编译器自由选择参数求值顺序,主要是为了优化编译效率。编译器可以根据上下文选择最高效的求值顺序(如利用 CPU 缓存、减少临时变量等),无需严格遵守从左到右的顺序。
func Test000(t *testing.T) {i := 0printValues(i, i+1) //这里绝对是0,1(不管哪个表达式先求值都一样,因为i不变)// 但如果是函数调用:a:= getValue()b:= getValue()printValues(a,b)
}
二十二:递归类型的定义限制
陷阱:在定义递归类型时,不能直接包含自身,必须通过指针间接引用。
// 错误定义
type TreeNode struct {Value intChildren []TreeNode // 编译错误:invalid recursive type TreeNode
}// 正确定义
type TreeNode struct {Value intChildren []*TreeNode // 通过指针间接引用
}
原因:值类型嵌套不好确定内存布局
所以一半都是 用指针类型
常见场景:
- 链表
- 树
- 图
- JSON/XML 解析模型
二十三: 浮点数的精度与比较问题
陷阱:浮点数有精度限制,直接比较可能得到意外结果。
解决方法:使用误差范围
a := 0.1
b := 0.2
c := 0.3fmt.Println(a+b == c) // 输出: false!
fmt.Println(a + b) // 输出: 0.30000000000000004// 正确比较方式
fmt.Println(math.Abs((a+b)-c) < 1e-9) // 使用误差范围
**扩展:**如果需要完全精确可以使用高精度十进制库(适合严格精度场景)
安装依赖 decimal
go install github.com/shopspring/decimal
示例代码:
package mainimport ("fmt""github.com/shopspring/decimal"
)func main() {a, _ := decimal.NewFromString("0.1")b, _ := decimal.NewFromString("0.2")c, _ := decimal.NewFromString("0.3")sum := a.Add(b)fmt.Println(sum.Equal(c)) // 输出 true(精确计算)
}
源码浅析:
type Decimal struct {value *big.Int // 整数部分//注意(vadim):这必须是一个int32,因为我们在计算过程中将其转换为float64。如果exp是64位,我们可能会失去精度。如果我们关心能够表示每一个可能的小数,我们可以使exp a*big.Int,但这会损害性能,这样的数字是不切实际的。exp int32 //小数部分
}
原理就是 value 是整数部分,exp是小数部分计算的时候变成 float32计算值
二十四:标签(Struct Tags)的解析规则
陷阱:结构体标签的解析有严格的语法规则,微小的格式错误会导致标签被忽略。
type User struct {Name string `json: "name"` // 错误!冒号后不能有空格Age int `json:"age"` // 正确City string `json:"city,omitempty"` // 正确:带选项
}// 反射读取标签
t := reflect.TypeOf(User{})
field, _ := t.FieldByName("Name")
fmt.Println(field.Tag.Get("json")) // 输出空字符串(因为标签解析失败)
扩展:tag标签可以自定义,但是约定成俗的规矩是 grom 用 grom:column, 序列化用json
二十五:运行时类型识别(RTTI)的性能代价
陷阱:过度使用反射或类型断言会影响性能,特别是在热点代码路径中。
// 反射的性能代价
func usingReflection(v interface{}) {rv := reflect.ValueOf(v)if rv.Kind() == reflect.String {s := rv.String() // 反射操作比直接调用慢10-100倍}
}// 类型断言的性能代价(相对较小,但仍需注意)
func usingAssertion(v interface{}) {if s, ok := v.(string); ok {_ = s // 类型断言有开销,但比反射小得多}
}
优化策略:在性能敏感处避免反射,使用代码生成或具体类型。
代码生成:比如 protobuf的grpc生成代码,虽然代码很多,但是运行很快。属于空间换时间(这点空间微不足道,但是时间很重要)