Stanford CS336 assignment1(上)
文章目录
- 介绍
- Byte-Pair Encoding (BPE) Tokenizer
- The Unicode Standard
- BPE算法示例说明
- 语料库文本
- 词汇表初始化
- 预分词
- 合并过程
- 第一轮合并
- 第二轮合并
- 后续合并
- 合并6次后的词汇表
- BPE 编码示例
- 输入与参数
- 编码过程
- 1. 预分词
- 2. 处理第一个预分词单元 'the'
- 3. 处理第二个预分词单元 ' cat'
- 4. 处理第三个预分词单元 ' ate'
- 最终编码结果
- 实现Tokenizer类
- 线性模型
- Transformer的嵌入层
- 前归一化
- RMS Layer Normalization
- SwiGLU
- RoPE旋转编码
- Softmax
- SDPA
- 多头自注意力
源仓库链接:https://github.com/stanford-cs336/assignment1-basics
介绍

Byte-Pair Encoding (BPE) Tokenizer
The Unicode Standard

(a)
>>> chr(0)
'\x00'
(b)
_repr_ (字符串表示):目标是明确和无歧义。它的主要受众是开发者,用于调试和日志记录。理想情况下,它应该返回一个字符串,让你能通过这个字符串重新创建出这个对象。
_str_ (打印表示):目标是可读性好。它的主要受众是最终用户。当你使用 print(obj) 或 str(obj) 时,调用的是这个方法,它应该返回一个对用户友好、易于理解的字符串。
(c)
>>> chr(0)
'\x00'
>>> print(chr(0))>>> "this is a test" + chr(0) + "string"
'this is a test\x00string'
>>> print("this is a test" + chr(0) + "string")
this is a teststring

(a)
UTF-8 是可变长度编码,对于 ASCII 字符(如英文字母、数字、常见符号)只使用 1 个字节,这些字符在大多数文本中占比较高。这使得 UTF-8 编码的文本通常更小,减少了存储和传输开销,从而提高了 tokenizer 训练的效率。
UTF-16 对于基本多文种平面(BMP)中的字符使用 2 字节,对于辅助平面中的字符使用 4 字节(通过代理对)。对于英文文本,UTF-16 通常比 UTF-8 大,因为 ASCII 字符在 UTF-16 中也需要 2 字节。
UTF-32 始终使用 4 字节 per character,这非常浪费空间。例如,ASCII 文本在 UTF-32 中会变大 4 倍,导致处理速度慢和存储成本高。
(b)
函数是错的,因为它试图逐个字节解码UTF-8字节串。但UTF-8是一种可变长度编码,一个字符可能由多个字节组成。如果逐个字节解码,那些多字节字符会被错误地解码成多个单独的字符,而不是一个正确的Unicode字符。
输入“中”字,其UTF-8编码是b'\xe4\xb8\xad'
函数会将其解析为0xe4, 0xb8, 0xad
报错输出:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe4 in position 0: unexpected end of data
(c)
一个两字节序列的例子是 0xD8 0x00(UTF-16 大端序),它解码为高代理码点 U+D800,该码点在没有对应低代理码位的情况下是无效的,不代表任何 Unicode 字符。
BPE算法示例说明
以下内容基于Sennrich等人[2016]的论文中的一个简化示例,说明Byte Pair Encoding(BPE)算法的工作过程。
语料库文本
假设语料库由以下文本组成:
low low low low low
lower lower widest widest widest
newest newest newest newest newest newest
此外,词汇表包含一个特殊标记<|endoftext|>。
词汇表初始化
词汇表初始时包含特殊标记<|endoftext|>和256个字节值(即所有可能的字节字符)。
预分词
为简化起见,预分词过程仅基于空格进行分割。分割后,我们得到以下单词频率表:
low:出现5次lower:出现2次widest:出现3次newest:出现6次
在Python中,这些单词被表示为字节元组(每个字节是一个bytes对象)。例如:
low表示为(l, o, w)lower表示为(l, o, w, e, r)widest表示为(w, i, d, e, s, t)newest表示为(n, e, w, e, s, t)
合并过程
BPE算法通过迭代合并最常见字节对来构建词汇表。
第一轮合并
首先,统计所有相邻字节对的频率(基于单词频率):
lo:7(出现在low和lower中)ow:7(出现在low和lower中)we:8(出现在widest和newest中)er:2(出现在lower中)wi:3(出现在widest中)id:3(出现在widest中)de:3(出现在widest中)es:9(出现在widest和newest中)st:9(出现在widest和newest中)ne:6(出现在newest中)ew:6(出现在newest中)
频率最高的对是es和st,频率均为9。由于平局,选择字典序较大的对,即st(因为s在字母表中位于e之后)。因此,合并st为单个单元。
合并后,单词表示为:
(l, o, w):5次(l, o, w, e, r):2次(w, i, d, e, st):3次(st被合并)(n, e, w, e, st):6次(st被合并)
第二轮合并
现在,统计新的字节对频率。注意,e和st现在相邻,对e st的频率为9(出现在widest和newest中),是最常见的对。因此,合并e st为est。
合并后,单词表示为:
(l, o, w):5次(l, o, w, e, r):2次(w, i, d, est):3次(est被合并)(n, e, w, est):6次(est被合并)
后续合并
继续此过程,最终的合并序列为:
- 合并
s t为st - 合并
e st为est - 合并
o w为ow - 合并
l ow为low - 合并
w est为west - 合并
n e为ne - 合并
ne west为newest(但注意,在合并过程中,步骤可能不同) - 合并
w i为wi - 合并
wi d为wid - 合并
wid est为widest - 合并
low e为lowe - 合并
lowe r为lower
合并6次后的词汇表
如果只进行6次合并,合并序列为:['s t', 'e st', 'o w', 'l ow', 'w est', 'n e']。此时,词汇表包含:
- 特殊标记
<|endoftext|> - 256个字节字符
- 合并后的单元:
st,est,ow,low,west,ne
使用此词汇表和合并规则,单词newest会被分词为[ne, west]。
此示例展示了BPE如何通过迭代合并常见字节对来构建子词词汇表。

我们需要实现的是一个这样的函数train_bpe
vocab, merges = train_bpe(input_path, vocab_size, special_tokens)
然后给他写进adpaters.py去做测试
参考了网上的几个大神的作业
tokenizer.py
from typing import Dict, Tuple, List, Iterable, Iterator
from collections import Counter
import regex as refrom queue import Empty
from multiprocessing import Process, Queue, Managerfrom tqdm import trange, tqdm
import pickleimport os from cs336_basics.tokenizer.pretokenization_regular_pattern import PAT
from cs336_basics.tokenizer.utils import find_chunk_boundaries def initialize_vocab(special_tokens: List[bytes]) -> Dict[int, bytes]:vocab = {i: bytes([i]) for i in range(256)} # ASCII charactersfor i, token in enumerate(special_tokens, start=256):vocab[i] = tokenreturn vocabdef word_to_bytes(word: str) -> List[bytes]:"""Convert a word to bytes."""byte_ids = [bytes([b]) for b in word.encode("utf-8")]return byte_idsdef split_by_special_tokens(text: str, special_tokens: list[str]
) -> List[str]:special_tokens_sorted = sorted(special_tokens, key=len, reverse=True)if not special_tokens_sorted:return [text]pattern = "|".join(re.escape(t) for t in special_tokens_sorted)special_chunks = re.split(f"({pattern})", text)return special_chunksdef pre_tokenize_string(text: str, special_tokens: List[str], include_special: bool = False) -> Counter:word_counter = Counter()special_chunks = split_by_special_tokens(text, special_tokens)for chunk in special_chunks:if chunk in special_tokens:if include_special:token = tuple(word_to_bytes(chunk))word_counter[token] += 1else:for match in re.finditer(PAT, chunk):word = match.group(0)token = tuple(word_to_bytes(word))word_counter[token] += 1return word_counter# TODO: Implement the worker for this.
def pre_tokenize_string_worker(input_path: str | os.PathLike, special_tokens: list[str], queue: Queue, start: int, end: int, include_special: bool = False,
):"""Pre-tokenize a string into bytes."""with open(input_path, "rb") as f:f.seek(start)chunk = f.read(end - start).decode("utf-8", errors="ignore")word_counter = pre_tokenize_string(chunk, special_tokens, include_special)# Put the result in the queuequeue.put(word_counter)def pair_counts(word_counter: Dict[Tuple[bytes], int],
) -> Dict[Tuple[bytes, bytes], int]:"""Count pairs of bytes in the word counter."""pairs: Dict[Tuple[bytes, bytes], int] = {}for token, freq in word_counter.items():for i in range(len(token) - 1):pair = (token[i], token[i + 1])pairs[pair] = pairs.get(pair, 0) + freqreturn pairsdef get_most_frequent_pair(pairs: Dict[Tuple[bytes, bytes], int],
) -> Tuple[bytes, bytes]:max_freq = max(pairs.values())candidates = [pair for pair, freq in pairs.items() if freq == max_freq]res = max(candidates)return resdef add_pair_to_vocab(vocab: Dict[int, bytes], pair: Tuple[bytes, bytes], vocab_inv: Dict[bytes, int]
) -> int:"""Add a new pair to the vocabulary."""index = len(vocab)s = vocab[vocab_inv[pair[0]]] + vocab[vocab_inv[pair[1]]]vocab[index] = svocab_inv[vocab[index]] = indexreturn indexfrom collections import Counter, defaultdictdef merge_pair(word_counter: Dict[Tuple[bytes], int], pair: Tuple[bytes, bytes]
) -> Tuple[Dict[Tuple[bytes], int], Dict]:"""Merge a pair of bytes in the word counter."""new_word_counter = Counter()updated_pair_counts = defaultdict(int)for token, freq in word_counter.items():new_token = []i = 0while i < len(token):if i < len(token) - 1 and (token[i], token[i + 1]) == pair:new_token.append(token[i] + token[i + 1])i += 2else:new_token.append(token[i])i += 1new_word_counter[tuple(new_token)] += freqfor j in range(len(new_token) - 1):new_pair = (new_token[j], new_token[j + 1])updated_pair_counts[new_pair] += freqreturn new_word_counter, updated_pair_countsdef check_and_convert_special_tokens(special_tokens: List[str] | List[bytes],
) -> List[bytes]:"""Check if special tokens are in the vocabulary and convert them to bytes."""if not all(isinstance(token, bytes) for token in special_tokens):special_tokens_bytes = [token.encode("utf-8") for token in special_tokens if isinstance(token, str)]return special_tokens_bytesdef train_bpe(input_path: str | os.PathLike ,vocab_size=10_000,special_tokens: List[str] = [],**kwargs,
):special_tokens_bytes = check_and_convert_special_tokens(special_tokens)vocab = initialize_vocab(special_tokens_bytes)vocab_inv = {v: k for k, v in vocab.items()}merges: List[Tuple[bytes, bytes]] = []# Pre-tokenizationwith open(input_path, "rb") as f:chunk_boundaries = find_chunk_boundaries(f, kwargs.get("num_processes", 8), special_tokens_bytes[0])manager = Manager()queue = manager.Queue()processes = []for start, end in zip(chunk_boundaries[:-1], chunk_boundaries[1:]):p = Process(target=pre_tokenize_string_worker,args=(input_path, special_tokens, queue, start, end, False),)processes.append(p)p.start()for p in processes:p.join()word_counter = Counter()for _ in range(len(processes)):try:word_counter += queue.get(timeout=10) # Wait up to 10 seconds for resultsexcept Empty:print("⚠️ Warning: A subprocess did not return a result!")# End Pre-tokenizationpairs_freqs = pair_counts(word_counter)num_merges = vocab_size - len(vocab)for _ in trange(num_merges):most_common_pair = get_most_frequent_pair(pairs_freqs)new_index = add_pair_to_vocab(vocab, most_common_pair, vocab_inv)merges.append(most_common_pair)word_counter, pairs_freqs = merge_pair(word_counter, most_common_pair)return vocab, mergesclass Tokenizer:def __init__(self, vocab: Dict[int, bytes], merges: List[Tuple[bytes, bytes]],special_tokens: List[str] | None = []):self.vocab = vocabself.merges = merges# self.register_special_tokens(special_tokens)self.vocab_inv = {v: k for k, v in self.vocab.items()}if special_tokens is None:self.special_tokens = {}self.bytes_special_tokens = []else:self.special_tokens = {token: i for i, token in enumerate(special_tokens, start=len(self.vocab))}self.bytes_special_tokens = [token.encode("utf-8") for token in special_tokens if isinstance(token, str)]def register_special_tokens(self, special_tokens):if special_tokens is None:self.special_tokens = {}self.bytes_special_tokens = []returnif not all(isinstance(token, bytes) for token in special_tokens):bytes_special_tokens = [token.encode("utf-8") for token in special_tokens if isinstance(token, str)]for i, token in enumerate(bytes_special_tokens, start=len(self.vocab)):# Add special tokens to the vocabularyself.vocab[i] = token# self.bytes_special_tokens = bytes_special_tokens# self.special_tokens = {token: i for i, token in enumerate(special_tokens, start=len(self.vocab))}def _pre_tokenize(self, text) -> List[bytes]:"""Pre-tokenize the input text into bytes."""parts = split_by_special_tokens(text, list(self.special_tokens.keys()))token_list = []for part in parts:if part in self.special_tokens.keys():token_list.append(part.encode("utf-8"))else:tokens = re.findall(PAT, part)token_list.extend(word_to_bytes(token) for token in tokens)return token_listdef encode(self, text: str) -> List[int]:byte_tokens = self._pre_tokenize(text)# Convert byte tokens to indicestoken_ids = []for byte_token in byte_tokens:# print(f"Processing byte token: {byte_token}")if byte_token in self.bytes_special_tokens:token_ids.append([self.vocab_inv[byte_token]])else:token_ids.append([self.vocab_inv[b] for b in byte_token]) #type: ignorefor i, pretoken in enumerate(token_ids):for merge in self.merges:new_index = self.vocab_inv.get(merge[0] + merge[1], None)if new_index is None:continuemerged = []j = 0while j < len(pretoken):if (j < len(pretoken) - 1and (self.vocab[pretoken[j]], self.vocab[pretoken[j + 1]]) == merge):merged.append(new_index)j += 2else:merged.append(pretoken[j])j += 1pretoken = mergedtoken_ids[i] = pretoken[:]return [i for pre in token_ids for i in pre]def encode_iterable(self, iterable: Iterable[str], batch_size: int = 1024) -> Iterator[int]:"""Encode lines of text from an iterable using buffered batching.This version preserves newlines by assuming the input was split with `splitlines(keepends=True)`."""batch = []for line in tqdm(iterable):if not line:continuebatch.append(line)if len(batch) >= batch_size:for encoded in map(self.encode, batch):yield from encodedbatch.clear()if batch:for encoded in map(self.encode, batch):yield from encodeddef decode(self, ids: list[int]) -> str:# https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_charactertokens = b"".join(self.vocab.get(i, b"\xef\xbf\xbd") for i in ids)return tokens.decode("utf-8", errors="replace")@classmethoddef from_files(cls, vocab_path: str, merges_path: str, special_tokens: list[str] | None = None):with open(vocab_path, 'rb') as vf:raw_vocab = pickle.load(vf)vocab = {int(k): (v.encode("utf-8") if isinstance(v, str) else v)for k, v in raw_vocab.items()}with open(merges_path, 'rb') as mf:raw_merges = pickle.load(mf)merges = []for a, b in raw_merges:merges.append((a.encode("utf-8") if isinstance(a, str) else a,b.encode("utf-8") if isinstance(b, str) else b))return cls(vocab, merges, special_tokens)
初始化与辅助函数:
initialize_vocab: 初始化基础词汇表(256个ASCII字符 + 特殊令牌)。
word_to_bytes: 将字符串转换为UTF-8字节序列。
split_by_special_tokens: 用正则表达式按特殊令牌分割文本。
pre_tokenize_string: 将文本按规则预分词(使用正则模式PAT,用于把输入的内容和标点符号分割成有意义的部分)并统计词频。
多进程处理:
pre_tokenize_string_worker: 多进程 worker 函数,处理文件块并统计词频。
使用multiprocessing.Queue收集结果,tqdm显示进度条。
BPE的核心函数:
pair_counts: 统计相邻字节对的频率。
get_most_frequent_pair: 找到最高频的字节对。
merge_pair: 合并字节对并更新词频统计。
add_pair_to_vocab: 将新合并的令牌加入词汇表。
训练入口:train_bpe:
- 使用多进程预分词文本文件。
- 迭代合并最高频字节对,直到词汇表达到指定大小(vocab_size)。
- 返回词汇表(vocab)和合并词(merges)。
示例:
string = """
low low low low low <|endoftext|>
lower lower widest widest widest <|endoftext|>
newest newest newest newest newest newest
"""
special_tokens = ["<|endoftext|>"]
PAT = r"\S+"
vocab, merge = train_bpe(vocab_size=269)
merge
[(b's', b't'),(b'e', b'st'),(b'o', b'w'),(b'l', b'ow'),(b'w', b'est'),(b'n', b'e'),(b'ne', b'west'),(b'w', b'i'),(b'wi', b'd'),(b'wid', b'est'),(b'low', b'e'),(b'lowe', b'r')]
BPE 编码示例
输入与参数
- 输入字符串:
'the cat ate' - 词汇表:
{0: b' ', # 空格1: b'a', # 字母 a2: b'c', # 字母 c3: b'e', # 字母 e4: b'h', # 字母 h5: b't', # 字母 t6: b'th', # 序列 th7: b' c', # 空格+c8: b' a', # 空格+a9: b'the', # 单词 the10: b'at' # 序列 at } - 合并规则:
[(b't', b'h'), # t 与 h 合并为 th(b' ', b'c'), # 空格与 c 合并为 c(b' ', b'a'), # 空格与 a 合并为 a(b'th', b'e'), # th 与 e 合并为 the(b' a', b't') # a 与 t 合并为 at ]
编码过程
1. 预分词
输入字符串通过预分词器分割为:[‘the’, ’ cat’, ’ ate’]
2. 处理第一个预分词单元 ‘the’
- 初始字节表示:
[b't', b'h', b'e'] - 应用合并规则:
- 匹配
(b't', b'h')→ 合并为[b'th', b'e'] - 匹配
(b'th', b'e')→ 合并为[b'the']
- 匹配
- 无更多可应用规则,最终对应整数:
[9]
3. 处理第二个预分词单元 ’ cat’
- 初始字节表示:
[b' ', b'c', b'a', b't'](注意空格保留) - 应用合并规则:
- 匹配
(b' ', b'c')→ 合并为[b' c', b'a', b't'] - 无其他可应用规则(需严格匹配连续字节对)
- 匹配
- 最终对应整数序列:
[7, 1, 5](即b' c'、b'a'、b't')
4. 处理第三个预分词单元 ’ ate’
- 初始字节表示:
[b' ', b'a', b't', b'e'] - 应用合并规则:
- 匹配
(b' ', b'a')→ 合并为[b' a', b't', b'e'] - 匹配
(b' a', b't')→ 合并为[b' at', b'e'](注意:此处规则中的b' a'是空格+a的合并结果)
- 匹配
- 无更多可应用规则,最终对应整数序列:
[10, 3](即b' at'和b'e')
最终编码结果
整数序列为:[9, 7, 1, 5, 10, 3]
实现Tokenizer类

class Tokenizer:def __init__(self, vocab: Dict[int, bytes], # 词汇表字典,将整数ID映射到字节tokenmerges: List[Tuple[bytes, bytes]], # BPE合并规则列表,每个元组表示要合并的两个字节序列special_tokens: List[str] | None = [] # 特殊token列表(如[CLS]、[SEP]等)):self.vocab = vocab # 存储词汇表self.merges = merges # 存储合并规则# 创建反向词汇表,用于从字节token查找对应的整数IDself.vocab_inv = {v: k for k, v in self.vocab.items()}# 处理特殊tokenif special_tokens is None:self.special_tokens = {} # 特殊token字典(token到ID的映射)self.bytes_special_tokens = [] # 特殊token的字节表示列表else:# 为特殊token分配ID(从当前词汇表长度开始)self.special_tokens = {token: i for i, token in enumerate(special_tokens, start=len(self.vocab))}# 将特殊token转换为字节表示self.bytes_special_tokens = [token.encode("utf-8") for token in special_tokens if isinstance(token, str)]def register_special_tokens(self, special_tokens):"""注册特殊token到词汇表中"""if special_tokens is None:self.special_tokens = {}self.bytes_special_tokens = []return# 将字符串类型的特殊token转换为字节表示if not all(isinstance(token, bytes) for token in special_tokens):bytes_special_tokens = [token.encode("utf-8") for token in special_tokens if isinstance(token, str)]# 将特殊token添加到词汇表中for i, token in enumerate(bytes_special_tokens, start=len(self.vocab)):self.vocab[i] = token # 将特殊token添加到词汇表def _pre_tokenize(self, text) -> List[bytes]:"""预分词函数:将输入文本分割成字节token参数:text: 输入文本字符串返回:字节token列表"""# 首先按特殊token分割文本parts = split_by_special_tokens(text, list(self.special_tokens.keys()))token_list = []# 处理每个分割部分for part in parts:if part in self.special_tokens.keys():# 如果是特殊token,直接编码为字节token_list.append(part.encode("utf-8"))else:# 使用正则表达式分割普通文本tokens = re.findall(PAT, part)# 将每个单词转换为字节表示token_list.extend(word_to_bytes(token) for token in tokens)return token_listdef encode(self, text: str) -> List[int]:"""将文本编码为整数ID序列"""# 预分词获取字节tokenbyte_tokens = self._pre_tokenize(text)# 将字节token转换为初始ID序列token_ids = []for byte_token in byte_tokens:if byte_token in self.bytes_special_tokens:# 处理特殊tokentoken_ids.append([self.vocab_inv[byte_token]])else:# 将普通token拆分为单个字节并查找对应IDtoken_ids.append([self.vocab_inv[b] for b in byte_token]) #type: ignore# 应用BPE合并规则for i, pretoken in enumerate(token_ids):for merge in self.merges:# 检查合并后的token是否在词汇表中new_index = self.vocab_inv.get(merge[0] + merge[1], None)if new_index is None:continue# 尝试应用合并规则merged = []j = 0while j < len(pretoken):if (j < len(pretoken) - 1and (self.vocab[pretoken[j]], self.vocab[pretoken[j + 1]]) == merge):# 找到可合并的相邻token,应用合并merged.append(new_index)j += 2 # 跳过已合并的tokenelse:# 无法合并,保留原tokenmerged.append(pretoken[j])j += 1pretoken = merged # 更新当前预分词序列token_ids[i] = pretoken[:] # 保存处理后的序列# 展平所有预分词序列并返回return [i for pre in token_ids for i in pre]def encode_iterable(self, iterable: Iterable[str], batch_size: int = 1024) -> Iterator[int]:"""批量编码可迭代对象中的文本行参数:iterable: 可迭代的文本行batch_size: 批处理大小返回:整数ID的迭代器"""batch = []for line in tqdm(iterable):if not line:continuebatch.append(line)if len(batch) >= batch_size:# 处理完整批次for encoded in map(self.encode, batch):yield from encoded # 逐个生成IDbatch.clear() # 清空批次# 处理剩余的不完整批次if batch:for encoded in map(self.encode, batch):yield from encodeddef decode(self, ids: list[int]) -> str:"""将整数ID序列解码回文本参数:ids: 整数ID列表返回:解码后的文本字符串"""# 将ID转换回字节token,使用替换字符处理未知IDtokens = b"".join(self.vocab.get(i, b"\xef\xbf\xbd") for i in ids)# 将字节解码为UTF-8字符串return tokens.decode("utf-8", errors="replace")@classmethoddef from_files(cls, vocab_path: str, merges_path: str, special_tokens: list[str] | None = None):"""从文件加载词汇表和合并规则创建Tokenizer实例"""# 加载词汇表文件with open(vocab_path, 'rb') as vf:raw_vocab = pickle.load(vf)# 处理词汇表数据,确保值为字节类型vocab = {int(k): (v.encode("utf-8") if isinstance(v, str) else v)for k, v in raw_vocab.items()}# 加载合并规则文件with open(merges_path, 'rb') as mf:raw_merges = pickle.load(mf)# 处理合并规则数据,确保为字节类型merges = []for a, b in raw_merges:merges.append((a.encode("utf-8") if isinstance(a, str) else a,b.encode("utf-8") if isinstance(b, str) else b))# 创建并返回Tokenizer实例return cls(vocab, merges, special_tokens)

线性模型
要自己设计一个线性模型
class Linear(nn.Module):def __init__(self, in_features: int, out_features: int, device= None, dtype = None ):super().__init__()self.in_features = in_featuresself.out_features = out_featuresself.weight = nn.Parameter(torch.empty(in_features, out_features, device=device, dtype=dtype))self._init_weight()def _init_weight(self):std = (2 / (self.in_features + self.out_features)) ** 0.5nn.init.trunc_normal_(self.weight, mean=0.0, std=std, a=-3 * std, b=3 * std)def forward(self, x: torch.Tensor) -> torch.Tensor:return x @ self.weight
设计一个Embedding层


Transformer的嵌入层
Transformer 的第一层是嵌入层,它将整数标记 ID 映射到维度为 d_model 的向量空间。文本序列被映射成词汇表的单词ID的数字序列。嵌入层再将每个数字序列射成一个嵌入向量,这是该词含义的一个更丰富的表示。
在这里我们将实现一个自定义的 Embedding 类
import torch
import torch.nn as nnclass Embedding(nn.Module):def __init__(self, num_embedding: int, embedding_dim: int, device = None, dtype = None):"""嵌入层初始化参数:num_embedding: int - 词表大小,即需要嵌入的不同token数量embedding_dim: int - 嵌入向量的维度device: torch.device - 计算设备 (CPU/GPU)dtype: torch.dtype - 数据类型"""super().__init__() # 调用父类nn.Module的初始化方法# 保存参数self.num_embedding = num_embedding # 词表大小self.embedding_dim = embedding_dim # 嵌入维度# 定义可学习的权重参数,形状为 (词表大小, 嵌入维度)self.weight = nn.Parameter(torch.empty(num_embedding, embedding_dim, device=device, dtype=dtype))# 初始化权重self._init_weight()def _init_weight(self):"""使用截断正态分布初始化权重"""# trunc_normal_: 截断正态分布初始化,将值限制在[a, b]范围内# mean=0.0, std=1.0: 均值为0,标准差为1# a=-3.0, b=3.0: 将值限制在[-3, 3]标准差范围内,避免极端值nn.init.trunc_normal_(self.weight, mean=0.0, std=1.0, a=-3.0, b=3.0)def forward(self, token_ids: torch.Tensor) -> torch.Tensor:"""前向传播过程参数:token_ids: torch.Tensor - 输入token索引,形状为 (B, S)B: batch size (批大小)S: sequence length (序列长度)返回:torch.Tensor - 嵌入向量,形状为 (B, S, D)D: embedding dimension (嵌入维度)"""# 使用索引查找:根据token_ids中的索引从weight中提取对应的嵌入向量# token_ids中的每个整数索引对应weight矩阵中的一行# 结果形状从 (B, S) 变为 (B, S, D)return self.weight[token_ids]
每个 Transformer 块都包含两个子层:多头自注意力机制和位置感知前馈网络。
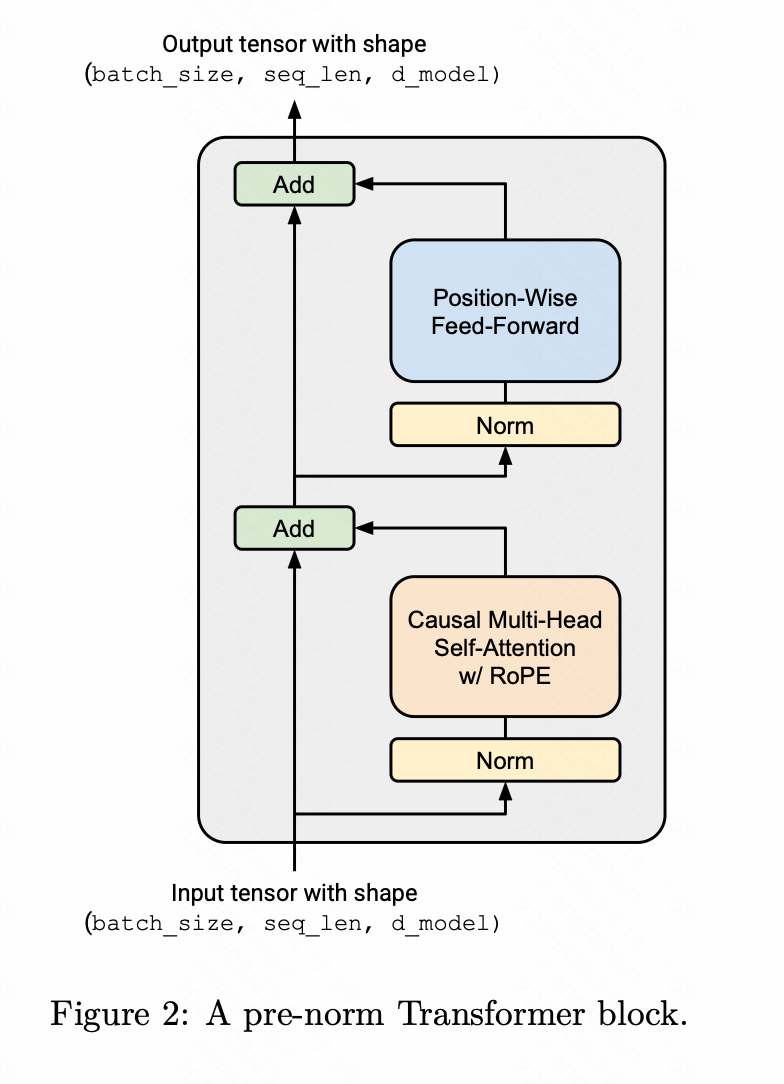
在最初的 Transformer 论文中,模型在每个子层周围使用了残差连接,然后进行层归一化。这种架构通常被称为“Post Norm” Transformer,因为层归一化是应用于子层输出的。
前归一化
然而,大量研究发现,将层归一化从每个子层的输出移到每个子层的输入可以提高 Transformer 的训练稳定性,下图展示了这种“前归一化”Transformer 块的视觉表示。然后,每个Transformer 块子层的输出通过残差连接加到子层输入上。前归一化的一个直观理解是,从输入嵌入到 Transformer 的最终输出之间存在一条干净的“残差流”,没有任何归一化,据称这有助于改善梯度流动。
这种预归一化 Transformer 现已成为当今语言模型(例如 GPT-3、LLaMA、PaLM 等)的标准,因此我们将实现这一变体。我们将依次介绍预归一化 Transformer 块的每个组件,并按顺序实现它们。
RMS Layer Normalization

class RMSNorm(nn.Module):def __init__(self, d_model: int, eps: float = 1e-5, device=None, dtype=None):super().__init__()self.d_model = d_modelself.eps = epsself.weight = nn.Parameter(torch.ones(d_model, device=device, dtype=dtype))def forward(self, x: torch.Tensor) -> torch.Tensor:x = x.float() # Ensure x is float for numerical stabilitynorm = torch.sqrt(torch.mean(x**2, dim=-1, keepdim=True) + self.eps)normalized_x = x / normreturn normalized_x * self.weight
SwiGLU
把SiLU和GLU组合在一起就成为了SwiGLU

先构建SiLu,再构建SwiGLU也就是FFN
def SiLU(x: torch.Tensor) -> torch.Tensor:"""Swish activation function."""return x * torch.sigmoid(x)class FFN(nn.Module):def __init__(self, d_model: int, d_ff: int, device=None, dtype=None):super().__init__()self.d_model = d_modelself.d_ff = d_ffself.w1 = Linear(d_model, d_ff)self.w2 = Linear(d_ff, d_model)self.w3 = Linear(d_model, d_ff)def forward(self, x: torch.Tensor) -> torch.Tensor:output = self.w2(SiLU(self.w1(x)) * self.w3(x))return output
RoPE旋转编码

其作用就是为 Transformer 模型中的 token 嵌入注入位置信息,使得模型能够感知 token 在序列中的顺序(即“谁在前、谁在后”),从而正确理解语言的结构和语义。
import torch
import torch.nn as nn # einops 是一个用于张量操作的库,提供更清晰、更易读的张量重排语法
import einopsclass RotaryPositionalEmbedding(nn.Module):"""旋转位置编码(Rotary Position Embedding, RoPE)模块。与传统的绝对位置编码不同,RoPE 通过将位置信息编码为旋转矩阵,使得注意力机制能够感知 token 之间的相对位置关系。"""def __init__(self, theta: float, d_k: float, max_seq_len: int, device=None):"""初始化 RoPE 模块。参数:- theta: 基础频率缩放因子(通常为 10000.0),控制频率衰减速度。- d_k: 注意力头的维度(即每个 token 的嵌入维度)。- max_seq_len: 支持的最大序列长度(用于预计算,但本实现中未显式使用)。- device: 计算设备(如 'cuda' 或 'cpu')。"""super().__init__()self.theta = thetaself.d_k = d_kself.max_seq_len = max_seq_len# 设置设备,默认为 CPUself.device = device if device else torch.device("cpu")# 计算逆频率(inverse frequencies):# 对于维度 0, 2, 4, ..., d_k-2,计算 1 / (theta^(i / d_k))# 这些频率用于构建旋转角度# torch.arange(0, d_k, 2) 生成 [0, 2, 4, ..., d_k-2](假设 d_k 为偶数)inv_freq = 1.0 / (self.theta ** (torch.arange(0, d_k, 2).float() / d_k))# 使用 register_buffer 注册为非参数缓冲区(不会被优化器更新,但会随模型移动设备)self.register_buffer("inv_freq", inv_freq)def _rotate_half(self, x: torch.Tensor) -> torch.Tensor:"""对输入张量进行“旋转一半”操作:将最后一维分成两半,交换并取负,实现 90 度旋转。例如:[x1, x2, x3, x4] -> [-x2, x1, -x4, x3]这是 RoPE 的核心操作,用于实现复数乘法的实部形式。参数:- x: 形状为 [..., d_k] 的张量返回:- 旋转后的张量,形状与输入相同"""# 将最后一维按每2个元素分组:(..., d_k) -> (..., d_k//2, 2)x = einops.rearrange(x, "... (d r) -> ... d r", r=2)# 拆分为两部分:x1 是偶数索引部分,x2 是奇数索引部分x1, x2 = x.unbind(dim=-1) # x1: [..., d_k//2], x2: [..., d_k//2]# 构造旋转后的形式:(-x2, x1)x = torch.stack((-x2, x1), dim=-1) # [..., d_k//2, 2]# 重新合并为 [..., d_k]return einops.rearrange(x, "... d r -> ... (d r)")def forward(self, x: torch.Tensor, token_positions: torch.Tensor) -> torch.Tensor:"""应用旋转位置编码到输入张量。RoPE 的数学本质是:将 token 嵌入视为复数,然后乘以 e^{i * m * θ}(m 是位置,θ 是频率),等价于:x * cos(mθ) + rotate(x) * sin(mθ)参数:- x: 输入张量,形状 [..., seq_len, d_k]- token_positions: 位置索引张量,形状 [..., seq_len],通常为 [0, 1, 2, ..., seq_len-1],支持动态位置(如滑动窗口)返回:- 应用 RoPE 后的张量,形状与 x 相同"""seq_len = x.size(-2) # 获取序列长度# 如果未提供 token_positions,则自动生成从 0 到 seq_len-1 的位置索引if token_positions is None:token_positions = torch.arange(seq_len, device=x.device)# 扩展为与 batch 维度对齐:(seq_len,) -> (B, seq_len)token_positions = token_positions.unsqueeze(0).expand(x.size(0), -1)# 计算每个位置和每个频率维度的旋转角度 θ = m * inv_freq# token_positions: [..., seq_len]# inv_freq: [d_k // 2]# 结果 theta: [..., seq_len, d_k // 2]theta = torch.einsum("... n, d -> ... n d", token_positions, self.inv_freq)# 计算 cos(θ) 和 sin(θ),并重复每个值两次以匹配 d_k 维度# 例如:[cos0, cos1] -> [cos0, cos0, cos1, cos1]cos = theta.cos().repeat_interleave(2, dim=-1) # [..., seq_len, d_k]sin = theta.sin().repeat_interleave(2, dim=-1) # [..., seq_len, d_k]# 应用 RoPE 公式:x_rot = x * cos + rotate_half(x) * sin# 这等价于复数乘法:(x_real + i*x_imag) * (cos + i*sin)x = x * cos + self._rotate_half(x) * sinreturn x
Softmax

Softmax 将这注意力得分转换为 非负、和为1 的权重:
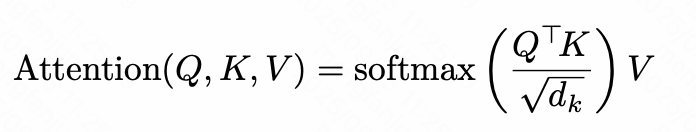
def softmax(x: torch.Tensor, dim: int = -1) -> torch.Tensor:x = x - torch.max(x, dim=dim, keepdim=True).valuesx = torch.exp(x)x = x / torch.sum(x, dim=dim, keepdim=True)return x
SDPA
SDPA实现标准的缩放点积注意力机制,根据查询(q)与键(k)的相似度,动态地从值(v)中提取加权信息,并支持通过 mask 控制注意力范围,重点读value,忽略不重要的部分。
SDPA就是这个计算:
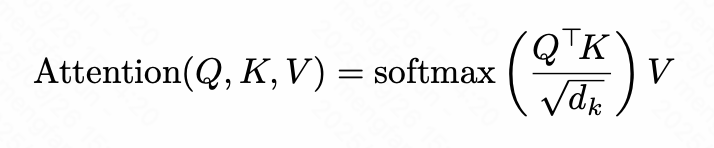

def scaled_dot_product_attention(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, mask: torch.Tensor | None = None) -> torch.Tensor:"""q: (B, S_q, D)k: (B, S_k, D)v: (B, S_v, D)mask: (B, S_q, S_k) or None"""d_k = k.size(-1)scores = torch.matmul(q, k.transpose(-2, -1)) / (d_k ** 0.5) # (B, S_q, S_k)if mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))attn_weights = softmax(scores, dim=-1) # (B, S_q, S_k)output = torch.matmul(attn_weights, v) # (B, S_q, D)return output
输出的结果是每个查询位置得到一个融合了上下文信息的表示
多头自注意力

这里的qkv虽然看起来一样,但是在nn.Linear中其Wq,Wk,Wv权重矩阵是完全不同的。
1.多头(Multi-Head)
把注意力拆成多个“小组”,每个小组独立关注不同的信息模式(比如一个头关注语法,一个头关注语义),最后汇总,效果比单头强得多。
2.位置感知(RoPE)
如果启用了use_rope=True,模型就能知道“第一个词”、“第二个词”……的位置关系,而且这种位置编码对长序列更友好(比传统的加性位置编码更强)。
3.防止作弊(因果掩码)
在生成文本时(比如写句子),模型只能看到当前词及之前的词,不能偷看未来的词。_causal_mask 就是干这个的——像考试时遮住后面的题目。
4.端到端学习
所有投影层(q_proj, k_proj 等)都是可训练的,模型会自动学会如何提取最有用的查询、键、值。
class MultiHeadAttention(nn.Module):def __init__(self,d_model: int, # 模型的隐藏层维度(例如 512)num_heads: int, # 注意力头的数量(例如 8)use_rope: bool = False, # 是否使用旋转位置编码(RoPE)max_seq_len: int | None = None, # 最大序列长度(用于 RoPE 缓存)theta: float | None = None, # RoPE 的基底参数(通常为 10000.0)token_positions: torch.Tensor | None = None, # 显式指定每个 token 的位置(用于 RoPE)):super().__init__()self.d_model = d_modelself.num_heads = num_heads# 检查 d_model 是否能被 num_heads 整除:每个头必须分到整数维度if d_model % num_heads != 0:raise ValueError("d_model must be divisible by num_heads")self.head_dim = d_model // num_heads # 每个注意力头的维度# RoPE 相关配置self.use_rope = use_ropeself.max_seq_len = max_seq_lenself.theta = thetaself.token_positions = token_positions# 如果启用 RoPE 且提供了必要参数,则初始化 RoPE 模块if use_rope and (max_seq_len is not None and theta is not None):# 注意:RoPE 通常作用于每个头的 head_dim 维度self.rope = RotaryPositionalEmbedding(theta, self.head_dim, max_seq_len)# 线性投影层:将输入分别映射为 Query、Key、Valueself.q_proj = nn.Linear(d_model, d_model) # 生成 Qself.k_proj = nn.Linear(d_model, d_model) # 生成 Kself.v_proj = nn.Linear(d_model, d_model) # 生成 V# 输出投影层:将多头拼接后的结果映射回 d_model 维度self.out_proj = nn.Linear(d_model, d_model)def _causal_mask(self, seq_len: int) -> torch.Tensor:"""生成因果掩码(Causal Mask),用于自回归生成(如语言模型)。只允许每个位置关注它自己及之前的位置,不能看未来。返回形状: (1, 1, seq_len, seq_len)"""# torch.tril 保留下三角(包括对角线),上三角为 0mask = torch.tril(torch.ones(seq_len, seq_len)).bool() # (S, S)# 增加 batch 和 head 维度以适配 attention 输入:(1, 1, S, S)mask = mask.unsqueeze(0).unsqueeze(0)return maskdef forward(self, in_features: torch.Tensor):"""前向传播:实现多头注意力计算。参数:in_features: 输入特征,形状 (B, S, D)B = batch sizeS = sequence lengthD = d_model(模型维度)返回:output: 注意力输出,形状 (B, S, D)"""B, S, D = in_features.size()# 1. 线性投影 + 拆分为多头# 先投影到 d_model,再 reshape 成 (B, S, num_heads, head_dim)# 然后转置为 (B, num_heads, S, head_dim),便于后续矩阵运算q = self.q_proj(in_features).view(B, S, self.num_heads, self.head_dim).transpose(1, 2) # (B, H, S, D/H)k = self.k_proj(in_features).view(B, S, self.num_heads, self.head_dim).transpose(1, 2) # (B, H, S, D/H)v = self.v_proj(in_features).view(B, S, self.num_heads, self.head_dim).transpose(1, 2) # (B, H, S, D/H)# 2. (可选)应用旋转位置编码(RoPE)为了保留词汇的相对位置关系if self.use_rope:# RoPE 将位置信息通过旋转矩阵融入 q 和 k,保留相对位置关系q = self.rope(q, self.token_positions) # token_positions 可为 None,此时默认使用 0,1,2,...k = self.rope(k, self.token_positions)# 3. 生成因果掩码(用于解码器或自回归任务)防止模型看到未来的数据mask = self._causal_mask(S) mask = mask.to(q.device) # 确保 mask 与数据在同一设备(CPU/GPU)# 4. 调用缩放点积注意力(注意:此处假设 scaled_dot_product_attention 支持 (B, H, S_q, S_k) 输入)# 输出形状: (B, H, S, D/H)attn_output = scaled_dot_product_attention(q, k, v, mask)# 5. 合并多头:转置回 (B, S, H, D/H) → reshape 为 (B, S, D)attn_output = attn_output.transpose(1, 2).contiguous().view(B, S, D)# 6. 最终线性投影output = self.out_proj(attn_output) # (B, S, D)return output
output是每个词(或 token)在“看过整个句子(或允许看的部分)之后”,重新生成的、带有上下文信息的新表示。