视觉/深度学习/机器学习相关面经总结(3)(持续更新)
对实习过程中用到的大模型的原理进行总结
目录
- 1、SAM
- 1.1 SAM1
- 面试回答
- 结构
- 1. Image Encoder(图像编码器):提取全局图像特征,为分割提供“图像基础信息”
- 2. Prompt Encoder(提示编码器):将多类用户提示转化为统一特征,实现“灵活交互”
- 3. Mask Decoder(掩码解码器):融合图像与提示特征,输出高精度分割结果
- 1.2 SAM2
- 面试回答:
- 结构
1、SAM
1.1 SAM1
面试回答
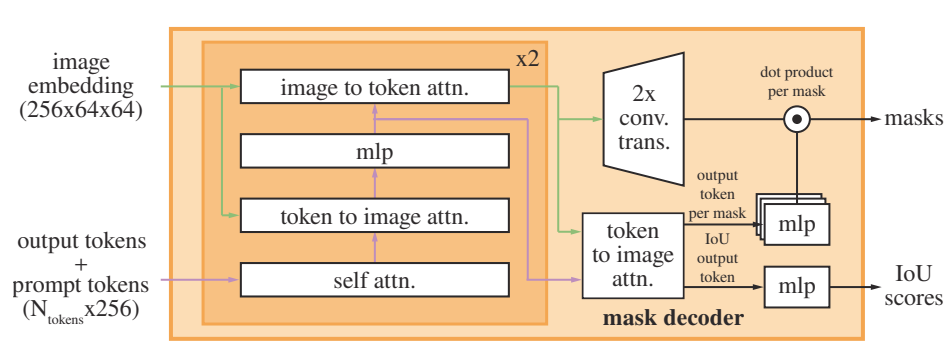
首先在结构上,三大核心模块:Image Encoder基于MAE预训练的ViT架构,提取为1/16下采样的64×64图像特征,提供全局语义基础;Prompt Encoder针对点、框、掩码三类提示分别编码——点/框通过坐标归一化、正弦余弦位置编码叠加少量可学习类别向量生成稀疏特征,掩码通过下采样与卷积生成密集特征,实现多提示统一转化;Mask Decoder则融合图像特征、提示特征及位置编码,借助Transformer注意力机制与可学习的掩码/IoU预测Token,输出4个不同粒度的二值化掩码及对应IoU分数,最终完成精准分割。它的输入是:「(图像 emb + 密集提示 emb) (Token 序列 + 稀疏提示 emb) 」
结构
三个模块:Image Encoder,Prompt Encoder和Mask Decoder

1. Image Encoder(图像编码器):提取全局图像特征,为分割提供“图像基础信息”
- 核心职责:将输入图像转化为具有全局语义信息的特征图,是后续分割的“图像理解基础”。
- 输入处理:为保证输入一致性与推理效率,对任意尺寸图像做标准化预处理——先等比例缩放至“长边=1024像素”,再减均值、除方差后补0至1024×1024。
- 核心技术:
- 基于MAE预训练的ViT架构(Vision Transformer),利用ViT的全局注意力优势捕捉长距离语义关联;
- 输出:生成1/16下采样的64×64特征图(即Image Embedding),通道数通常为768/1024,既保留足够空间细节(支撑细粒度分割),又压缩维度降低后续计算成本。
掩码自编码器(masked autoencoders, MAE)是视觉任务中的灵活的自监督学习器。MAE思路很简单:对输入图像的patches序列随机掩码(遮挡),然后尝试重建出这些被遮挡的像素。
2. Prompt Encoder(提示编码器):将多类用户提示转化为统一特征,实现“灵活交互”
- 核心职责:适配点、矩形框、掩码3类主流提示,将其编码为模型可理解的特征向量,是SAM“通用交互”的核心——解决“不同类型提示如何统一输入模型”的问题。
- 分类型编码逻辑(重点,体现设计细节):
提示类型 输入形式 核心编码步骤 可学习参数亮点 点(Point) 坐标(x,y)+类别(前景/背景) 1. 坐标移至像素中心→归一化到[-1,1];
2. 正弦余弦位置编码(不可学习,保证空间信息);
3. 叠加“前景/背景可学习向量”(仅2个可学习参数,轻量化)仅类别向量可学习,兼顾效果与效率 框(Box) 左上/右下角点坐标 1. 复用点的“坐标归一化+正弦余弦编码”;
2. 叠加“左上/右下角点可学习向量”(区分角点类型)仅角点向量可学习,与点编码复用逻辑 掩码(Mask) 二值化掩码(1024×1024) 1. 先下采样4倍→再通过2层Conv2D-LN-GeLU下采样4倍(总下采样16倍);
2. 无掩码时用“可学习向量复制填充”卷积层可学习,适配密集提示 - 输出:两类特征统一输出——点/框对应“稀疏特征向量”,掩码对应“64×64密集特征图”,为后续融合做准备。
3. Mask Decoder(掩码解码器):融合图像与提示特征,输出高精度分割结果
- 核心职责:将“图像特征(Image Embedding)”与“提示特征(Prompt Embedding)”融合,最终输出对应分割掩码及质量分数,是SAM“精准分割”的核心。
- 输入构成:4类关键输入——①Image Encoder输出的图像特征;②Prompt Encoder输出的稀疏/密集提示特征;③图像特征的位置编码(补充空间信息);④2个可学习Token(分别用于“掩码预测”和“IoU分数预测”)。
- 核心技术:
- 特征融合:通过Transformer注意力机制,让提示特征“引导”图像特征聚焦于目标区域(比如点提示会让图像特征在对应位置权重升高);
- 多粒度输出:为平衡“分割精度”与“场景适配性”,每次推理输出4个掩码(对应不同分割粒度),同时通过MLP输出每个掩码的IoU分数(供用户选择最优结果);
- 输出:4个1024×1024二值化掩码(与原图尺寸一致)+4个IoU分数(衡量掩码与真实目标的重合度)。
1.2 SAM2
面试回答:
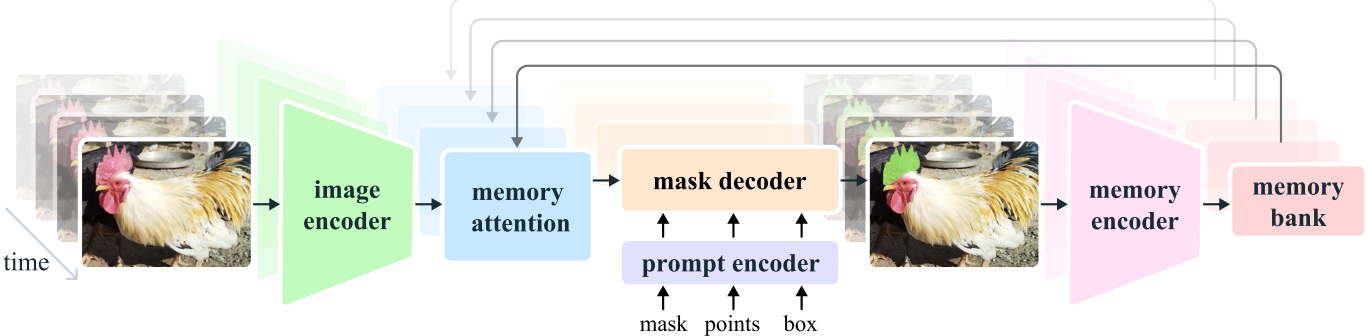
SAM2 将 SAM 的可提示分割从图像扩展到视频。
图像编码器:使用 MAE 预训练的 Hiera 层次化 ViT,结合 FPN 生成 stride 4–32 的多尺度特征,并以流式方式处理长视频。
记忆机制:通过 Memory Encoder 将每帧预测的掩码与图像特征编码为记忆,存入 Memory Bank(包含最近帧的空间特征和目标语义向量)。解码时,Memory Attention 将当前帧与历史记忆做交叉注意力(使用 FlashAttention2 加速),并加入时间位置嵌入以建模短期运动。
Prompt Encoder:与 SAM1 相同,支持点、框、掩码提示。
Mask Decoder:采用 双向 Transformer 融合当前帧特征、提示和历史记忆,输出多个候选掩码及其 IoU 分数,并新增 可见性预测头 以判断目标在当前帧是否可见。
这样 SAM2 实现了“任意帧提示—全视频掩码自动传播—多轮交互修正”的 Promptable Visual Segmentation。
结构
-
任务扩展:从静态图像的可提示分割扩展到 Promptable Visual Segmentation (PVS) ——在任意帧接收点击/框/掩码提示,自动生成该目标在全视频的掩码序列(masklet),支持用户多轮交互修正。
-
图像编码器:采用 MAE 预训练的 Hiera(层次化 ViT),并通过 FPN 多尺度融合 (stride 4/8/16/32),在保证高分辨率细节的同时流式处理视频,每帧只需一次前向。
-
记忆机制:
- Memory Encoder:将当前帧图像特征与预测掩码融合成记忆;
- Memory Bank:FIFO 队列保存最近 N 帧的空间特征与目标语义向量(object pointer),并对提示帧单独维护队列;
- Memory Attention:当前帧自注意力 + 与记忆做交叉注意力,使用 FlashAttention 2 加速,并加入时间位置嵌入建模短期运动。
-
Prompt Encoder:沿用 SAM1 设计,支持点/框/掩码提示。
-
Mask Decoder:
- 采用 双向 Transformer 块,输入 = 当前帧特征 + 历史记忆 + 当前提示;
- 输出多候选掩码及 IoU 分数;
- 额外 可见性预测头,判断当前帧是否能看到目标。
-
训练策略:在图像+视频数据上联合训练,随机帧接收提示并顺序预测真实掩码;支持交互式点击校正。