【不背八股】18.GPT1:GPT系列的初代目
引言
上篇文章提到,BERT 保留了 Transformer 中 Encoder 模块,在大部分理解类问题上,实现了最优效果。
BERT是在2018年10月发表的,在此之前,2018年6月 GPT-1 这篇工作发布的更早,它保留的是 Transformer 中 Decoder 模块,以现在这个时间点会看,GPT 的影响力更高,后面衍生出 ChatGPT 这种出圈产品。
本文将时间拨回到7年前,看看 ChatGPT 的源头 GPT-1 是如何设计的。
论文标题:Improving Language Understanding
by Generative Pre-Training
论文地址:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf

1. 背景
在 BERT 这项工作中,应用了大规模预训练+下游任务微调这套范式,其实,这套范式的思想最早起源于计算机视觉领域,GPT 比 BERT 更早采用了这套范式。
从 GPT 的标题就可以看出,GPT工作核心是通过生成式预训练来提升语言模型的理解力。
实现高水平的自然语言理解所面临的最大挑战是标注数据的稀缺。
为缓解这一问题,研究者早期尝试利用无监督学习手段,从大规模无标注语料中学习通用的词向量表示。典型方法如 Word2Vec 和 GloVe,它们通过统计词语共现关系,获得了能够捕捉语义相似性的低维向量表示。这些词向量在下游任务中被广泛使用,大幅提升了模型的性能。
随后,ELMo 提出了基于上下文的词表示,使得同一个词在不同语境下拥有不同的向量,更进一步改善了自然语言处理的效果。
但这些方法大多停留在“词级别”的表示,缺乏对长距离依赖、句子结构和更高层次语义的建模能力。
于是一个核心问题被提出:能否借助大规模的无监督文本,直接预训练一个能够捕捉丰富语义和上下文信息的模型,从而更好地服务于各类自然语言理解任务?
这就是 GPT 所要解决的问题。
2. 模型设计
GPT-1 的设计核心在于:采用 Transformer 解码器结构,并通过“预训练 + 微调”的流程,让模型既能学习通用的语言知识,又能高效适配下游任务。其整体设计可以分为三个部分:架构选择、预训练、微调。
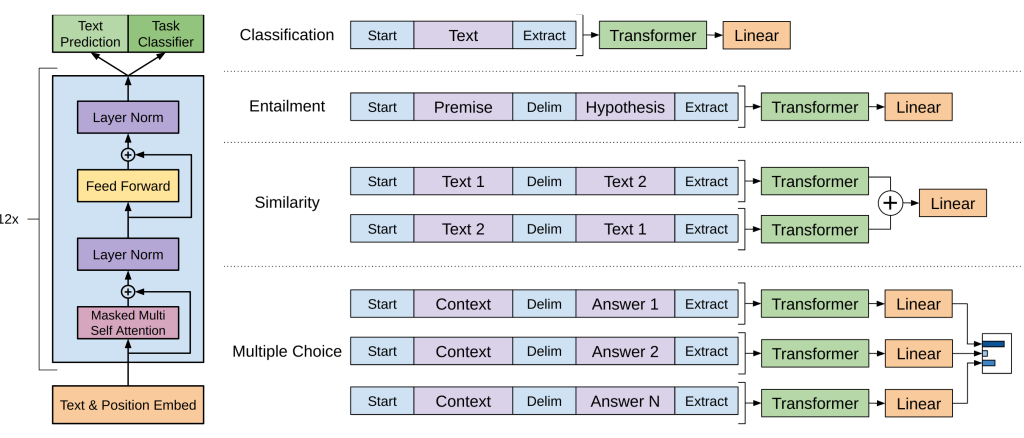
2.1 模型架构
-
Transformer 解码器(Decoder-only)
- GPT-1 采用了 Vaswani 等人在 Attention is All You Need 中提出的 Transformer 框架。
- 不同于 BERT 的“编码器结构”,GPT-1 使用 单向的解码器堆叠,以便进行自回归语言建模。
-
具体配置:
- 层数:12 层
- 隐藏维度:768
- 注意力头数:12
- 总参数量:约 1.17 亿
-
关键技术点:
- 使用多头自注意力(Multi-Head Self-Attention)捕捉长距离依赖
- 采用 GELU 激活函数、残差连接与 LayerNorm 保持稳定训练
- 使用字节对编码(BPE)词表(40,000 词元)提升表示能力
2.2 预训练阶段
-
目标函数:语言建模(Language Modeling,预测下一个词)
-
给定一个序列的前文,预测下一个 token 的概率:
L=∑ilogP(ui∣ui−k,…,ui−1;Θ) L = \sum_i \log P(u_i | u_{i-k}, \dots, u_{i-1}; \Theta) L=i∑logP(ui∣ui−k,…,ui−1;Θ)
-
-
训练数据:BooksCorpus(约 7,000 本书,7GB 文本)
- 数据连续性强,能够让模型学习跨段落、跨句子的长程依赖
-
训练策略:
- 批大小:64
- 序列长度:512
- 优化器:Adam,初始学习率 2.5e-4,带 warmup 和余弦退火
- 正则化:Dropout 0.1,L2 权重衰减,BPE 分词
2.3 微调阶段
在完成预训练后,GPT-1 会将模型迁移到具体的下游任务(如自然语言推理、问答、文本分类、语义相似度等)。其关键思路是:在预训练模型的基础上,仅增加一个简单的线性输出层,然后在标注数据上进行监督训练。
-
基本方法:
-
输入文本经过预训练的 Transformer,得到最后一层的表示向量 hlmh^m_lhlm;
-
再接一个线性层 + softmax,用来预测下游任务的标签:
P(y∣x1,…,xm)=softmax(hlmWy) P(y|x_1, \dots, x_m) = \text{softmax}(h^m_l W_y) P(y∣x1,…,xm)=softmax(hlmWy)
-
对应的监督学习目标函数为:
L2(C)=∑(x,y)logP(y∣x1,…,xm) L_2(C) = \sum_{(x,y)} \log P(y|x_1, \dots, x_m) L2(C)=(x,y)∑logP(y∣x1,…,xm)
-
-
辅助目标:
在微调过程中,作者发现如果在监督任务目标之外,同时保留一部分语言建模目标,能显著提高泛化性能并加速收敛。于是引入了联合损失函数:L3(C)=L2(C)+λ⋅L1(C) L_3(C) = L_2(C) + \lambda \cdot L_1(C) L3(C)=L2(C)+λ⋅L1(C)
- L1(C)L_1(C)L1(C):语言建模目标(预测下一个词)
- L2(C)L_2(C)L2(C):下游任务的监督目标
- λ\lambdaλ:权重系数(实验中设为 0.5)
-
任务输入转换:为了适配不同任务的输入,GPT-1 提供了简单而统一的方式:
- 文本分类:直接输入句子
- 自然语言推理(NLI):前提句 + 分隔符 + 假设句
- 语义相似度:拼接两句话,或交换顺序再融合
- 问答/常识推理:上下文 + 问题 + 分隔符 + 候选答案,每个候选单独计算概率,最后用 softmax 选择
通过这种方式,GPT-1 在迁移过程中几乎不需要复杂的任务特定改造,只需在通用架构上加上一个输出层,就能适配多种自然语言理解任务。
3. 实验与结果
GPT-1 在 12 个不同数据集 上进行了实验,涵盖了推理、问答、语义相似和分类四大类任务。
-
自然语言推理(Natural Language Inference, NLI)
- 数据集:SNLI、MultiNLI、QNLI、SciTail、RTE
- 任务目标:判断前提句与假设句的关系(蕴含、矛盾或中立)
-
问答与常识推理(Question Answering & Commonsense Reasoning)
- 数据集:RACE(英语阅读理解考试)、Story Cloze Test
- 任务目标:根据文章或故事,选择正确答案或结尾
-
语义相似度(Semantic Similarity)
- 数据集:MRPC(微软释义语料)、QQP(Quora 相似问句)、STS-B(语义文本相似基准)
- 任务目标:判断两句话是否表达相同含义,或计算语义相似度
-
文本分类(Text Classification)
- 数据集:SST-2(情感分类)、CoLA(语法可接受性)
- 任务目标:句子情感判别,或判断句子是否语法正确

GPT-1 在 12 个数据集中有 9 个刷新了当时的最佳成绩。
4. 分析与发现
除了在标准任务上的性能评估,作者还进行了深入分析,以探讨 GPT-1 为什么能在多任务上取得显著提升,以及不同设计选择对结果的影响。
4.1 零样本能力(Zero-shot Behaviors)
-
现象:在没有进行任务特定微调的情况下,预训练模型本身就展现出一定的“零样本”能力。
-
示例:
- 在情感分析(SST-2)任务中,作者仅在输入句子后附加一个提示词(如“very”),限制输出为“positive”或“negative”,模型依然能给出合理预测。
- 在问答(RACE)任务中,直接利用语言模型对候选答案计算条件概率,模型也能表现出超过随机水平的准确率。
-
启示:预训练语言模型在学习预测下一个词的过程中,隐性地习得了很多通用语言知识和推理能力。
4.2 消融实验(Ablation Studies)
作者通过对比不同实验设置,验证了各个组件的重要性:
-
没有预训练
- 如果直接在下游任务上训练 Transformer,性能显著下降(平均分降低约 14.8%),说明 预训练是性能提升的关键。
-
没有辅助语言模型目标
- 如果在微调过程中不保留语言建模目标,部分任务表现下降。
- 结果表明:大数据集(如 NLI、QQP)更依赖这一辅助目标,而小数据集影响不大。
-
架构对比:Transformer vs. LSTM
- 在相同框架下,用 LSTM 替换 Transformer,平均性能下降 5.6 分。
- 说明 Transformer 更擅长捕捉长程依赖,迁移能力更强。
4.3 层数转移的影响
- 作者研究了微调时,迁移不同数量的预训练层对性能的影响。
- 发现随着迁移层数增加,模型表现持续提升,在 MultiNLI 和 RACE 上最高可提升 9%。
- 这说明:预训练的每一层都学到了可迁移的功能表示。
总结
GPT-1 这篇工作思路很简单,一句话概括就是“预测下一个词+特定任务结构微调”。
总体来看,它更多是一种新结构的“试水”,GPT-1模型的参数量仅有1.17 亿参数(117M),预训练也仅仅采用了一个数据集 BooksCorpus。它把这条路探通了,后面系列就可以开始往数值膨胀的方向进一步拓展了。