中国菲律宾商会网站seo优化免费
想在 CentOS 上安装 Hadoop 3.4.1,我给你写一个完整、可执行的安装配置流程(假设你已经下载了 hadoop-3.4.1.tar.gz 并且系统已经安装了 JDK 11)。
1️⃣ 准备工作
安装 Java(JDK 11)并设置环境变量:
sudo mkdir -p /opt/jdk
sudo tar -zxvf jdk-11.0.27_linux-x64_bin.tar.gz -C /opt/jdk
echo "export JAVA_HOME=/opt/jdk/jdk-11.0.27" | sudo tee -a /etc/profile
echo "export PATH=\$JAVA_HOME/bin:\$PATH" | sudo tee -a /etc/profile
source /etc/profile
java -version # 验证
创建 Hadoop 安装目录:
sudo mkdir -p /opt/hadoop
sudo chown -R $(whoami):$(whoami) /opt/hadoop
2️⃣ 解压 Hadoop
cd /opt/hadoop
tar -zxvf /path/to/hadoop-3.4.1.tar.gz
#或者
#cd /opt
#sudo tar -zxvf hadoop-3.4.1.tar.gz -C /opt/hadoopmv hadoop-3.4.1 hadoop
此时 Hadoop 安装目录为
/opt/hadoop/hadoop
3️⃣ 配置环境变量
编辑用户 .bashrc 或全局 /etc/profile:
nano ~/.bashrc
添加以下内容:
# Hadoop 环境变量
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_HOME=/opt/jdk/jdk-11.0.27
sudo /opt/hadoop/hadoop-3.4.1/bin/hdfs namenode -format
netstat -tlnp | grep 9000
生效配置:
source ~/.bashrc
验证:
hadoop version
4️⃣ 配置 Hadoop
进入配置文件目录:
cd $HADOOP_HOME/etc/hadoop
编辑核心配置文件:
4.1 core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>
4.2 hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:///opt/hadoop/hadoopdata/hdfs/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>file:///opt/hadoop/hadoopdata/hdfs/datanode</value></property>
</configuration>
或者
<configuration><property><name>dfs.data.dir</name><value>/data/hdfs/datanode</value></property><property><name>dfs.replication</name><value>1</value> <!-- 单副本方便测试 --></property>
</configuration>
core-site.xml必须配合hdfs-site.xml的文件配置,
单独的core-site.xml的文件只能启动namenode节点
单独的hdfs-site.xml的文件只能启动datanode节点
如何单独启动namenode节点和datanode节点
命令行:
hdfs --daemon start datanodehdfs --daemon stop datanodehdfs --daemon start namenodehdfs --daemon stop namenode
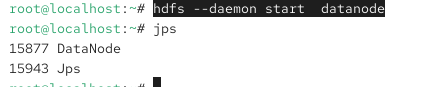
如果启动后出现
或者出现hdfs命令找不到就会是hdfs-site.xml出错。
可能是hdfs-site.xml的目录配错了。
修改成

netstat -tlnp | grep 9000

使用 jps 检查进程:
命令行:jps
4.3 mapred-site.xml
复制模板文件:
在文件夹
/opt/hadoop/hadoop-3.4.1/etc/hadoop
这里
cp mapred-site.xml.template mapred-site.xml
nano mapred-site.xml
cp命令是复制粘贴一个命名改变的文件。
不改变原文件。
添加:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
4.4 yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
5️⃣ 创建 HDFS 数据目录
mkdir -p /opt/hadoop/hadoopdata/hdfs/namenode
mkdir -p /opt/hadoop/hadoopdata/hdfs/datanode
确保当前用户可写:
sudo chmod 777 /opt/hadoop/hadoopdata
sudo chown -R $(whoami):$(whoami) /opt/hadoop/hadoopdata
6️⃣ 格式化 Namenode
hdfs namenode -format
输出成功提示表示 HDFS 可以启动。
7️⃣ 启动 Hadoop
启动 HDFS:
start-dfs.sh
启动 YARN:
start-yarn.sh
验证:
jps
应该看到:
NameNode
DataNode
SecondaryNameNode
ResourceManager
NodeManager
停止
stop-dfs.shstop-yarn.sh8️⃣ 测试 Hadoop
创建目录并上传文件:
hdfs dfs -mkdir /userhdfs dfs -mkdir /user/$(whoami)/1
hdfs dfs -mkdir /user/$(whoami)
hdfs dfs -put /etc/hosts /user/$(whoami)/
hdfs dfs -put /test/ /user/$(whoami)/
hdfs dfs -ls /user/$(whoami)
hdfs删除文件
hdfs删除文件hdfs dfs -rm /user/$(whoami)/hostshdfs删除空文件夹hdfs dfs -rm /user/$(whoami)/hosts使用递归删除命令可删除有文件的文件夹:hdfs dfs -rm -r /user/$(whoami)/test
✅ 到此,Hadoop 3.4.1 + JDK 11 在 CentOS 上已经配置完成,并且可以正常使用 HDFS 和 YARN。
✅ 注意事项
单独 DataNode 必须能访问 NameNode,否则无法注册。
dfs.data.dir必须有写权限。如果是单节点集群,只启动 DataNode 没用,因为没有 NameNode 管理元数据。
可用于扩展已有 NameNode 集群,增加存储容量。
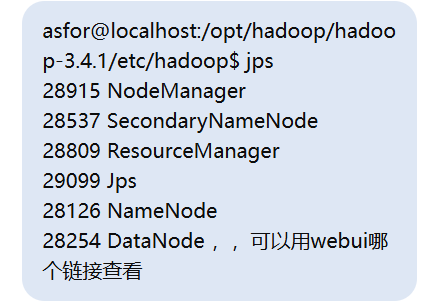
根据你的 jps 输出,你的 Hadoop 组件都在运行:
28126 NameNode
28254 DataNode
28537 SecondaryNameNode
28809 ResourceManager
28915 NodeManager
对应的 Web UI 地址如下:
1️⃣ NameNode Web UI
查看 HDFS 状态(文件系统容量、目录、DataNode 状态等)
默认端口:
9870(Hadoop 3.x)
http://localhost:9870/
功能:
查看 HDFS 总容量和已用容量
查看 DataNode 列表和状态
浏览 HDFS 目录结构
2️⃣ ResourceManager Web UI
查看 YARN 集群状态和运行中的 MapReduce 任务
默认端口:
8088
http://localhost:8088/
功能:
集群节点状态(NodeManager 列表)
正在运行的应用程序(MapReduce 作业)
作业历史记录
3️⃣ DataNode / NodeManager Web UI(可选)
DataNode 默认端口:
9864
http://localhost:9864/
NodeManager 默认端口:
8042
http://localhost:8042/
功能:
查看单个节点的资源使用情况
查看运行的容器和日志
✅ 总结
HDFS 文件系统:
http://localhost:9870/YARN 集群 / MapReduce 作业:
http://localhost:8088/单节点状态(可选):
DataNode:
http://localhost:9864/NodeManager:
http://localhost:8042/
你可以先打开
http://localhost:9870/查看 HDFS,再打开http://localhost:8088/查看 MapReduce 作业状态。