【AI论文】Qwen3-Omni技术报告
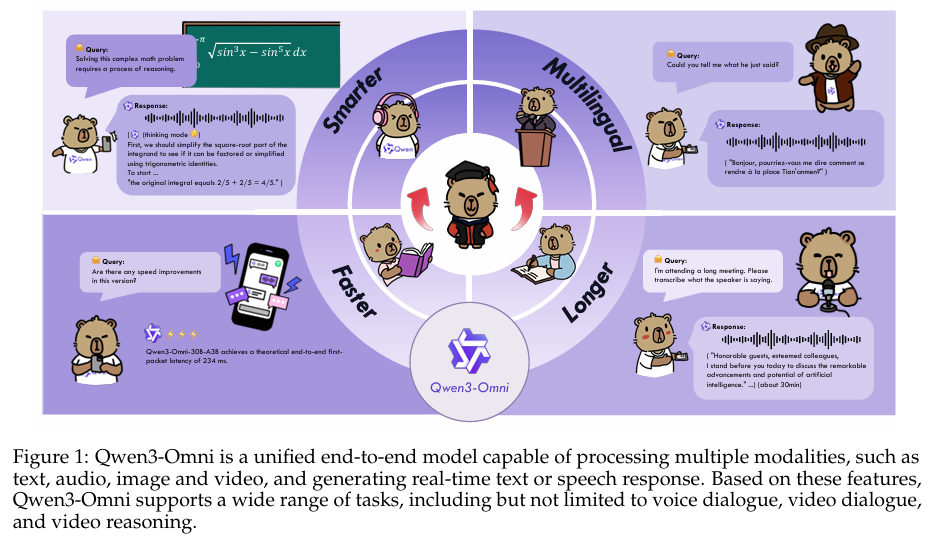
摘要:我们推出通义千问3-全能(Qwen3-Omni),这是一款单一的多模态模型,首次在文本、图像、音频和视频任务上均保持了与单模态模型相当的顶尖性能,且在各模态上均未出现性能衰减。Qwen3-Omni在通义千问系列中达到了与同规模单模态模型相当的性能,尤其在音频任务上表现卓越。在36个音频及视听基准测试中,Qwen3-Omni在32个基准测试上取得开源模型中的最优(SOTA)成绩,在22个基准测试上取得整体最优成绩,超越了Gemini-2.5-Pro、Seed-ASR和GPT-4o-Transcribe等强大的闭源模型。
Qwen3-Omni采用了“思考者-表达者”(Thinker-Talker)混合专家(MoE)架构,该架构统一了文本、图像、音频和视频的感知与生成能力,可输出流畅的文本和自然的实时语音。它支持119种语言的文本交互、19种语言的语音理解以及10种语言的语音生成。为降低流式合成中的首包延迟,表达者模块采用多码本方案,以自回归方式预测离散语音编码。利用这些码本的强大表征能力,我们用轻量级的因果卷积网络(ConvNet)取代了计算密集型的块级扩散模型,实现了从首个编码帧开始的流式输出。在冷启动场景下,Qwen3-Omni的理论端到端首包延迟可低至234毫秒。
为进一步强化多模态推理能力,我们引入了思考者模型,该模型可对任意模态的输入进行显式推理。鉴于当前研究界尚无通用的音频描述生成模型,我们对Qwen3-Omni-30B-A3B进行微调,得到了Qwen3-Omni-30B-A3B-Captioner模型,该模型可为任意音频输入生成详细且低幻觉的描述。Qwen3-Omni-30B-A3B、Qwen3-Omni-30B-A3B-Thinking和Qwen3-Omni-30B-A3B-Captioner均已根据Apache 2.0许可证公开发布。
Huggingface链接:Paper page,论文链接:2509.17765
研究背景和目的
研究背景:
随着人工智能技术的迅猛发展,多模态大型语言模型(Multimodal Large Language Models, MLLMs)已成为自然语言处理和计算机视觉领域的研究热点。
这些模型通过整合文本、图像、音频和视频等多种模态的信息,展现出强大的理解和推理能力。然而,传统LLM-centric的多模态模型往往存在模态间的性能权衡问题,即在提升某一模态性能时,可能会牺牲其他模态的性能。此外,现有模型在处理复杂多模态任务时,尤其是跨模态推理和实时交互方面,仍面临诸多挑战。
研究目的:
本研究旨在开发一个名为Qwen3-Omni的统一多模态模型,该模型能够在不牺牲任何单模态性能的前提下,实现文本、图像、音频和视频四种模态的统一理解和生成。
具体目标包括:
- 消除模态性能降级:通过联合多模态训练,实现跨模态性能的全面提升,避免传统模型中常见的模态间性能权衡问题。
- 增强跨模态推理能力:引入Thinking模型,显式地对任意模态的输入进行推理,提升模型在复杂多模态任务中的理解和推理能力。
- 实现实时音频交互:通过优化语音生成模块,降低首包延迟,提升模型在实时音频交互场景下的响应速度和流畅度。
- 支持多语言与多方言:扩展模型的语言支持范围,使其能够处理更多语言和方言的输入和输出。
研究方法
模型架构:
Qwen3-Omni采用了Thinker-Talker混合专家(Mixture-of-Experts, MoE)架构,该架构统一了文本、图像、音频和视频的感知与生成能力。
具体架构设计如下:
- Thinker模块:负责文本生成,采用MoE设计,支持高并发和快速推理。同时,Thinker模块还处理来自视觉和音频编码器的多模态特征,进行跨模态推理。
- Talker模块:负责生成实时语音,采用多码本表示和轻量级因果卷积网络(ConvNet),实现低延迟的语音合成。
- 视觉编码器:继承自Qwen3-VL,采用SigLIP2-So400m架构,支持图像和视频输入的处理。
- 音频编码器(AuT):全新训练的自回归音频编码器,支持大规模音频数据的监督学习,具备更强的通用音频表示能力。
训练策略:
- 分阶段预训练:
- 编码器对齐阶段:固定LLM参数,单独训练视觉和音频编码器,增强语义理解能力。
- 通用阶段:解冻所有参数,使用包含文本、图像、音频和视频的多模态数据集进行训练,提升模型的综合理解能力。
- 长上下文阶段:增加最大令牌长度,引入更多长音频和长视频数据,增强模型对长序列数据的理解能力。
- 后训练阶段:
- Thinker后训练:通过轻量级监督微调(SFT)和强到弱蒸馏(Strong-to-Weak Distillation)提升模型的指令跟随能力。
- Talker后训练:采用持续预训练(CPT)、长上下文训练和直接偏好优化(DPO)等技术,提升语音生成的质量和稳定性。
研究结果
性能表现:
- 综合多模态理解能力:Qwen3-Omni在36个音频和视听基准测试中,32个达到了开源SOTA,22个达到了整体SOTA,超越了包括Gemini-2.5-Pro、Seed-ASR和GPT-4o-Transcribe在内的强闭源模型。
- 文本理解能力:在文本到文本的任务中,Qwen3-Omni-30B-A3B-Instruct在多个基准测试中超越了更大的Qwen3-235B-A22B模型和GPT-4o-0327,展现出与文本专用模型相当的性能。
- 音频理解与生成能力:在语音识别、语音翻译和语音推理等任务中,Qwen3-Omni同样表现出色,特别是在长音频处理和跨模态音频理解方面展现出强大能力。
- 视频理解能力:在视频理解任务中,Qwen3-Omni通过统一的3D位置嵌入和时间对齐多模态旋转位置嵌入(TM-RoPE)技术,实现了对视频内容的精准理解和推理。
效率提升:
- 低延迟语音生成:通过采用多码本表示和轻量级ConvNet,Qwen3-Omni在冷启动设置下实现了234ms的理论端到端首包延迟,显著提升了实时语音交互的流畅度。
- 低资源消耗:在保持高性能的同时,Qwen3-Omni通过MoE架构和轻量级模块设计,有效降低了模型的计算成本和内存占用。
研究局限
尽管Qwen3-Omni在多模态理解和生成方面取得了显著成果,但该研究仍存在一些局限:
- 数据依赖性:模型性能高度依赖于训练数据的质量和多样性,数据工程的质量直接影响模型性能。特别是在处理低资源语言和方言时,数据稀缺问题尤为突出。
- 长视频理解:尽管在视频理解方面取得了进展,但对长视频和极端长视频的理解能力仍有待提高,特别是在处理低分辨率视频时的性能。
- 实时交互优化:虽然实现了低延迟的语音生成,但在高并发场景下,实时交互的稳定性和响应速度仍有提升空间。
- 跨模态对齐:不同模态间的信息对齐和融合仍面临挑战,特别是在处理复杂多模态任务时,跨模态对齐的准确性和效率有待提高。
未来研究方向
基于Qwen3-Omni的研究成果和局限,未来研究可以从以下几个方面展开:
- 数据自主性:减少对外部数据的依赖,通过自监督学习和无监督学习方法,提升模型从少量数据中学习的能力。同时,探索更有效的数据增强和合成技术,以缓解数据稀缺问题。
- 长视频理解:改进模型对长视频和极端长视频的理解能力,特别是在处理低分辨率视频时的性能。通过引入更先进的时间序列建模和注意力机制,提升模型对视频内容的精准理解和推理能力。
- 实时交互优化:进一步优化模型的实时交互能力,特别是在高并发场景下的稳定性和响应速度。通过引入更高效的流式处理技术和缓存机制,减少实时交互的延迟和卡顿现象。
- 跨模态对齐:探索更有效的跨模态对齐方法,提升不同模态间信息的融合和互补能力。通过引入更先进的对齐损失函数和注意力机制,提高跨模态推理的准确性和效率。
- 模型压缩与加速:探索更高效的模型压缩和加速技术,减少模型参数数量和计算成本。通过引入量化、剪枝和知识蒸馏等方法,实现模型在资源受限设备上的高效部署和运行。
- 多语言与多领域支持:扩展模型支持的语言和领域范围,提高模型在不同文化和领域背景下的适用性。通过引入多语言预训练和微调技术,以及领域自适应方法,提升模型在多语言和多领域任务中的性能。
通过上述方向的深入研究,可以进一步提升多模态大型语言模型的效率、通用性和可靠性,推动AI技术向更广泛的实际应用场景发展。