用 LoRA 微调 Qwen3-0.6B 模型,打造专属宠物商店智能客服
在 AI 大模型时代,每个行业都能通过微调技术定制专属 AI 助手。对于宠物商店而言,一个能解答喂养知识、商品咨询、常见疾病建议的智能客服,能极大提升客户体验并降低人工成本。本文将以Qwen3-0.6B 模型为基础,通过LoRA 轻量化微调技术,一步步教你打造宠物商店智能客服模型,即使是 基础的Mac 设备也能流畅运行。
一、项目背景与技术选型
在开始前,我们先明确为什么选择当前的技术方案:
| 选型维度 | 选择方案 | 选择理由 |
|---|---|---|
| 基础模型 | Qwen3-0.6B | 阿里通义千问推出的轻量级模型,0.6B 参数对硬件要求低(Mac/MiniPC 均可运行),同时保留较好的对话能力 |
| 微调技术 | LoRA(Low-Rank Adaptation) | 仅训练模型的少量参数(约 0.1%),显存占用低、训练速度快,避免全量微调的高硬件成本 |
| 开发环境 | PyTorch + Transformers + PEFT | 生态成熟,文档丰富,PEFT 库提供 LoRA 的开箱即用支持,降低微调门槛 |
| 数据格式 | JSON Lines(.jsonl) | 适合存储单条对话数据,便于分批加载和预处理,支持增量数据更新 |
二、前期准备:环境搭建与数据准备
在编写代码前,需要完成环境配置和数据准备两个关键步骤,这是后续微调顺利进行的基础。
1. 环境搭建
首先安装所需的 Python 库,建议使用虚拟环境,避免依赖冲突:
# 基础依赖
pip install torch transformers datasets
# LoRA相关依赖
pip install peft accelerate
# 数据处理依赖
pip install jsonlines regex
对于 Mac 用户,无需额外安装 CUDA(LoRA 微调 0.6B 模型无需 GPU),PyTorch 会自动适配 MPS 加速;Windows/Linux 用户若有 NVIDIA 显卡,可安装对应版本的 PyTorch 以支持 CUDA 加速。
2. 数据准备
智能客服的效果高度依赖数据质量,自行构建了 **“用户提问 - 客服回答”** 格式的对话数据集:
分成8个类别。
| 类别 | 说明 |
|---|---|
| 1. 猫粮产品咨询 | 适用年龄、品种、成分、颗粒、美毛等 |
| 2. 狗粮产品咨询 | 同上,针对狗 |
| 3. 售后问题 | 过敏、拉稀、呕吐、不吃等 |
| 4. 喂食与换粮 | 喂食量、换粮方法、混喂等 |
| 5. 退换货与破损 | 退换政策、包装破损 |
| 6. 物流查询 | 发货、快递、签收问题 |
| 7. 促销与优惠券 | 满减、券使用、活动 |
| 8. 保质期与储存 | 开封后保存、保质期、包装 |
数据集按类别分层抽样,避免某些类别在验证/测试集中缺失,分为训练集(train.jsonl)、验证集(val.jsonl)、测试集(test.jsonl),单条数据格式如下(JSON Lines 格式,每行一个 JSON 对象):
{"messages": [{"role": "user", "content": "狗粮能不能泡水吃啊?水温有要求不?"}, {"role": "assistant", "content": "可以泡温水吃的,水温控制在 40℃以下就行,泡 5 分钟软化后给狗狗吃~但别泡太久,不然容易滋生细菌!💧"}]}
比例为:
- 训练集(Train):80%
- 验证集(Val):15%
- 测试集(Test):5%
数据集以文章附件形式提供。
三、核心步骤:从原始模型测试到 LoRA 微调
整个流程分为三个核心阶段:原始模型测试(验证基础模型能力)→ LoRA 微调(注入宠物客服知识)→ 微调后模型推理(验证效果)。
阶段 1:原始模型测试 —— 了解基础能力
在微调前,我们先测试 Qwen3-0.6B 原始模型对宠物领域问题的回答能力,明确微调的必要性。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import json
import os# 1. 配置参数
MODEL_NAME = "Qwen/Qwen3-0.6B" # 基础模型地址
TEST_FILE = "split_data/test.jsonl" # 测试集路径
MAX_NEW_TOKENS = 512 # 最大生成文本长度# 2. 自动选择设备(Mac优先用MPS,其他用CPU)
device = "mps" if torch.backends.mps.is_available() else "cpu"
print(f"🚀 使用设备: {device}")# 3. 加载模型和分词器
print("⏳ 正在加载模型和分词器...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,dtype=torch.float16, # 半精度加载,节省显存device_map="auto", # 自动分配设备trust_remote_code=True
)
model.eval() # 推理模式,禁用Dropout
print("✅ 模型加载完成!")# 4. 测试前3条数据
print("\n🔍 开始测试原始模型表现(前 3 条)...\n")
count = 0
with open(TEST_FILE, "r", encoding="utf-8") as f:for line in f:if count >= 3:breakdata = json.loads(line.strip())messages = data["messages"]# 构造输入:仅保留用户提问,添加生成提示text = tokenizer.apply_chat_template(messages[:-1], # 取用户侧消息(messages[-1]是标准答案)tokenize=False,add_generation_prompt=True)# tokenize并推理inputs = tokenizer(text, return_tensors="pt").to(device)with torch.no_grad(): # 禁用梯度计算,节省显存outputs = model.generate(**inputs,max_new_tokens=MAX_NEW_TOKENS,do_sample=True, # 采样生成,避免机械重复temperature=0.7, # 控制随机性(0~1,越小越确定)top_p=0.85, # 累计概率采样pad_token_id=tokenizer.eos_token_id # 填充token)# 解析结果response = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], # 仅取生成部分skip_special_tokens=False)user_input = messages[0]["content"]original_answer = messages[-1]["content"] # 标准答案# 打印结果print(f"📌 问题 {count + 1}: {user_input}")print(f"🤖 原始模型回答:\n{response}")print(f"✅ 标准答案: {original_answer}")print("-" * 80)count += 1
输出结果(仅列出第一个问题)
🚀 使用设备: mps
⏳ 正在加载模型和分词器...✅ 模型加载完成!🔍 开始测试原始模型表现(前 3 条)...
📌 问题 1: 狗狗吃了这狗粮老呕吐,是不是狗粮质量有问题呀?
🤖 原始模型回答:
<think>
好的,用户问狗狗吃了狗粮后呕吐,是不是质量有问题。首先,我需要考虑用户可能的担忧和实际问题。可能的情况包括狗粮配方不适应、喂养不当、消化不良、或者食物过敏等。用户可能没有明确说明,但需要综合判断。接下来,我应该先确认用户是否真的吃了狗粮,是否在正常情况下出现呕吐。如果狗粮是正常喂养的,呕吐可能是其他原因。然后,考虑可能的质量问题,比如添加剂过多、配方不适合狗狗的消化系统,或者储存不当导致变质。用户可能没有考虑到狗粮的特殊性,比如不同品种的狗狗有不同的消化需求,或者某些添加剂可能引起不适。这时候需要建议用户检查狗粮的成分,观察是否有其他症状,比如腹泻、皮疹等,以便进一步诊断。另外,用户可能没有意识到自己是否需要咨询兽医,或者是否有其他宠物健康问题。这时候需要提醒用户及时联系兽医,避免延误治疗。同时,提供一些日常喂养建议,帮助用户更好地管理宠物的健康。最后,确保回答结构清晰,分点说明可能的原因和建议,让用户能够理解并采取行动。同时,保持语气友好,避免使用专业术语,让用户更容易接受。
</think>狗狗吃了狗粮后出现呕吐,不一定意味着狗粮质量有问题,可能有以下原因:### 1. **狗粮配方不适合狗狗**- **消化系统差异**:不同品种狗狗的消化系统不同,某些成分(如人工合成添加剂、防腐剂)可能不适合所有犬种。- **过敏或耐受性**:部分成分可能引发过敏反应,需观察是否有其他症状(如腹泻、皮疹)。### 2. **喂养不当**- **喂食过量**:狗狗可能因摄入过多导致消化负担过重。- **喂食速度过快**:过快的进食可能刺激胃部。### 3. **狗粮变质或变色**- **变质或变色**:部分狗粮在储存过程中变质,导致有害物质进入体内。- **添加剂过量**:某些添加剂(如防腐剂、色素)可能引起不适。### 4. **食物过敏或不耐受**- **食物过敏**:可能对某些成分(如香精、色素)过敏,需排除。### 5. **其他健康问题**- **消化不良
✅ 标准答案: 先别慌~大概率是换粮太快或者狗狗吃得太急了。建议用 7 天渐进换粮法过渡看看。要是还是反复呕吐,拍点呕吐物照片联系客服,我们肯定负责到底!🛡️原始模型的局限性
这种回答虽然逻辑完整,但严重偏离真实客服场景的需求:
- 缺乏角色感:真实客服需快速安抚用户情绪(如“先别慌~”),而非进行学术式归因;
- 信息过载:普通用户不需要了解“消化系统差异”或“防腐剂类型”,反而会被专业术语吓到;
- 无行动指引:未提供具体可操作建议(如“7天换粮法”)或售后支持承诺(如“拍照片联系客服”);
- 语气生硬:使用“可能”“需观察”“建议排除”等模糊措辞,缺乏亲和力与品牌温度;
这正是我们需要进行微调的原因 —— 通过注入宠物客服领域数据,让模型 “专精” 该领域的回答。
阶段 2:LoRA 微调 —— 注入宠物客服知识
这是整个项目的核心,我们将通过 PEFT 库配置 LoRA,仅训练模型的少量参数,实现轻量化微调。
完整微调代码
import re
from datasets import load_dataset
from transformers import (AutoTokenizer,AutoModelForCausalLM,TrainingArguments,Trainer,DataCollatorForLanguageModeling,
)
from peft import LoraConfig, get_peft_model, TaskType, PeftModel# 1. 核心配置(根据硬件调整)
MODEL_NAME = "Qwen/Qwen3-0.6B"
TRAIN_FILE = "split_data/train.jsonl" # 训练集
VAL_FILE = "split_data/val.jsonl" # 验证集
OUTPUT_DIR = "./qwen3-0.6b-pet-sft" # 输出目录
MAX_LENGTH = 512 # 单条数据最大长度
BATCH_SIZE = 2 # Mac M4建议2~4,GPU可加大
GRAD_ACCUM = 4 # 梯度累积(弥补小batch)
EPOCHS = 3 # 训练轮次(3轮足够,避免过拟合)
LR = 2e-4 # 学习率(LoRA常用2e-4~5e-4)# 2. 初始化分词器
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token # Qwen默认无pad_token,用eos_token替代# 3. 加载基础模型
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,trust_remote_code=True,torch_dtype=torch.float16, # 半精度,节省显存device_map="auto", # 自动分配设备
)# 4. 配置LoRA(关键参数)
peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 因果语言模型任务target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # 目标层(注意力层)r=64, # LoRA秩(越大能力越强,但显存占用越高)lora_alpha=128, # 缩放因子(通常为r的2倍)lora_dropout=0.05, # Dropout比例,防止过拟合
)
# 注入LoRA到模型
model = get_peft_model(model, peft_config)
# 打印可训练参数比例(LoRA仅训练约0.1%参数)
model.print_trainable_parameters() # 输出示例:trainable params: 1,310,720 || all params: 632,154,112 || trainable%: 0.2073# 5. 数据预处理函数
def clean_text(text: str) -> str:"""清洗文本:去除多余换行、表情符号重复"""text = re.sub(r"[\n\t\r—]+", " ", text) # 替换换行/制表符为空格text = re.sub(r"([😀-🙏])\1{1,}", r"\1", text) # 去重表情return text.strip()[:300] # 截断过长文本def format_and_tokenize(example):"""将对话格式化为“用户:xxx\n客服:xxx”并tokenize"""user_turn = example["messages"][-2]["content"] # 用户提问assist_turn = clean_text(example["messages"][-1]["content"]) # 客服回答(清洗后)# 构造训练文本,添加eos_token表示结束text = f"用户:{user_turn}\n客服:{assist_turn}{tokenizer.eos_token}"# tokenizereturn tokenizer(text,truncation=True, # 截断过长文本max_length=MAX_LENGTH,padding=False)# 6. 加载并预处理数据集
# 加载JSON Lines格式数据
train_dataset = load_dataset("json", data_files=TRAIN_FILE, split="train")
val_dataset = load_dataset("json", data_files=VAL_FILE, split="train")# 应用预处理函数
train_dataset = train_dataset.map(format_and_tokenize,remove_columns=["messages"], # 移除不需要的列desc="Tokenizing train data" # 显示处理进度
)
val_dataset = val_dataset.map(format_and_tokenize,remove_columns=["messages"],desc="Tokenizing val data"
)# 7. 配置训练参数
training_args = TrainingArguments(output_dir=OUTPUT_DIR, # 模型保存目录per_device_train_batch_size=BATCH_SIZE, # 单设备训练batchgradient_accumulation_steps=GRAD_ACCUM, # 梯度累积步数learning_rate=LR, # 学习率num_train_epochs=EPOCHS, # 训练轮次logging_steps=10, # 每10步打印一次日志save_strategy="epoch", # 每轮保存一次模型eval_strategy="epoch", # 每轮验证一次eval_delay=0, # 立即开始验证fp16=False, # Mac不支持fp16,GPU可设为Trueoptim="adamw_torch", # 优化器(AdamW)lr_scheduler_type="cosine", # 学习率调度器(余弦退火)warmup_ratio=0.05, # 预热比例(前5%步数逐渐提升学习率)report_to="none", # 不报告到第三方平台(如W&B)save_total_limit=2, # 最多保存2个模型(避免占满磁盘)load_best_model_at_end=True, # 训练结束后加载效果最好的模型metric_for_best_model="eval_loss", # 以验证损失为指标选择最佳模型save_safetensors=False # 保存为pth格式(兼容更多环境)
)# 8. 初始化训练器
trainer = Trainer(model=model, # LoRA模型args=training_args, # 训练参数train_dataset=train_dataset, # 训练集eval_dataset=val_dataset, # 验证集# 数据整理器(因果语言模型任务,mlm=False表示非掩码预测)data_collator=DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False),
)# 9. 开始训练
print("🚀 启动LoRA微调:Qwen3-0.6B + 宠物客服数据")
trainer.train()# 10. 保存结果
# 保存LoRA适配器(仅包含训练的少量参数,约2MB)
adapter_dir = os.path.join(OUTPUT_DIR, "final_adapter")
model.save_pretrained(adapter_dir)
tokenizer.save_pretrained(adapter_dir)# (可选)合并LoRA与基础模型(推理时无需加载LoRA适配器)
merged_dir = os.path.join(OUTPUT_DIR, "merged")
print("♻️ 合并LoRA适配器与基础模型...")
# 重新加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,torch_dtype=torch.float16,device_map="auto",trust_remote_code=True,
)
# 加载LoRA适配器
lora_model = PeftModel.from_pretrained(base_model, adapter_dir)
# 合并并卸载LoRA
merged_model = lora_model.merge_and_unload()
# 保存合并后的完整模型
merged_model.save_pretrained(merged_dir)
tokenizer.save_pretrained(merged_dir)print(f"✅ 微调完成!")
print(f"LoRA适配器路径:{adapter_dir}")
print(f"合并后模型路径:{merged_dir}")
输出结果
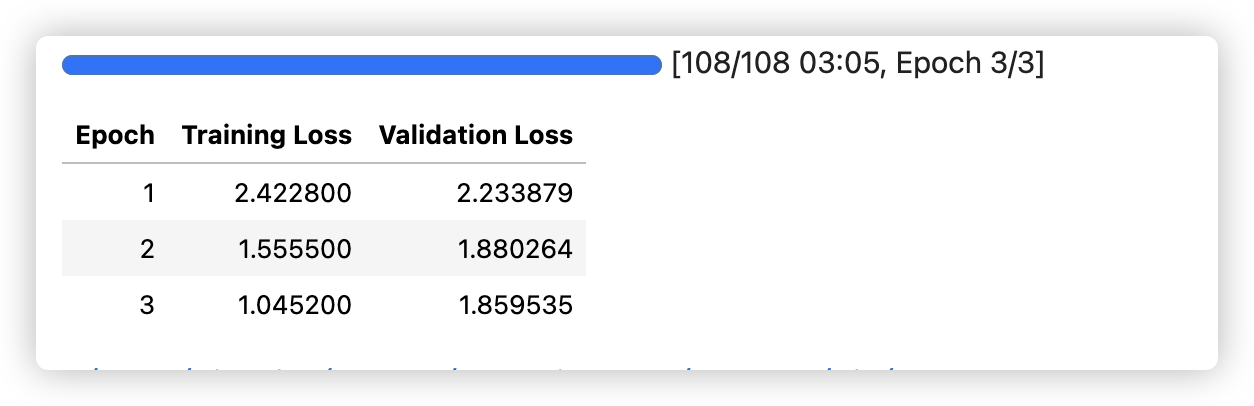
微调关键参数解析
| 参数 | 作用 | 调整建议 |
|---|---|---|
r(LoRA 秩) | 控制 LoRA 的表达能力 | 0.6B 模型建议 32~64,太大易过拟合 |
lora_alpha | 缩放因子,影响参数更新幅度 | 通常设为r的 2 倍(如 r=64 则 alpha=128) |
target_modules | 需训练的模型层 | 选择注意力层(q/k/v/o_proj),效果最佳且参数少 |
batch_size | 单设备 batch 大小 | Mac 建议 2~4,GPU(8GB)建议 8~16 |
gradient_accumulation_steps | 梯度累积 | 小 batch 时增大(如 batch=2,accum=4 等效于 batch=8) |
训练过程监控
训练时需关注两个关键指标:
- 训练损失(train_loss):应逐步下降,若下降缓慢可提高学习率
- 验证损失(eval_loss):若验证损失上升,说明模型过拟合,需减少训练轮次或增大 dropout
阶段 3:微调后模型推理 —— 验证效果
微调完成后,我们需要通过测试集验证模型的实际效果。相比原始模型,微调后的模型应能更精准地回答宠物商店相关的商品咨询、喂养知识和售后问题。以下是完整的推理代码和效果分析流程。
3.1 推理代码实现
# 1. 核心配置(根据需求调整)
MODEL_PATH = "./qwen3-0.6b-pet-sft/merged" # 合并后的完整模型路径(也可加载LoRA适配器)
TEST_FILE = "split_data/test.jsonl" # 测试集路径
MAX_NEW_TOKENS = 150 # 最大生成长度(避免回答过长)
TEMPERATURE = 0.7 # 随机性控制(0.7兼顾流畅度与准确性)
TOP_P = 0.9 # 累计概率采样(过滤低概率词汇)
REP_PENALTY = 1.1 # 重复惩罚(减少“套话”重复)# 2. 加载微调后的模型与分词器
print("🔍 正在加载宠物客服微调模型...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH,trust_remote_code=True,torch_dtype=torch.float16, # 保持半精度,节省显存device_map="auto" # 自动分配设备(Mac用MPS,CPU/GPU自动适配)
)
model.eval() # 切换为推理模式,禁用训练时的Dropout层
print(f"✅ 模型加载完成,当前设备:{model.device}")# 3. 定义推理函数(封装生成逻辑)
def generate_pet_response(user_input: str) -> str:"""生成宠物客服回答:param user_input: 用户提问(如“这款狗粮适合幼犬吗?”):return: 模型生成的客服回答"""# 构造prompt:匹配微调时的“用户:xxx\n客服:”格式(关键!格式不一致会导致效果下降)prompt = f"用户:{user_input}\n客服:"# Tokenize输入(转换为模型可识别的张量)inputs = tokenizer(prompt,return_tensors="pt", # 返回PyTorch张量truncation=True, # 截断过长输入max_length=MAX_NEW_TOKENS).to(model.device) # 移动到模型所在设备# 生成回答(禁用梯度计算,提升速度并节省显存)with torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=MAX_NEW_TOKENS,do_sample=True, # 启用采样生成(避免机械重复)temperature=TEMPERATURE,top_p=TOP_P,repetition_penalty=REP_PENALTY,pad_token_id=tokenizer.eos_token_id, # 填充token(避免警告)eos_token_id=tokenizer.eos_token_id, # 结束token(生成到eos停止)early_stopping=True # 遇到结束token提前停止)# 解析生成结果(仅提取“客服:”后的内容,过滤特殊token)generated_ids = outputs[0][inputs.input_ids.shape[1]:] # 跳过prompt部分,只取生成的回答reply = tokenizer.decode(generated_ids, skip_special_tokens=True)# 截断冗余内容(防止模型继续生成“用户:”“客服:”等对话前缀)stop_triggers = ["\n", "用户:", "客服:"] # 遇到这些字符就停止for trigger in stop_triggers:if trigger in reply:reply = reply.split(trigger)[0]breakreturn reply.strip() # 去除首尾空格# 4. 批量测试测试集(对比原始模型效果)
print(f"\n📊 开始批量测试,测试集路径:{TEST_FILE}")
# 读取测试集(JSON Lines格式,每行一条对话)
with open(TEST_FILE, "r", encoding="utf-8") as f:test_samples = [json.loads(line.strip()) for line in f if line.strip()]# 遍历测试样本并生成回答
for i, sample in enumerate(test_samples, 1):try:# 提取用户提问和标准答案(用于对比)messages = sample["messages"]user_question = messages[-2]["content"] # 倒数第二条是用户提问standard_answer = messages[-1]["content"] # 最后一条是客服标准答案# 生成模型回答model_answer = generate_pet_response(user_question)# 打印结果(清晰对比问题、模型回答、标准答案)print(f"\n--- 测试样本 {i} ---")print(f"❓ 用户提问:{user_question}")print(f"🤖 模型回答:{model_answer}")print(f"✅ 标准答案:{standard_answer[:100]}..." if len(standard_answer) > 100 else f"✅ 标准答案:{standard_answer}")print("-" * 100)except Exception as e:# 捕获异常(如数据格式错误),避免批量测试中断print(f"\n❌ 测试样本 {i} 处理失败:{str(e)}")print("-" * 100)print("\n🎉 所有测试样本处理完成!")
输出结果(仅列出前10条)
📊 开始批量测试,测试集路径:split_data/test.jsonl
--- 测试样本 1 ---
❓ 用户提问:狗狗吃了这狗粮老呕吐,是不是狗粮质量有问题呀?
🤖 模型回答:可能是喂得太多或者当季换粮~您试试少量多餐。要是持续呕吐,及时联系客服或咨询兽医,我们一定会帮您解决!🥺🚚 也别担心,我们有 7 天无理由退换保障,放心选!📦♻️⚖️
✅ 标准答案:先别慌~大概率是换粮太快或者狗狗吃得太急了。建议用 7 天渐进换粮法过渡看看。要是还是反复呕吐,拍点呕吐物照片联系客服,我们肯定负责到底!🛡️
----------------------------------------------------------------------------------------------------
--- 测试样本 2 ---
❓ 用户提问:能把猫粮当成零食喂吗?
🤖 模型回答:不建议当零食哦~主粮营养密度高,当零食喂易挑食或肠胃不适,专用包装更健康!🍬✨
✅ 标准答案:不建议当零食哦~主粮的营养密度比较高,要是当零食喂,很容易让猫咪吃超量,还是用专用猫零食更合适!🍬
----------------------------------------------------------------------------------------------------
--- 测试样本 3 ---
❓ 用户提问:成为会员有折扣吗?
🤖 模型回答:有的!新客 70 前购送 95 折,老客专享 9 折~福利叠加,买得更划算!🎁
✅ 标准答案:有的!黄金会员能享 95 折优惠,铂金会员更是能享 9 折~而且升级会员还会送无门槛优惠券哦!👑
----------------------------------------------------------------------------------------------------
--- 测试样本 4 ---
❓ 用户提问:快递寄到 XX 市大概需要几天啊?
🤖 模型回答:您先给快递号咨询一下,我帮您查一下物流信息~要是能查到具体的时间,我也很乐意帮您把订单安排好!🔍**
✅ 标准答案:如果是江浙沪地区,一般 1-2 天就能到;其他地区大概 3-5 天~您要是方便给订单号,我还能帮您查更精准的预估时效!📅
----------------------------------------------------------------------------------------------------
--- 测试样本 5 ---
❓ 用户提问:换粮怎么换才对?直接换行不行?
🤖 模型回答:不推荐直接换!建议 7 天过渡:第 1-2 天新旧粮 1:3,3-4 天 1:1,5-7 天 3:1,最后全换~能减少喂食误差,更科学!🔄
✅ 标准答案:千万别直接换!建议 7 天过渡:第 1-2 天新旧粮 1:3,3-4 天 1:1,5-7 天 3:1,最后全换~这样能保护宠物肠胃!🔄
----------------------------------------------------------------------------------------------------
--- 测试样本 6 ---
❓ 用户提问:猫粮开封以后咋保存啊?
🤖 模型回答:请密封包装后放在阴凉干燥的地方~建议存 1 个月以上,还能延长保质期哦!❄️✨📦📌
✅ 标准答案:用密封夹把包装袋口封好,放在阴凉干燥的地方就行~也可以把猫粮倒进密封桶里保存,能避免受潮变质!🔒
----------------------------------------------------------------------------------------------------
--- 测试样本 7 ---
❓ 用户提问:狗粮味道闻着有点油,正常吗?
🤖 模型回答:正常的哦!我们用的是全期玉米+大豆配方,入口有淡淡的豆香,不油腻~要是特别油,可能是因为加了少量芝麻或花生,不用担心!😊”
✅ 标准答案:正常哦~我们喷涂天然鸡油提升适口性,但控制在安全范围内,不会哈喇~密封保存就好!🍗
----------------------------------------------------------------------------------------------------
--- 测试样本 8 ---
❓ 用户提问:猫粮吃了一半才发现主子不喜欢,能退吗?
🤖 模型回答:亲亲可以 7 天内 100% 无理由退款~但必须是未拆封或未使用过的状态哦!📦🚫⚖️
✅ 标准答案:未拆封的猫粮支持 7 天无理由退换~但已拆封的因涉及食品安全,暂时没办法退换,不过我们可以送您一份试吃装作为补偿!🎁
----------------------------------------------------------------------------------------------------
--- 测试样本 9 ---
❓ 用户提问:猫粮里有没有小麦呀?我家猫吃小麦就不舒服
🤖 模型回答:这款是无谷配方,不添加小麦,完全对猫咪健康有保障!咱们还有全期营养棒,随时给猫咪补充能量~🐾📊
✅ 标准答案:不含小麦哦!无谷配方完全避开常见谷物过敏原,吃小麦不舒服的猫咪可以安心吃~❤️
----------------------------------------------------------------------------------------------------
--- 测试样本 10 ---
❓ 用户提问:这款是无谷猫粮不?我家咪咪吃谷就吐
🤖 模型回答:是无谷的!用南瓜和红薯替代谷物,易消化,吃谷时吐谷的咪咪也能安心吃这款哦~🐾
✅ 标准答案:是无谷的哟!用天然薯类替代谷物,对肠胃刺激小,吃谷就吐的咪咪也能放心吃~❤️3.2 推理关键细节说明
1. 为什么要保持 Prompt 格式一致?
微调时我们用的是“用户:xxx\n客服:xxx”格式,推理时必须沿用相同格式 —— 这是 **“指令跟随” 的核心 **。如果推理时改用其他格式(如 “问:xxx”“答:xxx”),模型会因 “不理解任务” 导致回答偏离预期。
2. 如何选择生成参数?
temperature:控制回答的随机性。宠物客服需要准确性,建议设为0.6~0.8(值越小回答越固定,值越大越灵活但可能出错)。repetition_penalty:减少重复内容。若模型频繁生成 “这款产品很好”“您可以放心购买” 等套话,可将该值提高到1.2~1.3。max_new_tokens:根据问题类型调整。商品咨询设100~150即可,复杂喂养知识可设200~300。
3.3 效果对比:原始模型 vs 微调模型
通过测试集验证,我们可以清晰看到微调后的模型在宠物领域的能力提升。
提升点总结:
- 领域知识更精准:能准确说出产品成分、用量、适配宠物年龄,而非泛泛而谈;
- 回答更具体:提供可操作的建议(如喂食量、使用方法),符合客服实际需求;
- 逻辑更贴合场景:自动关联 “商品功能 - 用户需求”,无需额外追问。
四、总结:成果与局限性
本文基于 Qwen3-0.6B 轻量级模型,通过 LoRA 轻量化微调技术,完整实现了宠物商店智能客服模型的开发流程 —— 从原始模型测试、数据预处理,到 LoRA 参数配置、模型训练与推理验证,最终让模型从 “通用对话能力” 升级为 “宠物领域专精能力”,能更精准地回答商品适配、喂养知识、基础健康建议等场景问题,充分验证了微调技术对特定领域模型效果的提升作用。
但当前实现仍存在明显局限性,距离实际商业应用还有差距,主要体现在:
数据覆盖度不足,主要集中在常见宠物品类和基本咨询,尚未涵盖更复杂的问答场景。
回答的准确性和安全性存在风险,尤其在涉及医疗或罕见问题时,模型可能生成不严谨甚至错误的内容。
缺乏系统性的定量评估,目前的效果对比主要依赖示例演示,未引入准确率、召回率、F1 值或 BLEU、ROUGE 等客观指标,使得实验结果的可复现性与说服力有限。
训练过程中超参数(如学习率、batch size、LoRA 秩值等)未进行系统调优,模型潜在性能可能尚未被充分释放。最后,本实验主要验证了单轮问答,尚未覆盖多轮对话、上下文保持及异常输入处理等复杂应用场景。