建网站是自己做还是用CMS邢台做网站咨询
SparkSession
定义与功能:SparkSession是Spark SQL的入口,封装SparkContext,提供了创建DataFrame和执行SQL的能力。它实质上是SQLContext和HiveContext的组合,因此兼容这两者的API。
创建方式:在使用spark-shell时,Spark会自动创建一个名为spark的SparkSession对象。在程序中,可以通过SparkSession.builder().appName("AppName").getOrCreate()方法创建。DataFrame的创建与操作
创建方式:
从数据源创建:支持从多种数据源(如JSON、Parquet、JDBC等)读取数据并创建DataFrame。
从RDD转换:可以通过调用RDD的toDF()方法,并指定schema信息,将RDD转换为DataFrame。
从Hive表查询:在HiveContext下,可以通过SQL查询Hive表并返回DataFrame。
操作:DataFrame API提供了丰富的transformation和action操作,允许用户对数据进行各种转换和查询。

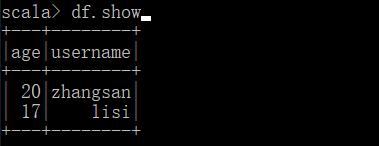
SQL语法与视图
临时视图与全局视图:
临时视图:通过DataFrame的createOrReplaceTempView()方法创建,只在当前SparkSession中有效。
全局视图:通过createGlobalTempView()方法创建,在所有SparkSession中共享,但需要在配置文件中指定Hive相关信息。
SQL查询:在创建了视图后,可以使用SparkSession的sql()方法执行SQL查询,并返回查询结果的DataFrame。



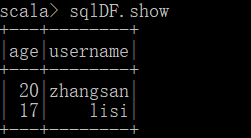
数据类型与兼容性
数据类型:Spark SQL支持多种数据类型,包括基本数据类型(如Int、String等)和复杂数据类型(如Struct、Array、Map等)。
兼容性:Spark SQL不仅兼容Hive,还支持从RDD、Parquet文件、JSON文件等多种数据源获取数据,未来版本甚至支持获取RDBMS数据以及Cassandra等NOSQL数据。
总结
Spark-SQL核心编程涉及SparkSession的创建与使用、DataFrame的创建与操作、SQL语法与视图的应用以及数据类型与兼容性等多个方面。通过掌握这些核心知识点,开发人员可以更加高效地使用Spark SQL进行数据处理和查询。
DataFrame 的 DSL 语法
Spark SQL 的 DataFrame 提供了一个特定领域语言(DSL)来管理结构化的数据。在 Scala、Java、Python 和 R 中均可使用此 DSL,无需创建临时视图即可进行数据操作。
创建 DataFrame
使用 spark.read 方法从多种数据源(如 JSON 文件)创建 DataFrame。
查看 DataFrame 信息
printSchema:查看 DataFrame 的 schema 信息。
show:展示 DataFrame 中的数据。
数据选择
select:通过列名或列表达式选择数据。可以使用 $ 符号或单引号表达式来引用列。
数据过滤
filter:根据条件过滤数据。
数据分组与聚合
groupBy:按指定列分组。
count:统计分组后的数据条数。
RDD 与 DataFrame 之间的转换
RDD 转换为 DataFrame
![]()
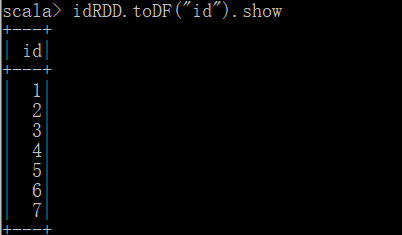
在 IDEA 中开发时,需要引入 import spark.implicits._。
可以使用 toDF 方法将 RDD 转换为 DataFrame,通常需要先定义一个样例类来表示数据结构。
DataFrame 转换为 RDD
DataFrame 是对 RDD 的封装,可以直接调用 rdd 方法获取内部的 RDD。
转换后的 RDD 存储类型为 Row,可以通过 getAs 方法获取特定列的数据。
使用场景与优势
使用场景:适用于需要对结构化数据进行高效查询和处理的场景,如数据分析、数据清洗等。
优势:
易用性:DataFrame API 提供了简洁且强大的数据操作能力,降低了开发难度。
性能优化:Spark SQL 的优化执行引擎能够自动进行多种优化作,提高查询性能。
兼容性:兼容 Hive,可以在已有的 Hive 仓库上直接运行 SQL 或 HQL。
定义:DataSet是具有强类型的数据集合,需要提供对应的类型信息。它是Spark 1.6版本中引入的一个新的数据抽象,旨在提供比RDD更高层次的抽象和更多的优化机会。
特点:DataSet与RDD和DataFrame共享许多共性,如惰性执行、自动缓存、分区等。但DataSet的每一行都有具体的类型,这提供了比DataFrame更丰富的类型信息和更强的类型安全性。
DataSet的创建与操作
创建方式:
使用样例类序列创建:通过定义样例类,并使用Seq的toDS()方法将序列转换为DataSet。
使用基本类型的序列创建:虽然不常见,但也可以将基本类型的序列(如SeqInt])转换为DataSet。
从RDD转换:SparkSQL能够自动将包含有case类的RDD转换成DataSet。
操作:DataSet API提供了与DataFrame相似的transformation和action操作,但由于DataSet具有强类型,因此在进行操作时可以获得更好的类型检查和编译时错误提示。
DataFrame与DataSet的转换与关系
转换:
DataFrame转换为DataSet:通过调用DataFrame的asT]()方法,可以将DataFrame转换为特定类型的DataSet。
DataSet转换为DataFrame:通过调用DataSet的toDF()方法,可以将DataSet转换回DataFrame。
关系:
共性:DataFrame和DataSet都是Spark平台下的分布式弹性数据集,它们共享许多共性,如惰性执行、自动缓存、分区等。同时,它们也都支持Spark SQL的操作,如select、groupby等。
区别:主要区别在于每一行的数据类型。DataFrame的每一行是Row类型,而DataSet的每一行是用户自定义的类型(通常是case类)。因此,DataSet提供了比DataFrame更丰富的类型信息和更强的类型安全性。
RDD、DataFrame、DataSet三者的对比与选择
对比:
RDD:提供了低级别的抽象,允许用户以任意方式操作数据。但由于缺乏类型信息,RDD的API相对较为繁琐,且容易出错。
DataFrame:提供了高级别的抽象,以Row和Schema的形式组织数据。虽然比RDD更易于使用,但仍然缺乏类型安全性。
DataSet:结合了RDD的低级别操作和DataFrame的高级别抽象,同时提供了类型安全性。是处理结构化数据的首选方式。
选择:
在处理结构化数据时,应优先考虑使用DataSet。因为它提供了类型安全性,并且API更加简洁易用。
在需要低级别操作或处理非结构化数据时,可以考虑使用RDD。
DataFrame可以作为DataSet的特例(即DatasetRow])来使用,但在需要类型安全性时应转换为DataSet。
总结
Spark-SQL核心编程(三)主要涉及DataSet的创建与操作、DataFrame与DataSet的转换与关系以及RDD、DataFrame、DataSet三者的对比与选择。通过掌握这些核心知识点,开发人员可以更加高效地使用Spark SQL进行结构化数据的处理和查询。