【MySQL】性能优化与核心机制深度解析
简介
本文将系统性地深入探讨MySQL数据库的性能优化实践、索引核心原理、事务机制以及高可用架构设计。内容涵盖慢查询定位、索引数据结构、事务特性、日志系统、MVCC、主从同步和分库分表等关键主题。
一、性能瓶颈定位:慢查询分析与SQL执行剖析
1. 如何定位慢查询
慢查询是数据库性能优化的首要切入点。MySQL提供了内建的慢查询日志(Slow Query Log)来辅助定位。
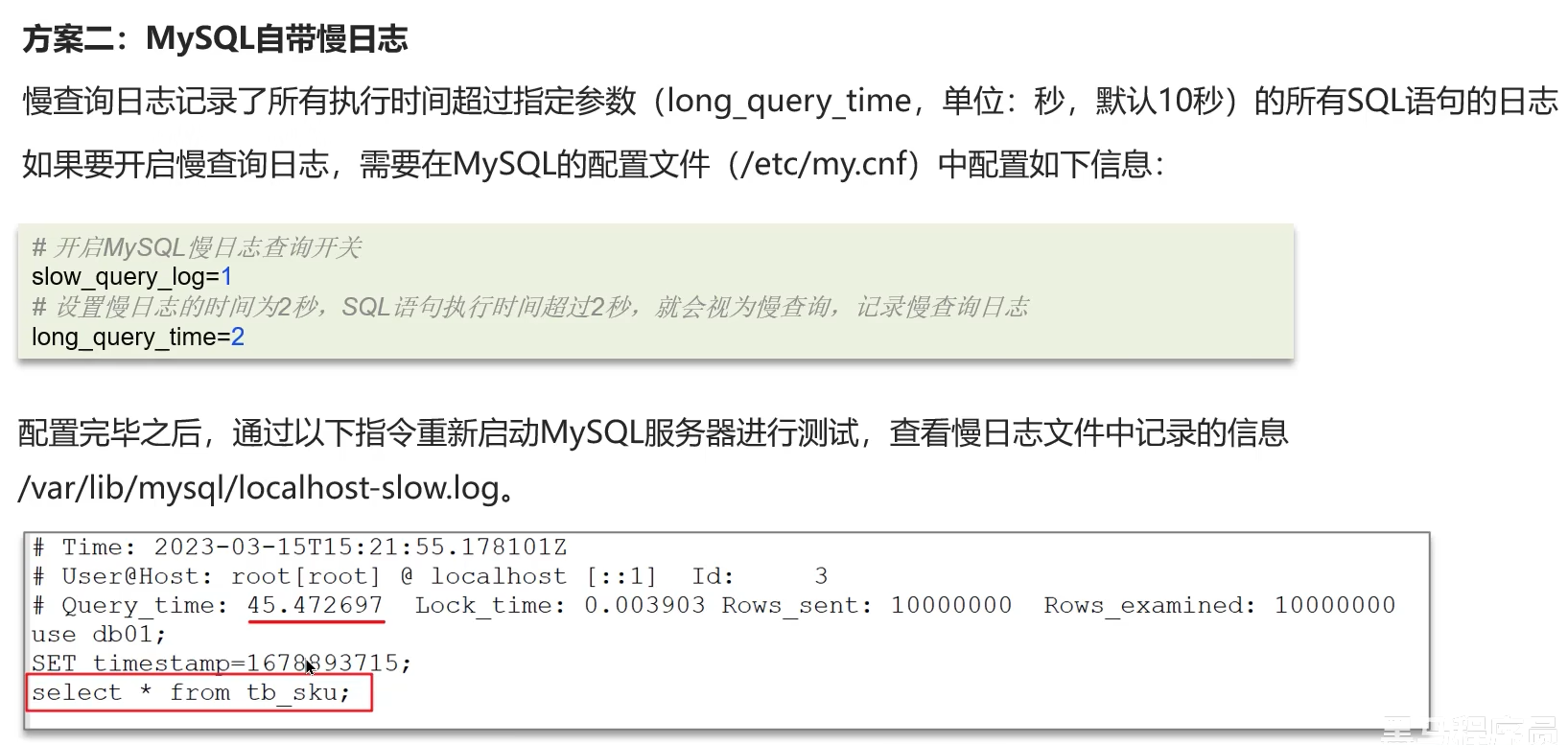
注意开启MySQL日志定位慢查询只能在测试阶段,因为在实际开发中会降低效率
- 开启与配置:
# 在my.cnf或my.ini配置文件中slow_query_log = 1slow_query_log_file = /var/lib/mysql/mysql-slow.loglong_query_time = 2 # 定义慢查询阈值(单位:秒)log_queries_not_using_indexes = 1 # 记录未使用索引的查询配置后需重启MySQL服务或使用`SET GLOBAL`命令动态启用。
- 日志分析:
- 使用MySQL自带工具
mysqldumpslow进行快速分析: -
mysqldumpslow -s t -t 10 /path/to/slow.log # 按时间排序,显示最慢的10条
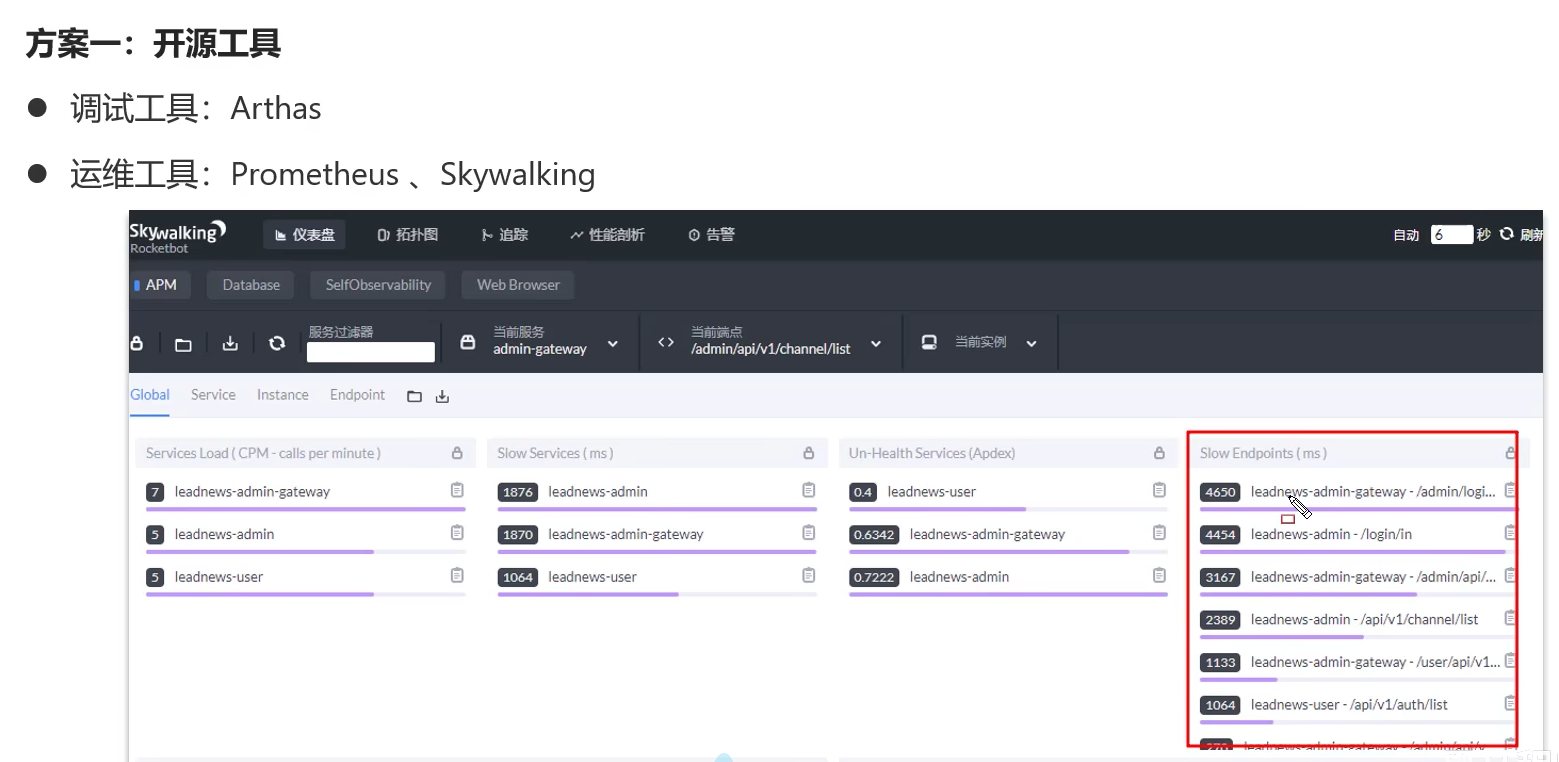
- 使用MySQL自带工具
* 使用高级工具(Arthas或者prometheus、Skywalking)进行深度分析,它能提供更详细的统计信息和优化建议。
2. SQL执行很慢如何分析?
一条SQL语句的执行过程可以简化为以下流程,其性能瓶颈可能出现在任何一个环节:

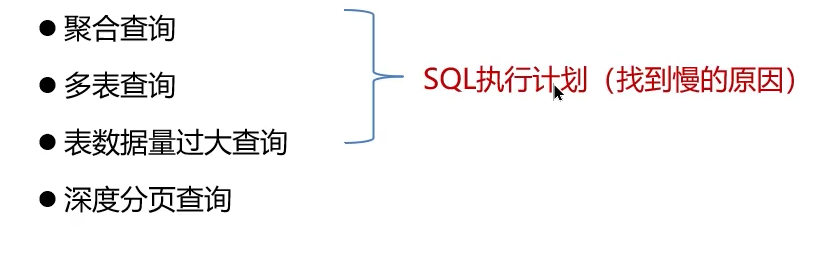
-
使用
EXPLAIN诊断执行计划:这是分析SQL性能的最重要工具。执行EXPLAIN SELECT ...或EXPLAIN FORMAT=JSON SELECT ...来查看MySQL的查询计划。重点关注以下字段:- type:访问类型。从优到差:
system>const>eq_ref>ref>range>index>ALL。出现ALL(全表扫描)或index(全索引扫描)通常需要优化。 - key:实际使用的索引。如果为
NULL,则表示未使用索引。 - rows:MySQL预估需要扫描的行数。值越大,性能越差。
- Extra:额外信息。
Using filesort(无法利用索引排序)、Using temporary(使用了临时表)、Using where(在存储引擎层后过滤)是常见性能瓶颈点。而Using index(使用覆盖索引)是良好信号。
- type:访问类型。从优到差:
-
检查系统状态:
- 确认是否命中索引:通过
EXPLAIN的key字段判断。 - 检查缓冲池命中率:通过监控
Innodb_buffer_pool_reads(从磁盘读取的次数)和Innodb_buffer_pool_read_requests(总读取请求数)来计算命中率。命中率低意味着大量磁盘I/O,是性能杀手。 - 检查锁竞争:使用
SHOW ENGINE INNODB STATUS或查询information_schema.INNODB_LOCKS和INNODB_LOCK_WAITS表,查看是否有阻塞性锁。
- 确认是否命中索引:通过

type最好控制在range之前的类型
3、排查的方向:
4.小结

二、索引:数据库性能的基石
1. 索引概念及底层数据结构
索引是帮助MySQL高效获取数据的排好序的数据结构。它就像书本的目录,能极大加速数据检索速度。
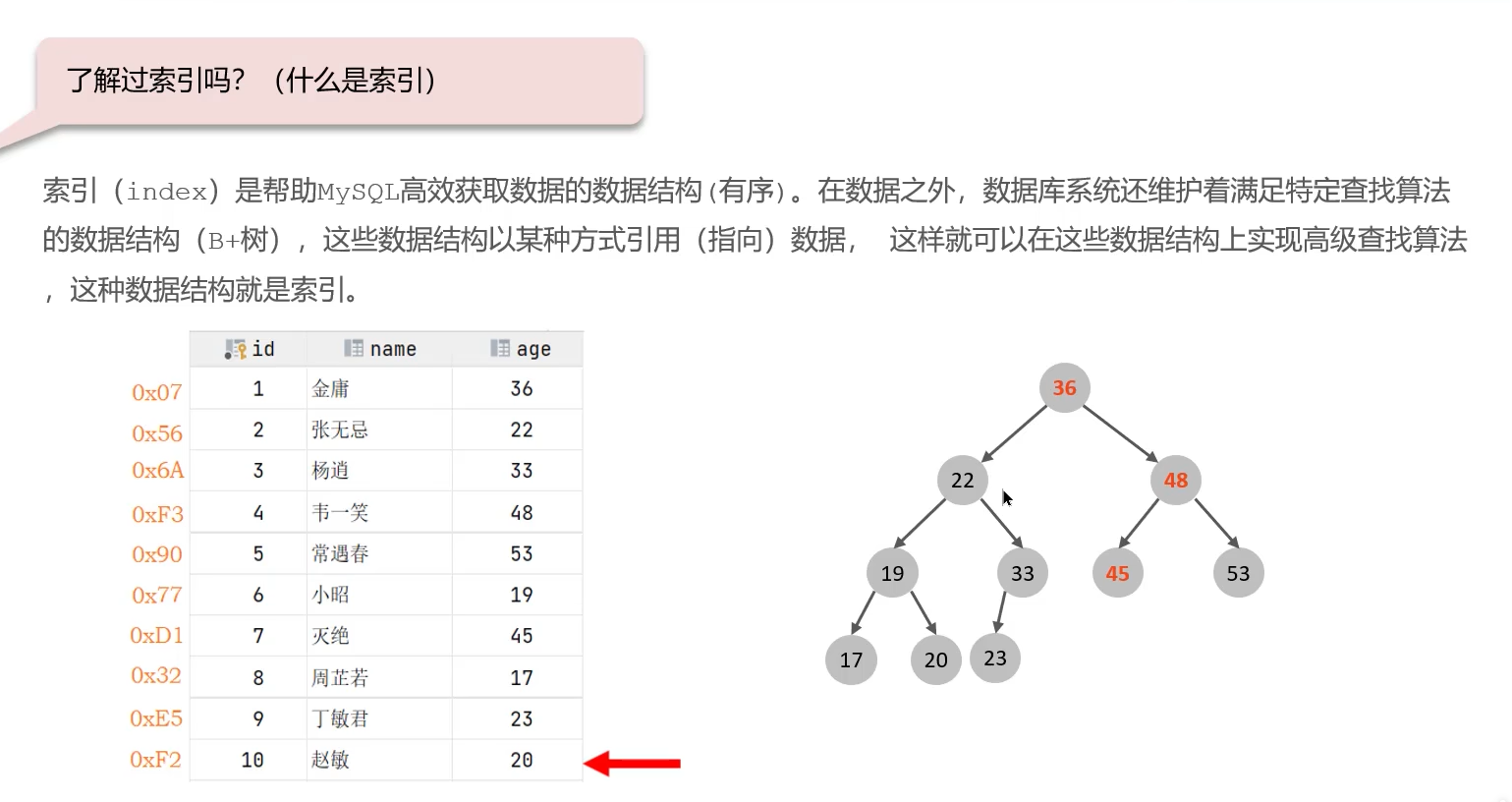
MySQL中InnoDB存储引擎的索引基于B+Tree数据结构实现。其优势在于:
- 矮胖平衡:树的高度低,通常只需3-4次磁盘I/O就能定位到数据,查询效率稳定。
- 有序存储:所有数据都存储在叶子节点,且叶子节点之间通过指针相连,非常适合范围查询和排序操作。
- 非叶子节点只存键值:单个节点可以容纳更多索引项,进一步降低树的高度。
拓展: 数据结构对比
二叉树和红黑树