构建生产级多模态数据集:视觉与视频模型(参照LLaVA-OneVision-Data和VideoChat2)
构建生产级多模态数据集:视觉与视频模型
一、构建自定义图文数据集
1. 基础结构
LLaVA-OneVision-Data-SAE 的结构
[{"image": "CLEVR-Math/identity_1040.jpg","conversations": [{"from": "human","value": "<image>\nHint: Please answer the question and provide the final answer at the end.\nQuestion: Subtract all balls. How many objects are left?"},{"from": "gpt","value": "The answer is 7"}]}]
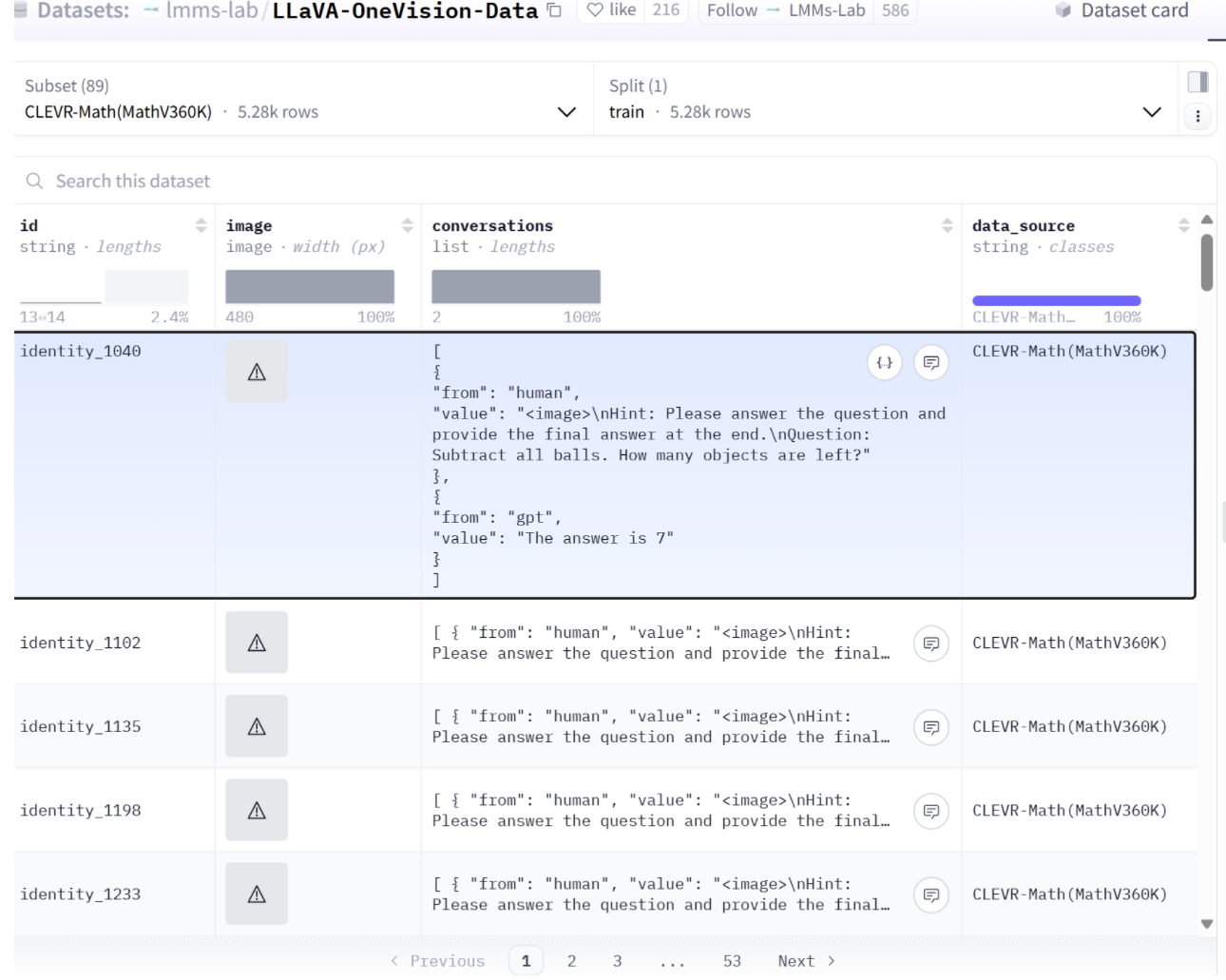
表1:图文对话数据模式
| 字段名 | 数据类型 | 是否必须 | 描述 | 示例 |
|---|---|---|---|---|
| id | String | 可选 | 样本的唯一标识符,可用于追踪和调试。 | “image_0001_conv_1” |
| image | String | 是 | 关联的图像文件名(相对路径)。 | “0001.jpg” |
| conversations | List[Object] | 是 | 一个包含多轮对话的列表。 | [{“from”: “human”, “value”: “…”}, {“from”: “gpt”, “value”: “…”}] |
| conversations.from | String | 是 | 对话发起者的角色。推荐使用"human"和"gpt"以区分用户输入和模型生成。 | “human” |
| conversations.value | String | 是 | 该轮对话的具体文本内容。对于第一轮的用户输入,通常包含一个特殊的图像占位符 。 | “请描述图中的主要物体。\n” |
1.2 自定义图片描述信息标注指南
自定义标注的核心是为你的图像生成高质量的 (instruction, output)对
| 任务类型 | 指令模板示例 | 期望输出示例 |
|---|---|---|
| 简单描述 | “描述这张图片。” | “一张城市夜景的照片,高楼灯火通明。” |
| 详细描述 | “详细描述图片中的场景、物体和它们的属性。” | “照片近处是一杯咖啡,杯上有拉花…” |
| 视觉问答 (VQA) | “图片中有几只动物?” | “两只。” |
| 推理问答 | “这个人为什么穿着雨衣?” | “因为正在下雨。” |
| 多图比较 | “比较这两张图片的风格。” | “图一更写实,图二更抽象。” |
2. 生成高质量的回答(Output)
回答的质量直接决定模型的学习效果。
-
准确性:回答必须严格基于图像事实,避免幻觉。
-
完整性:对于复杂问题,回答应覆盖所有方面。
-
清晰简洁:避免冗余信息,语言流畅,语法正确。
-
图像占位符:在用户的第一轮提问中,必须包含一个特殊的占位符(如),以在文本中明确指示图像信息的位置。这有助于训练脚本识别和处理多模态输入。
-
负样本构建:数据集中必须包含模型应该拒绝回答的场景。这对于提升模型的安全性和可靠性至关重要。例如:
○ 内容缺失:当被问及图片中不存在的物体时,模型应回答无法找到或图中没有该物体。
○ 不当问题:对于涉及隐私、偏见或有害内容的问题,模型应礼貌地拒绝回答。
3. 数据质量控制
-
图像质量:分辨率建议不低于512px,剔除模糊、失真的图像。
-
图文相关性:确保文本描述与图像内容高度匹配,可通过CLIP等模型辅助过滤。
-
多样性:确保数据覆盖多个领域和场景避免类别失衡。
标注流程
4.标注流程
-
预训练模型生成:使用 Qwen、Kimi 等模型生成描述或答案,再进行人工审核和修正,是效率较高的方法。
-
人工标注:人工质检模型标注后的结果,错误地方给出修正。
-
合成数据:对于特定任务(如图像编辑),可利用大语言模型生成指令,再用文本到图像模型(如Stable Diffusion)生成对应图像,构建三元组数据。
5. 图片存储格式:从JPG到分片Parquet
图片需要将原始的JPG图像和JSON格式的标注,转换为可用于大规模训练的分片式Apache Parquet数据集。整个流程将以Hugging Face datasets库作为核心工具。
工作流程:
-
**组织图像文件**:将所有JPG图像文件存放在一个目录下,例如 data/images/。 -
**创建元数据文件**:在data/目录下创建一个名为metadata.jsonl的文件。JSON Lines (.jsonl) 格式要求每一行都是一个独立的、完整的JSON对象。 -
**关联元数据与图像**:metadata.jsonl中的每个JSON对象都对应一个图像。至关重要的是,每个对象都必须包含一个file_name字段,其值是图像文件相对于metadata.jsonl文件的路径 3。
一个metadata.jsonl文件的行示例如下:
JSON
{"file_name": "images/0001.jpg", "id": "image_0001_conv_1", "conversations": "[{\"from\":
\"human\", \"value\": \"<image>\\n请描述图中的场景。\"},
{\"from\": \"gpt\", \"value\": \"图中展示了一个阳光明媚的午后公园,几个人在草地上野餐。\"}]"}
-
使用datasets进行数据摄取与转换
-
序列化为分片Parquet
-
Parquet格式介绍:
● 卓越的性能:Parquet是一种基于Apache Arrow的列式存储格式 。与行式存储(如CSV或JSON)不同,列式存储允许数据加载器只读取其需要的列。例如,在进行数据探索或调试时,可以只加载文本
conversations列,而完全跳过体积庞大的图像数据,从而实现数量级的读取速度提升。
● 高效的压缩:Parquet支持多种高效的压缩算法(如Snappy, Gzip, Zstd),能够显著减小数据集的存储体积,从而降低存储成本和网络传输时间。
● 强大的生态系统兼容性:Parquet是大数据生态系统中的事实标准,与Apache Spark, Dask 18, Pandas等工具无缝集成,极大地简化了下游的数据分析和处理任务。
● 分片(Sharding)策略:将大型数据集切分为多个较小的Parquet文件(即分片)是一种关键的优化策略。
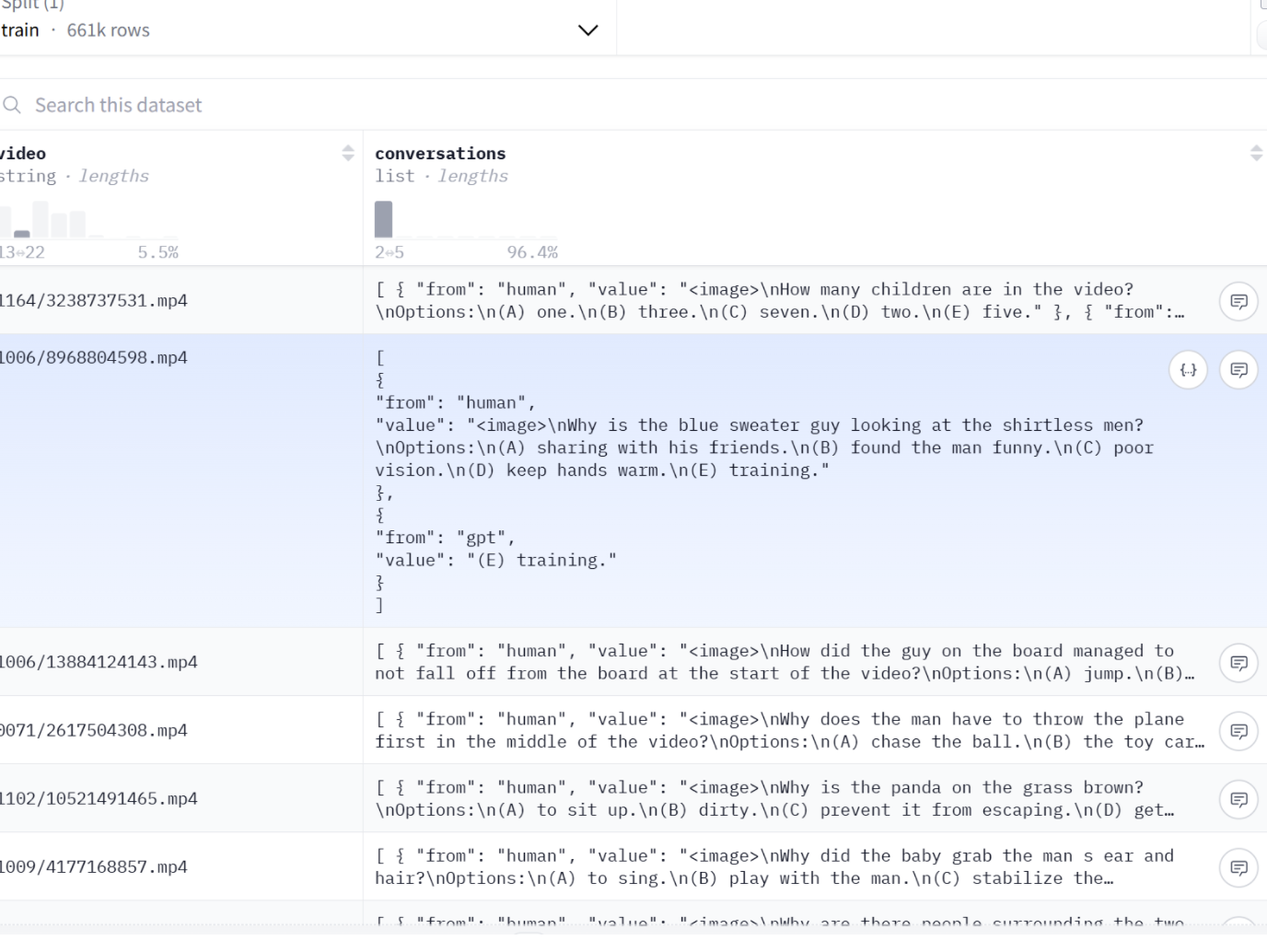
二、构建用于视频语言模型的数据集
VideoChat2 的训练数据通常以 JSON 格式组织,这是一种灵活且高效的结构化文本格式,非常适合存储大量的多模态训练样本。
2.1. 时间维度标注
原始数据格式展示
[{"video": "1164/3238737531.mp4","conversations": [{"from": "human","value": "<image>\nHow many children are in the video?\nOptions:\n(A) one.\n(B) three.\n(C) seven.\n(D) two.\n(E) five."},{"from": "gpt","value": "(D) two."}]}]
| 字段名 | 数据类型 | 是否必须 | 描述 | 示例 |
|---|---|---|---|---|
| video | String | 是 | 视频文件的路径或唯一标识符。系统会根据此路径加载视频片段 | “1164/3238737531.mp4” |
| conversations | List[Object] | 是 | 一个包含多轮对话的列表。 | [{“from”: “human”, “value”: “…”}, {“from”: “gpt”, “value”: “…”}] |
| conversations.from | String | 是 | 对话发起者的角色。推荐使用"human"和"gpt"以区分用户输入和模型生成。 | “human” |
| conversations.value | String | 是 | 该轮对话的具体文本内容。对于第一轮的用户输入,通常包含一个特殊的图像占位符 。 | “请描述图中的主要物体。\n” |
与静态图像不同,视频的核心在于其时间维度。对视频的标注必须能够捕捉随时间展开的动作、事件和场景变化。LLaVA-Video-178K等数据集中的标注就体现了这一点,其描述是叙事性的,捕捉了一系列连续的动作,例如:“一个人……进入画面……蹲下……然后站起来……并离开画面” 。
实现更高级的功能,例如回答“视频的第5秒到第10秒之间发生了什么?”这类问题,需要一种结构化的标注方法。推荐采用一种分段事件的模式,将整个视频的描述分解为一系列带有时间戳的事件片段。
2.2标注指南:
标注员在创建时间描述时应遵循以下原则:
● 关注动态变化:重点描述动作、对象/角色间的互动,以及场景状态的显著变化。
● 使用一致术语:对于视频中反复出现的关键对象或人物,使用统一的名称。
● 按时间顺序描述:严格按照事件在视频中发生的先后顺序进行描述。
● 明确起止点:为每个独立的事件或动作片段标注清晰的开始和结束时间(以秒为单位)