【C++】:模板进阶
希望文章能对你有所帮助,有不足的地方请在评论区留言指正,一起交流学习!
目录
1.非类型模板参数
1.1.非类型模板参数介绍
1.2.按需实例化
1.3.array容器
2.模板的特化
2.1.引入
2.2.函数模板特化
2.3.类模板的特化
3.模板的分离和编译
3.1 什么是分离编译
3.2 模板的分离编译
3.3.如何解决
本篇博客讲述模板的非类型模板参数、模板的特化以及类模板的定义和声明分离。模板的初阶知识点,可以看C++模板初阶-CSDN博客这篇博客了解一下。
1.非类型模板参数
1.1.非类型模板参数介绍
对于固定大小的数据结构,对于以前的定义数据结构大小的方式,是在类的前面使用#define定义一个宏,但是对于不同情况下的需要的数据结构大小的是无法做出灵活的调整。define的方式是简单的替换,当需要创建另一个大小不一样的数据结构的时候,还需要重整一遍#define以及数据结构的类,造成代码的冗余。
在此引入了非类型模板参数,非类型模板参数不是类型,而是模板定义中接受 编译器常量值;
- 参数值必须在编译器期间期间确定,
- 非类型模板参数在模板的内部是常量(无法修改);
- 不同的值也会生成一个完全独立的模板
- 非类型模板参数只能是整数 int或者char
非类型模板参数像 “家具的固定尺寸”(如定制衣柜的宽度1.8m、高度
2.4m)—— 尺寸在生产前(编译期)确定,生产后(实例化后)不可修改;类型模板参数像 “家具的材质”(如实木、板材),不同材质对应不同生产工艺(不同实例)。
例子:创建一个固定的数组类。以栈为例子:
template <class T>
class stack
{
public://仅仅演示,成员函数不写啦
private:T _a[N];//开辟空间大小size_t _size;//栈中元素数量T _top;//栈顶元素
};int main()
{stack<int> a;//固定大小为10 stack<int> b;//固定大小为10 ,但是10无法满足要50或者更大的return 0;
}假如a的栈大小为10 就可以决定了,但是对于b需要更大的栈,如何解决,是写一些新的栈再定义一个新的宏,还是有别的方式?那就是非类型模板参数。
template <class T, int N = 10>
class stack
{
public://仅仅演示,成员函数不写啦private:T _a[N];//开辟空间大小size_t _size;//栈中元素数量T _top;//栈顶元素
};int main()
{stack<int, 10> a; //固定大小为10stack<int, 50> b; //固定大小为50 stack<int, 10> c; //使用缺省值固定大小为10return 0;
}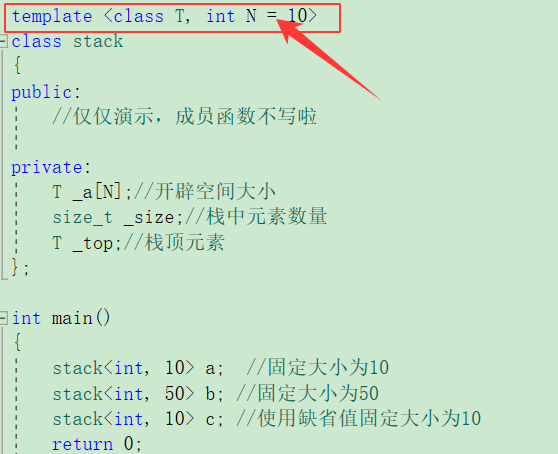
就是上述的的箭头指向,在使用的时候给整型常量就可以。
1.2.按需实例化
证明N是一个常量
按需实例化,
在 C++ 中,模板本身不会生成任何可执行代码,只有当你真正使用(实例化)它时,编译器才会生成对应的代码。这种只在需要时才生成代码的机制,就叫 按需实例化(也叫延迟实例化)。
在上述的程序执行中,没有出现错误。

但是在增加上述函数的调用之后,就会报错程序崩溃。就是按需实例化用的时候才生成代码。和显示实例化不同,强制编译器生成某个模板实例,即使没用到。
此时报错,证明了N是一个常量在类中
1.3.array容器
在这里我要介绍一个STL中的容器array,因为他就是采用了非类型模板参数
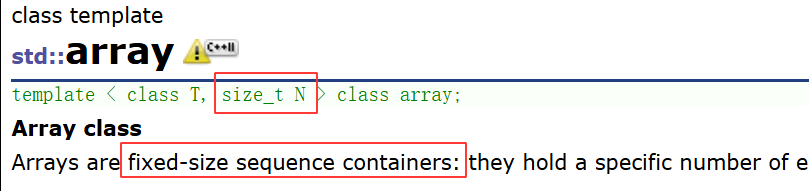
arrayC++11增加的是固定长度的大小数组的容器,比较鸡肋。和C语言的原生数组一样,不初始化,区别就是array会检测访问越界。而原生数组的读取时候检测不到,在写入的时候可能检测到。array - C++ Reference。
相较于array可以使用vector来创建数组,而且还初始化了空间数据。所以说array是比较鸡肋的容器。
C++委员会很好的,和其他语言的区别优点:好用贴近操作系统,比java快
C++没有处网络库,搭建网络,有许多鸡肋的问题 array和C语言的原生数组一样,都没有初始化对检查越界十分严格,原生数组是不会检查越界读取检测不出来,写一部分可以检测出来。没有越界检测就没有什么区别。
可以使用vector 可以检查,还可以初始化
vector在堆上 arrary在栈上。多了一个指针,实际当中没有人用的。
array
[ int, int, int, ... (共10个int) ] // 直接在栈上
- 没有额外指针
- 大小固定,编译期已知
- 生命周期随作用域结束而销毁
vector<int>>
vector对象: { pointer, size, capacity } // 在栈上│▼[ int, int, int, ... ] // 在堆上
- 多了三个成员变量:
pointer:指向堆内存size:元素个数capacity:容量- 内存分配在堆上,可以动态扩容
2.模板的特化
2.1.引入
#include <iostream>
using namespace std;
template <class T>
bool Greater(const T& x, const T& y)
{return x > y;
}
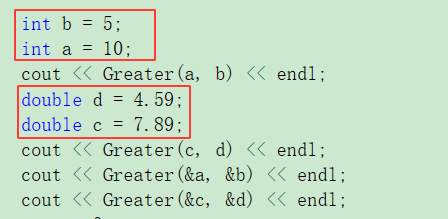
int main()
{int a = 10;int b = 5;cout << Greater(a, b) << endl;double c = 7.89;double d = 4.59;cout << Greater(c, d) << endl;cout << Greater(&a, &b) << endl;cout << Greater(&c, &d) << endl;return 0;
}上述程序运行的结果如下,

运行的结果是对的,按照我们的思路来,传递a b c d对比就是其值的大小,而不是其地址的大小,但是其比较的值是正确的那么大家在看一下下面的程序
将 a和b以及d和c创建的顺序调换,程序的输出结果就会改变。下面两个比较就是地址。

但是我们想比较就是二者的值。所以怎么办呢?
如何在创建一个模板参数,适配这种特殊类型的应用?
2.2.函数模板特化
函数模板的特化步骤:
1. 必须要先有一个基础的函数模板
2. 关键字template后面接一对空的尖括号<>
3. 函数名后跟一对尖括号,尖括号中指定需要特化的类型
4. 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
bool Greater(T x, T y)
{return x > y;
}
//函数模板的特化
template <>
bool Greater<int*>(int* x, int* y)
{return *x > *y;
}
上述的程序就是函数模板的特化,专门为int*特化的函数,但是建议大家不要使用特化了,另写一个函数或者另写一个函数模板都是一样的。
bool Greater(int* x, int* y)
{return *x > *y;
}
template <class T>
bool Greater(T* x, T* y)
{return *x > *y;
}上述两个一个为函数,一个为函数模板,可以更加清晰表明函数的用途,所以不仅以使用函数的特化,而且模板的特化要求形参表也相同,导致const修饰的引用或者指针,傻傻的分不清。
这里还有一个小的知识点就是函数的调用顺序问题,有现成的函数调用现成的函数,有更加符合条件的函数模板嗲用函数模板。后者是存在隐式理性转换的情况。
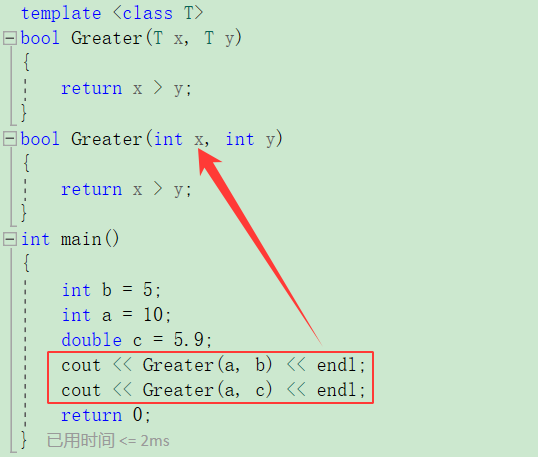
有现成的函数就调用现成,没有现成的就调用最匹配的,第二次调用函数的时候,存在类型转换了,不适合模板。
2.3.类模板的特化
(1)全特化
将类的所有的模板参数特化为确定的数据类型。
template<class T1, class T2>
class Data
{
public:Data() { cout << "Data<T1, T2>" << endl; }
private:T1 _d1;T2 _d2;
};
//全特化
template<>
class Data<int, char>
{
public:Data() { cout << "Data<int, char>" << endl; }
private:int _d1;char _d2;
};
int main()
{Data<int, int> d1;Data<int, char> d2;
}2.偏特化
- 偏特化 将类的部分的模板参数特化为确定的数据类型
偏特化并不仅仅是指特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版本。
第一种情况偏特化 将类的部分的模板参数特化为确定的数据类型
#include <iostream>
using namespace std;
template<class T1, class T2>
class Data
{
public:Data() { cout << "Data<T1, T2>" << endl; }
private:T1 _d1;T2 _d2;
};
第二种情况:偏特化并不仅仅是指特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版本。
//两个参数偏特化为指针类型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public:Data() { cout << "Data<T1*, T2*>" << endl; }private:T1 _d1;T2 _d2;
};
//两个参数偏特化为引用类型
template <typename T1, typename T2>
class Data <T1&, T2&>
{
public:Data(const T1& d1, const T2& d2): _d1(d1), _d2(d2){cout << "Data<T1&, T2&>" << endl;}private:const T1 & _d1;const T2 & _d2;
};类模板特化实例,
我们以Date类例子 排升序利用sort以及Less的仿函数来达到排升序的目的
template<class T>
struct Less
{bool operator()(const T& x, const T& y) const{return x < y;}
};int main()
{Date d1(2022, 7, 7);Date d2(2022, 7, 6);Date d3(2022, 7, 8);vector<Date> v1;v1.push_back(d1);v1.push_back(d2);v1.push_back(d3);sort(v1.begin(), v1.end(), Less<Date>());auto it = v1.begin();while (it != v1.end()){cout << *it << " ";it++;}cout << endl;vector<Date*> v2;v2.push_back(&d1);v2.push_back(&d2);v2.push_back(&d3);sort(v2.begin(), v2.end(), Less<Date*>());for (auto ptr : v2){cout << *ptr << " ";}cout << endl;return 0;
}将日期输入到vector中调用函数sort实现排升序的目的
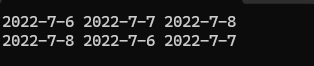
输入Date的顺序改变了,但是输入Date*的顺序没有改变,因为其中比较的是大小,需要特定的模板仿函数。
template<>
struct Less<Date*>
{bool operator()(Date* x, Date* y) const{return *x < *y;}
};![]()
输出结果达到期望效果。
综上:模板特化的核心价值,是为 “通用模板无法满足需求的特殊数据类型” 提供针对性实现,既保留了模板的通用性,又解决了特殊场景下的逻辑适配问题 —— 本质是 “通用方案补漏”,同时兼顾了便捷性和正确性。
虽然有用,但是不建议使用,还要写一个模板,还不入重新新一个模板函数。
3.模板的分离和编译
3.1 什么是分离编译
3.2 模板的分离编译
我们还是以模板类stack为
//stack.h文件
#include<vector>
#include<list>
#include<deque>
using namespace std;
namespace XLZ
{template<class T, class Container = deque<T>>class stack{public:void push(const T& x);void pop();T& top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;};class foo{public:void func1();void func2();};
}//stack.cpp
#include "Stack.h"
namespace XLZ
{template<class T, class Container >void stack<T, Container>::push(const T& x){_con.push_back(x);}template<class T, class Container >void stack<T, Container>::pop(){_con.pop_back();}void foo::func1(){printf("func1");}
}
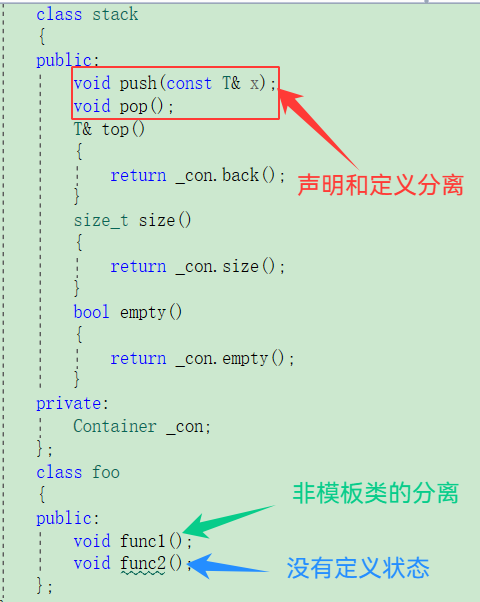
我们在main函数中调用分别调用函数 push size 以及 func1和func2
测试程序 :为了区分错误,我们分别逐个调用函数。
单独调push
XLZ::stack<int> st;
st.push(1);

出现链接错误
单独调size
XLZ::stack<int> st;
st.size();单独调func1
XLZ::foo f;
f.func1()单独调func2
XLZ::foo f;
f.func2()![]()
func2 是没有定义的非模板函数,但是push模板类已经定义了,为什么还是没有找到,而且发生了链接错误。
我们复习一下之前程序编译的 4 个阶段
- 预处理:对源代码做 “文字级加工”,比如把宏替换成实际内容、把
#include的头文件完整展开、删除注释、处理#if这类条件编译,最后生成.i后缀的文件。- 编译:检查代码语法是否正确,然后把预处理后的代码转换成汇编代码,生成
.s后缀的文件。- 汇编:把汇编代码翻译成二进制机器码(电脑能直接识别的底层指令),生成
.o后缀的 “目标文件”。- 链接:把多个
.o目标文件(比如程序里不同模块的目标文件)“拼接” 起来,再结合需要的库文件,最终生成能直接运行的.exe可执行程序。
Stack.h文件在预处理阶段,在Test.cpp文件中展开,此时的文件中的只有函数push,pop的声明,没有其定义
由于每个.cpp文件的编译时单独进行的,所以,在stack.cpp文件中的函数还是模板,没有实例化,模板有实例化就没有定义,当链接的时候,寻找不到函数的定义将出现来链接错误。
3.3.如何解决
模板定义的位置显式实例化。这种方法不实用,不推荐使用。
//显示实例化
template
class stack<int>;
类似于上述这种,但是创建double类型的栈的时候又要添加下面的代码
template
class stack<double>;对于C++模板来说不实用,不如不分离好使
那么怎么解决呢?
将声明和定义放在一个文件就好了啊
using namespace std;
namespace XLZ
{template<class T, class Container = deque<T>>class stack{public:void push(const T& x);void pop();T& top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;};template<class T, class Container >void stack<T, Container>::push(const T& x){_con.push_back(x);}template<class T, class Container >void stack<T, Container>::pop(){_con.pop_back();}
}
当某个.cpp文件包含这个头文件的时候,编译器能看到完整的模板定义,当遇到模板实例化的时候都会在编译时生成该实例的代码,链接阶段就不会出现 “找不到定义” 的错误。
模板的优缺点:【优点】1. 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生2. 增强了代码的灵活性【缺陷】1. 模板会导致代码膨胀问题,也会导致编译时间变长2. 出现模板编译错误时,错误信息非常凌乱,不易定位错误