意力机制 | 添加Deformable-LKA可变形大核注意力
意力机制 | 添加Deformable-LKA可变形大核注意力
改进是,Deformable_LKA可变形大核注意力
集合大卷积核,的广阔感受野和可变形卷积层的灵活性,有效的处理复杂视觉信息,
机制通过动态的 调整卷积核的大小和形状,去适应不同的图像特征,进而去提高模型适应性
在yoloV8中,Deformable_LKA可用来对于提升小目标和不规则形状的目标检测能力
对于3D方向,引入大核注意力机制D_LKA概念
这是采用大卷积核的注意力机制,能够充分理解上下文
该机制在类似于自注意力机制的感受野允许,能降低计算量,
提出的注意力机制收益五可变形卷积来灵魂或的扭曲采样网络,。
让模型能够适当的适应不同的数据模式,

,引入变形大核注意力机制D_LKA,概念
是采用大卷积核的注意力机制
更好去理解上下文, 在类似于自注意力的感受野运行
降低计算量
我们的注意力机制受益于可不按行卷积可以去灵活的扭曲,采样网络模型,可以更好的适应不同的数据模型
二、D_LKA模原理
原理是结合大卷积核的大感受野和可变形卷积的灵活性质的机制
1、通过采用大卷积核来模拟类似自我关注的感受野,降低计算量
2、库编写卷积去灵活的调整采样网络模型,。更好适应不同的数据集
1、大卷积核,D_LKA 使用大卷积核去捕获上下文的信息,更宽的感受野
2、可变形卷积,结合可变形卷积技术,允许模型的采样网络去根据图像特征灵活的改变
3、2D,3D适应性,D_LKA的两个版本,在处理不同深度数据时
三、大卷积核,
利用捕获图像广泛的上下文信息机制,模型自注意力机制的感受野,去使用更少的参数核计算量,
通过使用,深度可分离的卷积,和深度可分离的带扩张的卷积两种
去有效的构建大卷积核,
该方法允许网络在较大的感受野内学习特征,
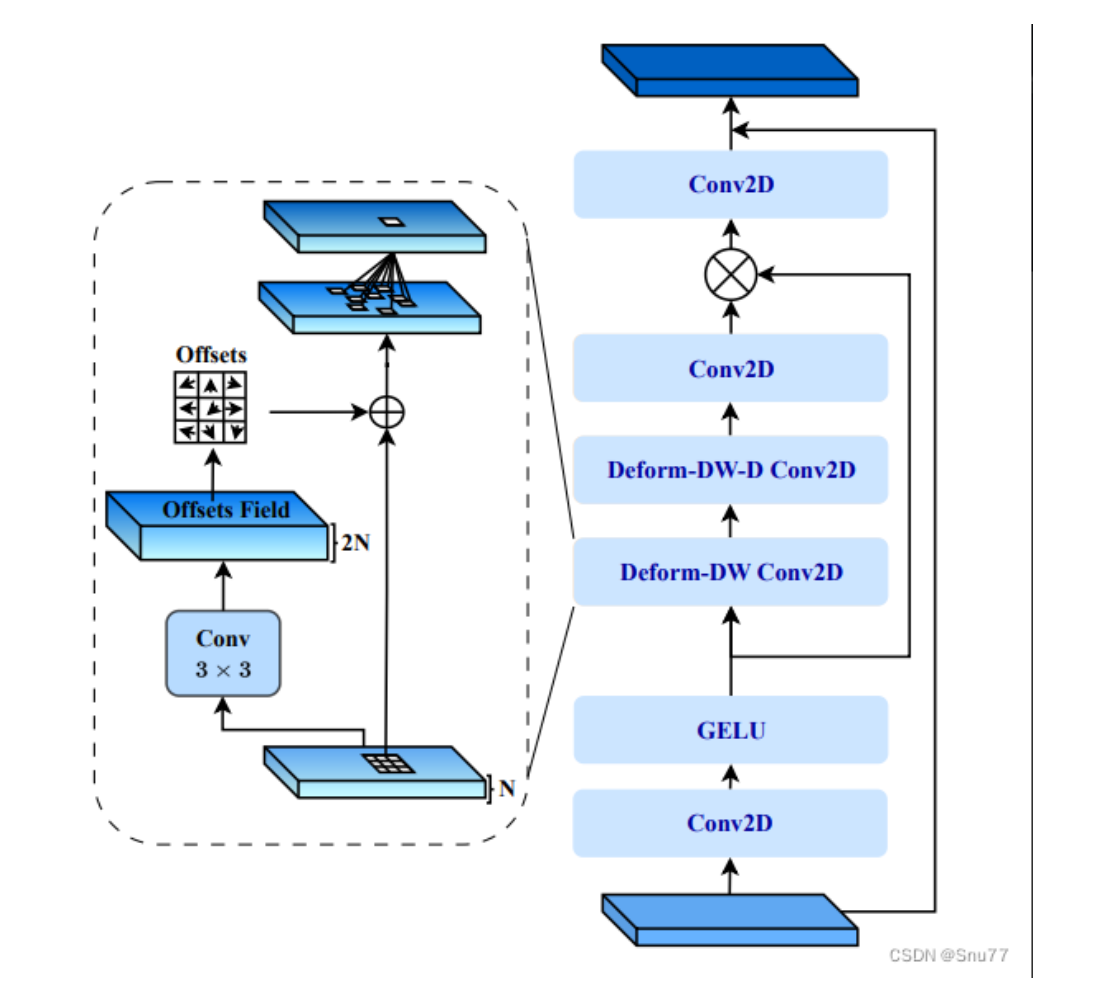
如图,变形大核注意力机制,D_LKA 模块架构
1、标准的2D卷积核
2、带偏移量的变形卷积,允许网络模型根据输入的特征自适应的调整感受野
3、偏移量的计算,由标准卷积层生成,主要用于知道变形卷积层的如何调整采样位置
4、激活函数,增加模型的非线性能力

3可变卷积
增强模型对不规则物体的捕获能力,可变形卷积通过添加额外的偏移量去调整便准卷积的采样位置,允许卷积核动态的去适应图像的内容
该机制能够是的卷积层去灵活的捕获更重形态的结构‘,通过图像信息去动态的增加偏移量,可变形卷积能够提高自视用的内核形状,有主意提高分割精准性
4、2D 3D 适应
时D_LKA技术对于不同维度数据的能力适应性
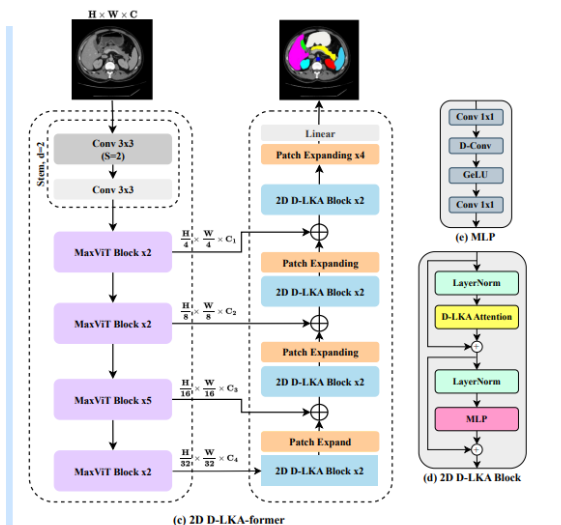
,2D D_LKA模型,针对二位数据的设计,常用于医学成像方面呢
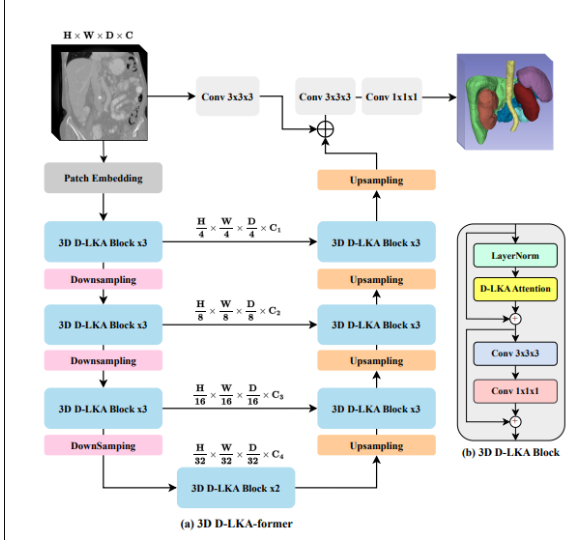
3D D_LKA模型扩展了技术,能够去处理三位数据集,充分立体图像体积的数据中的上下文信息,去交叉加深数据的深度理解,尤其,在多个层面分析核识别图像的特征,在医学冲构建 3D图由大用处
-
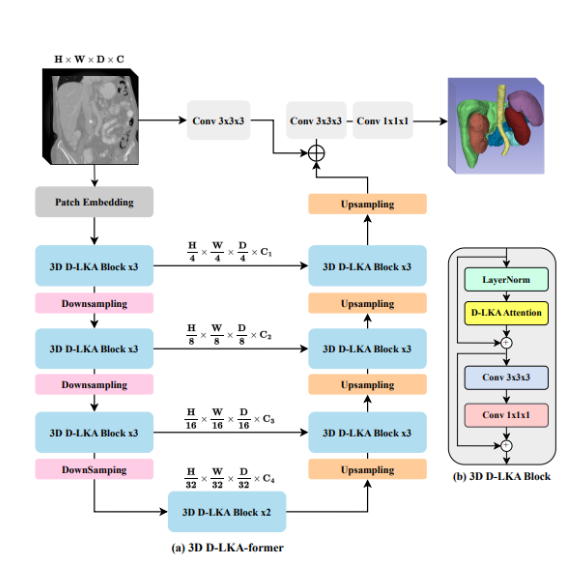
3D D-LKA模型(左侧): 包含多个3D D-LKA块,这些块在下采样和上采样之间交替,用于深度特征学习和分辨率恢复。
-
2D D-LKA模型(右侧): 利用MaxViT块作为编码器组件,并在不同的分辨率级别上使用2D D-LKA块,通过扩展(Patch Expanding)和D-LKA注意力机制进行特征学习。