(Arxiv-2025)Lynx:迈向高保真个性化视频生成
Lynx:迈向高保真个性化视频生成
paper title:Lynx: Towards High-Fidelity Personalized Video Generation
paper是字节跳动发布在Arxiv 2025的工作
Code:链接
Abstract
我们提出了 Lynx,这是一种能够从单张输入图像生成个性化视频的高保真模型。基于开源的扩散 Transformer (DiT) 基础模型,Lynx 引入了两个轻量级适配器以确保身份一致性。ID-adapter 使用 Perceiver Resampler 将 ArcFace 提取的人脸嵌入转换为紧凑的身份 token 作为条件输入,而 Ref-adapter 则整合了来自冻结参考路径的稠密 VAE 特征,并通过跨注意力在所有 Transformer 层中注入细粒度的细节。这些模块共同实现了在保持时间一致性和视觉真实感的同时,鲁棒的身份保持。通过在包含 40 个主体和 20 个无偏提示的精心构建的基准上进行评估(共得到 800 个测试用例),Lynx 展现出卓越的人脸相似度、具有竞争力的提示遵循能力以及强大的视频质量,从而推动了个性化视频生成的发展。
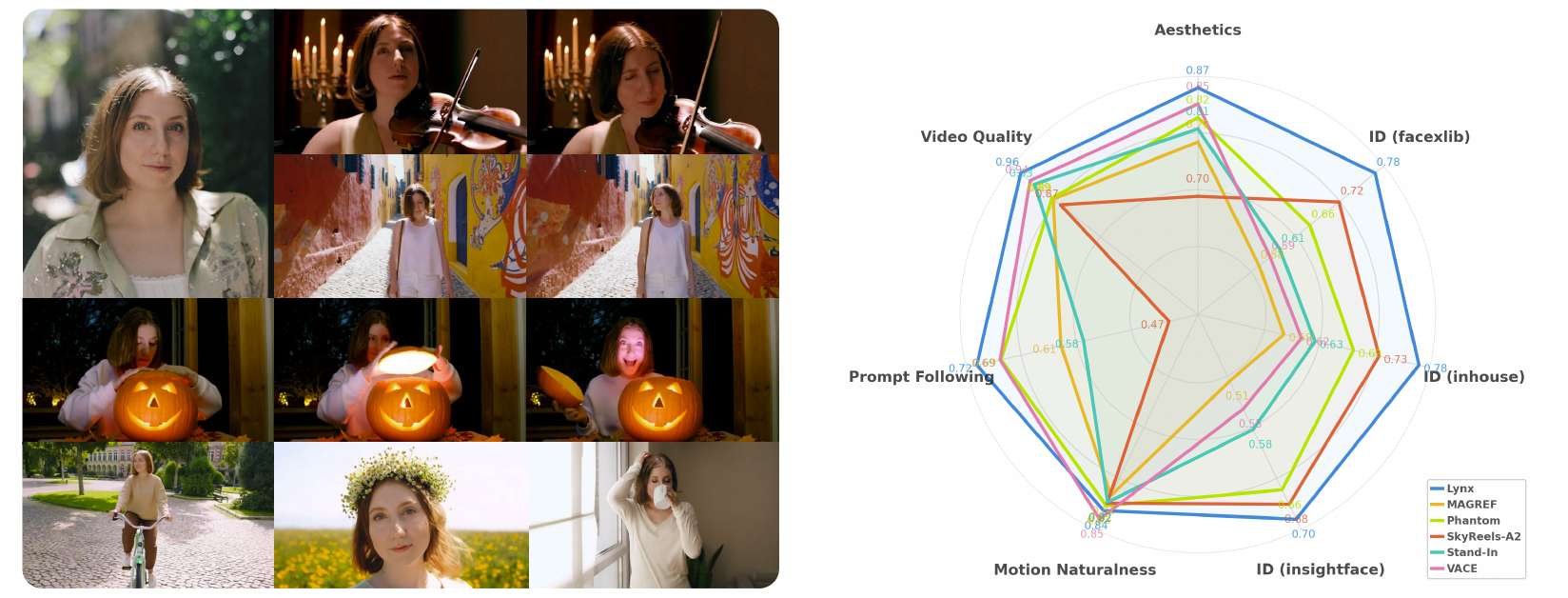
图1 左:Lynx 能够持续保持高保真的人脸身份,同时生成自然的动作、连贯的光照,以及灵活的场景适应(输入显示在左上角)。右:与其他方法相比,Lynx 在身份相似度和感知质量方面表现出明显优势,同时在动作自然性上仍保持竞争力。
1 Introduction
视觉内容生成领域见证了快速发展,这主要归功于扩散模型 [17, 34, 37] 的出现,它们为跨多种模态的高保真合成提供了一种可扩展且有效的框架。基于文本到图像生成的早期突破 [3, 32, 35, 36, 39],研究社区已将扩散方法扩展到时间域,产生了文本到视频模型 [4, 15, 26, 27, 33, 40, 42, 46],能够从自然语言提示中合成动态视觉内容。骨干架构的最新进展——例如扩散 Transformer (DiT) [34]——进一步提升了生成质量和可扩展性。除了基础生成之外,人们对下游任务的兴趣日益增长,包括视频编辑 [28, 44, 51]、多镜头叙事 [24] 和可控运动合成 [14, 23],反映了该领域对可控性、可重用性和高效性的不断需求。由此趋势衍生出的一个关键方向是个性化视频生成,其目标是合成能够忠实保持主体身份的视频。
个性化内容创作在图像领域已被广泛探索,其中基础生成模型通过用户提供的参考进行适配,以实现多样且身份一致的输出。早期方法 [12, 18, 38] 通过全模型或参数高效的微调(如 LoRA [18])实现了强身份保持。更近期的方法 [43, 47, 50] 基于身份嵌入或参考特征的轻量条件机制,使得无需重新训练整个模型即可实现高效个性化。在这些进展以及通用视频基础模型发展的基础上,近期研究开始探索时间域中的身份保持 [9, 11, 22, 31, 45, 48],旨在生成时间上连贯且逼真的个性化视频。
在本报告中,我们提出 Lynx——一个高保真的个性化视频生成框架,旨在从单张输入图像中保持身份。Lynx 并未重构或微调完整的基础模型,而是采用基于适配器的设计,包括两个专用组件:ID-adapter 和 Ref-adapter。ID-adapter 利用交叉注意力注入从单张人脸图像提取的身份特征。具体而言,人脸嵌入通过人脸识别模型获得,并通过 Perceiver Resampler 转换为一组紧凑的身份 token,实现丰富且高效的表征学习。为了进一步增强细节保持,Ref-adapter 融合了从预训练 VAE 编码器(继承自基础模型)中提取的参考特征。这些特征通过扩散骨干的冻结副本,获得所有 DiT 模块的中间激活,然后通过交叉注意力融入生成过程。训练方面,我们采用多阶段渐进策略,结合时空帧打包设计,以有效处理不同宽高比和时间长度的图像与视频数据。
我们在一个由 40 个不同主体和 20 个无偏人类相关提示组成的基准上评估 Lynx,共生成 800 个测试案例。人脸相似度通过三种专家人脸识别模型评估。为了评估提示跟随和视频质量,我们构建了一个基于 Gemini-2.5-Pro API 的自动化流程,指导模型对美学质量、运动自然度、提示对齐和整体视频质量进行评分。如表 1 和表 2 所示,Lynx 在身份保持方面始终优于近期的个性化视频生成方法,同时在提示对齐和整体视频质量上表现更佳。
2 Related Works
视频基础模型。近期的视频基础模型主要建立在扩散框架上,其中变分自编码器 (VAE) [25] 将原始视频压缩为紧凑的潜在表征,从而实现高效的训练与生成。早期的潜在扩散方法将图像基础模型扩展到视频域,采用 U-Net 架构并引入时间模块,如三维卷积和时间注意力 [4, 16, 40]。随着对可扩展性和长程时间一致性的需求增长,研究逐渐转向基于 Transformer 的架构。扩散 Transformer (DiT) [34] 及其双流变体 MMDiT [10] 展示了更强的时空建模能力,提升了时间一致性。这些架构现已支撑最先进的视频基础模型,包括 CogVideoX [46]、HunyuanVideo [27]、Wan2.1 [42]、Seedance 1.0 [13] 等,它们通过大规模训练数据、强大计算资源以及更长上下文长度实现了强泛化能力。
身份保持的内容创作。身份保持生成是内容创作的核心课题,并已在图像领域得到广泛研究。早期方法 [12, 18, 38] 通常依赖模型微调或优化以获得特定主体模型。然而,这类基于微调的方法在现实应用中往往不切实际,因为其计算开销大且缺乏可扩展性。例如,DreamBooth [38] 和基于 LoRA 的变体 [18] 需要微调完整基础模型或额外的低秩适配器。为克服这些限制,无需微调的方法 [43, 47] 引入轻量 ID 注入模块,从而避免逐主体训练。IP-Adapter [47] 使用人脸识别编码器提取身份特征,并通过适配器将其注入基础模型。在此基础上,InstantID [43] 融合 ControlNet [49] 模块,以实现输入解耦和更精细的控制。
随着大规模视频基础模型的出现,研究重心转向个性化视频生成。例如,ConsistID [48] 通过频率分解强化人脸身份一致性。ConceptMaster [21] 使用 CLIP 图像编码器和可学习的 Q-Former 将视觉表征与对应的文本嵌入融合,用于每个概念。HunyuanCustom [20] 在 HunyuanVideo [27] 基础上扩展出多模态定制框架,整合图像、音频、视频和文本条件,通过模态特定模块实现更强的身份一致性和可控视频生成。另一类工作(如 SkyReels-A2 [11]、VACE [22]、Phantom [31])将参考条件与噪声潜变量拼接,并在去噪过程中处理完整序列。然而,平衡身份相似度和可编辑性一直是长期存在的挑战。我们的方法在显著提升相似度的同时,保持了强提示跟随能力和高视频质量。
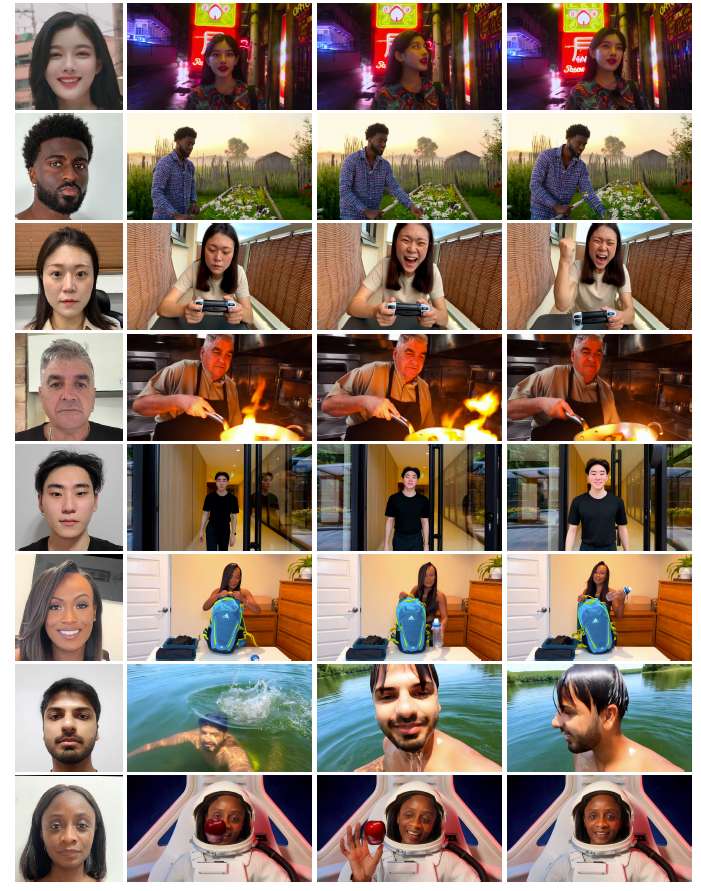
图 2 由单张输入图像生成的视频,在表现性面部表情(第 3 行)、多样光照(第 1、4、5 行)、姿态变化(第 2、6、7 行)以及物体交互(第 8 行)方面展示了强身份保持能力。
3 Architecture and Training Strategy
3.1 Model Architecture
我们采用 Wan2.1 [42] 作为基础模型,这是最新开源的视频基础模型之一。Wan 基于 DiT 架构 [34] 构建,并结合了 Flow Matching [30] 框架。每个 DiT 模块首先对视觉 token 进行时空自注意力运算,从而实现空间细节与时间动态的联合建模,然后通过交叉注意力引入文本条件。
不同于重构和微调整个模型,我们引入两个适配器模块,即 ID-adapter 和 Ref-adapter,用于注入身份特征,并在基础模型之上实现个性化视频生成。整体架构与适配器设计如图 3 所示。
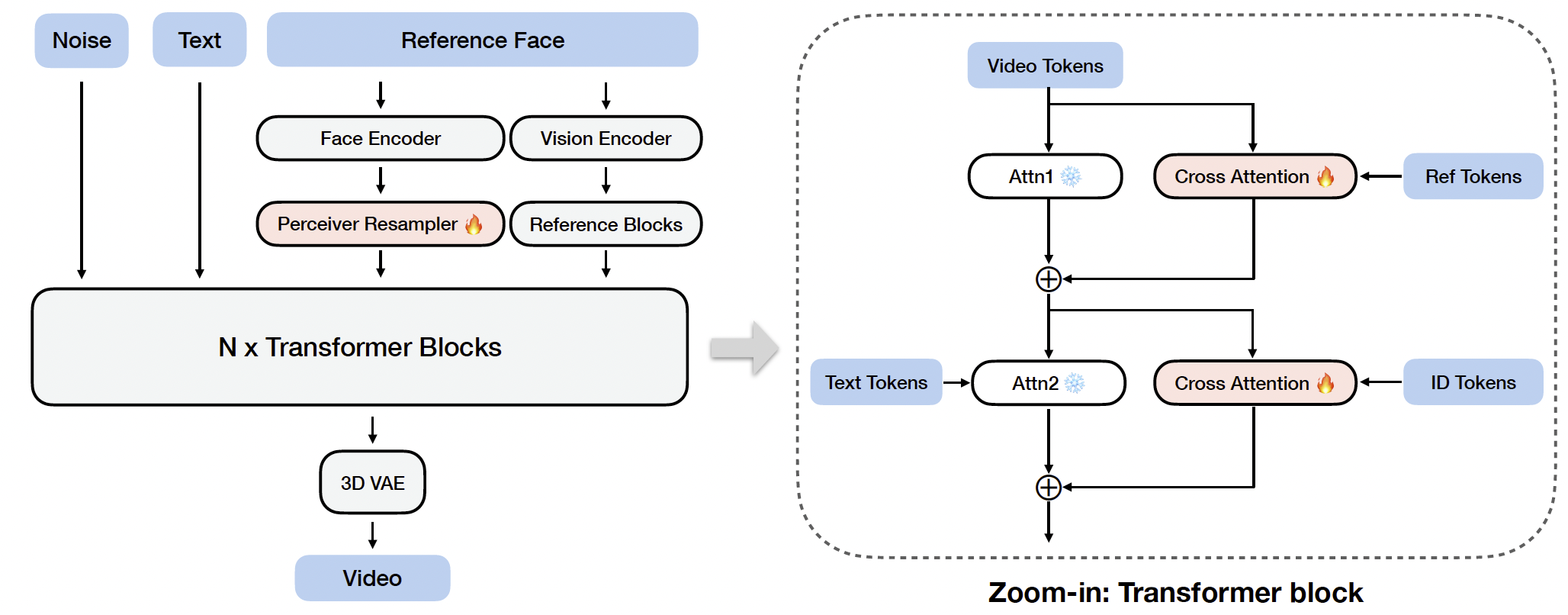
图 3 Lynx 的架构。基于 DiT 的视频基础模型,Lynx 引入了两个适配器模块,通过交叉注意力注入身份特征。
ID-adapter. 先前的工作 [43, 47] 在文本到图像模型(如 Stable Diffusion [36])中引入了人脸识别特征 [8] 以实现个性化生成。这些方法通常附加额外的适配器层,并引入额外交叉注意力模块,以基于身份特征来调控生成过程。具体而言,人脸图像通过人脸特征提取器获得特征向量。为了将该向量转换为适合交叉注意力的序列,使用 Perceiver Resampler [1](亦称 Q-Former [29])进行训练,将其映射为固定长度的 token 嵌入表征。我们采用相同范式。给定一个维度为 512 的人脸特征向量,Resampler 生成一个由 16 个 token 组成的序列,每个 token 维度为 5120。该 token 序列与 16 个额外的寄存器 token [6] 拼接,并与输入视觉 token 进行交叉注意力。所得表征随后被加回主分支。
Ref-adapter. 近期的一些方法 [11, 31] 使用 VAE 特征在参考注入过程中增强细节保持,利用了 VAE 编码器生成的空间密集表征。作为对 ID-adapter 的补充,我们的设计也引入 VAE 密集特征以增强身份保真度。不同于以往直接将特征图置于噪声潜变量之前的图像到图像式生成方式,我们将参考图像输入基础模型的冻结副本(噪声水平设为 0,文本提示为“image of a face”),这一设计类似于 ReferenceNet [19]。这使得参考图像的空间细节能够在所有层中被捕获。与 ID-adapter 相同,我们在每一层应用独立的交叉注意力来融合对应的参考 token。
3.2 Training Strategy
我们在此描述大规模训练所采用的策略。由于训练视频(和图像)在空间分辨率和时间长度上存在差异,我们采用 NaViT 方法 [7] 来高效地批处理异构输入。多个视频或图像被打包为一个长序列,并通过注意力掩码来区分不同样本。训练遵循渐进式课程,首先进行图像预训练,以利用大规模图像数据的丰富性,然后扩展到视频训练,以恢复时间动态。
3.2.1 Spatio-Temporal Frame Pack
传统的图像域训练通常依赖分桶 (bucketing) 来处理多分辨率输入。图像会被裁剪并调整到一组预定义的宽高比和分辨率,在训练过程中,数据加载器从单一桶中采样,从而保证批次中的图像具有相同的尺寸。虽然该策略对图像有效,但在视频上泛化性较差,因为额外的时间维度(帧长)带来了显著的复杂性。按照分辨率和时长同时分桶会降低灵活性,并限制模型对任意宽高比和视频长度的泛化能力。
为克服这一限制,我们借鉴 Patch n’ Pack [7] 的方法,将每个视频的分块化 (patchified) token 拼接为一个长序列,并将其视为统一批次。注意力掩码确保 token 仅在各自视频内部进行注意力计算,避免跨样本干扰。在位置编码方面,我们对每个视频独立应用三维旋转位置嵌入 (3D-RoPE) [41]。这一设计实现了对异构图像和视频的高效批处理,同时保持空间与时间一致性。
3.2.2 Progressive Training
图像预训练。我们首先利用大量可用的图像数据进行图像预训练。为确保各训练阶段的一致性,每张图像被视为单帧视频,并应用上述相同的帧打包策略。在实验中,我们发现从零开始训练 Perceiver Resampler 会产生不理想的结果:即使经过大量训练,也未观察到人脸相似性,这表明模型要么无法收敛,要么需要极其漫长的训练。相反,我们发现将 Resampler 初始化为图像域的预训练检查点(例如 InstantID [43]),能显著加快收敛速度。在这种初始化下,仅经过 10k 次迭代即可出现可识别的人脸相似性,而完整的第一阶段训练则运行 40k 次迭代。
视频训练。单独的图像预训练往往会生成基本静态的视频,因为模型主要学习的是保持外观而非捕捉运动。为恢复时间动态性,第二阶段必须让模型接触大规模视频数据。该阶段使网络能够学习运动模式、场景切换和时间一致性,同时保留并增强图像预训练阶段建立的强身份条件。训练在该阶段进行 60k 次迭代。
4 Data Pipeline
我们的数据管道目标是构建高质量的人物–文本–视频三元组。虽然文本提示可以通过字幕生成模型(如 Qwen 2.5-VL [2])轻松获得,但主要挑战在于建立可靠的人物–视频配对,即将人物图像作为身份(ID)条件与该人物的目标视频配对。
我们的原始数据包括来自公开数据集和内部来源的图像与视频。这些数据可分为四类:(1) 单张图像;(2) 单个视频;(3) 同一人的多场景图像集合;(4) 同一人的多场景视频集合。为了构建图像–图像和图像–视频配对(其中一张图像作为 ID 条件,另一张图像或视频作为生成目标),一种直接的方法是从图像或视频中裁剪人脸。然而,这往往导致表情和光照的过拟合。同时,多场景数据对于鲁棒训练至关重要,但本身极为稀缺。
为克服这些限制,我们采用了两种增强策略,如图 4 所示:
- 表情增强。我们使用 X-Nemo [52] 编辑源人脸,使其匹配目标表情,从而丰富表情多样性(图 4a)。
- 肖像重光照。我们使用 LBM [5] 对人脸进行重光照,并在不同光照条件下替换背景,以增强对光照变化的鲁棒性(图 4b)。
增强后,我们使用人脸识别模型进行身份验证,丢弃低相似度的配对,以确保高质量的 ID 一致性。相似度过滤也应用于未经增强的多场景数据。
最终,我们的管道共构建了 5020 万对数据,包括 2150 万单场景配对、770 万多场景配对,以及 2100 万增强的单场景配对。对于直接从目标中裁剪条件图像的单场景配对,我们还通过分割人物并替换背景来进行背景增强。在训练过程中,这些不同类型的配对通过加权采样进行检索,以平衡数据多样性。