FreeFusion:基于交叉重构学习的红外与可见光图像融合
FreeFusion: Infrared and Visible Image Fusion via Cross Reconstruction Learning
FreeFusion:基于交叉重构学习的红外与可见光图像融合
摘要—现有的融合方法通过经验性地设计精细的融合损失来保留源图像的特定特征。由于图像融合没有真值,手工设计的损失可能无法使融合图像涵盖所有重要特征,进而影响高层任务的性能。这里存在两个主要挑战:源图像之间的域差异和不同层级任务的语义失配。本文提出了一种基于交叉重建学习的红外与可见光图像融合方法,该方法不使用任何手工设计的融合损失,而是促使网络自适应地融合源图像的互补信息。首先,我们设计了一个交叉重建学习模型,将融合特征解耦以重建另一模态的源图像。因此,融合网络被迫学习两种模态特征的域自适应表示,从而实现它们在潜在空间中的域对齐。其次,我们提出了一种动态交互融合策略,该策略在融合特征和目标语义特征之间构建相关矩阵以克服语义失配。此外,我们增强强相关特征并抑制弱相关特征以提高交互能力。在三个数据集上的大量实验表明,与最先进的方法相比,该方法具有优越的融合性能,同时提高了分割精度。索引词—红外与可见光图像融合,交叉重建学习,动态交互融合,特征相关矩阵。
I. 引言
可见光图像通过反射光信息获得,包含丰富的边缘和纹理细节。但它们对光照条件和恶劣天气敏感。红外图像通过热辐射信息捕获,能够有效地在夜间和烟雾条件下突出目标。但它们缺乏足够的细节。红外与可见光图像融合(IVIF)旨在整合它们的互补信息,生成具有强感知能力的新图像,从而有利于后续的高层视觉任务,例如语义分割[4]、[5]、目标检测[6]和目标跟踪[7]。现有的IVIF方法[8]、[9]、[10]、[11]、[12]可以分为四类。(1)基于编码器-解码器的方法(例如,YDTR[13]、U2Fusion[14]、PIAFusion[15]、CDDFuse[16])设计模态特定的编码器从源图像中提取信息。然后,通过融合模块(例如,多尺度特征融合层或注意力机制)生成融合特征表示。最后,使用解码器重建融合图像。(2)基于对抗学习的方法(例如,FusionGAN[17]、DDcGAN[18]、TGFuse[19])设计生成器将条件向量映射到融合图像空间,判别器约束融合图像保留热辐射信息和纹理信息。(3)基于联合多任务的方法(例如,Tardal[1]、MetaFusion[20]、SegMif[21])利用高层任务提供目标语义特征,从而促使融合特征获得目标轮廓信息。(4)基于自编码器的方法(例如,DIDFuse[22]、NestFuse[23])训练一个自编码器,通过重建对应图像获得提取图像特征的能力。然后,设计手工制作的融合规则(例如,l1-范数、逐元素相加和逐元素选择最大值)来融合互补特征。例如,NestFuse[23]采用空间/通道注意力融合策略来手动融合特征。虽然基于自编码器的方法没有设计明确的融合损失,但手工制作的融合规则无法自适应地融合两种模态的重要信息。相比之下,我们将融合特征解耦为两种模态特征,然后将它们反向映射到源图像,迫使融合特征自适应地包含所有源图像信息。此外,由于IVIF没有真值,前三类方法为特征提取、特征融合和图像重建构建了各种手工设计的融合损失函数。
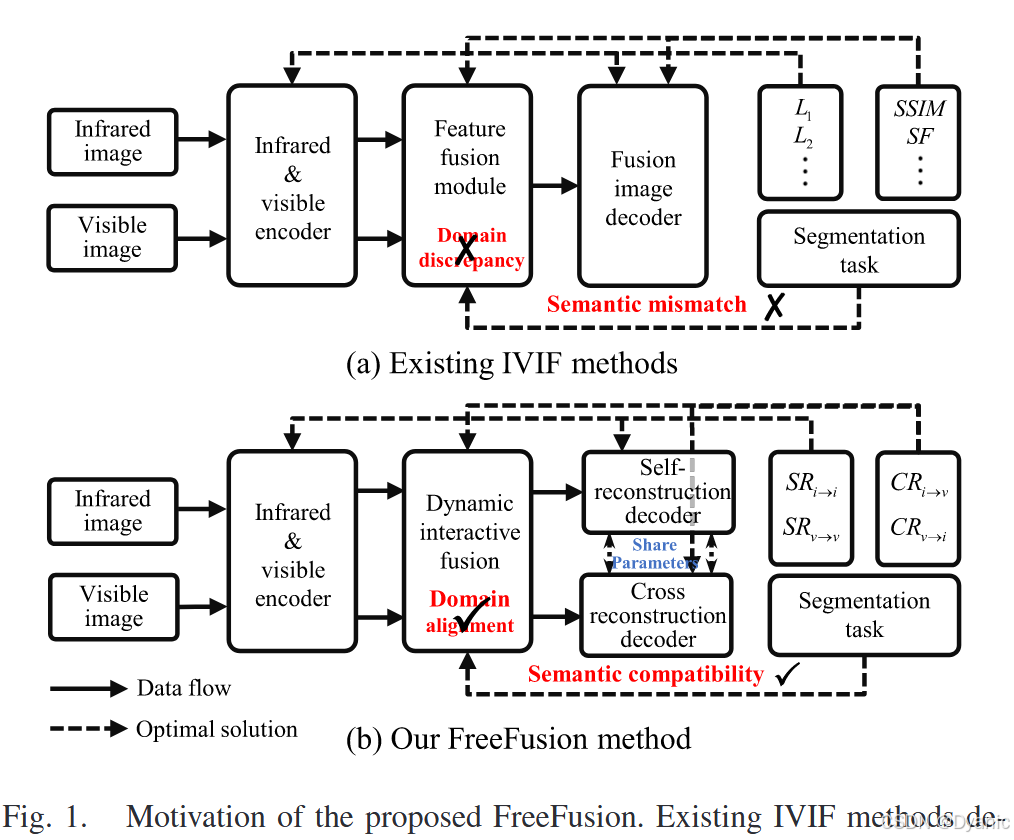
如图1(a)所示,像素强度损失(例如,L1[1]、[15]、L2[13]、[14]、[16]、[21]等)约束红外和可见光编码器提取热辐射和纹理特征。结构损失(例如,SSIM[1]、[13]、[14]、[16]、[21]、SF[13]等)确保特征融合模块包含结构和边缘信息。它们都有助于融合图像解码器生成融合图像。

更多损失函数如图2(左)所示。然而,构建精细的损失函数可能无法有效监督IVIF框架保留源图像的所有有用信息。特别是,IVIF面临两个挑战。红外和可见光特征之间的域差异以及语义从而有利于后续的高层视觉任务,例如语义分割[4]、[5]、目标检测[6]和目标跟踪[7]。现有的IVIF方法[8]、[9]、[10]、[11]、[12]可以分为四类。(1)基于编码器-解码器的方法(例如,YDTR[13]、U2Fusion[14]、PIAFusion[15]、CDDFuse[16])设计模态特定的编码器从源图像中提取信息。然后,通过融合模块(例如,多尺度特征融合层或注意力机制)生成融合特征表示。最后,使用解码器重建融合图像。(2)基于对抗学习的方法(例如,FusionGAN[17]、DDcGAN[18]、TGFuse[19])设计生成器将条件向量映射到融合图像空间,判别器约束融合图像保留热辐射信息和纹理信息。(3)基于联合多任务的方法(例如,Tardal[1]、MetaFusion[20]、SegMif[21])利用高层任务提供目标语义特征,从而促使融合特征获得目标轮廓信息。(4)基于自编码器的方法(例如,DIDFuse[22]、NestFuse[23])训练一个自编码器,通过重建对应图像获得提取图像特征的能力。然后,设计手工制作的融合规则(例如,l1-范数、逐元素相加和逐元素选择最大值)来融合互补特征。例如,NestFuse[23]采用空间/通道注意力融合策略来手动融合特征。虽然基于自编码器的方法没有设计明确的融合损失,但手工制作的融合规则无法自适应地融合两种模态的重要信息。相比之下,我们将融合特征解耦为两种模态特征,然后将它们反向映射到源图像,迫使融合特征自适应地包含所有源图像信息。此外,由于IVIF没有真值,前三类方法为特征提取、特征融合和图像重建构建了各种手工设计的融合损失函数。如图1(a)所示,像素强度损失(例如,L1[1]、[15]、L2[13]、[14]、[16]、[21]等)约束红外和可见光编码器提取热辐射和纹理特征。结构损失(例如,SSIM[1]、[13]、[14]、[16]、[21]、SF[13]等)确保特征融合模块包含结构和边缘信息。它们都有助于融合图像解码器生成融合图像。更多损失函数如图2(左)所示。然而,构建精细的损失函数可能无法有效监督IVIF框架保留源图像的所有有用信息。特别是,IVIF面临两个挑战。红外和可见光特征之间的域差异以及语义然后通过增强强相关特征来提高它们的交互能力。
II. 相关工作
A. 无监督融合方法
无监督融合方法专注于构建手工设计的融合损失,推动融合图像与源图像相似。例如,Zhao等人[16]提出了一种相关驱动的特征分解融合方法,并设计了相关驱动损失以保留更多模态共享和模态特定信息。Tang等人[15]设计了一个渐进式图像融合网络,通过构建光照感知损失自适应地整合有意义的信息。Zhao等人[25]探索了一种交互式特征嵌入方法,采用结构相似性损失来保留源图像的重要信息。Ma等人[18]构建了双判别器条件生成对抗网络,设计了内容损失来约束融合图像与源图像之间的像素强度和梯度变化。Rao等人[19]采用轻量级变换器模块和对抗学习算法来构建基于方差的结构相似性损失,约束融合图像。Yao等人[31]提出了一种彩色图像融合框架,其中构建了基于高斯模糊核的颜色损失,以在低光照条件下保留可见光图像的颜色信息。然而,这些融合方法构建手工设计的融合损失,可能无法保留源图像的所有有用信息。相比之下,我们提出的交叉重建学习不使用任何手工设计的融合损失。由于融合结果不受任何特定先验知识假设的约束,融合模型可以自由地融合更全面的信息。
B. 自监督融合方法
自监督融合方法旨在训练编码器-解码器模型进行特征提取和图像重建,并设计特定的融合策略来保留源图像的特定特征。例如,Li等人[23]开发了一种嵌套连接方法,利用多尺度深度特征融合策略来保留更多显著特征。Zhao等人[22]探索了深度图像分解策略,其中损失函数被设计为使源图像的背景/细节特征图相似/不同。Li等人[29]基于残差架构设计了残差融合网络,并提出了细节保留损失和特征增强损失来迫使网络融合更多细节特征。Liang等人[32]通过自监督表示学习设计了图像分解模型,可以在没有任何配对数据或复杂数据损失的情况下实现图像融合。Tang等人[33]利用场景光照解耦网络来重建两个源图像,同时保留源图像的有用信息。Xu等人[34]通过跨模态重建将源图像分解为场景特征和属性向量。然后,分别使用手工设计的平均和加法策略融合两种模态的场景特征和属性向量。然而,手工设计的融合策略缺乏自适应性,导致重要特征的丢失。相比之下,我们提出交叉重建学习,将融合特征解耦为两种模态特征,交叉重建源图像。因此,交叉重建过程迫使融合特征自适应地包含源图像的所有重要信息。上述融合方法使用源图像作为真值进行端到端训练,但难以充分解决源图像之间的域差异,导致一些重要细节信息丢失。相比之下,我们的交叉重建学习解耦融合特征以重建另一模态的源图像。在解耦和重建过程中,可见光和红外特征被迫在同一域空间中保持一致,从而实现跨模态特征域对齐。
C. 联合多任务融合方法
最近,联合多任务融合方法尝试使用来自高层视觉任务的语义信息来加强融合网络的性能。它们分为两类:级联学习方法[1]、[35]、[36]和交互学习方法[2]、[20]、[21]、[37]。级联学习方法通过使用高层任务作为约束来训练融合网络,促使融合网络生成有利于下游任务的融合结果。例如,Sun等人[35]通过目标检测网络获得目标相关信息,然后使用目标位置作为先验信息来指导融合网络。Liu等人[1]结合双对抗学习和检测网络,提出了两层优化公式来加强融合和分割任务之间的联系。Tang等人[36]利用语义损失引导高层语义信息流回图像融合模块,缓解融合和分割任务之间的差距。Wu等人[38]使用热启动融合损失获得初始融合结果,然后直接引入分割损失进行语义驱动训练。Yao等人[39]实施基于强度和梯度的融合损失来训练拉普拉斯金字塔融合网络。然后,融合结果附加到使用交叉熵损失训练的分割网络。因此,这两种方法都使用了语义级损失和融合级损失。相比之下,我们的方法不采用任何融合损失,即我们通过交叉重建源图像来解耦融合特征,这确保模型自由地融合两种模态的互补特征。交互学习方法设计不同层级特征图之间的分层交互,从而弥合融合和高层任务之间的差距。例如,Zhao等人[20]通过用于目标检测的元特征嵌入来解决语义特征和融合特征之间的差异。Wang等人[37]探索融合和显著目标检测任务之间的协作关系,并设计了交互增强的多任务范式。Liu等人[21]提出了一种多交互特征学习架构,利用双任务相关性来提高双任务的性能。此外,一些研究结合低层视觉任务来提高融合任务的性能。例如,Jie等人[40]结合超分辨率任务实施随机迭代去噪过程,从而生成高分辨率融合结果。Li等人[41]首次尝试在单阶段框架中解决图像配准和融合问题,促进了两个任务的相互增强。Li等人[42]利用配准网络获得对齐知识,监督不匹配的图像融合,使融合算法摆脱严格配准。Li等人[43]联合训练图像融合和恢复任务,可以有效地融合和恢复退化的多模态信息。现有方法将来自高层视觉任务的目标语义信息嵌入到融合任务中,但两个不同层级的任务阻碍了这一过程。因此,我们提出动态交互融合来实现语义兼容性并细化每个任务的特征表示。特别是,我们利用相关矩阵和查询级交互,使目标语义信息能够自然地兼容于融合任务。
III. 提出的方法
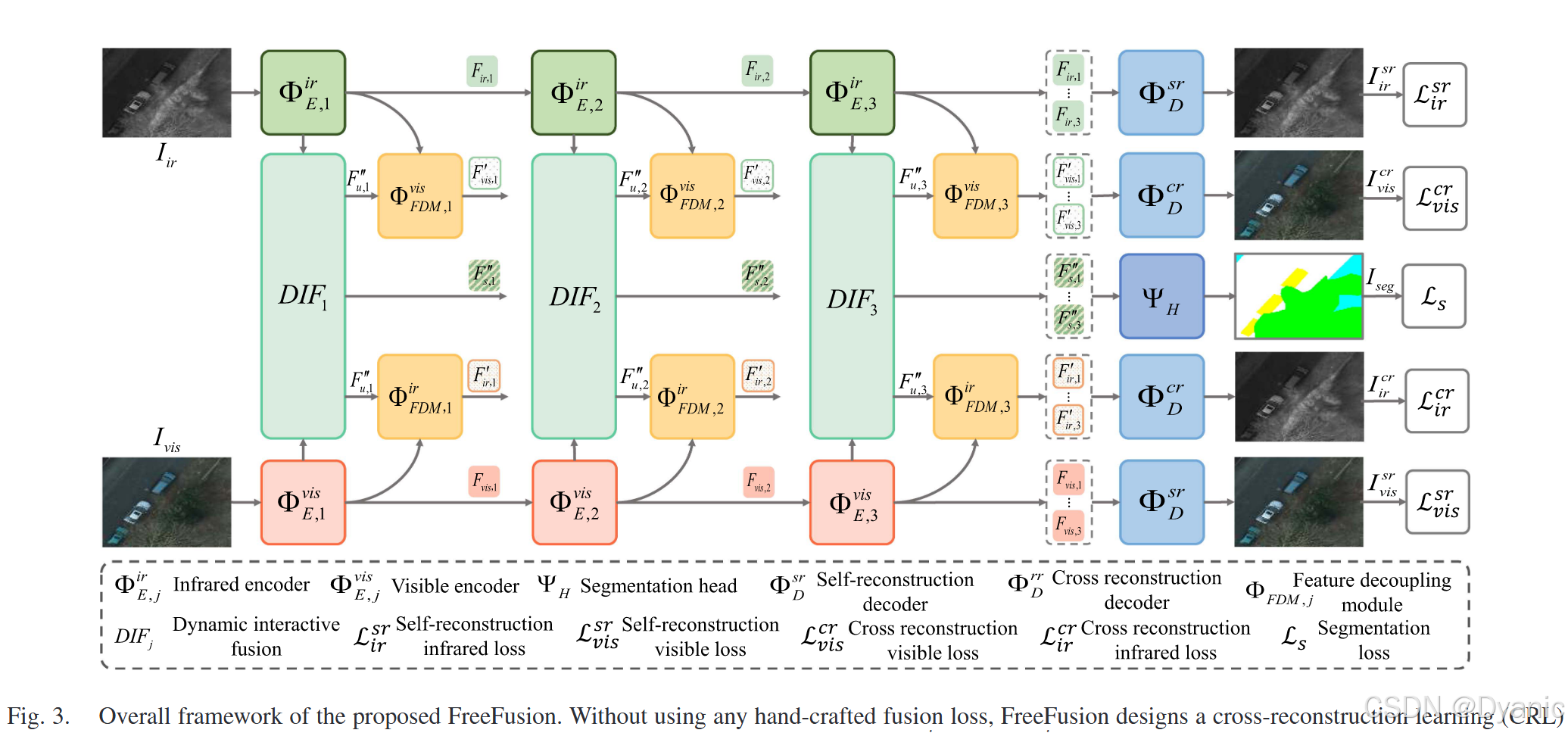
由于没有真值可用于训练融合模型,现有方法构建精细的融合损失,可能无法保留源图像的所有重要特征。如图3所示,FreeFusion旨在设计一个CRL框架,不使用任何手工设计的融合损失,同时迫使网络自适应地融合源图像的互补信息。特别是,我们设计DIFjDIF_jDIFj来实现融合和分割任务之间的自然语义兼容性。详细内容如下介绍。
A. 交叉重建学习
在不使用任何手工设计的融合损失来训练融合模型的情况下,带来了如何迫使网络自由地提取和融合所有重要特征然后重建融合图像的挑战。我们的方法通过实施CRi→vCR_{i→v}CRi→v和CRv→iCR_{v→i}CRv→i来学习逆映射知识,这迫使融合特征包含两种模态的关键特征。通过SRi→iSR_{i→i}SRi→i和SRv→vSR_{v→v}SRv→v进行特征提取:我们通过解耦融合特征来重构相应的源图像,从源图像中提取重要特征。首先,给定输入红外图像IirI_{ir}Iir和可见光图像IvisI_{vis}Ivis,红外和可见光编码器表示为ΦE,jirΦ^{ir}_{E,j}ΦE,jir和ΦE,jvisΦ^{vis}_{E,j}ΦE,jvis,其中j=1,2,3j = 1, 2, 3j=1,2,3是层数。在每一层中,两种模态编码器通过ΦE,jirΦ^{ir}_{E,j}ΦE,jir和ΦE,jvisΦ^{vis}_{E,j}ΦE,jvis执行特征提取,生成红外特征Fir,jF_{ir,j}Fir,j和可见光特征Fvis,jF_{vis,j}Fvis,j。然后,来自每层的红外和可见光特征被输入到自重建解码器ΦDsrΦ^{sr}_{D}ΦDsr,重建红外图像IirsrI^{sr}_{ir}Iirsr和可见光图像IvissrI^{sr}_{vis}Ivissr。红外图像重建损失Lirsr\mathcal{L}^{sr}_{ir}Lirsr和可见光图像重建损失Lvissr\mathcal{L}^{sr}_{vis}Lvissr确保学习到的源图像综合特征在自重建过程中不会丢失,可以写为:
Lirsr=‖Iir−Iirsr‖1+1−S(Iir,Iirsr)(1)
\mathcal{L}^{sr}_{ir} = ‖I_{ir} − I^{sr}_{ir}‖_1 + 1 − \mathcal{S} (I_{ir}, I^{sr}_{ir} ) \tag{1}
Lirsr=‖Iir−Iirsr‖1+1−S(Iir,Iirsr)(1)
Lvissr=‖Ivis−Ivissr‖1+1−S(Ivis,Ivissr)(2)
\mathcal{L}^{sr}_{vis} = ‖I_{vis} − I^{sr}_{vis}‖_1 + 1 − \mathcal{S} (I_{vis}, I^{sr} _{vis}) \tag{2}
Lvissr=‖Ivis−Ivissr‖1+1−S(Ivis,Ivissr)(2)
其中S(⋅,⋅)\mathcal{S}(·, ·)S(⋅,⋅)表示结构相似性指数[25]。
通过CRi→vCR_{i→v}CRi→v和CRv→iCR_{v→i}CRv→i进行特征融合:如果融合特征可以被解耦生成跨模态图像,它将被迫自由地融合两种模态的重要特征信息。同时,红外和可见光特征必须在同一域空间中进行域对齐。如图3所示,来自DIFjDIF_jDIFj的融合相关特征Fu,j′′F ''_{u,j}Fu,j′′(详见第III-B节)和红外特征Fir,jF_{ir,j}Fir,j被输入到ΦFDM,jvisΦ^{vis}_{FDM,j}ΦFDM,jvis以生成解耦的可见光特征Fvis,j′F' _{vis,j}Fvis,j′。类似地,解耦的红外特征Fir,j′F'_{ir,j}Fir,j′可以通过ΦFDM,jirΦ^{ir}_{FDM,j}ΦFDM,jir获得。然后,来自每层的解耦红外和可见光特征被输入到交叉重建解码器ΦDcrΦ^{cr}_{D}ΦDcr,分别生成交叉重建的红外图像IircrI^{cr}_{ir}Iircr和交叉重建的可见光图像IviscrI^{cr}_{vis}Iviscr。交叉重建损失Lircr\mathcal{L}^{cr}_{ir}Lircr和Lviscr\mathcal{L}^{cr}_{vis}Lviscr主要确保融合特征中包含的两种模态信息不会丢失。它们可以写为:
Lircr=‖Iir−Iircr‖1+1−S(Iir,Iircr)(3)
\mathcal{L}^{cr}_{ir} = ‖I_{ir} − I^{cr}_{ir} ‖_1 + 1 − \mathcal{S} (I_{ir}, I^{cr}_{ir} ) \tag{3}
Lircr=‖Iir−Iircr‖1+1−S(Iir,Iircr)(3)
Lviscr=‖Ivis−Iviscr‖1+1−S(Ivis,Iviscr)(4) \mathcal{L}^{cr}_{vis} = ‖I_{vis} − I^{cr}_{vis}‖_1 + 1 − \mathcal{S} (I_{vis}, I^{cr}_{vis}) \tag{4} Lviscr=‖Ivis−Iviscr‖1+1−S(Ivis,Iviscr)(4)
最后,SRi→iSR_{i→i}SRi→i、SRv→vSR_{v→v}SRv→v、CRi→vCR_{i→v}CRi→v和CRv→iCR_{v→i}CRv→i训练四个共享参数的解码器,从而使解码器实现图像重建的泛化能力。因此,在推理阶段,融合特征直接输入到解码器,可以生成融合图像。
B. 动态交互融合
融合特征可以帮助分割任务提供像素级的细节信息,目标语义特征可以引导融合任务包含丰富的语义信息。但由于任务层级的差异,融合和分割任务存在语义失配。因此,如图4所示,我们设计DIFjDIF_jDIFj来实现两个不同层级任务之间的语义兼容性。在本小节中,我们强调两个阶段:跨任务交互和任务查询,将在下面详细介绍。在跨任务交互阶段,我们引入ΦCTIM,jΦ_{CTIM,j}ΦCTIM,j,在任务内和任务间建立空间细粒度交互,以加强相互有益的特征表示,如图5所示。我们利用相关矩阵来加权输入特征图的每个像素位置信息,从而增强融合和语义特征之间的潜在联系。我们可以自然地推断出四个相关矩阵块:融合任务内相关、分割任务内相关,以及两个任务之间的任务间相关。具体来说,在每一层中,我们将Fvis,jF_{vis,j}Fvis,j和Fir,jF_{ir,j}Fir,j输入到ΦFFM,jΦ_{FFM,j}ΦFFM,j以生成融合特征Fu,jF_{u,j}Fu,j,然后融合特征通过ΦFTM,jΦ_{FTM,j}ΦFTM,j转换为目标语义特征Fs,jF_{s,j}Fs,j。接下来,Fu,jF_{u,j}Fu,j和Fs,jF_{s,j}Fs,j被展平为融合向量Vu,jV_{u,j}Vu,j和目标语义向量Vs,jV_{s,j}Vs,j。我们连接Vu,jV_{u,j}Vu,j和Vs,jV_{s,j}Vs,j得到混合向量Vmix,jV_{mix,j}Vmix,j。Vmix,jV_{mix,j}Vmix,j与可学习的权重矩阵WQW_QWQ、WKW_KWK和WVW_VWV相乘,分别得到QQQ、KKK和VVV,可以表示如下:
{Q,K,V}={Vmix,jWQ,Vmix,jWK,Vmix,jWV}(5)
\{Q, K, V \} = \{V_{mix,j}W_Q, V_{mix,j}W_K, V_{mix,j}W_V \} \tag{5}
{Q,K,V}={Vmix,jWQ,Vmix,jWK,Vmix,jWV}(5)
随后,使用QQQ和KKK之间的缩放点积计算相关矩阵,然后用softmax函数将它们归一化到[0, 1.0]。之后,相关矩阵与VVV相乘以增强任务内和任务间的混合向量表示。为了捕获Vmix,jV_{mix,j}Vmix,j中的不同上下文信息,多个注意力头并行计算。这种机制促进了融合和分割任务的全局交互和融合。显然,我们通过增加强语义相关位置的权重值和减少弱语义相关位置的权重值来实现融合和语义特征之间的语义兼容性。值向量通过相关矩阵加权以增强任务内自身信息和任务间互补信息。注意力机制计算如下:
Vmix,j′=softmax(QKTdk)V(6)
V'_{mix,j}=softmax(\frac{QK^T}{\sqrt{d_k}})V \tag{6}
Vmix,j′=softmax(dkQKT)V(6)
其中dk\sqrt{d_k}dk是缩放因子,Vmix,j′V '_{mix,j}Vmix,j′表示输出的细化混合向量。最后,我们根据reshape(split(Vmix,j′))reshape(split(V '_{mix,j}))reshape(split(Vmix,j′))分割V ′mix,j,从而生成融合交互特征Fu,j′F '_{u,j}Fu,j′和语义交互特征Fs,j′F'_{s,j}Fs,j′。在任务查询阶段,我们引入两个任务查询模块(即ΦTQM,juΦ^u_{TQM,j}ΦTQM,ju和ΦTQM,jsΦ^s_{TQM,j}ΦTQM,js),构建空间细粒度交互以生成更精细的任务特定特征表示。我们将所有下标统一表示为x={u,s}x = \{u, s\}x={u,s}以简化表达,其中Fu,jF_{u,j}Fu,j和Fs,jF_{s,j}Fs,j定义为任务查询特征Fx,jF_{x,j}Fx,j,Fu,j′F '_{u,j}Fu,j′和Fs,j′F'_{s,j}Fs,j′定义为任务交互特征Fx,j′F'_{x ,j}Fx,j′。具体来说,Fx,jF_{x,j}Fx,j和Fx,j′F'_{x,j}Fx,j′被转换为任务查询向量Vx,jV_{x,j}Vx,j和任务交互向量Vx,j′V'_{x,j}Vx,j′。如图6所示,与原始的自注意力机制不同,我们将Vx,jV_{x,j}Vx,j作为任务查询,Vx,j′V'_{x,j}Vx,j′作为键和值。因此,Vx,jV_{x,j}Vx,j和学习到的Vx,j′V'_{x,j}Vx,j′通过矩阵乘法构建长程交互,产生细粒度的任务特定特征表示。Vx,jV_{x,j}Vx,j和Vx,j′V'_{x,j}Vx,j′通过三个可学习矩阵WQ^W_{\hat{Q}}WQ^、WK^W_{\hat{K}}WK^和WV^W_{\hat{V}}WV^映射到Q^x\hat{Q}_xQ^x、K^x\hat{K}_xK^x和V^x\hat{V}_xV^x,可以表述为:
KaTeX parse error: Got function '\hat' with no arguments as subscript at position 50: … = \{ V_{x,j}W_\̲h̲a̲t̲{Q},V'_{x,j} W_…
这里,K^x\hat{K}_xK^x和V^x\hat{V}_xV^x执行缩放点积计算,然后通过softmax操作获得注意力分数。接下来,注意力分数应用于Vx,jV_{x,j}Vx,j以生成精细的任务相关向量Vx,j′′V''_{x,j}Vx,j′′。最后,Vx,j′′V''_{x,j}Vx,j′′通过reshape操作生成任务相关特征Fx,j′′F''_{x,j}Fx,j′′,其中Fx,j′′F''_{x,j}Fx,j′′分别表示融合相关特征Fu,j′F '_{u,j}Fu,j′和语义相关特征Fs,j′′F''_{s,j}Fs,j′′。
C. 架构
如图3所示,我们的方法由CRL框架组成,包括ΦE,jirΦ^{ir}_{E,j}ΦE,jir、ΦE,jvisΦ^{vis}_{E,j}ΦE,jvis、ΦFDM,jvisΦ^{vis}_{FDM,j}ΦFDM,jvis、ΦFDM,jirΦ^{ir}_{FDM,j}ΦFDM,jir、ΦDsrΦ^{sr}_DΦDsr、ΦDcrΦ^{cr}_DΦDcr和ΨHΨ_HΨH。j=1,2,3j = 1, 2, 3j=1,2,3表示特征层级索引。具体来说,ΦE,jirΦ^{ir}_{E,j}ΦE,jir包括三个编码器块,其中每个编码器块包含一个3×3核的卷积层和一个残差层。残差层由两个3×3核的卷积层和跳跃连接组成。ΦE,jvisΦ^{vis}_{E,j}ΦE,jvis具有相同的结构。ΦDsrΦ^{sr}_{D}ΦDsr包括三个解码器块。每个解码器块由一个3×3核的卷积层、一个残差块和一个上采样组成。上采样进行双线性插值和一个1×1核的卷积层。ΨHΨ_HΨH分为三个块。前两个块与解码器块具有相同的结构。最后一个块由一个3×3核的卷积层、一个残差块和一个分类层组成。分类层是一个1×1核的卷积层。此外,我们在编码器-解码器之间添加跳跃连接以充分融合多尺度特征。跳跃连接也在DIFjDIF_jDIFj和ΨHΨ_{H}ΨH之间执行。ΦFDM,jΦ_{FDM,j}ΦFDM,j用于解耦融合特征以生成另外两种模态特征。ΦFDM,jΦ_{FDM,j}ΦFDM,j包括ΦFDM,jvisΦ^{vis}_{FDM,j}ΦFDM,jvis和ΦFDM,jirΦ^{ir}_{FDM,j}ΦFDM,jir。为了生成解耦的可见光特征Fvis,j′F'_{vis,j}Fvis,j′,我们将融合相关特征Fu,j′′F''_{ u,j}Fu,j′′和红外特征Fir,jF_{ir,j}Fir,j输入到ΦFDM,jvisΦ^{vis}_{FDM,j}ΦFDM,jvis。首先,Fir,jF_{ir,j}Fir,j被输入到由一个1×1核的卷积层和PReLU以及一个1×1核的卷积层和Sigmoid组成的非线性变换,以生成增强系数。然后,Fir,i和增强系数相乘以获得强调自身显著部分的红外特征。最后,Fu,j′′F ''_{u,j}Fu,j′′和增强的红外特征执行逐元素减法以生成Fvis,j′F'_{vis,j}Fvis,j′。整个过程可以表示为:
Fvis,j′=Fu,j−(Fir,j⊗σ(C11(δ(C11(Fir,j)))))(8)
F'_{vis,j}=F_{u,j}-(F_{ir,j}\otimes\sigma(C_1^1(δ(C_1^1(F_{ir,j})))))\tag{8}
Fvis,j′=Fu,j−(Fir,j⊗σ(C11(δ(C11(Fir,j)))))(8)
其中σσσ和δδδ分别表示Sigmoid和PReLU激活函数。⊗⊗⊗表示逐元素乘法。此外,ΦFDM,jirΦ^{ir}_{FDM,j}ΦFDM,jir生成解耦的红外特征Fir,j′F'_{ir,j}Fir,j′,具有相同的操作。
DIFjDIF_jDIFj包括ΦFFM,jΦ_{FFM,j}ΦFFM,j、ΦFTM,jΦ_{FTM,j}ΦFTM,j、ΦCTIM,jΦ_{CTIM,j}ΦCTIM,j和ΦTQM,jΦ_{TQM,j}ΦTQM,j。ΦCTIM,jΦ_{CTIM,j}ΦCTIM,j和ΦTQM,jΦ_{TQM,j}ΦTQM,j的详细结构在第III-B节中提供。ΦFFM,jΦ_{FFM,j}ΦFFM,j融合红外和可见光特征以生成融合特征。我们首先连接模态特征Fir,jF_{ir,j}Fir,j、Fvis,jF_{vis,j}Fvis,j,然后通过进行三个3×3核的卷积层获得融合特征。接下来,我们通过进行一个1×1核的卷积层从红外和可见光图像获得权重图W1W_1W1、W2W_2W2。权重图W1W_1W1表述为:
W1=C11(C33(Fir,j⊎Fvis,j))(9)
W_1 = C^1_1 ( C^3_3 ( F_{ir,j} ⊎ F_{vis,j} )) \tag{9}
W1=C11(C33(Fir,j⊎Fvis,j))(9)
其中CnkC^k_nCnk表示"k×kk×kk×k核的卷积+ReLU"层的数量为nnn,⊎⊎⊎表示特征连接。最后,通过对Fir,jF_{ir,j}Fir,j和Fvis,jF_{vis,j}Fvis,j使用通道乘法生成增强的模态特征。W2W_2W2以相同的方式获得。然后,我们通过进行一次3×3核的卷积层连接这两个特征和融合特征Fu,jF_{u,j}Fu,j。特征融合过程表示为:
Fu,j=C31(Fvis,jW1⊎Fir,jW2)(10)
F_{u,j} = C_3^1 ( F_{vis,j}W_1 ⊎ F_{ir,j}W_2 ) \tag{10}
Fu,j=C31(Fvis,jW1⊎Fir,jW2)(10)
ΦFTM,jΦ_{FTM,j}ΦFTM,j将融合特征转换为语义特征。我们对融合特征执行一个3×3核的卷积层和一个1×1核的卷积层。然后,它与融合特征连接以生成语义特征,可以表示为:
Fs,j=C11(C31(Fu,j))+Fu,j(11)
F_{s,j} = C^1_1 (C_3^1 (F_{u,j})) + F_{u,j} \tag{11}
Fs,j=C11(C31(Fu,j))+Fu,j(11)
D. 模型训练和推理
训练:我们联合训练SRi→iSR_{i→i}SRi→i、SRv→vSR_{v→v}SRv→v、CRi→vCR_{i→v}CRi→v、CRv→iCR_{v→i}CRv→i和分割任务。因此,总损失函数可以表述如下:
Ltotal=Lirsr+Lvissr+Lircr+Lviscr+αLs(12)
\mathcal{L}_{total} = \mathcal{L}^{sr}_{ir} + \mathcal{L}^{sr}_{vis} + \mathcal{L}^{cr}_{ir} + \mathcal{L}^{cr}_{vis} + α\mathcal{L}_s \tag{12}
Ltotal=Lirsr+Lvissr+Lircr+Lviscr+αLs(12)
其中ααα是平衡融合和分割任务的超参数。Ls=Lce+Ldice\mathcal{L}_s = \mathcal{L}_{ce} + \mathcal{L}_{dice}Ls=Lce+Ldice表示分割损失,包含交叉熵损失Lce\mathcal{L}_{ce}Lce和dice损失Ldice\mathcal{L}_{dice}Ldice。如果我们考虑像素的分类概率,每个像素都保证被准确分类。Lce\mathcal{L}_{ce}Lce在类别预测中提供准确性,表示如下:
Lce=−1Y∑y=1Y∑c=1Cgy,clog(py,c)(13)
\mathcal{L}_{ce}=-\frac{1}{Y}\sum^{Y}_{y=1}\sum^{C}_{c=1}{g_{y,c}log(p_{y,c})} \tag{13}
Lce=−Y1y=1∑Yc=1∑Cgy,clog(py,c)(13)
其中CCC和YYY分别表示类别数和像素数。gy,cg_{y,c}gy,c表示第yyy个像素属于类别ccc的概率,py,cp_{y,c}py,c是相应的语义标签。Ldice\mathcal{L}_{dice}Ldice通过优化整体区域相似性确保小类或不平衡类别得到适当处理,表示如下:
Ldice=1−1C∑c=1C2∑y=1Ypy,cgy,c+ε∑y=1Ypy,c+∑y=1Ygy,c+ε(14)
\mathcal{L}_{dice}=1-\frac{1}{C}\sum^C_{c=1}\frac{2\sum^Y_{y=1}p_{y,c}g_{y,c}+ε}{\sum^Y_{y=1}p_{y,c}+\sum^Y_{y=1}g_{y,c}+ε} \tag{14}
Ldice=1−C1c=1∑C∑y=1Ypy,c+∑y=1Ygy,c+ε2∑y=1Ypy,cgy,c+ε(14)
其中εεε设置为1×10−71×10^{−7}1×10−7以确保分母不为零。推理:整体框架依赖于源图像的信息,这确保ΦDcrΦ^{cr}_DΦDcr和ΦDsrΦ^{sr}_DΦDsr包含源图像的综合重要特征。由于ΦDcrΦ^{cr}_DΦDcr和ΦDsrΦ^{sr}_DΦDsr共享参数,我们统一表示为解码器ΦDΦ_DΦD。因此,融合结果可以在推理阶段由ΦDΦ_DΦD生成,可以写为:
If=ΦD(Fu,1′′,Fu,2′′,Fu,3′′)(15)
I_f=Φ_D(F''_{u,1},F''_{u,2},F''_{u,3}) \tag{15}
If=ΦD(Fu,1′′,Fu,2′′,Fu,3′′)(15)
其中Fu,j′′,j=1,2,3F ''_{u,j}, j = 1, 2, 3Fu,j′′,j=1,2,3表示由ΦTQM,juΦ^u_{TQM,j}ΦTQM,ju生成的融合相关特征,IfI_fIf表示融合结果。
IV. 实验
A. 设置
数据集:我们在五个代表性数据集上进行实验:Potsdam[44]、WHU[45]、MFNet[46]、M3FD[1]和LLVIP[47]。Potsdam数据集提供城市环境的详细信息,包括6类目标:不透水表面、建筑物、低矮植被、树木、汽车和杂物。它分为30对图像用于训练和7对图像用于测试。WHU数据集描述土地场景,标注为7个不同类别,包括农田、城市、村庄、水域、森林、道路和其他。它包括100对图像,其中80对图像用于训练,20对图像用于测试。MFNet数据集呈现白天和夜间的城市场景,有9个不同的目标类别,包括背景、汽车、行人、自行车、弯道、停车、护栏、颜色锥和减速带。它包含1177对图像,其中784对图像用于训练,393对图像用于测试。此外,三个数据集用于评估语义分割任务的性能。M3FD数据集涵盖不同的光照、季节和天气场景,标注了六个目标类别,即行人、汽车、公交车、摩托车、卡车和路灯。LLVIP数据集提供夜间和白天的道路行人场景,标注了行人类别。M3FD包含1260对图像,LLVIP包含3463对图像,用于测试以评估融合性能。此外,M3FD和LLVIP分别分为训练集(2940和12025张图像)和测试集(1260和3463张图像)以评估目标检测任务的性能。实施:我们的FreeFusion使用pytorch框架在NVIDIA GeForce RTX 4090 GPU上实现。学习率初始化为2×10−5并逐渐衰减到1×10−6。批量大小设置为4。我们使用一阶动量0.9和二阶动量0.99的Adam优化器训练FreeFusion 50个epoch。所有图像都裁剪为320×320的大小。指标:使用六个指标来定量衡量我们的方法:熵(EN)[48]、标准差(SD)[49]、空间频率(SF)[50]、平均梯度(AG)[51]、结构内容差异(SCD)[49]和视觉保真度(VIF)[52]。更大的EN意味着融合图像包含更丰富的细节和信息。更高的SD意味着图像具有更高的对比度和亮度变化。更大的SF表示融合图像中更丰富的纹理表示。更高的AG表示融合结果中包含更锐利的边缘。更大的SCD表示融合图像更好地保留了源图像的结构信息。更高的VIF表示融合图像在人眼视觉感知上更好。此外,我们使用mDice和mAcc指标来评估分割任务的性能。mDice更高意味着模型在所有类别上具有更好的分割性能。更高的mAcc表示模型更准确地分类像素。我们使用mAP50→95来评估目标检测任务的性能。mAP50→95表示以0.05为间隔在0.5到0.95的不同IoU阈值下AP的平均值。更高的mAP50→95表示更好的目标定位能力。
B. 消融研究
跨任务交互模块ΦCT IM的分析:由于融合和分割是两个不同层级的任务,它们之间存在语义失配。如第III-B节所述,我们引入ΦCT IM来实现像素级融合特征和目标语义特征的语义对齐。为了验证其效果,我们研究了不同交互方式对融合结果和语义分割的性能影响。如表I所示,我们的FreeFusion(w/ ΦCT IM)取得了最佳结果。简单的聚合操作(连接和求和)无法直接融合具有语义失配的两个特征,导致融合特征包含较少的信息(例如,像素强度和梯度)。此外,w/o ΦCT IM方法直接利用分割特征通过反向传播方式提示融合特征,这对融合性能的指导有限。相比之下,w/ ΦCT IM方法获得最佳指标分数,相对于w/o ΦCT IM,EN/SD/SF/AG/SCD/VIF提高了2.3% /6.6% /38.5% /32.4% /14.7% /25.6%的相对百分比。通过定性和定量分割实验结果,我们发现不同的变体(连接、求和和w/o ΦCT IM)在不同程度上导致分割性能下降。w/ ΦCT IM在mAcc和mDice上比第二好的方法高出2.7%和2.7%。如图7(b-d)所示,目标(例如汽车)的轮廓无法精确分割,
图8. w/o ΦCT IM和w/ ΦCT IM的特征可视化。©表示融合特征Fu,2从ΦF F M,2输出获得,(d)表示融合交互特征F ′u,2从ΦCT IM,2输出获得。
表II POTSDAM数据集上任务查询模块(ΦT QM)的重要性研究
这说明这些变体生成的融合结果未能保留目标边缘。原因是它们忽略了不同层级任务的特征失配,从而限制了语义特征整合的效果。如图8所示,我们可视化代表性特征来讨论DIF2中ΦCT IM的有效性。显然,图8©中的融合特征缺乏目标语义信息(例如,屋顶目标),导致无法充分提取语义级特征表示。相比之下,如图8(d)所示,w/ ΦCT IM在两个不同层级任务之间实现语义兼容性,促进融合特征包含更多目标语义信息,从而获得更好的融合性能。
任务查询模块ΦT QM的有效性:在第III-B节中,我们引入ΦT QM来细化任务相关的特征图。为了验证ΦT QM在我们FreeFusion中的有效性,我们采用w/ ΦTu QM(在CRL中带有ΦT QM的FreeFusion)、w/ ΦsT QM(在分割任务中带有ΦT QM的FreeFusion)、w/o ΦT QM(在两个任务中不带ΦT QM的FreeFusion)和w/ ΦT QM(FreeFusion)进行比较。表II显示了不同方法的定量结果。w/ ΦT QM与其他三个变体相比获得了最佳的融合性能。此外,w/ ΦTu QM取得了良好的性能,在EN/SD/SCD/VIF上比w/ ΦsT QM高出4.2% /18.7% /126% /4%的相对百分比。w/ ΦTu QM也优于w/o ΦT QM,在EN/SD/SCD/VIF上提高了3% /17% /47.5% /5.9%的相对百分比。与w/ ΦsT QM和w/o ΦT QM相比,w/ ΦTu QM可以在一定程度上提高融合性能,但w/ ΦTu QM在EN/SD/SF/AG/SCD/VIF上仍然比w/ ΦT QM低2.4% /12.9% /54.3% /45.9% /28.3% /30.8%的相对百分比。三个变体的定量结果比较表明,ΦT QM增强了任务内特征图的细粒度表示,从而提高了融合性能。
特征解耦模块ΦF DM的影响:我们设计ΦF DM来交叉重建源图像,迫使融合特征保留源图像的重要信息,从而在不使用任何融合损失的情况下生成融合图像。为了验证ΦF DM的有效性,w/o ΦF DM方法直接使用融合特征重建相应的红外图像和可见光图像,而不是从融合特征中解耦另一种模态特征。如表III所示,w/ ΦF DM的融合性能在EN、SD、SF、AG、SCD、VIF上分别比w/o ΦF DM高出7.5% /40.8% /21.9% /14.9% /385.2% /41.6%的相对百分比。w/ ΦF DM的分割性能在mDice和mAcc上分别比w/o ΦF DM高出0.68% /0.96%的相对百分比。此外,我们在图9中提供了w/o ΦF DM和w/ ΦF DM的融合结果。尽管w/o ΦF DM未能完全保留源图像的主要信息,一些重要信息(例如,屋顶及其纹理)无法有效突出。相比之下,w/ ΦF DM突出了纹理细节,可以明显提高融合性能。此外,在图10(b)-(d)中,单一的红外或可见光图像无法保证分割结果的准确性,例如建筑物和汽车。w/o ΦF DM提高了分割结果的准确性,但仍然无法识别"不透水表面"和"建筑物"类别。w/o ΦF DM的定性和定量评估证明了解耦另一种模态特征以交叉重建源图像的重要性。
图10. 在Potsdam数据集上w/o ΦF DM和w/ ΦF DM产生的分割结果的视觉比较。
表IV POTSDAM数据集上不同超参数α对融合性能的有效性
不同α的分析:表IV显示了不同α对融合性能的影响。当α = 0.1时,模型无法充分利用目标语义信息来帮助融合,这限制了融合效果。当α = 2时,融合性能下降。这表明模型更倾向于提取目标语义特征,导致像素级细节丢失。因此,我们取α = 1,确保模型实现更好的融合性能。
C. 与最先进方法的比较
我们在我们的FreeFusion和最先进的方法之间进行了定性和定量比较,包括YDTR[13]、Tardal[1]、U2Fusion[14]、PIAFusion[15]、SegMif[21]、CDDFuse[16]和Text-IF[53]。
- 定性比较:不同融合方法在Potsdam、WHU和MFNet数据集上的定性结果如图11、12、13所示。红外图像不仅呈现热信息,还包括对比度和纹理信息等其他特征。同样,可见光图像不仅包含纹理信息,还包含颜色、边缘和结构信息。在本节中,我们比较不同方法的融合结果在保留源图像重要特征方面的表现。在图11中,可见光图像呈现高饱和度的颜色信息,红外图像呈现高像素强度的热信息。如红框所示,YDTR、Tardal、U2Fusion、PIAFusion、SegMif和Text-IF无法保留可见光图像的颜色信息。我们可以清楚地观察到树木具有低颜色饱和度和模糊的纹理细节。CDDFuse融合了可见光图像的颜色信息,但失去了高对比度的热辐射信息。以足球门为例,YDTR和Tardal无法保留红外图像的热辐射信息(例如,门框)。相比之下,我们的方法可以融合红外图像中的重要信息(如高强度热辐射信息)和可见光图像中的信息(如纹理和颜色信息)。在图12中,红外图像呈现高对比度信息,可见光图像呈现边缘细节信息。U2Fusion、CDDFuse、Text-IF和我们的方法保留了可见光图像的边缘细节。以城市(例如,建筑物)为例,PIAFusion和SegMif可以最大化融合可见光图像中的边缘细节。Tardal丢失了可见光图像的重要信息,呈现不同程度的目标模糊。相比之下,我们的融合结果可以保留源图像的结构和边缘细节。在图13中,融合结果旨在在夜间条件下保留源图像的目标和背景信息。如红框所示,YDTR、U2Fusion和CDDFuse保留了可见光图像的结构特征,但丢失了红外图像的强度信息。Tardal、SegMif、PIAFusion和Text-IF无法保留结构信息,导致目标信息丢失(例如,人的腿)。Tardal无法根据可见光图像的纹理信息自适应地调整目标区域(例如,行人的裤子)的强度分布,产生模糊的纹理细节。相比之下,我们的融合结果有效地整合了互补信息,清晰地展示了更清晰的纹理细节。总的来说,我们的融合结果可以自适应地融合重要信息,包括显著特征和背景纹理信息。注意,图13中的图像由于其尺寸为320×320而显得模糊。
- 定量比较:在Potsdam、WHU和MFNet数据集上的定量比较如表V、VI和VII所示。在表V中,我们的融合结果获得了最佳指标分数,比次优结果在EN/SD/SF/AG/SCD/VIF上提高了0.9% /2.8% /2.3% /4.0% /4.0% /1.0% /2.3%的相对百分比。在表VI中,我们的融合结果总体上优于其他方法,比次优方法在EN/SD/SF/AG/SCD上提高了2.6% /5.4% /24.8% /17% /6.4%的相对百分比。在表VII中,我们的融合结果取得了有竞争力的性能,比第二好的值在EN/SF/AG/SCD上提高了2.6% /2.2% /7.2% /13.9%。定量结果表明,我们的融合结果从源图像中保留了更丰富的纹理细节、更高的对比度和更大的梯度。如表VIII所示,我们的方法实现了第二快的推理时间,消耗0.0049秒。此外,我们的方法总共产生99.08G FLOPs,其中ΦiEr,j、ΦvEi,sj、ΦD和DIFj分别占21.01G、21.01G、10.30G和46.76G。
D. 泛化实验
为了验证我们FreeFusion的泛化能力,我们选择在WHU数据集上训练的融合模型,直接在M3FD和LLVIP数据集上测试。M3FD和LLVIP数据集的融合结果如图14所示。直观地,红外图像呈现高像素强度的热辐射信息(第一组),可见光图像呈现丰富的纹理细节信息(第二组)。如红框(c1、d1、f1和h1)所示,YDTR、Tardal、PIAFusion和CDDFuse未能保留显著目标区域(例如,白云)的强度分布。此外,Tardal过度强调保留红外图像的热目标信息,导致融合结果无法自适应地调整热辐射信息和纹理信息。如红框(c2-e2和h2)所示,YDTR、Tardal、U2Fusion和CDDFuse丢失了可见光图像的一些纹理细节,伴随着模糊(例如,护柱和人行道)。相比之下,我们的方法自由地保留了可见光图像的纹理细节和红外图像的目标强度信息。这一优势源于我们的方法不使用手工设计的融合损失,使融合图像更全面地保留源图像的所有重要特征。
定性比较如表IX和X所示。在表IX中,与第二名方法相比,我们的融合结果在EN、SD、SF、AG和SCD上分别提高了0.83%、4.74%、18.33%、23.46%和4.65%。在表X中,我们的融合结果在SD、SF、AG和SCD上取得了最佳性能,分别比第二好的结果提高了7.45%、11.78%、9.24%和3.49%。总的来说,我们的FreeFusion在大多数评估指标上实现了优越的性能。
E. 高层任务的性能
- 红外-可见光语义分割的评估:更好的融合结果可以有效地帮助分割任务提高分割精度。我们通过在Potsdam、WHU和MFNet数据集上评估红外和可见光融合图像的分割精度来进一步验证我们方法的有效性。我们方法和其他方法生成的融合结果使用相同的超参数配置重新训练语义分割网络。采用语义分割基准SegFormer[54]。不同方法的定性结果如图15所示。在图15(第一组)中,与其他方法相比,我们的FreeFusion能够有效地突出植被、道路和汽车的信息。例如,YDTR、Tardal、U2Fusion、PIAFusion和Text-IF未能保留可见光图像的颜色和纹理特征,因此分割网络无法识别场景中的"低矮植被"和"不透水表面"区域。在图15(第二组)中,我们的FreeFusion学习红外和可见光图像的互补特征以提高分割精度。例如,可见光图像突出了识别"水域"和"农田"类别的背景信息。现有方法生成的融合结果丢失了可见光图像的重要特征(例如,边缘细节),导致分类不准确。在图15(第三组)中,我们的FreeFusion能够在极端黑暗中识别"汽车"的完整结构。由于SegMif和CDDFuse丢失了红外图像的热辐射信息,融合结果无法帮助分割汽车轮廓(例如,轮子)。相比之下,我们的方法生成的融合结果保留了源图像的重要特征(例如,梯度、目标、轮廓等),从而提高了分割精度。表XI报告了定量结果。与Potsdam和WHU数据集上的第二好值相比,我们的FreeFusion在mDice上提高了0.92% /0.48%的相对百分比,在mAcc指标上提高了0.46% /0.32%的相对百分比。我们的FreeFusion在MFNet数据集的mDice上排名第一,比第二好的值提高了0.29%的相对百分比。这证明我们的FreeFusion生成的融合图像有效地增强了目标和背景信息。
- 红外-可见光目标检测的评估:我们研究了融合结果对M3FD和LLVIP数据集上目标检测性能的影响。具体来说,我们使用我们方法和SOTA方法生成的融合结果重新训练YOLOv5的检测模型。图16显示了不同方法的定性检测结果。在第一组中,现有融合方法未能充分保留可见光图像的完整结构(例如,公交车),过度关注热辐射信息,导致对远处目标的检测不准确。在第二组中,YDTR、U2Fusion、PIAFusion和Text-IF未能充分整合纹理细节和高对比度信息,导致难以检测"人"。尽管其他方法生成的融合结果可以检测目标"人",但模型检测目标"人"的置信度分数仍然低于我们的FreeFusion。相比之下,我们的FreeFusion生成有利于检测的融合结果,帮助目标检测模型在不同场景中实现优越的检测性能。表XII报告了定量结果。我们可以看到,我们的FreeFusion获得了最佳检测结果,在mAP50→95(%)方面分别比第二名方法高出5.91%和1.96%。
V. 结论
本文提出了一种不使用任何手工设计融合损失的红外与可见光图像融合的交叉重建学习方法。特别是,交叉重建学习被设计为解耦融合特征以生成另一种模态特征,从而交叉重建源图像。这确保网络自适应地融合重要特征,并在解耦和重建过程中实现两种模态的域对齐。此外,构建了动态交互融合,解决了两个不同层级任务之间语义失配的困境。因此,设计了两个任务的特征相关矩阵来实现映射对齐,然后在融合过程中实现它们的相互指导。在三个公共数据集上的大量定性和定量实验表明,与现有的最先进方法相比,我们的FreeFusion实现了优越的融合性能,并促进了下游分割精度。FreeFusion通过交叉重建学习实现了两种模态域对齐。然而,由于两种模态特征没有明确对齐,将具有大域差异的源图像映射到同一域空间是具有挑战性的。在未来的工作中,我们尝试利用文本提示从源图像提供明确描述,从而引导两种模态在同一文本空间中对齐以消除域差异。