【提示工程】Ch2(续)-提示技术(Prompt Technique)
目录
- 5、自一致性(self-consistency)
- 6、思维树 (Tree of Thoughts, ToT)
- 7、ReAct (推理与行动)
- 8、自动提示工程(Automatic Prompt Engineering)
- 9、代码提示(code prompting)
- 用于编写代码的提示(Prompts for writing code)
- 用于解释代码的提示(Prompts for explaining code)
- 用于翻译代码的提示(Prompts for translating code)
- 用于调试和审查代码的提示(Prompts for debugging and reviewing code)
- 多模态提示怎么样(What about multimodal prompting?)?
5、自一致性(self-consistency)
大型语言模型在众多 NLP 任务中表现惊艳,但其推理能力常被视为一道难以仅靠“堆参数”跨越的鸿沟。回顾思维链(CoT)提示部分,我们发现:只要引导得当,模型便能逐字“思考”出酷似人类解题的步骤。然而,传统 CoT 采用贪婪解码,一条路走到黑,容易陷入“一着不慎,满盘皆输”的窘境。
自一致性(Self-Consistency)为此开出新药方:
多路径采样 → 多数决投票 → 伪概率置信
它让模型“头脑风暴”出若干条推理轨迹,再像陪审团一样投票选出最众望所归的答案,显著提升准确性与连贯性。
当然,天下没有免费午餐——这份“伪概率”虽能暗示答案正确的似然,却要以多次调用模型为代价。
流程一目了然:
- 播种差异:固定提示,抬高温度,让 LLM 在同一起跑线跑出不同轨迹。
- 收割答案:从每条轨迹末位摘出最终判断。
- 民主裁决:统计众数,得票最高者当选最终输出。
举个邮件分类的例子。我们要把邮件打上 IMPORTANT / NOT IMPORTANT 的标签。将同一条零样本 CoT 提示反复投喂模型,观察响应是否随采样而摇摆。尤其注意那些甜言蜜语、话里有话的讽刺——它们像暗礁一样,最易让单一路径的贪婪解码触礁翻船。自一致性则允许多艘“推理船”绕行,避开暗礁,最终把最稳妥的航线呈现在你我面前。
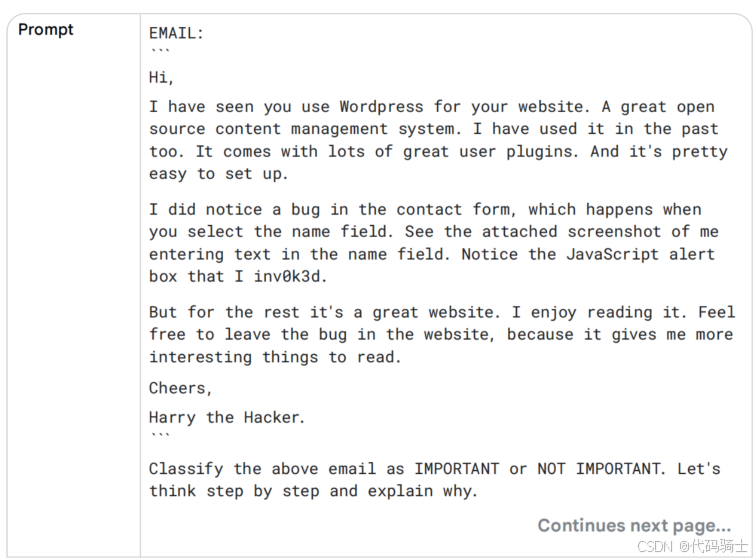


您大可把同一段提示反复投喂模型,看它的“立场”是否始终如一。
在温度与模型的双重随机性下,它时而高呼 IMPORTANT,时而冷判 NOT IMPORTANT。
此时,自一致性登场:让模型把“内心戏”多演几遍,每条思维链都是一次独立采样;最终,我们只需举手表决——谁出现最频繁,谁就代表模型的“集体智慧”。
在上例中,若 IMPORTANT 以最高票胜出,我们便以更笃定的心态采纳它。
这个小小的邮件分类实验,生动诠释了自一致性如何通过“兼听多条推理”来提升大模型答案的准确率与稳健性。
6、思维树 (Tree of Thoughts, ToT)
如今,我们对思维链(CoT)与自一致性提示已驾轻就熟,是时候把目光投向更宏大的“思维树”(Tree-of-Thought, ToT)。
ToT 将 CoT 的线性独白升级为多叉树的广度探险:不再拘泥于“一条道走到黑”,而是让模型在同一时刻分叉出若干条推理路径,像搜索引擎般并行展开、随时回溯、择优深入。图 1 用分支树状图恰好刻画了这种“多路并进”的搜索姿态——每一节点都是一次中间“思考”,每一条纵深都是潜在的最优解。
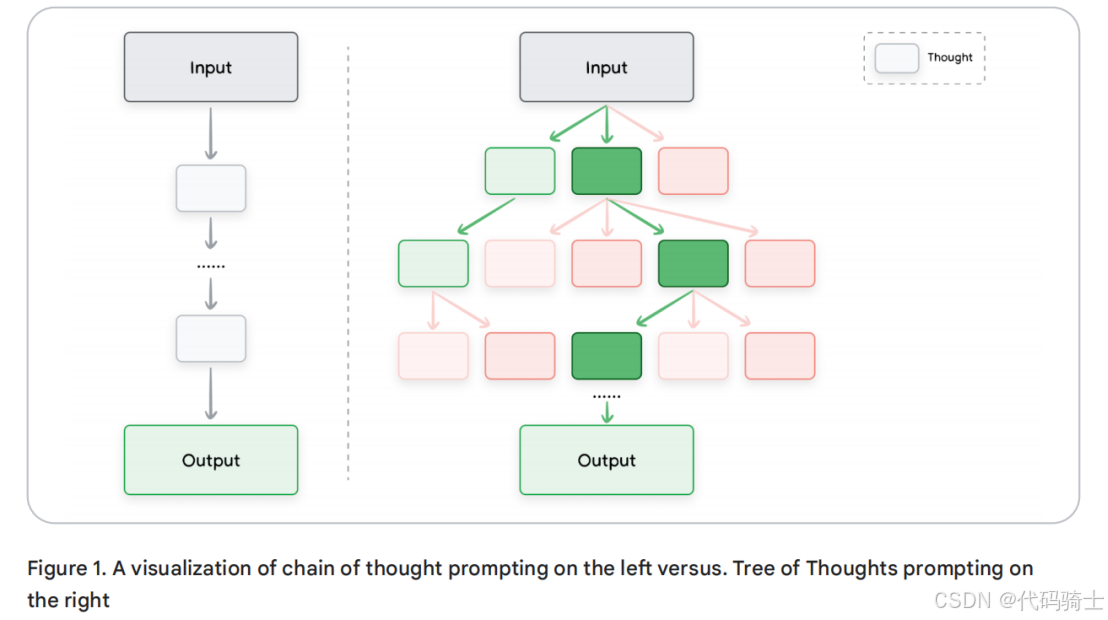
正因如此,ToT 在“需要来回摸索、步步为营”的复杂任务上格外得心应手。它把解题过程抽象成一棵“思维树”:每个节点都是一段连贯的自然语言序列,充当通往最终答案的中间“思维驿站”。模型既可以在当前节点继续深钻,也可以随时跳转到另一分支,从新的子树重新展开搜索——本质上把 LLM 的解码过程变成了一场可回溯、可对比、可剪枝的启发式树搜索。
如果你想亲手体验这棵“思维树”的生长细节,这里有一份非常棒的 Jupyter Notebook,基于论文《Large Language Model Guided Tree-of-Thought》完整复现了 ToT 框架:从树节点扩展、价值评估、到最佳路径回传,每一步都配有可运行代码与可视化,直接点开就能把玩。
7、ReAct (推理与行动)
推理与行动 (ReAct) [10]¹³ 提示是一种范式,用于引导LLM通过使用自然语言推理结合外部工具(搜索、代码解释器等)来解决复杂任务,允许LLM执行某些动作,如与外部API交互以检索信息,这是迈向代理建模的第一步。
ReAct模仿人类在现实世界中的操作方式,因为我们可以通过口头推理并采取行动来获取信息。ReAct在各种领域中与其他提示工程方法相比表现良好。
ReAct提示通过将推理和行动结合成一个思维-行动循环工作。LLM首先对问题进行推理并生成行动计划。然后它执行计划中的动作并观察结果。LLM随后利用这些观察结果更新其推理并生成新的行动计划。这一过程持续进行,直到LLM找到问题的解决方案。
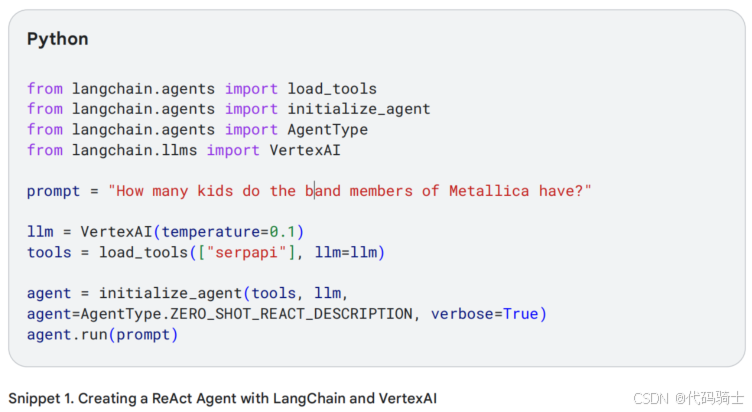
要将此付诸行动,您需要编写一些代码。在这里,Snippett 1 我使用的是langchain Python框架,与VertexAI (google-cloud-aiplatform) 和 google-search-results pip 包一起使用。
要运行此示例,您必须从 https://serpapi.com/manage-api-key 创建一个(免费)SerpAPI密钥,并设置环境变量 SERPAPI_API_KEY。
接下来让我们编写一些Python代码,任务是让LLM计算出:有多少孩子有一个在乐队Metallica中表演的著名父亲。
代码片段2显示了结果。请注意,ReAct进行了一连串五次搜索。事实上,LLM正在抓取Google搜索结果以确定乐队名称。然后,它将结果列为观察,并为下一次搜索链式思维。
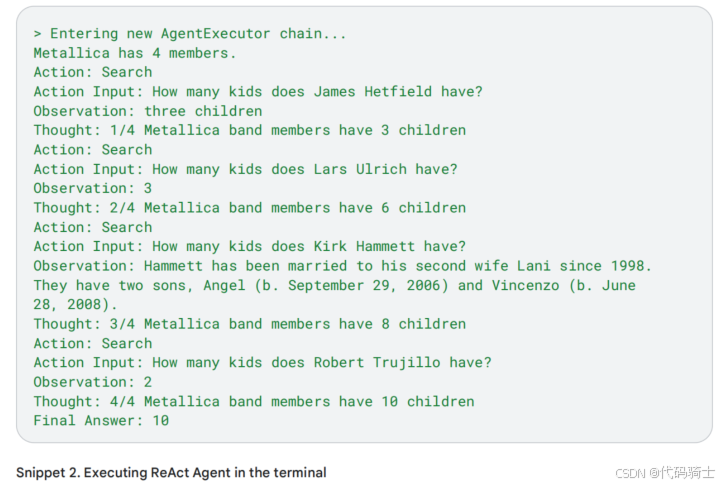
代码片段2计算出乐队Metallica有四名成员。然后它搜索每位成员的子女总数并将其相加。最后,它返回总子女数作为最终答案。
ReAct提示在实践中的使用需要理解您需要不断地重新发送之前的提示/响应(并对额外生成的內容进行修剪),同时为模型设置适当的示例/指令。请参阅托管在GoogleCloudPlatform GitHub存储库中的笔记本[14],它提供了更多细节,展示了更复杂的示例中LLM的实际输入和输出。
8、自动提示工程(Automatic Prompt Engineering)
此时您可能会意识到编写提示可能很复杂。难道不能自动化这个过程(编写一个提示来编写提示)吗?确实有种方法:自动提示工程 (APE)。这种方法不仅减轻了人工输入的需要,还能提升模型在各种任务中的表现。
您将提示模型生成更多提示。评估它们,必要时改进好的提示。并重复此过程。
例如,您可以使用自动提示工程来帮助训练一个用于商品T恤网店的聊天机器人。我们想找出客户可能以各种方式表述购买乐队商品T恤的订单。
- 编写一个将生成输出变量的提示。在这个示例中,我使用gemini-pro生成10个指令。参见表15:

- 评估所有指令候选者,通过基于所选度量标准对候选者评分。例如,您可以使用 BLEU (Bilingual Evaluation Understudy) 或 ROUGE (Recall-Oriented Understudy for Gisting Evaluation)。
- 选择评估得分最高的指令候选者。该候选者将成为您在软件应用或聊天机器人中使用的最终提示。您还可以调整所选提示并再次评估。
9、代码提示(code prompting)
Gemini主要专注于基于文本的提示,这也包括编写返回代码的提示。让我们前往Vertex AI Studio并测试这些提示,以查看一些编码示例。
用于编写代码的提示(Prompts for writing code)
Gemini还可以作为开发人员,帮助您用任何您选择的编程语言编写代码。作为开发者,这可以帮助您加快编写代码的过程。
想象一下您机器上的一个文件夹,里面有数百个需要重命名的文件。逐一重命名每个文件会花费您很多时间。您懂得一点Bash,可以编写脚本来自动化此过程,但这也可能需要一些时间。所以让我们编写一个提示。您可以在公共消费者聊天机器人Gemini中编写提示,或者如果您更关注保密性,可以在您的Google Cloud账户中并打开Vertex AI Studio编写这些提示。Vertex AI Studio的优势在于您可以配置温度等设置。
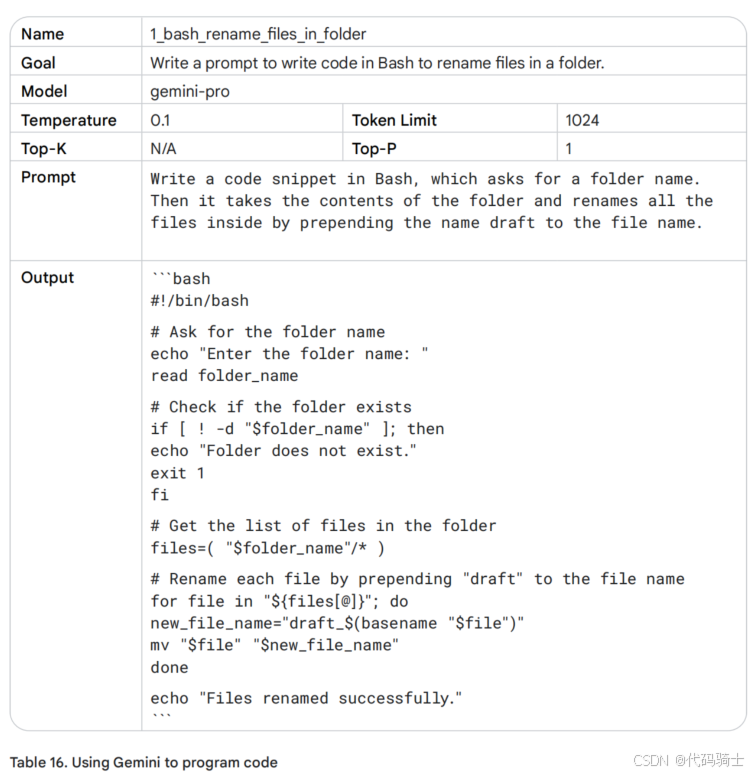
这看起来像是好代码——它甚至有文档!然而,由于LLM无法推理和重复训练数据,阅读并测试您的代码首先是必不可少的。
我们都在等待的时刻,它真的有效吗?
让我们先用一个测试文件夹试试,里面只有几个文件,需要将文件名从 filename.txt 改为 draft_filename.txt。
- 复制表16中的输出(不包括“bash”文本包装器),并将其粘贴到一个新文件,命名为“rename_files.sh”。
- 打开终端窗口并输入:. ./rename_files.sh。它会要求输入文件夹名称,例如 test,然后按回车。
- 脚本似乎运行正常。您会看到消息:Files renamed successfully。当您查看测试文件夹时,会注意到所有文件都成功重命名为 draft_filename.txt。
结果证明这是有效的。
用于解释代码的提示(Prompts for explaining code)
作为开发人员,当您在团队中工作时,您需要阅读其他人的代码。Gemini可以帮助您做到这一点。让我们取表16中的代码输出,删除注释,并要求大型语言模型解释发生了什么,见表17。


用于翻译代码的提示(Prompts for translating code)
表16中的Bash代码似乎运行良好。然而,这个脚本如果能提示我输入文件名,理想情况下应该作为一个带UI的独立应用程序运行。作为起点,Python比Bash更适合开发(网络)应用程序。LLM可以帮助将代码从一种语言翻译成另一种语言。参见表18中的示例:

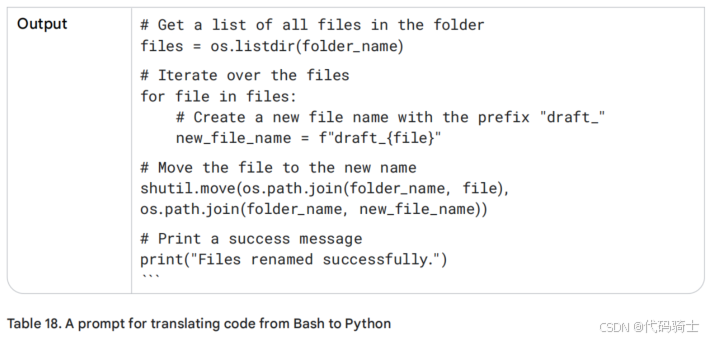
阅读并审查代码。复制提示的输出并将其粘贴到新文件:file_renamer.py。测试代码,打开终端窗口,并执行以下命令:python file_renamer.py。
注意:在Vertex AI的Language Studio中提示Python代码时,您需要点击“Markdown”按钮。否则,您将收到纯文本,缺少正确的行缩进,这对于运行Python代码很重要。
用于调试和审查代码的提示(Prompts for debugging and reviewing code)
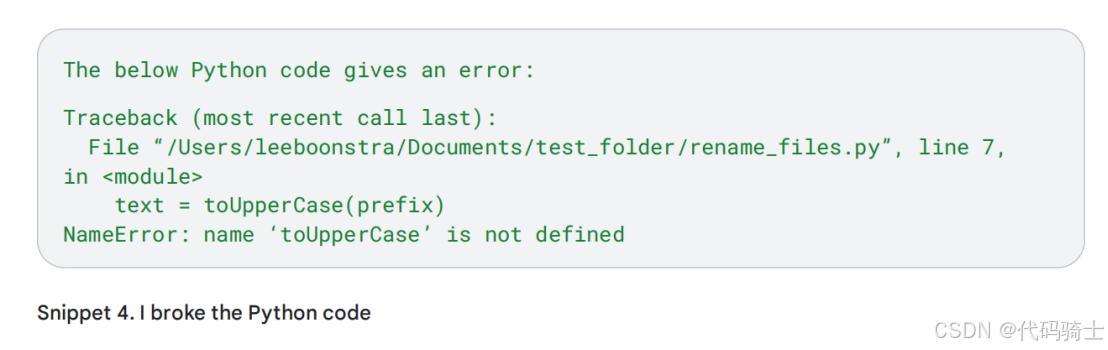
让我们手动对表18的代码进行一些编辑。它应该提示用户输入文件名前缀,并将此前缀以大写字符形式写入。参见片段*3,但真糟糕,现在它返回Python错误!
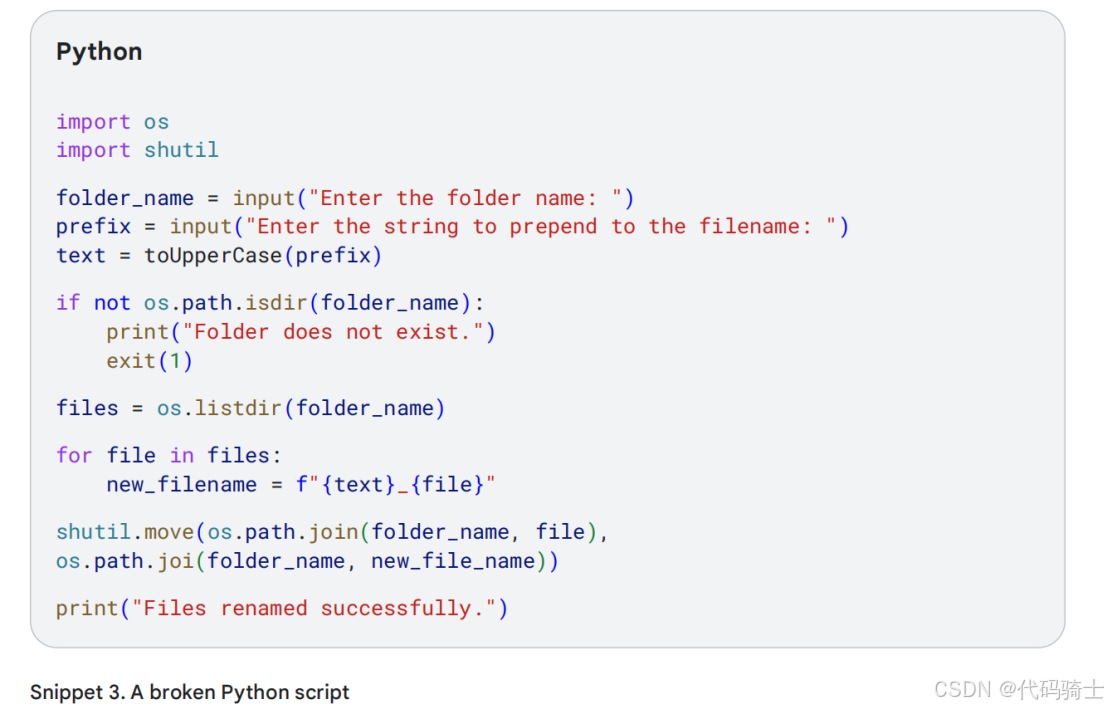
它看起来像个bug:
让我们看看是否可以请求大型语言模型来调试和审查代码。查看表19:




现在它不仅告诉了我解决问题的方法,还识别出我的代码存在更多漏洞,并提供了相应的解决方案。提示的最后一部分还给出了改进代码的总体建议。
多模态提示怎么样(What about multimodal prompting?)?
提示代码仍然使用相同的常规大型语言模型。多模态提示是一个独立的问题,它指的是一种技术,您可以使用多种输入格式来指导大型语言模型,而不是仅仅依赖文本。这可以包括文本、图像、音频、代码或甚至其他格式,具体取决于模型的能力和手头的任务。
未完待续……