众智FlagOS 1.5发布:统一开源大模型系统软件栈,更全面、AI赋能更高效
大模型的发展正深刻地重塑着科技边界。然而,浪潮之下,一个基础性的挑战日益凸显:人工智能的算力基础设施正变得愈发“碎片化”。在AI芯片百花齐放的态势下,不同的硬件架构形成了独立的生态“烟囱”,模型在不同算力间的迁移与适配成本高昂,这不仅制约了技术创新的速度,也阻碍了AI普惠的进程。
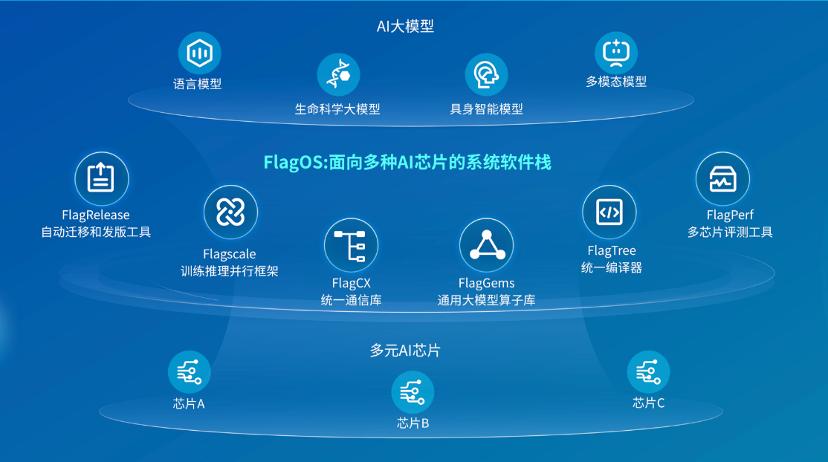
我们相信,要释放大模型的全部潜能,需要一个开放、统一的软件基座来弥合这些裂痕。基于这一理念,北京智源人工智能研究院携手学术界与产业界的众多伙伴,在过去两年多的时间里,持续投入研发了面向多种AI芯片的系统软件栈——众智FlagOS。
今天,我们正式发布众智FlagOS 1.5。这不仅是一次版本迭代,更是我们在全面性、AI能力、性能和应用场景四个维度上取得关键进展的阶段性总结。我们希望借此与社区分享我们的思考与成果,并以开源的方式邀请更广泛的共建。
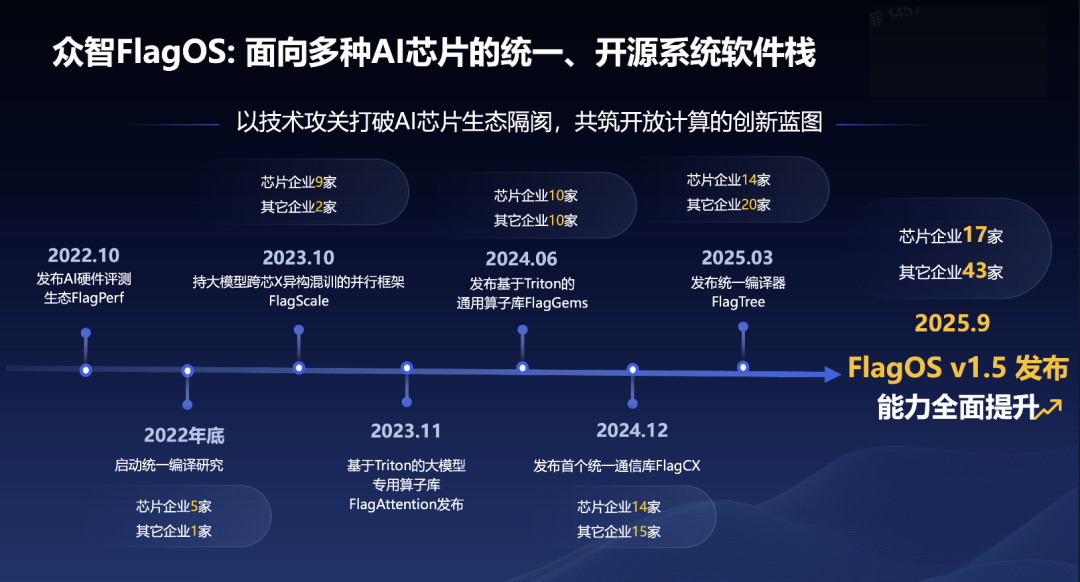
1 FlagOS 1.5 的四大核心进展
一套优秀的统一系统软件栈,离不开兼容性、性能、开发效率与应用价值的持续突破。围绕这四个关键方向,FlagOS 1.5 在本次发布中做出了系统性的提升,力求回应当前AI基础设施在演进过程中面临的核心挑战。
1.全面性:向着更广泛的硬件兼容迈进
FlagOS的核心使命是消除硬件隔阂。在1.5版本中,我们进一步扩展了平台的兼容性:
更广泛的异构芯片支持:现已支持超过 12 家国内外主流芯片厂商的 20 余种芯片型号,大幅降低硬件适配的复杂性。
更完善的组件协同:从算子库(FlagGems)、编译器(FlagTree)到通信库(FlagCX)和并行框架(FlagScale),FlagOS 1.5的各个组件间协同更加紧密,为上层应用提供了稳定、一致的开发体验。
2.性能:在统一之上追求极致效率
统一不应以牺牲性能为代价。FlagOS 1.5通过深度优化,在多个环节实现了显著的性能提升:
训练与推理加速:通过改进并行策略与调度算法,在典型大模型任务中,实现了最高36.8%的训练加速与 20%的推理加速。
通信效率优化:针对大规模集群中至关重要的通信环节,通过深度优化Pipeline,新版FlagCX的通信效率实现了最高2.5倍的增长,并率先支持了跨芯片的异构混合训练。
3.自动化:以AI驱动AI系统软件的开发
我们探索将AI的能力应用于系统软件自身的开发流程中,以期实现开发效率的范式变革:
算子开发的自动化:我们推出了全球体量最大的Triton 算子库以及 Triton-Copilot 工具,后者利用AI技术实现算子代码的自动生成、验证与优化,原先需要领域专家1~2天才能完成的高性能算子开发工作,如今开发新手或研究生也能在1~2小时内完成。
模型迁移的辅助自动化:结合AI Agent技术的 FlagRelease 平台,能够对主流开源模型在不同芯片上的迁移、验证和发布流程提升自动化程度,经测试,其效率相较于传统方法提升了4 倍。
4.应用场景:从大模型到具身智能
软件的价值最终体现在应用。FlagOS 1.5将支持范围从云端大模型,进一步拓展到了前沿的具身智能领域:
端云协同支持:系统全面支持了机器人“大脑”(如智源RoboBrain)与“小脑”(如VLA)模型的开发与部署,打通了从预训练到端侧推理的全链路,为更智能的机器人提供了强大的系统支撑。
支持“超节点”新架构:在北京市科委推动多家企业共同打造的国产高性能算力互联集群“北京方案”中,浪潮信息元脑超节点SD200上,成功实现了基于FlagOS的高效训练和推理,帮助SD200成为首个实现DeepSeek-R1每token推理延迟低于10ms的硬件系统;在海光Nebula超节点上,通过FlagOS的自动优化能力,分钟级搜索出优化策略,在千卡上获得超过98%的弱扩展效率。
2 开放共建,推动AI基础设施协同发展
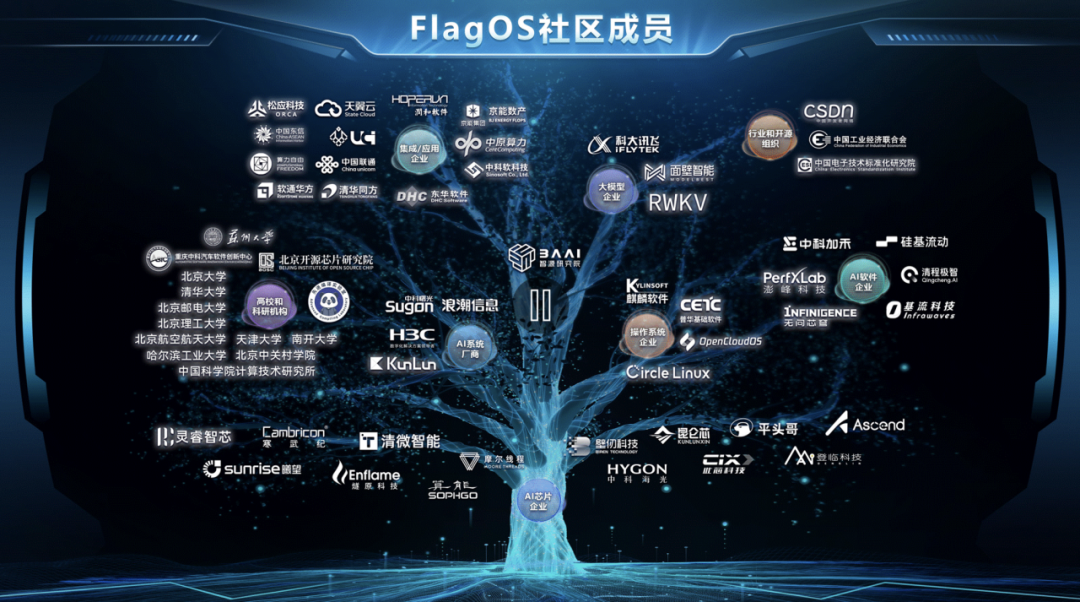
众智FlagOS从立项之初就选择了开源。我们深知,构建一个真正通用、高效的AI系统生态,仅依靠任何单一机构的力量远远不够,需要开放的标准、透明的协作以及全球社区的共同智慧。
我们希望通过FlagOS,构建一个“社区共研发-芯片共适配-模型共受益”的良性循环。我们发布的不是一个封闭的成品,而是一个持续演进的、开放的起点。
构建一个能支撑未来十年、二十年AI发展的软件基座,是一项宏大而艰巨的系统工程。
在此,我们诚挚地邀请全球的开发者、研究人员以及产业伙伴,关注并加入到FlagOS的开源建设中来。无论是贡献一行代码、提出一个建议,还是基于它开发新的应用,都将是这个开放生态不可或缺的一部分。
让我们一起,为智能时代构建一个更加坚实、开放的智算底座。