Redis持久化:RDB和AOF
目录
一、引言
二、RDB持久化
2.1 RDB工作原理
2.2 RDB优缺点
三、AOF持久化
3.1 AOF工作原理
3.2 AOF优缺点
四、结语

一、引言
Redis的核心特点可以用一个字概括:快!其高速性能的关键原因之一,在于它的所有核心数据均直接存储在内存中。主线程执行命令时,无需与磁盘进行交互,从而彻底规避了磁盘IO(输入/输出)带来的性能损耗——要知道,磁盘IO的速度远低于内存操作,是传统存储方案中常见的性能瓶颈。
但内存存在一个天然缺陷:它属于带电易失性存储。一旦服务器重启、意外宕机或遭遇断电,内存中的所有数据都会直接丢失。这意味着,若仅将数据存于内存而不做任何持久化处理,数据的可靠性将面临巨大挑战,甚至可能造成不可挽回的数据损失。
为了解决这一问题,Redis专门提供了RDB(Redis DataBase,快照持久化) 和AOF(Append-Only File,只追加文件)两种持久化机制。它们的核心原理是将内存中的数据定期或实时同步到磁盘文件中;当服务器重启时,Redis再从这些磁盘文件中读取数据并恢复到内存,以此保障数据在故障后仍能有效留存。
二、RDB持久化
RDB(Redis DataBase)是 Redis 默认的持久化方式,其核心原理是在指定时间间隔内,将内存中的 “全量数据” 生成一份二进制快照文件(.rdb)并写入磁盘,类似给数据 “拍照片”。
2.1 RDB工作原理
RDB的出发分为两类,一类是手动触发,另一类是自动触发。
手动触发可以通过以下两个命令来完成:
1)SAVE:会阻塞主线程,直到RDB生成完成。
2)BGSAVE:主线程会创建出一个子进程来给内存中的数据形成快照,写入到磁盘文件中。
因为BGSAVE不会阻塞主线程,所以需要手动触发RDB的场景下,推荐使用BGSAVE。
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> REDIS0010ú redis-ver^F7.0.15ú
redis-bitsÀ@ú^EctimeÂ<82>èÔhú^Hused-mem¸^W^N^@ú^Haof-baseÀ^@ÿáfÑxcý&<9e>以上是Redis为空时dump.rdb(在/var/lib/redis路径下) 文件的内容。下面我们尝试创建几个key,然后执行bgsave命令,接着再次查看dump.rdb 文件。
127.0.0.1:6379> mset key1 111 key2 222 key3 333
OK
127.0.0.1:6379> bgsave
Background saving started
127.0.0.1:6379> REDIS0010ú redis-ver^F7.0.15ú
redis-bitsÀ@ú^EctimeÂÂéÔhú^Hused-memÂ<80>9^O^@ú^Haof-baseÀ^@þ^@û^C^@^@^Dkey2ÁÞ^@^@^Dkey3ÁM^A^@^Dkey1ÀoÿÈNñ´n^B^[<90>我们可以看到,dump.rdb文件中,出现了key1、key2、key3等字样,说明已经对Redis中的数据进行了持久化。
下面我们通过kill -9 命令来将Redis干掉,如果正常退出的话,会自动触发RDB持久化,所以为了演示服务器突然间挂掉的场景,选择了9号信号。

前后两次查到了进程PID不一样,说明Redis已经重启了。下面重新登录Redis客户端,看看数据有没有丢失。
127.0.0.1:6379> keys *
1) "key3"
2) "key1"
3) "key2"
127.0.0.1:6379> mget key1 key2 key3
1) "111"
2) "222"
3) "333"
127.0.0.1:6379> 可以看到重启之后,数据还是得到了保留。
关于自动触发RDB,我们可以看看Redis的配置文件(在/etc/redis路径下)。
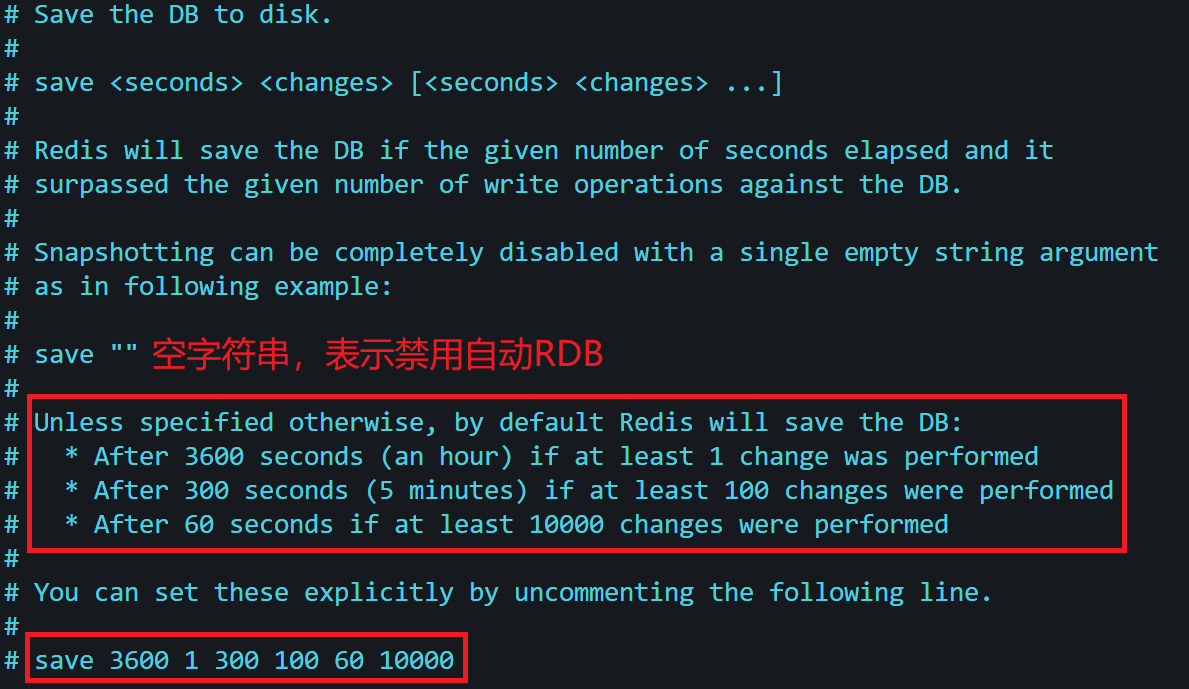
# 规则:save <seconds> <changes>
save 3600 1 # 3600秒内有1次写操作,触发RDB
save 300 100 # 300秒内有100次写操作,触发RDB
save 60 10000 # 60秒内有10000次写操作,触发RDBbgsave执行流程。
- 主线程接收 bgsave命令,调用 fork() 创建子进程(子进程共享主线程的内存数据副本)。
- 子进程遍历内存中的 Redis 数据(如键值对、哈希表等),将数据序列化(二进制格式)后写入临时文件(如temp.rdb)。
- 子进程写入完成后,用临时文件替换旧的 RDB 文件(如temp.rdb),并向主线程发送 “完成信号”。
- 主线程收到信号后,记录 RDB 完成时间,bgsave 流程结束。
2.2 RDB优缺点
| 优点 | 缺点 |
|---|---|
| 1. 文件体积小:二进制压缩格式,占用磁盘空间少; 2. 恢复速度快:加载二进制文件直接入内存,适合大型数据恢复; 3. 性能影响小:BGSAVE 异步执行,主线程阻塞少。 | 1. 数据安全性低:快照间隔内宕机,会丢失该间隔的所有数据(如配置 60 秒 / 10000 次写,若 59 秒宕机,丢失 59 秒数据); 2. fork 成本高:数据量大时,fork 子进程会消耗大量内存(需复制页表),且可能阻塞主线程; 3. 不适合实时备份:无法做到 “秒级” 数据不丢失。 |
我们通过修改配置文件,将 RDB 的触发条件设置为 save 1 1(1 秒内有 1 次写操作就触发 RDB),这样不就做到“秒级” 数据不丢失了吗?
理论上看起来还可行,但是实际上完全不可行。
RDB的核心是全量数据快照。每触发一次RDB,就要创建子进程,创建子进程必经之路就是要复制页表(虽然有写时拷贝,但是不管页表的事,关乎的是数据),数据量越大耗费的时间越长。而且每一秒都要进行全量数据快照,也就是说每一秒都要 fork() ,必然会严重影响到主线程的执行效率。
而且,RDB是异步执行。从触发到完成有一定的延迟。比如在第0秒触发,但快照实际在第 1.5 秒才完成。若第 1.4 秒发生宕机,第 0~1.4 秒的数据都会丢失(超过 1 秒)。
所以,就有了AOF。
三、AOF持久化
AOF(Append Only File)是 Redis 的另一类持久化机制,核心原理是将每一条 “写操作命令”(如 SET、HSET、LPUSH 等)以文本格式追加到 AOF 文件中,类似 “日志记录”。Redis 重启时,通过重新执行 AOF 文件中的命令,即可恢复内存数据。

默认情况下,AOF机制并没有打开,下面我们将它打开(no改为yes),然后重启Redis使其生效。
3.1 AOF工作原理
AOF 的运行分为 命令追加(Append)、文件刷盘(Sync)、日志重写(Rewrite) 三大流程,确保 “数据不丢失” 与 “文件不膨胀”。
1)命令追加:
- 主线程处理每一条 “写操作命令” 时,先执行命令修改内存数据,再将命令追加到 AOF 缓冲区(内存缓冲区,避免频繁写磁盘)。
下面的演示flushall追加到.aof文件末尾。
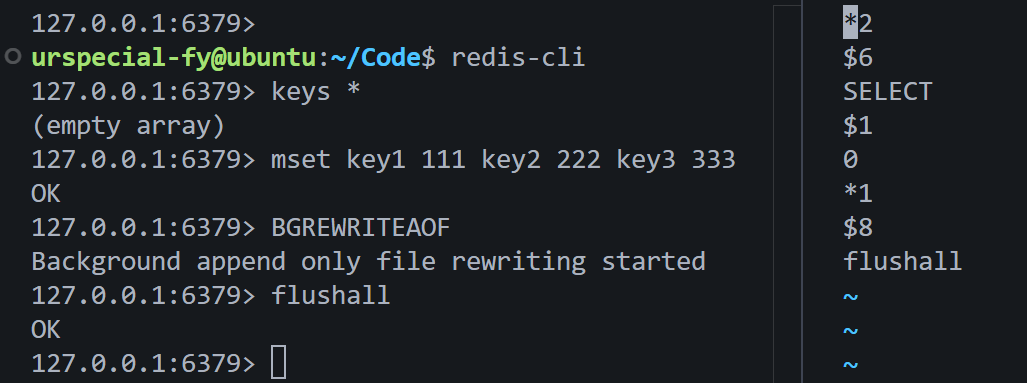
中间手动执行了一次bgrewriteaof命令,精简了指令,所以没看到mset。
2)文件刷盘(Sync):
AOF 缓冲区的内容何时写入磁盘?取决于 刷盘策略(fsync 策略),这是平衡 “数据安全性” 和 “性能” 的关键。
| 刷盘策略(appendfsync) | 原理 | 数据安全性 | 性能影响 | 适用场景 |
|---|---|---|---|---|
always | 每执行一条写命令,立即调用 fsync () 将缓冲区内容写入磁盘 | 最高(不丢数据) | 最低(频繁 IO) | 金融级核心数据 |
everysec | 每秒调用一次 fsync ()(默认),缓冲区内容每秒写入磁盘 | 较高(丢 1 秒内) | 较高(平衡) | 绝大多数业务场景 |
no | Redis 不主动调用 fsync (),由操作系统决定何时刷盘(通常 30 秒~1 分钟) | 最低(丢多) | 最高(无 IO 阻塞) | 非核心缓存数据 |
# appendfsync always
appendfsync everysec
# appendfsync no可以看到,默认是采用每秒写入磁盘。
3)日志重写(Rewrite):
AOF不断追加命令,那么文件就会不断膨胀。举个例子:
127.0.0.1:6379> set key 111
127.0.0.1:6379> set key 222
127.0.0.1:6379> set key 333
127.0.0.1:6379> set key 444
上面执行了4条命令,但是最终结果只用最后一条有用,因为前面的数据都被覆盖掉了。这种情况下,如果不加以斟酌,直接把这4条命令全部刷到磁盘文件中,必然会导致文件膨胀,浪费空间(前3条命令是没必要的)。
我们知道,AOF是以文本的方式直接追加到文件中的,文件太大的话,在加载时就需要耗费比较多的时间,导致Redis重启可能很慢。
为了解决这样的问题,引入了重写。
日志重写的作用是:生成一份 “精简版 AOF 文件”,仅保留 “恢复当前内存数据所需的最小命令集”,替代旧文件。
日志重写的触发方式:
1)手动触发,通过命令bgrewriteaof,上面使用过。
2)自动触发。通过配置 “AOF 文件大小增长率” 和 “最小文件体积” 触发。
auto-aof-rewrite-percentage 100 # AOF 文件大小比上次重写后增长 100%(即翻倍)
auto-aof-rewrite-min-size 64mb # AOF 文件最小达到 64MB 才触发重写(避免小文件频繁重写默认是采用每秒刷盘的策略,随着时间的推移,磁盘中对应文件越来越大,那么就会自动触发重写,为的就是尽可能的避免文件过大。
日志重写的流程:
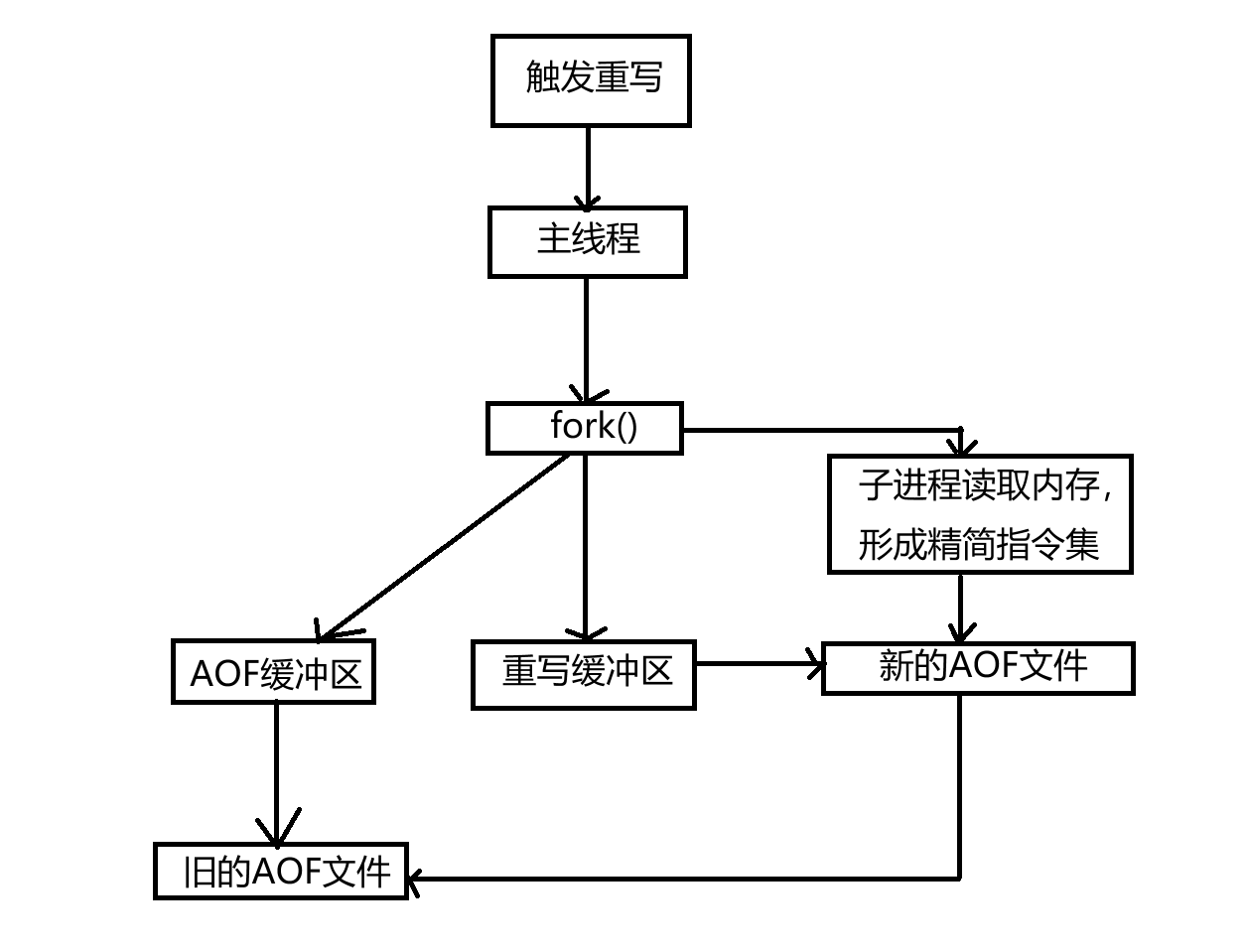
1)触发重写。
2)主线程fork()出一个子进程。子进程读取当前内存数据,生成 “精简命令集”(如多次 SET 合并为一条,过期数据不记录),写入临时 AOF 文件。
3)重写期间,主线程将新的写命令同时追加到 “旧 AOF 缓冲区” 和 “重写缓冲区”(确保重写期间的新命令不丢失)。
4)子进程完成重写后,主线程将 “重写缓冲区” 的命令追加到临时文件,然后用临时文件替换旧 AOF 文件。
5)主线程删除旧文件,重写完成。
为什么在重写期间,主线程还要往AOF缓冲区中写入命令,只写入重写缓冲区不就好了吗?
上面也提到,重写期间,主线程将新的写命令追加到 “重写缓冲区”,然后将重写缓冲区的命令追加到新的AOF文件,是为了避免重写期间的命令丢失。
重写期间,还要坚持往AOF缓冲区中写入新的命令,因为子进程重写形成新的AOF文件需要时间,在新的AOF文件替换旧AOF文件之前,旧的AOF文件仍然是Redis数据恢复的可靠依据。
假设重写期间不向AOF缓冲区中添加新的命令:
如果重写过程中,Redis意外宕机,新AOF文件尚未生成或不完整,而旧文件又缺少重写期间的新命令,将造成这部分数据永久丢失。
RDB不能频繁触发,因为会影响到主线程的执行效率。AOF机制也每秒刷盘,难道不会影响到主线程的执行效率吗?
RDB如果频繁触发,那么需要频繁拷贝页表,页表的大小要比几条命令大得多,而且这个工作需要主线程参与。AOF机制中主线程,只需要把命令拷贝到内存中的缓冲区,刷盘过程由后台进程异步执行,与主线程解耦。
Redis 会单独启动一个 AOF 刷盘后台线程,专门负责 “将 AOF 缓冲区的命令写入磁盘”,整个过程与主线程无关:
- 后台线程每秒定时唤醒,先将缓冲区数据 “写入操作系统的页缓存(Page Cache)”(内存到内存的拷贝,速度极快);
- 再调用
fsync()强制将页缓存数据刷到物理磁盘(真正的 IO 操作,由后台线程承担耗时,主线程完全感知不到)。
即使 fsync() 因磁盘性能问题耗时较长,也只会阻塞后台线程,不会影响主线程处理请求 —— 这是 AOF 与 RDB 最核心的差异。
3.2 AOF优缺点
| 优点 | 缺点 |
|---|---|
| 1. 数据安全性高:支持秒级(everysec)或实时(always)刷盘,丢失数据少; 2. 文件可读性强:文本格式,可手动修改或恢复(如误删数据,可编辑 AOF 删除误操作命令); 3. 增量记录:仅追加写命令,无全量数据快照的性能开销。 | 1. 文件体积大:文本格式且记录所有命令,磁盘占用远高于 RDB; 2. 恢复速度慢:重启时需重新执行所有命令,数据量大时恢复时间长; 3. 刷盘性能损耗: |
看到这里,可能又会发出疑问:刷盘不是有后台线程来完成,与主线程无关吗?为什么又说always策略刷盘会影响主线程的性能?
明确一点,always策略的刷盘操作与主线程强绑定,且需同步等待磁盘 IO 完成。但是everysec策略是后台异步刷盘。always策略的设计目标是 “最大化数据安全性”(确保每条写命令都落盘,不丢失任何数据),但代价是将磁盘 IO 耗时直接转嫁到主线程,主线程必须等待数据写入磁盘完成才可以继续执行。
四、结语
构思这篇博客的时候,没想到那么大的篇幅,最后也只能硬着头皮完成了。如有错误,还请指出!
完~