计算机视觉 - 物体检测 开山鼻祖 R-CNN系列:Fast R-CNN、Faster R-CNN、Mask R-CNN
| 特性 | R-CNN | Fast R-CNN | Faster R-CNN |
|---|---|---|---|
| 区域提议方法 | 选择性搜索(传统算法) | 选择性搜索(传统算法) | 区域提议网络(RPN)(深度学习) |
| 特征提取方式 | 每个候选区域独立提取(极度冗余) | 整张图像提取一次(共享特征图) | 整张图像提取一次(共享特征图) |
| 训练流程 | 多阶段Pipeline(繁琐复杂) | 单阶段,近似端到端 | 端到端(统一网络) |
| 关键创新 | 首次将CNN用于特征提取 | 共享特征图 解决计算冗余。 RoI Pooling,多任务损失。 | RPN,锚点框,特征共享。 提升提议效率。 |
目录
R-CNN: Regions with CNN features
1. 步骤简述
2. R-CNN的训练三步走
3. 与 OverFeat 比较,未来优化加速版本伏笔
Fast R-CNN 特征图共享 + 池化
Faster R-CNN RPN网络进行提议生成
端到端的进化:区域提议网络 RPN & 参数共享
Mask R-CNN 实例分割
损失函数 + 并行解耦
掩码卷积 + RolAlign
下期预告后续 YOLO系列 + SSD
R-CNN: Regions with CNN features
https://arxiv.org/pdf/1311.2524
核心贡献:通过“区域提议+CNN特征”的架构和“预训练+微调”的策略,首次证明深度学习在目标检测上的巨大潜力。
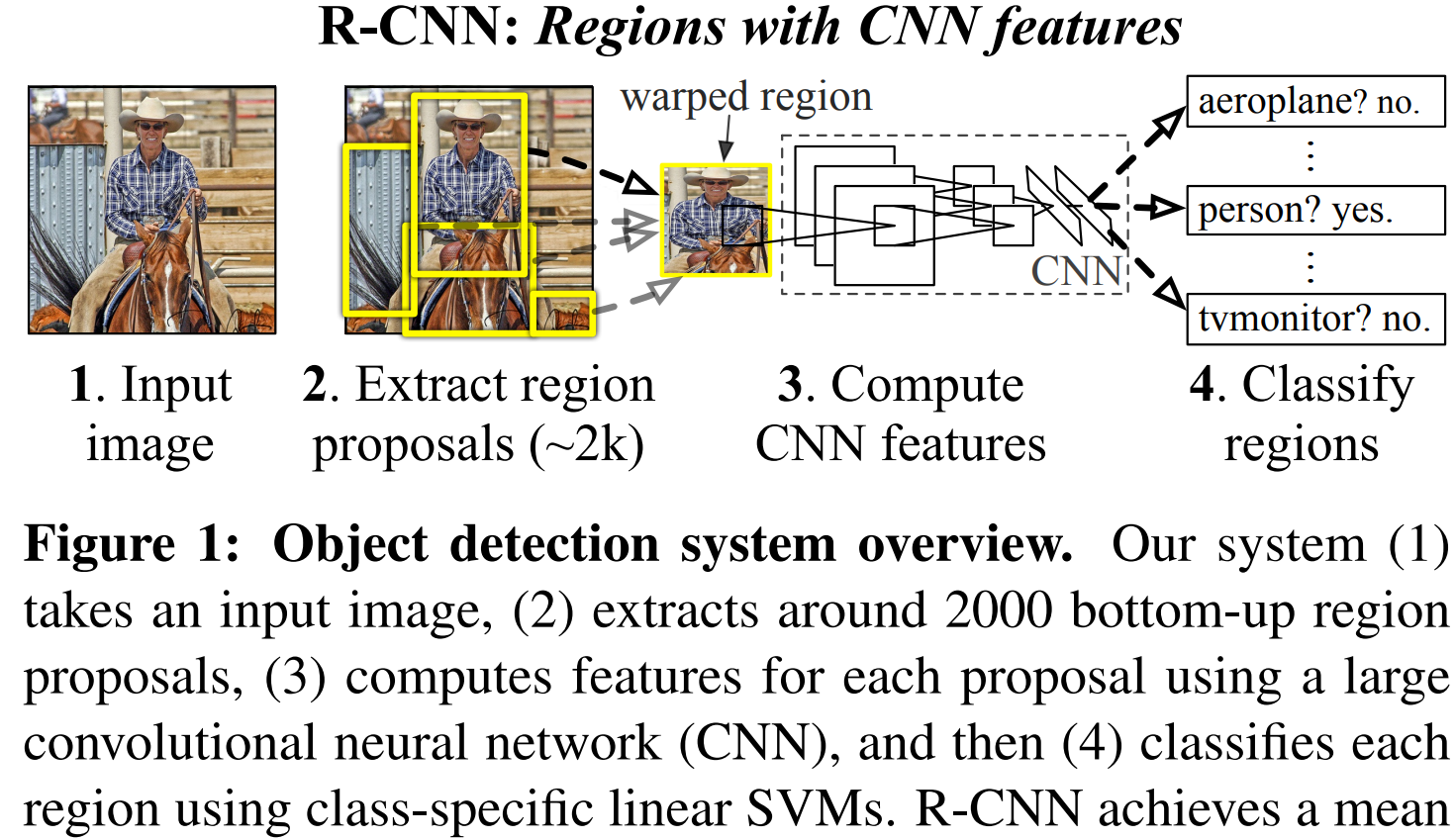
1. 步骤简述
步骤一:生成区域提议
-
目标: 找出图像中所有可能包含物体的区域,避免使用暴力穷举的滑动窗口法。
-
具体操作:
-
使用一种类别无关的区域提议算法(在R-CNN原文中主要使用的是 Selective Search)。
-
Selective Search 的工作方式是:首先根据像素颜色、纹理等信息将图像分割成许多小区域,然后通过一种自底向上的策略,不断地合并最相似的小区域,形成更大的区域。在每一次合并过程中,都会将新产生的区域作为一个候选框输出。
-
这个过程最终会生成大约 2000个 质量较高的候选区域提议。这些提议可能包含物体,但还不知道是什么物体。
-
-
特点: 这一步是“盲目的”,它只关心“这里可能有个东西”,而不关心“这个东西是什么”。它的优势在于召回率高,即真正物体被包含在这些提议中的概率很高。
步骤二:用CNN提取每个提议的特征
-
目标: 将每个区域提议转换为一个固定长度的、能够代表该区域内容的特征向量。
-
具体操作:
-
图像变换: 由于CNN的全连接层需要固定大小的输入,而区域提议是任意形状的,因此需要对每个提议进行缩放(Warping)。
-
前向传播: 将缩放后的
227x227图像输入到一个预训练好的大型CNN中(例如AlexNet)。网络最终在最后一个全连接层输出一个 4096维的特征向量。
-
-
核心创新: 这是首次将如此深层的CNN网络应用于区域级别的特征提取,所得到的特征比手工设计的特征(如HOG、SIFT)强大得多。
步骤三:用SVM对每个特征进行分类打分
-
目标: 判断每个区域提议属于哪个特定类别(如猫、狗、汽车等)还是背景。
-
具体操作:
-
训练类别专用的SVM: 为PASCAL VOC数据集中的每一个类别(共20类)训练一个线性SVM分类器。例如,有一个“猫”SVM,一个“狗”SVM等。
-
分类打分: 将步骤二中提取的每个区域提议的4096维特征向量,分别输入到所有21个SVM分类器(20个物体类 + 1个背景类)中。
-
-
注意点: 为什么用SVM而不是直接用CNN本身的Softmax分类器?在原始论文中,作者发现正负样本的定义(IoU阈值)对性能影响很大,使用SVM并采用一种特定的正负样本定义(IoU<0.3为负样本)能取得更好的效果。
步骤四:应用非极大值抑制(NMS)去除重复检测
-
目标: 对同一物体产生的多个重叠的、重复的检测框进行清理,只保留最好的一个。
-
具体操作(对每个类别独立进行):
-
将所有被分类为“猫”的区域提议,按照“猫”SVM的得分从高到低排序。选中得分最高的那个提议,确认它检测到了一个物体。
-
计算这个最高分提议与剩余所有“猫”提议的交并比(IoU)。如果某个提议与最高分提议的IoU超过一个预设阈值(如0.3),则认为它检测的是同一个物体,于是将其删除(抑制掉)。
-
-
结果: 经过NMS后,每个物体理论上只对应一个最准确的检测框,消除了大量重复框。
步骤五:边界框回归(BBox Regression)进行微调
-
目标: 进一步精修步骤四保留下来的检测框的位置和大小,使其更贴合物体的真实边界。
-
具体操作:
-
训练回归器: 为每个类别单独训练一个线性回归模型。这个模型的输入是区域提议的CNN特征(4096维),输出是4个值
(Δx, Δy, Δw, Δh),分别表示对原始框中心点坐标(x, y)和宽高(w, h)需要进行微调的量。 -
应用回归器: 对于NMS后留下的一个被判定为“猫”的检测框,使用“猫”类别的边界框回归器,根据其特征预测出微调量
(Δx, Δy, Δw, Δh)。 -
执行微调: 使用特定的公式(例如,中心点偏移用加法,宽高缩放用指数函数)将微调量应用到原始检测框上,生成最终更精确的边界框。
-
2. R-CNN的训练三步走
- 用大型图片分类数据集(如ImageNet)预训练一个CNN网络,让它学会识别通用物体特征。
- 用目标检测数据集中的候选区域对这个预训练网络进行微调,把它的分类头从1000类换成检测所需的类别数(如20类+背景),并用宽松的标准(与真实框重叠度≥0.5)定义正负样本来调整网络参数。
- 用微调后的CNN提取区域特征,并以更严格的标准(仅用真实框作正样本,重叠度<0.3的为负样本)为每个类别训练一个线性SVM分类器,来完成最终的物体分类。
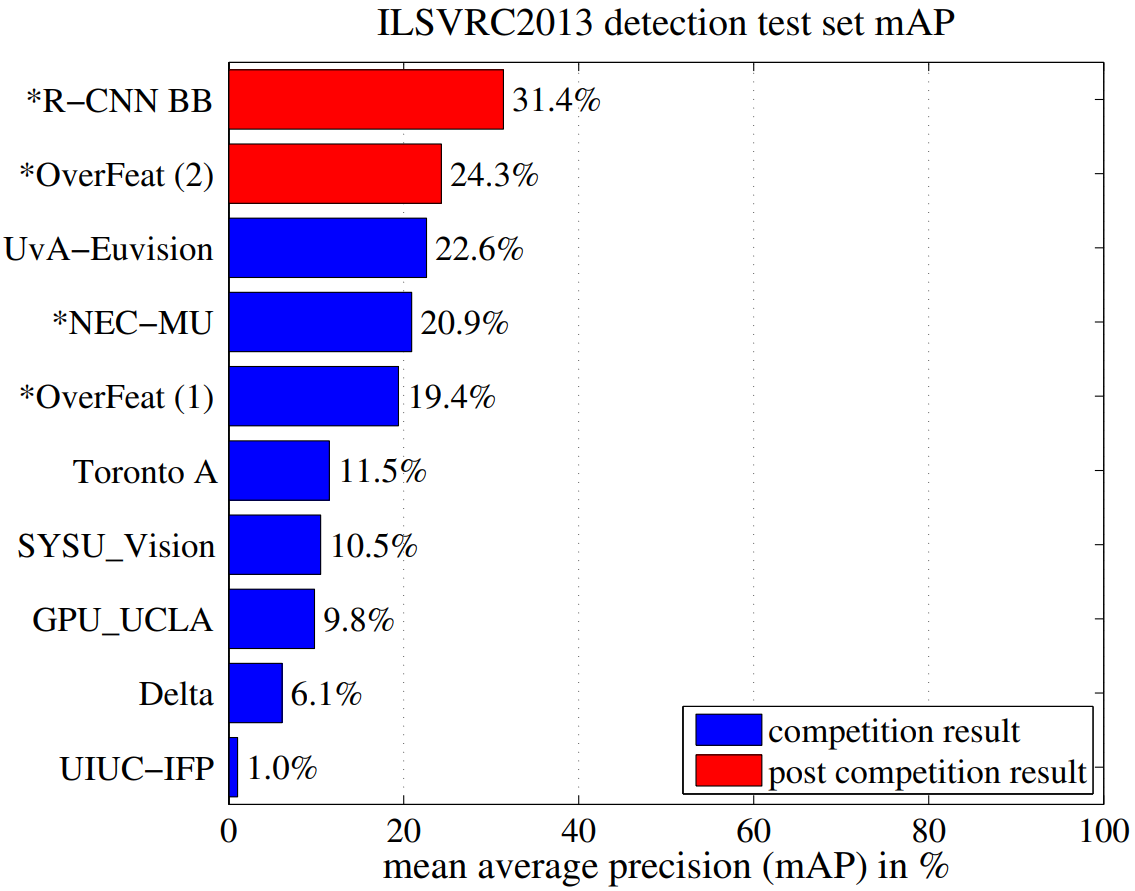
3. 与 OverFeat 比较,未来优化加速版本伏笔
-
速度: OverFeat更快(约快9倍,2秒/图 vs R-CNN的十几秒/图)。
-
原因: OverFeat通过卷积方式在全图上直接计算,天然地共享了重叠窗口的计算,效率极高。而R-CNN需要将每个提议单独扭曲再送入CNN,计算重复度高。
-
-
精度: 如前文所示,R-CNN的精度显著更高(31.4% vs 24.3%)。
-
隐含原因:
-
提议质量: 选择性搜索产生的提议质量更高,减少了搜索空间,降低了分类器的负担。
-
训练策略: R-CNN使用了更精细的训练策略(针对检测任务的微调、使用SVM等)。
-
-
Fast R-CNN 特征图共享 + 池化
https://arxiv.org/pdf/1504.08083
通过一种统一的、端到端的训练框架,加速&提升性能。
R-CNN 的核心问题:
-
重复计算: 对约2000个区域提议中的每一个,都需要独立地通过CNN进行前向传播,计算冗余度极高。
-
多阶段训练: 流程割裂,需要分步训练CNN、SVM和边界框回归器,非常繁琐。
-
存储空间大: 每个区域提议的特征向量需要写入磁盘,占用大量空间。
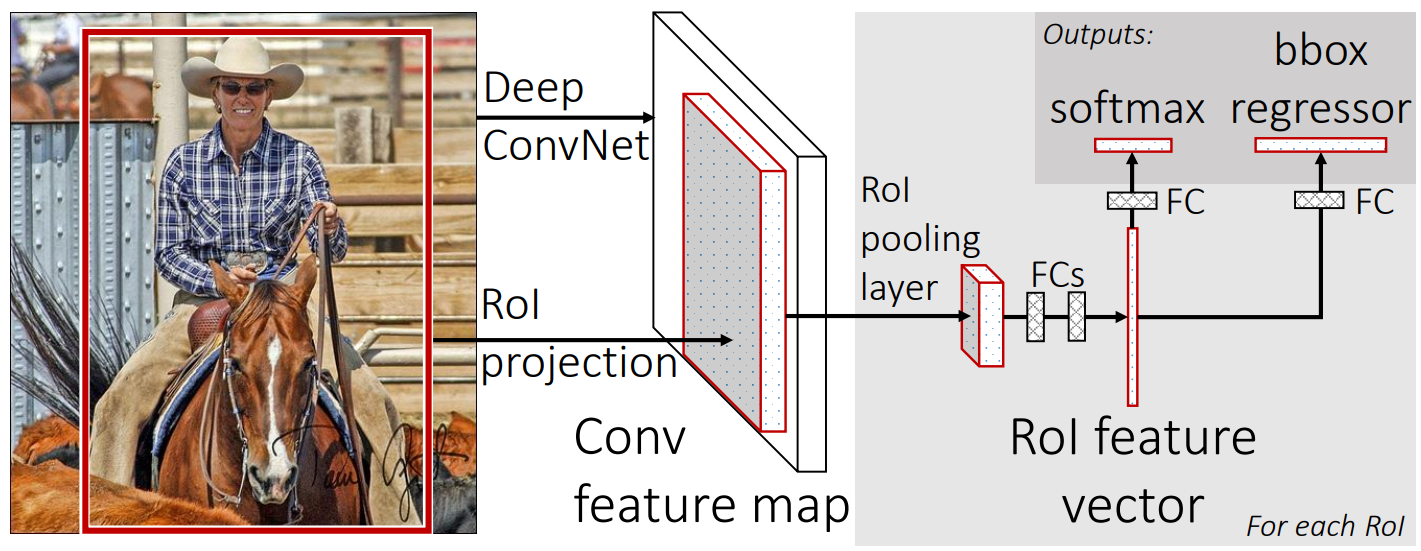
Fast R-CNN 的解决方案:
-
特征图共享(核心创新):
-
做法: 将整张图像只一次通过CNN,得到一个共享的卷积特征图。
-
效果: 避免了重复计算,这是速度提升的根本原因。
-
-
兴趣区域池化层 Rol:
-
问题: 区域提议是任意大小的,如何从共享特征图上为每个提议提取固定长度的特征向量?
-
做法: 引入 RoI Pooling 层。该层将每个区域提议在特征图上对应的区域,统一池化成一个固定大小(如7x7)的特征网格。这样,不同大小的提议都能输出相同维度的特征。
-
-
端到端的联合训练:(合并上面的3-5步)
-
做法: 将分类任务(是什么物体)和边界框回归任务(精修位置)合并到一个网络结构中。
-
在RoI Pooling层之后,网络有两个并列的输出层:一个用于Softmax分类(代替SVM),一个用于边界框回归。合并损失函数 L = L_cls(分类损失) + λ * L_loc(回归损失)。
-
-
Fast R-CNN 的高效训练方法:分层采样
- 做法: 先随机采样 N 张图片(例如 N=2),然后从每张图片中采样 R/N 个 RoI(例如 128/2=64)来组成一个批次。
- 优势: 来自同一张图片的 RoI 在向前和向后传播时,可以共享计算和内存(因为它们来自同一张共享特征图)。这极大地减少了计算量,比 R-CNN/SPPnet 的策略快约64倍。
Faster R-CNN RPN网络进行提议生成
https://arxiv.org/pdf/1506.01497
端到端的进化:区域提议网络 RPN & 参数共享
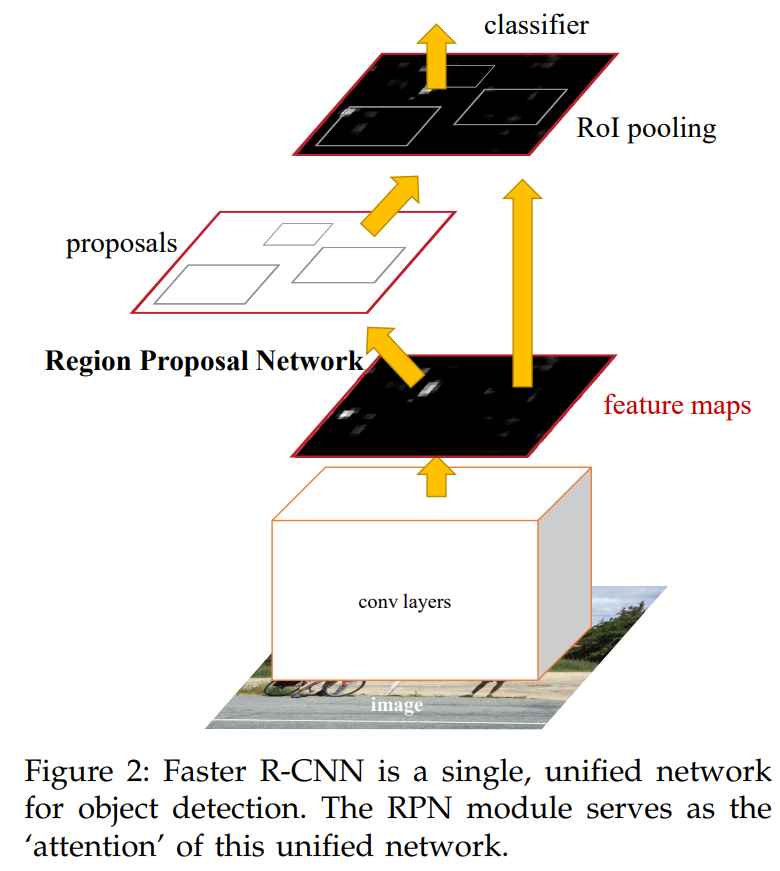
1. 卷积层 -> 特征图; 2. RPN -> 候选框; 3. Rol 池化成统一特征;
(分支合并的箭头 代表RPN 和 R-CNN共享特征参数。)
4. 全连接层 FC 并行输出 类别和边框回归。
| 模块 | 任务 | 分类 (cls) 内容 | 回归 (reg) 内容 |
|---|---|---|---|
| RPN | 区域提议 | 二分类:物体 vs 背景 | 类别无关:调整锚点框逼近物体 |
| Fast R-CNN | 精确检测 | 多分类:具体是哪个物体类别 | 类别特定:为每个类别精细调整框位 |
-
区域提议网络(RPN Region Proposal Network,革命性创新):
-
目标: 用神经网络自己学习生成区域提议。
-
做法:
-
RPN 在最终的共享卷积特征图上滑动一个小网络。
-
在每个滑动窗口的中心,预设多种不同大小和长宽比的框,称为锚点框。
-
RPN 同时为每个锚点框输出两个预测:① 这个框是“物体”的置信度;② 对这个框进行微调的回归参数。
-
-
效果: 区域提议的生成也变成了一个可微分的、可由网络学习的部分。这意味着它可以在GPU上高速运行,并且能和检测网络一起被优化。
-
-
共享卷积特征:
-
做法: RPN 和 Fast R-CNN 的检测网络(分类+回归)共享同一张卷积特征图。
-
效果: 避免了为两个任务分别计算特征,防止计算冗余和特征不一致。
-
-
训练技巧:
-
4步交替训练:
-
使用预训练的 ImageNet 模型(如 VGG)初始化共享卷积层。
-
仅针对区域提议任务 训练 RPN。
-
用第一步 RPN 生成的提议框来训练 Fast R-CNN,使其学会分类和精修边界框。
-
将第二步训练好的 Fast R-CNN 的卷积层参数复制过来,作为 RPN 的新的共享卷积层初始值。保持这些共享卷积层的参数不变,只微调 RPN 特有的层(即 cls 和 reg 层)。
-
只微调 Fast R-CNN 特有的层。
-
-
样本平衡: 一张图像会产生约 20000 个锚点框,但大部分是负样本(背景)。直接训练会导致模型偏向于预测背景。因此,每个 mini-batch 从一张图像中随机采样 256 个锚点框,并保证正负样本的比例最高为 1:1。如果正样本不足 128 个,就用负样本填充。
-
Mask R-CNN 实例分割
https://arxiv.org/pdf/1703.06870
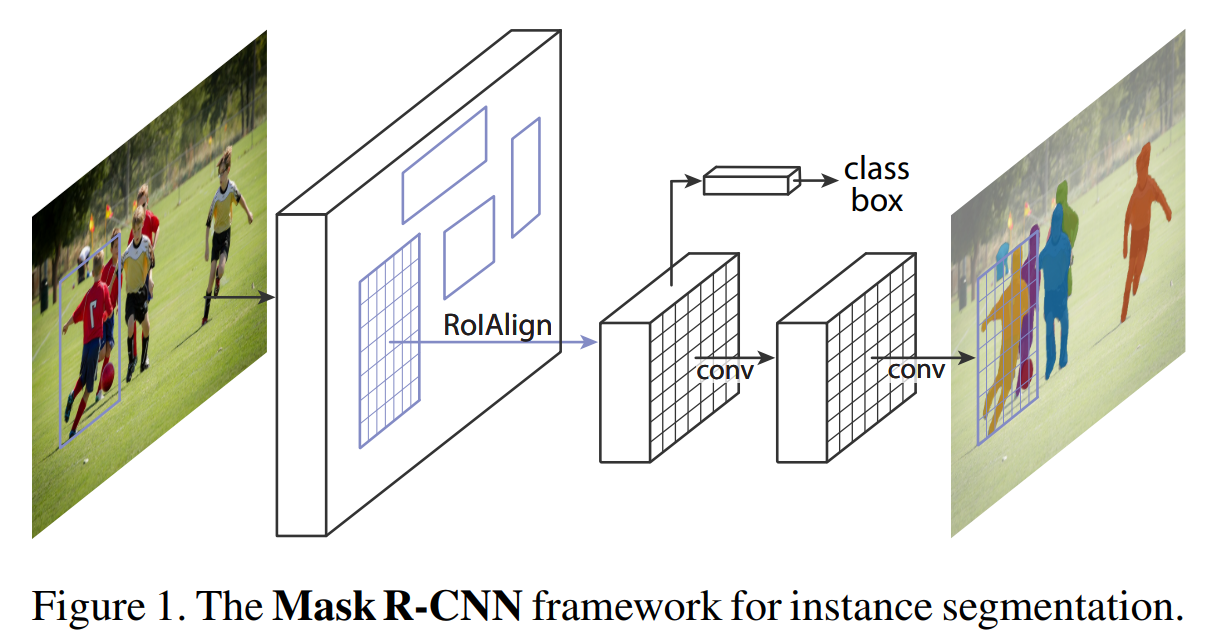
-
在 Faster R-CNN 框架上增加了一个并行的掩码预测分支,从而将目标检测扩展为了实例分割。
-
不同于那些 先分割 再分类的复杂方法,Mask R-CNN 的掩码预测与分类是解耦的(并行互不依赖)。
-
提出了 RoIAlign 层,解决了 Faster R-CNN 中 RoI Pooling 操作造成的空间不匹配问题,极大地提升了像素级定位的精度。

损失函数 + 并行解耦
新损失函数 ![]() 分类损失 + 边界框回归损失 + 新增的掩码损失。
分类损失 + 边界框回归损失 + 新增的掩码损失。
-
对于每个 RoI,掩码分支会输出一个大小为
K × m × m的张量。 -
K是总类别数(比如 COCO 数据集有 80 类)。 -
这意味着网络会为每一个类别都生成一个独立的、分辨率为
m × m的二值掩码。例如,对于同一个物体,网络会同时生成一个“猫”的掩码、一个“狗”的掩码、一个“车”的掩码等等。
实现 并行解耦:
-
掩码分支的责任: 专注于学习如何描绘物体的形状,而不用关心这个物体是什么。它只需要为每个类别生成高质量的轮廓模板。
-
分类分支的责任: 专注于判断物体的类别。
掩码卷积 + RolAlign
掩码是空间信息,空间信息需要用能保持空间结构的全卷积网络 FCN 来建模。
RoIPool 的操作流程里,有两步强制 “量化”(把连续的坐标 / 尺寸,变成离散的整数),误差会使得掩码出问题。
RoIAlign 计算 RoI 在特征图上的位置时,不做取整; 周围取点,进行双线性插值。
因为 bin 的尺寸是连续的(比如 1.457 像素宽),而特征图的像素是离散的(每个像素是一个固定点)
下期预告后续 YOLO系列 + SSD
R-CNN 属于二阶段目标检测算法,其核心是分两步完成检测任务:
第一步先通过选择性搜索等方法生成大量可能包含目标的候选区域(Region Proposal)
第二步再对这些候选区域进行特征提取、分类与边界框回归
整体流程存在 “生成候选区 - 精细检测” 的明显阶段划分,精度高,但速度相对较慢。
而SSD 和 YOLO 系列属于单阶段目标检测算法:
它们摒弃了 “先找候选区” 的步骤,直接在网络对图像提取的特征图上,通过预设的锚点或网格,同步完成目标类别预测与边界框位置回归。
整个检测过程端到端一次完成,无需分阶段处理,因此检测速度远快于 R-CNN。