Moviechat论文阅读

1.摘要
background
最近,将视频基础模型与大语言模型(LLM)结合的视频理解系统展现了巨大潜力,但现有系统只能处理包含极少帧数的短视频。对于长视频(如电影、电视剧),巨大的计算复杂度、高昂的内存成本以及如何连接长时间的上下文信息成为了主要的挑战。现有方法在处理超过几百帧的视频时就会遇到显存瓶颈。
innovation
为了解决长视频理解的挑战,论文提出了一个名为 MovieChat 的新框架。其核心创新点如下:
1.受认知科学启发的记忆机制:借鉴了 Atkinson-Shiffrin 记忆模型,将视频信息处理分为短期记忆和长期记忆。短期记忆是一个固定长度的缓冲区,用于处理眼前的、密集的视频帧信息(Dense Token);长期记忆则通过一个特殊的“记忆巩固”机制,将短期记忆中的信息进行压缩,形成稀疏但关键的记忆(Sparse Memory)进行永久存储。
2.高效的记忆巩固:通过周期性地合并(merge)短期记忆中相似的相邻帧来减少信息冗余,从而将密集的视觉Token转化为稀疏的记忆表示。这个过程无需额外参数,极大地降低了计算和存储开销。
3.显著的效率优势:相比于 Video-LLaMA、VideoChatGPT 等先前方法,MovieChat 在处理长视频时的显存(VRAM)成本降低了约 10000倍。这使得它可以在一块24GB显存的GPU上处理超过10000帧的视频,而其他方法在100帧左右就会崩溃。
4.发布首个长视频理解基准:为了评估模型性能,论文还构建并发布了 MovieChat-1K 数据集,包含1000个长视频和14000个人工标注的问答对。
2. 方法 Method
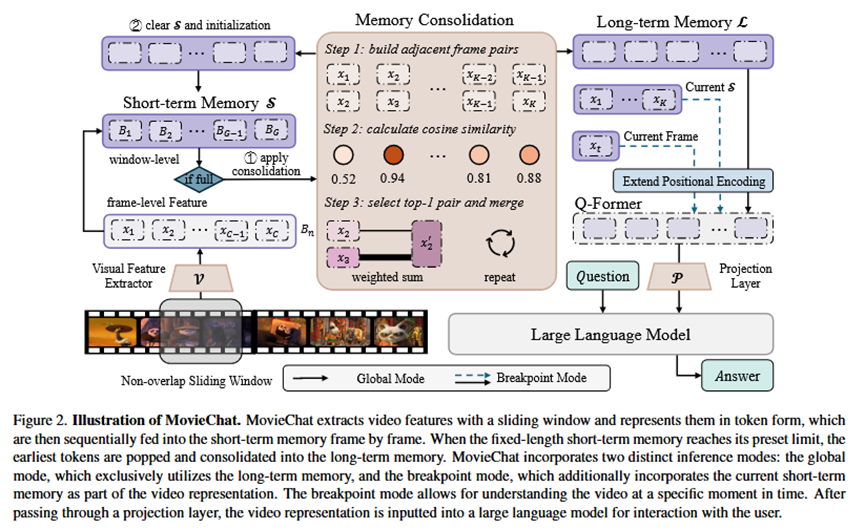
总体流程 (Pipeline):
MovieChat的流程如图2所示,是一个总分结构。首先,模型通过一个滑窗从视频中逐帧提取视觉特征;这些特征(以Token形式表示)被送入一个固定大小的短期记忆模块;当短期记忆存满后,一个记忆巩固模块会将最早进入的、最冗余的帧信息进行压缩,并存入长期记忆模块;最后,根据用户的提问模式(全局理解或针对某个时间点的理解),模型会整合长期记忆和/或短期记忆,通过一个投影层(Q-Former)输入到大语言模型中,生成最终的回答。
各模块详解:
视觉特征提取 (Visual Feature Extraction):
输入:原始视频流(T帧 HxW 分辨率的RGB图像)。
做法:使用一个预训练的、基于图像的ViT模型(如EVA-CLIP的ViT-G/14)和一个Q-former(来自BLIP-2),以滑动窗口的方式逐帧提取特征。这样做是因为强大的视频基础模型较少,且后续的记忆机制能有效捕捉时序关系。
输出:每个视频帧对应的视觉Token序列。
短期记忆 (Short-term Memory, S):
输入:从视觉特征提取模块输出的帧Token。
做法:它是一个固定长度的先进先出(FIFO)队列,用作一个临时缓冲区,存储最近一段时间内的、密集的视频帧信息。
输出:当队列满时,最早进入的帧Token会被“弹出”,送往记忆巩固模块。
记忆巩固与长期记忆 (Memory Consolidation & Long-term Memory, L):
输入:从短期记忆模块弹出的帧Token。
做法:这是框架的核心。它采用一个无参数的迭代合并算法(见Algorithm 1)。算法会计算相邻帧Token之间的余弦相似度,然后贪婪地将最相似的一对帧进行加权平均合并成一个Token。这个过程不断重复,直到Token数量减少到一个预设的阈值。
输出:经过压缩的、稀疏的视频记忆Token,这些Token被存入长期记忆中。
推理模式 (Inference):
全局模式 (Global Mode):用于回答关于整个视频的问题。此时,只有长期记忆 (L) 中的内容被送入LLM。
断点模式 (Breakpoint Mode):用于回答关于视频某一特定时刻的问题。此时,模型会结合长期记忆 (L)、当前的短期记忆 (S) 以及当前帧的特征,一起送入LLM,以提供更具上下文和即时性的回答。
3. 实验 Experimental Results
实验数据集:
MovieChat-1K:本文提出的新基准,专注于长视频理解。包含1000个高质量视频片段(大部分超过10000帧),涵盖纪录片、动画、侦探片等15个类别,并提供14000个问答对。
短视频问答数据集:MSVD-QA, MSRVTT-QA, ActivityNet-QA,用于验证模型在传统任务上的性能没有下降。
实验结论:
1.长视频问答实验(核心实验):在MovieChat-1K上,MovieChat的表现显著优于所有基线模型(如Video Chat, Video-LLaMA)。这是因为基线模型无法处理整个长视频,只能通过稀疏采样几帧来“猜测”答案,丢失了大量信息,而MovieChat能够整合整个视频的上下文。
2.显存成本对比实验:MovieChat的平均每帧显存增量成本(21.3KB/f)远低于其他方法(约200MB/f),展示了其高达10000倍的效率优势,这是其能够处理长视频的物理基础。
3.消融实验:实验证明,去掉记忆机制(w/o MM)后,模型性能会大幅下降,验证了短期和长期记忆模块的有效性。同时,对记忆模块的各个超参数(如长短期记忆的长度、合并的长度等)进行了实验,验证了当前参数选择的合理性。
4.短视频任务实验:尽管专为长视频设计,MovieChat在短视频问答和生成任务上依然取得了与其他SOTA模型相当甚至更好的性能,证明了其方法的普适性。
4. 总结 Conclusion
本文的MovieChat框架通过一个新颖的、受人脑记忆启发的“短期-长期”记忆机制,成功解决了大模型在长视频理解任务上的内存和计算瓶颈。通过将冗余的密集视觉信息压缩成稀疏的关键记忆,它首次让模型能够处理并理解上万帧的视频内容,远超现有系统能力。