基于Go语言实现分布式类地球模拟系统
分布式类地球模拟系统
1 引言
许多科幻与前卫题材的作品中,一直有一个热点的主题:“我们的世界是被计算机模拟的”。与之相应地,“用计算机模拟一个类似的世界”也一直被视为一件在当前技术手段与硬件条件下不可能完成的、近乎科幻的事情。
常见的用计算机模拟世界的相关想法与尝试,一种是以“数字地球”(Digitalearth)为代表,将当前世界的数据与信息完整的录入计算机,实现彻底的数字化。第二中则是寄希望于量子计算等前沿科技手段,大幅提升计算能力后,在计算机里建立世界法则,演算世界运行,从而实现一个模拟世界。概念上讲,相比起对于将现有数据进行数字化的第一种,“量子世界”无疑更加接近“创造一个虚拟世界”的本质。问题在于,要创造一个“量子世界”,量子计算等能大幅提高当前计算机计算能力的手段是不可或缺的,仅凭现有技术与硬件,远不足以建立一个真正意义上的虚拟世界。
然而,科技是在发展的,虽然现在还没引来量子计算成熟化这样的飞跃,但我们也取得了很多新的成果,其中有几件引起了我的注意:分布式系统、去中心化架构、区块链技术(Distributed,DecentralizedandBlockchain)。分布式系统,使得我们可以突破单机硬件条件的限制来扩展系统负载能力,单机性能(计算能力与存储容量)不够,那么就放到集群上去。去中心化架构,则进一步打破单核的分布式系统的集群规模的上限,提升整个系统的健壮与容错性。区块链技术,则给了去中心化架构一把锁,其共识机制能很好的保证无中心状态的集群能稳固的、秩序的运行。
结合上述技术的特点,我提出一个这样的设想:一个“分布式类地球模拟系统”,建筑在一个去中心化的分布式集群上,系统中的每一个用户的设备同时也是集群中的一个节点,每个单机设备承担各自所需的主要计算与存储压力。系统中的两名用户靠近,对系统的同一处进行观测时,数据以点对点(Peer-to-Peer)的方式在两人的设备间交换,当两名用户原理,各自独立的观测不同地方时,两人的设备则各自维护自己所需的那一份数据。换而言之,对于单一用户设备,其单机性能只需满足单一用户所需并能够在可预期的范围内与附近设备进行数据的共享与交换就可以了。
最近分布式、去中心化与区块链等技术都比较成熟了,诸如 Telegram、Everipedia 等项目也让我们看到了相关技术的实际运用前景,“分布式类地球模拟系统”已经不再是一个设想。然而要实际实现它,还有一些其它的技术难题,比如,如何构造一个球体的、足够大的(与地球实际比例尺至少大于 100% 的)“类地球”模型;如何将整个“类地球”模型的庞大数据拆散并进行分布式存储,保证各用户观测模型同一点时得到的结果一致;如何为系统添加足够多的让其更加“真实”的细节,或者说细节是无穷的,如何保证系统能不断的加入这些新的细节;还有系统的部署、客户端的呈现、数据的安全等很多问题。说实话我并没有自信在短时间内全部解决,但我会在文中详细的讨论它们,尽可能的给出可行的默认实现,或可能的解决方案。
本文的结构如下:在第二章会讨论“模拟现实”这个概念,具体地阐述本次研究的背景与想法的来源,然后会整理一些文献,进行技术选型并列出一些技术手段,包括一些开发语言、框架与算法等。接下来在第三章,将分成三部分依次谈谈本系统设计的三大模块:客观(Objective)模块、主观(Subjective)模块以及辅助模块,解释它们的功能用途、技术原理、实现方案等。在第四章将展示该系统设计的一个 Demo 实现,展示一些已取得的成果预览与分析,接着给出一份关于系统的部署、测试与改进的指南,并留下一些更加“疯狂”的进一步设想。最后会对全文进行总结,包括我对“分布式类地球模拟系统”的设计以及 Demo 实现的自我评价。
2 需求与架构
2.1 需求分析
2.1.1 什么是“模拟现实”
“模拟现实(Simulatedreality)”这个概念,在国内似乎不太受到关注。请注意我不是指人们常说的“虚拟现实(Virtualreality.)”,后者(VR)重点在于带给人们如同现实一般的虚拟地(Virtual,形容词)体验,而前者(SR),本质上是一种假说,即:我们的现实可能是仿造的(Simulated,动词)。
显而易见的是,SR 更接近于科幻或其他前卫题材作品里的概念,相对于在当今技术手段与硬件条件下能够实现的 VR 来说,SR 远远没有那么现实。可能也正是由于这个原因,现如今 VR 技术发展的如火如荼,而 SR 相关问题相对冷门,是的,它们可能根本还称不上是一种“技术”,因为缺少很多技术探索与可用实现,只是一些问题,一些科学狂人提出的猜想。
“模拟现实”是一个较大的范畴,其下还有很多分支,比如,“模拟理论”认为现在这个“现实”世界是计算机模拟出来的;“计算主义”认为人的认知与意识等心理活动本身就是一种计算;“梦境论”,呃,这个就比较神学了,我不太了解也不好解释。总之,就我自己而言,我并不在乎现在生活的这个世界是不是虚拟的,我关注的是“模拟理论”(Simulationargument)这个分支,或者说“模拟假说”(Simulationhypothesis),这个假说指出,我们生活的现实是一种人工的模拟,而且很有可能是基于计算机的模拟。反过来说,就是计算机很有可能能够模拟出一个人造的“现实”。
2.1.2 为什么要模拟“类地球”
牛津大学教授、《超级智能》(Superintelligence)作者 NickBostrom 有一个著名的三难选择(Trilemma),他曾经指出,有三个看起来都同不太可能的命题,其中至少有一个是真的:第一,人类很可能在达到“后人类”(posthuman,后人类阶段的文明应当有足够运行大量祖先模拟的计算能力与资源)阶段之前灭绝,第二,任何后人类文明都不可能(即使他们有能力)大量地进行“祖先模拟”(ancestorsimulations,指文明对他们自己或类似文明的历史阶段的模拟),第三,我们几乎一定是生活在一个计算机模拟(computersimulation)(的世界)中[1]。我最看中其中第三点,如果人类能顺利达到后人类阶段,且没什么阻止后人类进行祖先模拟,那么第三个命题,世界是模拟出来的,就很可能是真的。
在我看来,SR 的冷门的待遇与其重要性并不相称,既然人们可以接受日心说,接受地球不是宇宙中心的观点,那么为何不能接受 SR,接受我们的所在并不是最为底层的那个“现实”世界呢?(以 NickBostrom 教授的存在大量嵌套的、虚拟机中虚拟机般的模拟世界的假设为前提)我并不是 SR 的无条件支持者,但我认为我们应当加强对这个理论的重视,未知与不确定容易造成恐慌或盲目,我们应当通过科学的介入来消弭一些这个理论的神秘主义色彩,特别是不要让其为别有用心的人利用来蛊惑人心。
我不是 SR 的无条件支持者,再次声明。但我希望能稍稍揭开一点这个理论的神秘色彩。我不能直接证明第三个命题,即证明世界到底是不是模拟的,这太困难了,但我可以尝试在第一个命题,即人类能不能进行祖先模拟这点上,做点工作。很显然,人类目前还没有达到 NickBostrom 所说的“后人类文明”阶段,即还没有足够的计算能力与资源进行大量的祖先模拟,但或许我的这份工作,可以提前为“人类能进行大量祖先模拟”这个猜想增加一点筹码。
2.2 文献综述
2.2.1 分布系统与去中心化
分布式哈希(DHT)[2]是分布式存储的关键,需要通过合适的 hash 算法把存取派发到集群节点上去(如图 2-1)。要想把模拟系统的地形区块数据分摊到用户设备上,让所有用户访问与共享,首要考虑的就是如何快速低延迟的发现其他可用设备节点。为了解决这个问题,国内外前人已做了大量工作,许多协议与算法应运而生,如 CARP、Chord、Pastry、ROAD[3]等。
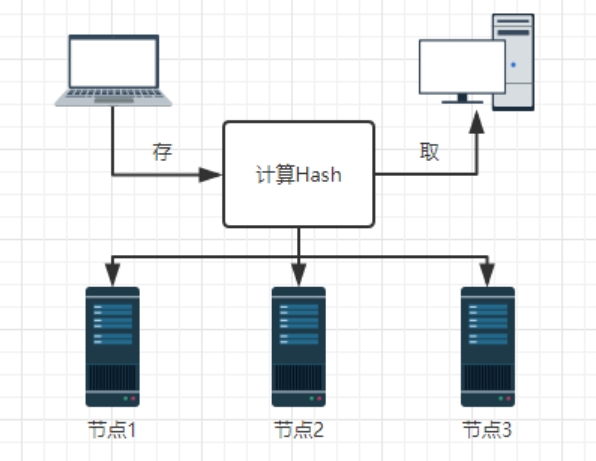
图 2-1 分布式 hash 拓扑图
去中心化的服务需要依托于各个参与者设备的存储与计算资源(如图 2-2),如何避免其中混入攻击者,防止有人作弊甚至多人合谋攻击等是必须考虑的[4]。一方面,为防泄密,我们需要确保任何节点不能单独、提前解读密文[5],但另一方面,我们还要考虑容错个别故障节点、识别与抵抗恶意节点[6]。简单来说,就是需要我们构筑一个可靠的共识系统[7],这不止是区块链,也是任何去中心化服务的重点与难点。
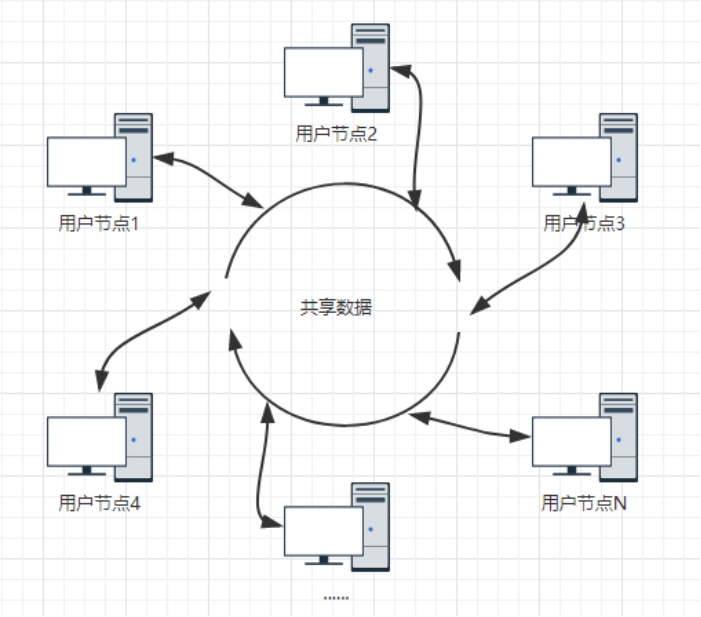
图 2-2 去中心化网络拓扑图
2.2.2 地形生成与球面划分
地形生成技术在 Roguelike 游戏中很常见[8],其中比较经典的如 DwarfFortress,其系统十分复杂且真实,涉及高度、降雨、温度、地质、矿产、生态群落等等细节[9](如图 2-3 与图 2-4)。随着最近 Roguelike 游戏逐渐受到关注,地形生成与自然模拟技术也有了很多新的发展。当前常见地形生成技术有柏林噪声[10]、中点位移[11]、随机分形[12]等等。
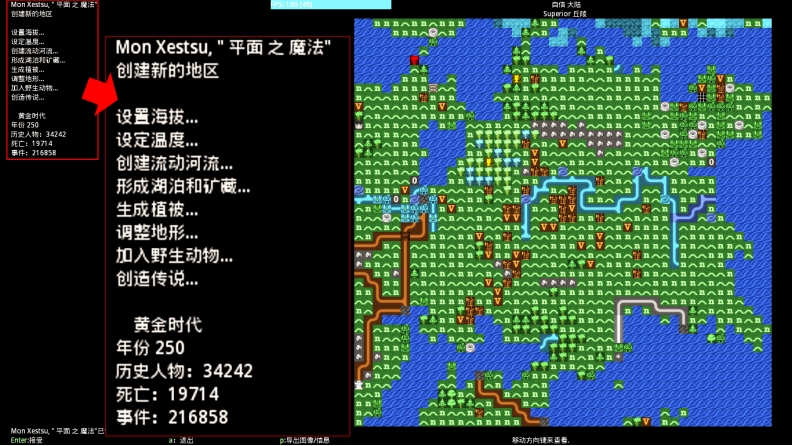
图 2-3DF 随机地形生成
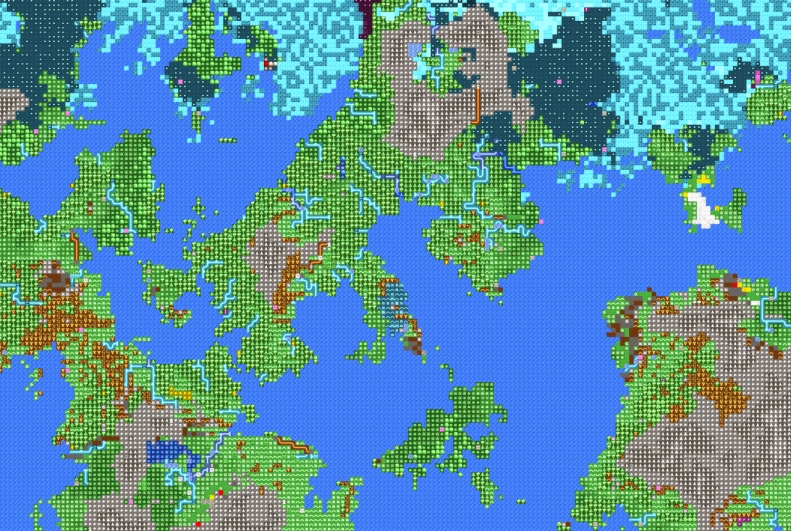
图 2-4DF 随机世界地图
通过查阅相关文献,我收集整理了一些关于当前地球海陆比、平均海拔、大陆分布等参数(如图 2-5),以及相关的数值拟合公式与算法[13]。通过合理运用这些数值调整系统的一些约束条件,以期生成随机但又类似于地球的较为合理的模型。
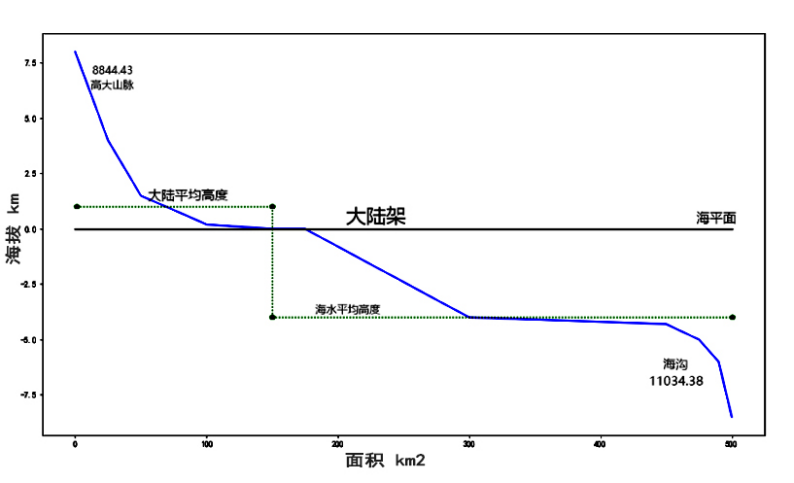
图 2-5 海陆起伏曲线
现在大部分的仿真、游戏与 VR 产品里,球体地图模型比较少见。有的用上下、左右分别相接的循环矩形平面来代替,有的用圆柱体、正方体等来近似拟合,也有的用六边形与五边形拼接密铺球面来抽象。究其原因,我觉得是球面多边形密铺与划分[14]的难题造成的。在查阅相关资料与文献后,我觉得可以挑战一下,这个问题可以通过先用菲波那契网格(Fibonaccilattice)[15]均分球面(如图 2-6),转化为点集多边形划分问题,再用 Delaunay 三角剖分[16]等方法来解决,这样就能构建一个更加真实的球体地图模型了。
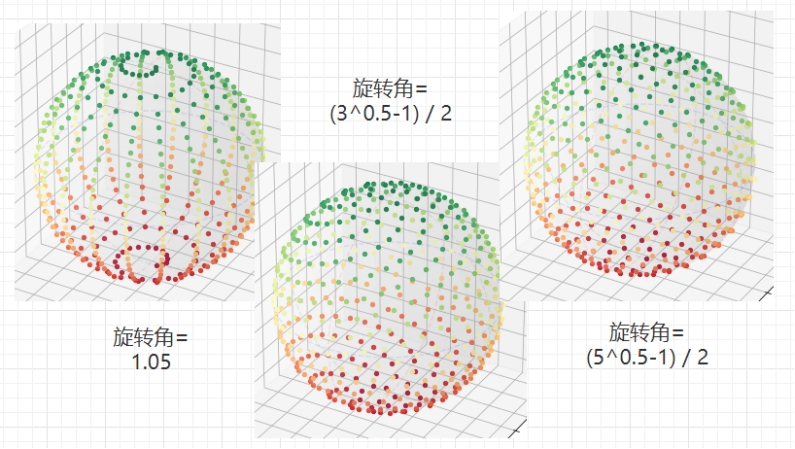
图 2-6 球面网点均匀分布
2.3 技术架构
2.3.1 理论与原理
在讨论这个系统的具体理论与原理之前,我想我们可以先试试“逆向思维”:什么样的系统才称得上是“类地球模拟”?它应该具有什么样的特点与特性?
首先,我并不期望在这个系统里录入现实地球的全部数据,这点交给数字地球去吧;也并不期望这个系统能具有像现实世界一样完整的物理法则,没有量子计算这几乎不可能。说到底,我并没有打算还原真实的地球,这个系统的定位是“类地球模拟”,或者说,是“祖先模拟”(ancestorsimulations)的一个初期尝试。
基于此,我对这个系统的要求“并不高”:
(1)它必须足够大,大到足以让系统内的“人”有“真实感”。
具体来说,我对系统的要求为,其“地球模型”与现实地球的比例尺至少为 100%。但这并不意味着我需要 1:1 的录入现实地球的模型数据,我要的不是现有地球的数字化模型,而是一个类似地球的、能让系统内的人感到“真实合理”的近似模型。
(2)它的负载能力足够强,强到足够让大量的用户参与。
其实更理想的是,系统能自己产生大量的“活着”的先祖,那么就足以证明“后人类”与“祖先模拟”的可能性了。不过理想就先妥协吧,我们先设计让大量现实的用户来进入系统进行交互,至少要证明,建立一个支撑很多先祖“生活”的庞大模拟世界是可能的。
(3)它应当有足够的拓展性,为以后的“发展”做准备。
一个静态的系统是没意义的,我觉得那并不算是一个有效的“祖先模拟”,因为“先祖们的文明”是会发展的。真正的“祖先模拟”应该预见到这种发展,能够不断加入新的细节、新的规则,不至于轻易的让“先祖”们尴尬的看到“世界的边境”。
以上,总结一下就是,称得上“类地球模拟”的系统应该具有的特性有:规模需要足够大、可负载用户足够多、可拓展性足够强。
(1)针对规模足够大
我设计了一套随机地形生成算法的来解决。相比于传统算法,这套算法有一些特点。这套算法可以延迟计算模型上任意位置的地形参数,且任意时刻对同一位置的计算结果是相同的。我们并不需要一开始就将整个 1:1 于地球的庞大模型计算完毕,仅当用户对某处进行观测时我们才需要计算那里的数据。其次,这套算法是允许多起点演算的,我们并不需要从某个原点开始,向某个方向递归演算,某处的数据并不依赖于上一处数据,这使得系统中的用户可以从任意地方开始观测。最后,也是最重要的,这套算法是“并行”的,这套算法的无数个拷贝可以同时在不同的进程、主机甚至不同的平台上运行,它们对模型观测结果都是一致的。这套算法可以把所有数据藏在一个简单的随机种子里,等未来需要的时候才生成。同一系统里,无论何人、无论何时需要这些数据,计算得到的结果与其他人都是一致的。另外,在这套随机生成算法的基础上,我还参考了一些现有地球参数加以修正,以保证生成的模型相较于地球显得足够合理。
(2)可负载用户量的问题
这里就是分布式系统、去中心化架构、区块链技术(Distributed,DecentralizedandBlockchain)发挥作用的时候了。分布式系统,使得我们可以突破单机硬件条件的限制来扩展系统负载能力,单机性能(计算能力与存储容量)不够,那么就放到集群上去。分布式系统当前应用十分广泛,通过集群的力量,毫无疑问确实能大大提高系统的负载能力,但这个提高是有上限的,在中心化的架构里,随着集群不断扩展,集群的复杂度与管理维护成本将大幅提升。这时就需要用到去中心化架构,来进一步打破单核的分布式系统的集群规模的上限,提升整个系统的健壮与容错性。借助分布式与去中心化,我们的系统就可以突破当前硬件条件的限制,理论上做到无限扩展、无限负载。最后,去中心化的集群是不安全的,很有可能由于失去管理而失控,这就还需要结合区块链以技术,特别是其共识机制,来保证这个无中心状态的集群能稳固的、秩序的运行。
(3)针对拓展性的问题
我的思路是,尽量抽取一些基础的、公共的逻辑做成基础设施,预留好接口,提供通过中间件、插件的方式扩展系统模块的能力。举例来说,为模型添加一种新的地貌、给用户添加一项新的操作、系统中添加一种新的规则等可以预期的后续拓展,都应当能够在不破坏现有系统运行的前提下加入,不会打破系统中用户观测到内容的一致性。这就要求系统在设计之初,就得考虑到新地貌、新操作、新规则等内容扩展的需求,不至于在添加这些可预期的新需求的时候,影响到诸如地形生成算法(会导致与旧系统观测到的地形模型冲突)、传输协议(会使得新旧系统之间无法交流)、底层数据结构(直接导致旧系统无法升级)等重要的部分。当然,如果计算能力足够强了(比如量子计算成熟),一次性建立完整的、成熟的、毫无破绽的系统也是没问题的,但这难度太高了,所以我们只要考虑如何使得系统可以不断“进化”,不要比“先祖们”的发展速度慢就可以了。
2.3.2 算法与工具
根据前文的分析与设计,“分布式类地球模拟系统”需要重点考虑与设计的算法有:
(1)随机地形生成算法
前文从理论上分析过,我们需要一个能够延迟的、并发的、多起点的计算与生成模型的随机生成算法。我将通过球面大量均匀布点、二层确定随机(以第一次随机结果作为第二次随机种子)等方式,结合 Perlin 噪声[10],来完成需求的算法。
(2)地球参数拟合与验证
具体来说,我们需要借助 Python 或 Matlab 进行数值计算与拟合,以地球参数为参考,针对模型参数进行调整与优化(比如调节海陆比、大陆分布等),约束随机生成的模型(比如限制 Perlin 噪声生成地形时的波长与频率等),使之尽量合理。
(3)球面均分与区块划分
参考现有研究与文献,我确定采取通过斐波那契网格(Fibonaccilattice)[15]在球面上均匀布点,然后以网点为中心、与周围点连线的中垂线为边,划分出各个网点对应的多边形,这个多边形内所有点都距离这个网点最近,这样整个球面就被均匀地划分成了一系列的区块,球面上任意坐标一定落在某个区块内或极细的交界线上。
(4)去中心化的数据加密
这块可以说是至关重要的,按照设计,用户间的数据交换直接在中心化网络中完成,不用向单一中央设备请求。但系统需要为这张去中心化的网络提供保障,建立可靠的加密机制[17],保证网络中的各用户以及其数据的安全,抵抗故障与干扰,防止恶意攻击与破坏。
(5)区块链与用户共识
系统用户之间可见,用户的各种操作与结果也相互可见。单一用户的操作与数据必须能低延迟的同步给其他用户,保证整个系统的状态对于所有用户一致[18],避免冲突。对于用户的一些重要操作,需要借鉴与参考区块链的 PoW、PoS[19]等机制,比如 Ouroboros[20]等,将其安全的同步到共享网络里,并保证这些操作不可篡改、难以伪造等。
接下来,我会尝试实现一个“分布式类地球模拟系统”的实际可用的 Demo,我将用到的语言、工具、类库有:
(1)Python 与 Anaconda
我将用 Python 进行一些数值拟合、特征提取以及算法的尝试与验证。Anaconda 是一个流行的用于数据科学(DataScience)领域的 Python 发行版,我主要需要使用其中默认包含的 Matplotlib 与 NumPy 两个包,前者是 Python 的 2D 绘图库,能做出类似 Matlab 的效果,后者是 Python 的开源数值计算扩展,方便进行矩阵运算等。相关 License 参见附录 C。
(2)Go 与相关框架
我将用 Go 语言来进行主要模块开发,Go 语言优秀的并发支持与跨平台特性十分适合这个高并发的分布式系统。此外,我还需要用到这些框架:gin-gonic/gin(Go 的高效 Web 框架,用来提供 HTTP 服务)、gorilla/websocket(Go 的 WebSocket 实现,用来支持双向长连接通讯)、emirpasic/gods(Go 的数据结构集成库,包含红黑树、有序 Set 等常用数据结构)、kardianos/service(Go 的跨平台系统服务框架)。相关 License 参见附录 C。
(3)Javascript、three.js、electron、
我采用 JavaScript 与 Web 技术开发诸如仪表盘(dashboard)、监控地图等管理页面。基于 three.js 框架与 WebGL 技术开发主要交互窗口,并基于 NodeJS 与 Electron 完成客户端打包与发布,使其能脱离用户浏览器环境,作为本地桌面 App 独立运行。相关 License 同样都放在了附录 C。
3 设计与实现
本次研究,我将亲手实现一个“分布式类地球模拟系统”的 Demo,我将其拆分成三个主要模块来开发:客观模块(ObjectiveModule)、主观模块(SubjectiveModule)以及辅助模块(Othermodules)。
其中,客观模块负责的是,诸如地形生成、球体建模、区块划分等,不包含用户参与和交互的、系统的多份拷贝以相同参数在不同进程、不同主机、不同平台上各自独立运行时,不经过任何数据交换、不依赖任何存储数据的前提下就能保持一致的功能。直观上来看,客观模块负载的负责就如同自然环境与物理法则一般,是不受“人为”(我是指系统中的用户)干扰的。
与客观模块相反,主观模块负责处理诸如去中心化网络上的数据交换、用户数据共享与安全等功能,主要处理由用户生产的、在用户间的传播的、不同用户各自不同的数据,系统的不同拷贝的主观部分表现可能完全不一致。也即是说,主观部分负责的是有用户参与的“人为”部分的功能。
辅助模块不是必要的,它不是“分布式类地球模拟系统”的一部分,只是我本次 Demo 所实现的特性。本次的 Demo 以“分布式类地球模拟系统”的设计为原型,以其作为后端核心,打造一款类似 Minecraft 的在线多人沙盒游戏。但这并不意味着这个系统本身只能用于这么一款游戏,所以针对这款特定游戏的这些包括服务端、客户端代码,以及一些常用工具在内的部分都被我分到了辅助模块里。不过这并不是说辅助模块不重要,可以理解为,辅助模块是为了把抽象的功能以有形的方式展现而存在,是展现这个系统魅力的重要但不唯一载体。
3.1 客观模块
3.1.1 数值拟合
我并没有直接录入现有地球的详细数据,这对于个人开发者来说也不太现实。如前文曾经分析的,这个系统真正需要的是参考当前地球的一些重要参数作为约束,来避免采用随机算法后生成的模型太过于不合理。下面我将按照系统初始化的顺序,挑一些比较重要的拟数值拟合加以说明。
首先要进行的是“大陆核”gathers 的抽取。gathers 是用来生成大陆分布的,每个 gather 由一个三维向量与一个代表“聚合力度”(gatherstrength)的浮点数构成,一个 gather 就对应一块大陆,聚合力度正比于大陆面积。gathers 的数量并不固定,而是一个遵循正态分布的随机数。
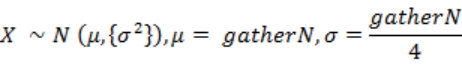
式 3-1 中 gatherN 为可配置参数,代表期望的大陆核数量。
每个 gather 的“聚合力度”则是由当前地球各大陆面积分布拟合而来的,拟合表达式根据可配置参数 gatherExpr 解析,默认如式 3-2。
![]()
式 3-2 中的 x 是 0 到 1 之间的均匀随机数,通过拟合函数使得各大陆核的聚合力度,或者说面积分布满足长尾分布。
有了这些 gathers,我们就能大致确定下整个球体模型表面,哪些地方属于大陆,哪些地方属于海洋。然后当需要时,我们会对某个大陆核计算它的平均海拔等级,我们先为整个模型的平均海拔等级(注意海拔等级不等于海拔,它更接近于海陆占比这样的概念,是负责给出一个概率上合理的参数,而后需要经过海拔拟合得到实际海拔)添加可配置参数 level(浮点类型),然后在这个 level 的上下进行随机浮动,按照下式 3-3 所示,求出这个大陆核的平均海拔等级。
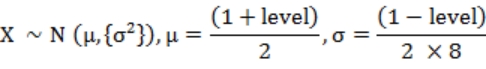
接下来,我们可能会在球体模型上划分出一些“区块”(代码里实际英文名称为 Chunk,区别于后面区块链部分所要用到的 Block),需要计算这些区块的平均海拔。计算某个区块平均海拔的过程如下:首先我们需要从所有大陆核中查找到距离该区块最近的核,并求出这个距离 gd,为此要求我们实现对所有大陆核做某种排序,使之能较快的进行查找,这里具体排序细节不表。接着我们按照前文的过程,计算出这个核心的平均海拔等级 gi,并取出这个大陆核的聚合力度 gs。对了,之前的 gd 是直线距离,我们需要将其转为球面距离,转换函数见式 3-4。

之后我们需要计算一个 wave 参数,它代表“波动力度”,距离与聚合力度之比正比于波动力度,如式 3-5 所示。
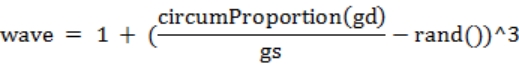
式 3-5 中的 rand()函数代表生成一个 0 到 1 范围内的均匀随机数。现在我们可以计算区块的海拔等级了。
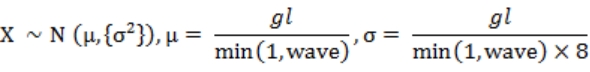
式 3-6 中的 min 函数用于取最小值,目的是舍去式 2-2 计算得出的 wave 中可能小于 1 的部分。现在我们得到了海拔等级,但“海拔等级”不等于海拔,它是一个 0 到 1 间的、概率上比较合理的浮点数。我们需要通过海拔拟合公式把这个参数转化为实际海拔。我们在系统添加两个可配置参数:陆地高度拟合表达式 hightExpr、海洋深度拟合表达式 depthExpr,海拔拟合公式 altitudeFn 由这两个表达式组合并导出。默认情况下这个拟合公式如式 3-7 所示。
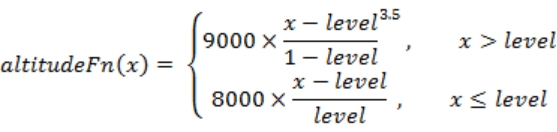
式 3-7 中,level 为前文设定的总平均海拔等级,x 代表传入的海拔等级参数。有了平均海拔、波动力度以及前文得到的区块到核心距离、区块聚合力度等参数,通过它们进行一些组合与调整,就可以计算出一个区块的地形地貌。
然而有一点需要重点强调的,上文中所有公式中涉及随机数的地方,包括正态分布、平均分布、长尾分布等,其随机种子都是根据全局随机种子,加上一些特定参数后生成的,保证了全局随机种子以及特定参数一致的情况下,这些“随机”的结果也一定一致。另外,上文中诸如一些可配置参数与表达式的默认值等大多是拟合验证而来,如图 3-1 所示。
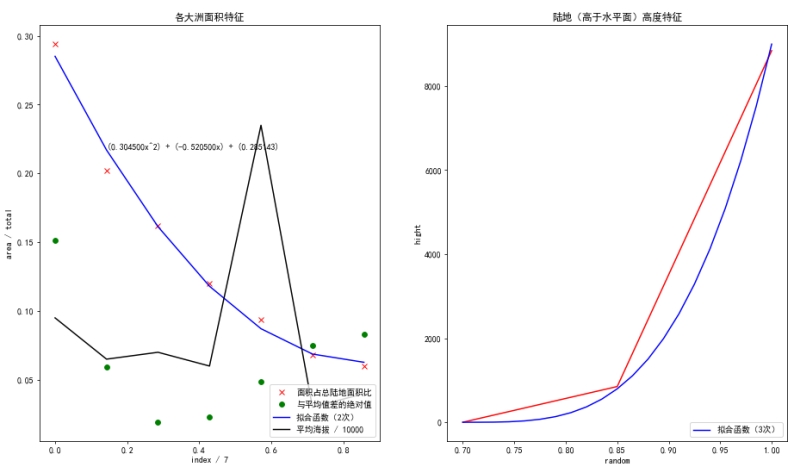
图 3-1 大陆面积高度等数值拟合图像
3.1.2 球面建模
本系统模型将会非常大,设计目标是与实际地球的比例尺至少达到 100%。这意味着,从用户的角度看去,所见范围内无限接近于平面。为了方便进行拟合与运算,我们需要把玩家及其所见范围内的曲面的坐标投影到平面的坐标上去。同时,为了降低系统开销,我决定将系统底层模型拆分成无数个区块,以区块为单位进行曲面到平面的投影,避免随着用户坐标移动而大量进行重新投影计算。这些需要我们能均匀的把球面均匀划分成无数多边形。
“均匀划分”这个问题并不好办,这里对“均匀”的要求,需要各个点距离近似、各个区块面积相近、形状相似,最重要的,要保证球面上任意坐标,除区块间极细的界线外,一定被包含且仅被包含在某一个区块内。在这里,我采用了这样的方案:用斐波那契网格的原理,在球面上,以 Z 轴等等间,X、Y 轴无秩序的方式布点。这个“无秩序”是指,先后步下的两点之间,其 X、Y 轴坐标向量对应的夹角,或者说旋转角度,与圆周角的比是无理数,且这个无理数越“无理”,布点效果就越好。前文中图 2-6 展示了在这个旋转角分别为 1.05、(-1)/2、(-1)/2(也就是黄金分割)时的分布效果。
需要注意的是,这里我们只是参考这个原理,但我们并不需要真的去一次性生成所有的布点。事实上,区块数目是个可变的参数,它可以被设置的非常大,以至于系统模型与真实的比例尺远超 100%,如果我们真的尝试一次性生成所有的区块,数据量将非常庞大。相反,我对原布点算法做了点改造,如式 3-8 所示,不是逐一计算所有点的位置,而是只算出需要的点的坐标。
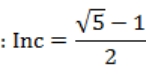
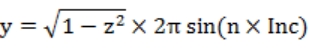
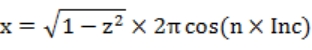
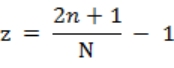
式 3-8 中 N 为设定的总区块数,n 为任意区块号,式 3-8 使得我们完成了对球面的均匀划分,得到了无数划分后的区块,虽然实际没有用到时并没有人知道它们位于哪儿。但这是个问题,实际场景中我们很可能不知道用户坐标所属区块,而是反过来要找到这个区块,我们不可能为遍历全部区块(事实上总区块数可能接近无限)。好在我们采用的斐波那契网格布点的方法,在 Z 轴上等间、有序的分布,我们可以通过从 Z 轴最近处开始向外查找得到目标区块。具体查找算法就不分析了,接下来我们要做的,是对区块进行从三维到二维的投影。对于坐标为(X,Y,Z)的区块,其投影公式如式 3-9。
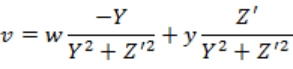
![]()
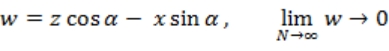
![]()
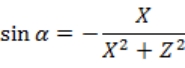
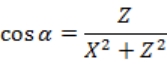
式 3-9 中,(X,Y,Z)为区块坐标,(x,y,z)为区块中待投影点的坐标,(u,v,w)为投影后的坐标,其中(u,v)即为投影到二维坐标系的坐标,w 在 N(总区块数)趋近于无穷大时应当趋近与〇。
3.1.3 地形生成
现在给定任意用户坐标,我们已经可以查找到其所属区块以及临近区块,可以计算得到这个区块所属大陆核以及其相关参数。这些参数一方面对于系统初始化时来说是随机的、延迟的,另一方面却又在系统以一定条件初始化完毕后是可预期的、确定不变的(即使它们仍然是延迟的、未被观测与计算的)。那么可以推知,以这些参数为基础进行的一切确定地演算,甚至以这些参数为随机种子再生成的随机演算,其结果都是确定的。这是这个“类地球模拟”的客观模块之所以可以分布式地运行于完全不同的进程、主机与平台,它们之间毫无交互、不需要任何数据存储或交换,就能保持一致的根本基础。
再次总结上面这段的重点:客观模块之所以能在独立的环境里保持一致,根本基础在于一些虽然延迟、未计算,但观测结果早已在初始化时就确定了。为了方便,后文我将用“可预知”来描述这样的特性。可预知性非常重要,之后的所有客观模块的新增内容,包括地貌、特征、生物群落等等,都绝对不能打破这一点,否则独立的环境里观测到的模型数据就真的变成随机的了。更直观的说,就是两名用户,某一天同时来到了同一坐标,一个看到这里是山,另一个看到这里是水,系统的一致性就被打破了。
下面我们就尝试用这些“可预知”的抽象参数,来进一步生成一些具体有形的数据吧。我们以生成地形为例,假定我们的系统中有三种地形:高山、平原、丘陵,等比例的分布在所有属于陆地的区块(区块的平均海拔等级大于总海陆比),关于分布比例这里我先多提一句,我们并不需要、也很给无穷多的区块各自分配好地形,在这个系统中大部分情况下我们都是自下而上的,只关注用户所观测区域的数据,所以某个地形的分布比例,实际上是以调整任意区块可能属于某地形的概率的方式来保证的,它们并不完全一致,但在足够多的区块下近似一致。
假设某个用户“诞生”在了这个系统里,我们有了一个模型上的坐标。根据这个坐标,我们拿到了诸如区块信息、大陆参数等等“可预知”的基础参数,我们需要用这些参数判定,当前这个用户所在属于高山、平原、丘陵中的哪一类。很明显,这三类的主要区别在于地势起伏,那么我们可能会用到的参数主要有:wave(波动力度)、altitude(平均海拔)、distance(距离)。注意我没有加任何前缀,拿 distance 来说,需要的话,我们可以取得用户到区块原点的距离、区块原点到大陆核心的距离、区块与临近其它区块的距离等等。我基于这些参数进行分析并提取了这三种地形的概率特征,用 P(A)、P(B)、P(C)依次代表高山、平原与丘陵的特征概率,下面将一一解读。
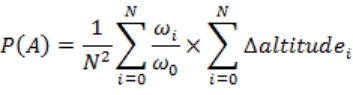
式 3-10 实际指出了,高山地形特征概率 P(A),正比于临近 N 个区块波动力度(wave)与本区块波动力度之比的平均值,也正比于本区块与临近区块平均海拔(altitude)之差的平均值。满足该地形特征的一个例子如,临近区块有很多都是海洋,平均海拔远低于该区块(altitude 之差很大),又或者大家都是陆地,但某区块相对周围的波动力度很小(周围区块 wave 可能仍然小于 1,但大于本区块,不会直接导致所在大陆平均海拔与波动力度相除后得到较低的海拔,所以都是陆地,但却会在与本区块的“争夺”中失势)。
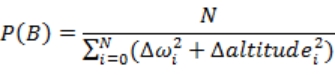
式 3-11 意味着,平原地形特征概率反比于区块与周边波动力度之差的平方的平均值、反比于区块与周边平均海拔之差方平均值。平方运算是用来取差的绝对值的,更直观的说明,就是与周边区块起伏不大的区块最有可能成是平原特征。
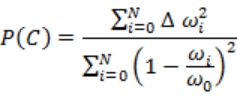
最后的式 3-12 则代表着,丘陵地形很大概率正比于周围区块的波动力度之差的平方和、反比于周围区块波动力度与本区块之商的标准差的平方和。举例来说,某区块临近的区块很可能波动很大,但它们呈现犬牙起伏形状,高低互相抵消,所以一方面,它们的波动力度标准差平方和并不大,另一方面,波动力度之差绝对值的累加却很大,那么这样的区块就很满足这个公式,其地形就很大概率是丘陵地形,起伏不平。
有了三种地形的特征公式,我们可以很轻易的判别某用户所在处的地形了,然而这还不够,我们还缺少了最关键的一项:目标地形的生成。我的计划是像 Minecraft 那样,通过噪声函数来生成地形,通过调节噪声的波长与频率等,来调节地势起伏与疏密。有两种备选算法,分别是 Perlin 噪声(ImprovedNoise)与 Simplex 噪声,顺便一提其实两种算法都是 Perlin 提出的。相对而言,Perlin 噪声提出的更早,应用更成熟更广泛,Simplex 噪声基于前者做了很多改进,优化了复杂度等。这里参照着 Perlin 噪声的 Java 示范代码,用 Go 语言实现了一套标准的 ImprovedNoise 算法(我选择 Go 主要是出于其对并发与跨平台等的考虑、以及在区块链等技术上的成熟应用,但在其他一些诸如计算机图形等基础算法上,Go 目前确实比较空白),如果后续有时间或许我也会尝试一下 SimplexNoise。有了 Go 语言版本的噪声生成函数,接下来就是根据之前的判别公式,调整波形,控制生成符合预期的地形了,这里更多的是体力活,不断调整系数与权重寻找比较合适的值就行了,需要注意的是如何优化客户端到服务器的地形生成与数据传输过程,可以选择全部放在服务器生成后传给客户端,也可以把必要参数传给客户端由其自行生产,其中涉及到诸如数据安全、传输效率、用户体验等诸多细节,但不是这里的重点,我就不再过多展开了。
最后顺便一提,以上生成地形的算法与过程只是个例子,并不是完整方案,我仍然可能继续调整与优化它,比如可以根据周围平均海拔都高于本区块,抽象出峡谷地貌,或者根据周围平均波动力度都小于本区块,抽象出盆地等等。
3.2 主观模块
3.2.1 区块链与共识
要在去中心的网络上保证整个系统的秩序与安全,区块链是个很好的解决方案,Everipedia 的案例就是个很好的例子,给了我很大的启发。Everipedia 建筑与 EOS 系统,它通过诸如抵押代币进行文章编辑提交、用户公共投票决定文章质量、建立基于共识治理机构实施修改方案等手段,来构建一个开放式、全透明、可信任的去中心化的公共百科。
虽然我也希望像 Everipedia 那样直接把软件项目建筑在 EOS 之上,但这有点困难,毕竟 EOS 是 EnterpriseOperationSystem,商用分布式区块链系统。我的打算是,针对本系统的需求,自己基于 Go 语言实现一套区块链,在区块链与分布式技术等方面,Go 语言有大量成熟的应用与案例给我借鉴,虽然不能保证做的多好,但完成起码的功能与机制应该是没问题的,在实现的过程中我也能更好的理解区块链底层原理,从而更好的调整系统的理论与设计。
首先,我需要设计区块链的基本单位,即每个“区块”(这里的区块不同于之前地形模型的区块,这里是 Block,之前是 Chunk)的具体结构体。对这个结构体,有一个基本要求就是,其必须是“完全可序列化”的,以便在后续进行区块签名时能方便的把完整区块的信息加入进去,也方便后续区块链在不同进程服务间进行数据同步。在 Golang 里,“完全可序列化”需要满足两个条件,一是所有字段必须是公开可访问的、二是结构体内字段不能有接口与指针(包括函数接口与指向结构体的指针等)。Block 的结构体声明如表 3-1 所示。
表 3-1Block 结构体
字段名 | 数据类型 | 注释说明 |
Index | int64(64 位长整数) | 区块号,自增 |
Time | int64 | Unix 时间戳 |
Data | Data(嵌套结构体) | 实际数据 |
Prev | []byte(字节组) | 区块前置哈希 |
Hash | []byte | 本区块的哈希 |
Nonce | int64 | 随机数字 |
其中 Time 字段为区块建立时的时间戳,Data 字段是嵌套结构体,目前只包含字符串 Server 与字节组 Pubkey 两个子字段,Nonce 字段是一个用于进行工作量证明(ProofofWork)的随机数字。下面重点分析 Hash 字段:Hash 字段是对当前结构体全部字段(包括 Data 与其嵌套内的 Server、Pubkey 在内)进行 sha256 数据摘要的签名,这个签名保证了区块内数据的有效性,即一旦 Block 内任何字段的值发生任何一点变动,都会导致最终 Hash 无法匹配。这个“任何字段”中又包含了 Prev 字段,也就是上一区块的 Hash,其保证上一区块内数据有效性,依次类推,我们就得到了一些列环环相扣不可篡改的区块。
介于之前所分析的,Block 结构体上不应有不可序列化的指针,所以 Block 之间虽然是链式关系,但并不能加入链接指针用链表表达,为此我们需要另一个数据结构 chain 来辅助维护 Block,即为“区块链”,其结构体不再具体展开。需要注意的时,在分布式系统上,链的增删改查是大量并发与异步的,传统的加锁并发复杂度太高不易维护,这时就是体现 Go 的优势的时候了,借助 Go 的 goroutine 与 channel 模型,通过建立一个轻量的 goroutine 作为 service,通过 channel 向 service 中添加事务,从而保证所有链操作同步有序执行,避免并发冲突,实现无锁并发。
有一种观点认为,共识机制才是区块链的灵魂,确实,共识机制保证了区块链的秩序与运转。目前区块链共识机制有很多,常见的如 POW、POS、DPos 以及 POI、POP 等等,各有优缺,具体如何选择是个难题,要考虑包括但不限于实现复//去中心化程度、交易证明效率、对坏节点的处理能力等诸多方面。以后有时间与精力是我肯定会尝试更多更优方案,但现在就先实现一个基于 POW 的共识机制吧。
回顾我们的 Block 结构体,其包含 Hash 字段,它是对完整结构体数据的签名,数据的任何改变都会导致 Hash 的变化。另外结构体里还有 Nonce 字段,这是一个随机数,这个数字变化当然也会影响 Hash。接下来要进行的工作量证明(ProofofWork)主要就是基于 Hash 与 Nonce 完成。简单来说,其基本原理是基于这样一个事实:Hash 可以被计算,但很难被定向的计算,这意味着我们可以对任意数据做签名,却很难针对特定签名来构造数据,一般只能通过暴力搜索来寻找。所以如果我们对 Hash 加以一些限制,这些限制越严格,满足条件的特点 Hash 越少,搜索难度也就越高。基于此,我设计了一个 miningTarget 结构体,结构体内容如表 3-2 所示。
表 3-2MiningTarget 结构体
字段名 | 数据类型 | 注释说明 |
difficulty | int(整数) | 困难度 |
Int | *big.Int(大整数指针) | 目标特征 |
其中,difficulty 字段是可配置的,在系统初始化时由配置系统传入,它代表了搜索目标 Hash(也就是 mining,挖矿)的难度指标。Int 字段则是一个指向无上限的非常大的整数的指针,其在 Go 语言的底层表示为[]Word,即 Word 结构体切片(可变长数组),任何[]byte(字节组)数据都可以被写入一个 big.Int,并与其它 big.Int 数据进行比较,所以 big.Int 即可以作为搜索(挖矿)的目标哈希的特征指标,当目标 Hash“小于”这个指标时视为挖矿成功。Int 字段(目标特征)是由 difficulty 字段计算得到的,它们间的关系如式 3-13 所示。
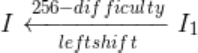
式 3-13 中,leftshift 值二进制向左移位操作,I1 为值为 1 的 big.Int。经过移位,我们实际得到的目标特征指标形如表 3-3 所示的 bytes。
表 3-3 目标特征指标的内存结构
bit: | 000…000 | 1 | 0000…0000 |
length: | Difficulty | (I1) | 255-difficulty |
也就是说,difficulty 指标越小,那么目标特征指标越大,搜索到小于目标特征指标的 Hash 的概率越大,难度越低。反之,当 difficulty 指标很大,比如极端到 255 时,目标特征值就是 1,而比 1 小的值只有 0 这一种可能了,搜索这个唯一 Hash 将十分困难。理解了这个原理,接下来要做的就是,对于给定的数据 Data,为其添加 Index、Time、Prev 等字段,构造出 Block,然后不断改变 Block 的 Nonce 字段,并重新计算 Hash,直到找到满足目标特征的 Hash,视为挖矿成功,之后可以就将这个 Block 通过 P2P 网络广播到所有节点上去进行区块插入操作。收到新区块的节点只需要依次验证区块索引号(Index)、区块前置哈希(Prev),并对区块重新签名,将得到的结果与原 Hash、目标特征做匹对,就能确定新区块是否是当前链上有效的后续区块,这样一个加入了“灵魂”(共识机制)的区块链才算是真正打造成型。
3.2.2 数据缓存与交换
前文分析曾提到,用户数据一般情况下是由各自设备独立、分布式的维护的,而不是集中的由某一中央服务来维护。当用户需要交换数据,比如两个用户“靠近”后,设备之间的数据彼此独立的数据才会进行共享与交换。基于这些,我对本系统的数据层提出了两点要求:第一,需要能做到按坐标快速索引,以便查找某坐标及附近的数据。第二,需要能按时间排序,且自动释放较长时间不用的旧数据,以便把单机设备数据量控制在一定范围内。另外,这个数据层必须是基于内存的、能高效访问与操作的、对并发与分布式友好的。幸运的是,基于 Golang 的特性,构建一个这样的数据层很容易,我参考 Memcached 与 Redis 等缓存数据库,简单实现了一个具有之前说的两点特性的缓存数据层。其以“瓦片数据”TileData 结构体为基本单位,TileData 结构体如表 3-4 所示。
表 3-4TileData 结构体
字段名 | 数据类型 | 注释说明 |
Nano | int64(64 位长整数) | Unix 时间戳,纳秒级 |
Coord | [3]float64(三维浮点数组) | 三维坐标 |
Data | []byte(bytes 字节组) | 序列化后的数据 |
其中,Nano 字段用于按时间戳对数据进行排序,当一个 TileData 被访问或更新时将同时刷新 Nano 时间戳,并重新排列其在 cache 里的位置,当 cache 队列达到单机设备限制的阈值时将进行缓存的清理,回收陈旧数据,释放内存,这时就会选择 Nano 最小(意味着数据陈旧)的 TileData,将其从缓存队列中移除。
TileData 是缓存数据层的基本单位,缓存数据层身又维护着两个数据结构,一个是以 Coord(三维坐标)为 Key、TileData 的指针为 Value 的哈希表 cache,一个是以 TileData 的指针为基础单位、以 TileData 的 Nano 字段为索引 Key 的红黑树 retrieve。前者(cache 结构)用于进行快速的低时间复杂度的按坐标查找瓦片的任务,后者(retrieve)为所有瓦片建立按时间自排序、自平衡的索引,用于方便进行内存的回收与释放工作。
单机设备的缓存阈值(cachethres)是可分别配置的,各个节点可以视各自硬件能力等情况自行调整。cachethres 结构包含两个字段,hold 与 max,一般来说只需设定 threshold 即可,max 将自动调整为 hold 的二分之三并取整。比如我们设定系统的缓存阈值为 1024(阈值最好设定为 2 的倍数,以便二分之三取整运算),这意味着缓存容量将被控制在 1024 到 1536 间,假设平均一个瓦片的 Data 字段存有 1k 数据,那么可以预期系统缓存层占单机设备内存量将被控制在 1M 到 1.5M 之间。当新数据不断产生超过这个阈值,即 cache 的 size 达到 1536 时,系统将根据 retrieve 索引表来查找所有 Nano 字段最早的瓦片数据(TileData)并释放掉。
有了上述具有按坐标快速索引、按时间自动释放的数据缓存层,单机设备的数据问题以及解决了,并且也为设备节点间查询“距离自己最近的数据”打好了基础,当然,考虑到分布式与并发问题,还要借助 Go 的 goroutine 与 channel 机制加以一些改造。
接下来我们需要考虑数据交换时的具体问题,特别的安全问题,即如何认证某个设备提供的数据的有效性。参考 SSH 协议,我采用 ssh-rsa 非对称加密算法来进行数据的加解密。具体来说,对于每个单机设备,我用 RSA 算法为其生成一个 RSA 密钥(rsa.PivateKey),分别生成其 x509 证书的密钥(PrivateKey,注意已经不是之前那个 RSA 密钥了)与公钥(PublicKey)的 pemdata,为了防止后文混淆,后文我将分别用 RSA 密钥、x509 公钥(的 pemdata)、x509 密钥来称呼。x509 密钥将被写入本地 id_rsa 文件以持久化,并将在以后系统重新启动等时候再次载入并从中拿到 RSA 密钥,它将被用来解密以后经过 x509 公钥加密的密文数据。但 x509 公钥并不会被持久化,我们再次利用之前的 RSA 密钥,按照 SSH 协议生成一个 PublicKey,后文称作 SSH 公钥,然后将其序列化为 AuthorizedKey 并写入 id_rsa.pub 文件以持久化。同时,这个 SSH 公钥也将被写入到之前构建的区块链上去,面向全节点公开。
这里的加解密机制比较错综复杂,现在整理一下,我们主要有四个常用的 Key,它们分别是:RSA 密钥(rsa.PrivateKey)、x509 公钥或其 pem(x509.PublicKey)、x509 密钥或其 pem(x509.PrivateKey)、SSH 公钥或其许可证(ssh.AuthorizedKey)。其中,RSA 密钥与 x509 密钥皆为节点私有,绝不泄露给他人,SSH 公钥则放在区块链里,链式节点都可以查询,用于进行节点间身份校验。校验时,某节点 X 将向要身份不明的来源节点索要 SSH 公钥,而后用自己私有的 RSA 密钥(或从私有 x509 密钥中读出自己的 RSA 密钥),生成一份 SSH 公钥,并与对方持有的 SSH 公钥进行比对,确定对方可信任,即 SSH 公钥校验通过后,才可以与对方交换 x509 公钥。然后,对方节点可以用其通过校验获取到的某节点 X 的 x509 公钥,对某段信息进行加密,并将其在集群中传播,而只有持有 x509 密钥的节点 X 能解读这段密文的内容。具体关系用图解表示如图 3-2 所示。
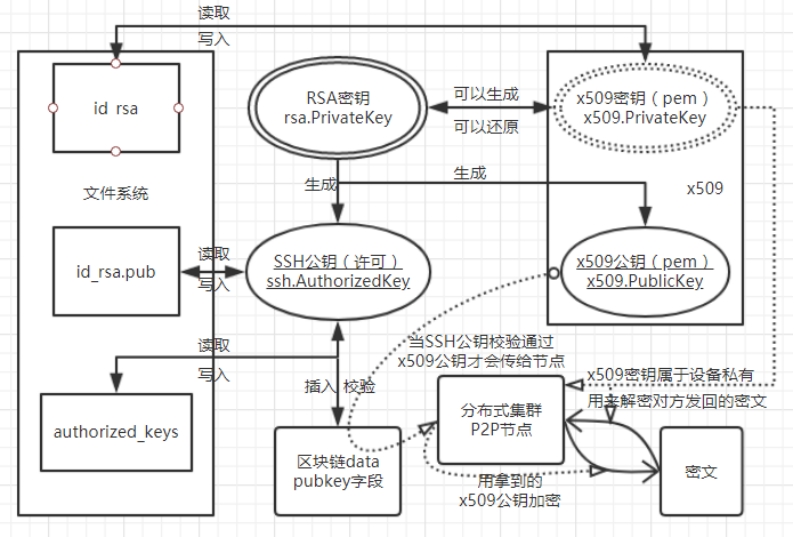
图 3-2 公钥密钥关系及加解密认证原理
3.3 辅助模块
3.3.1 服务端
前文里,我们构建了区块链、共识机制、数据缓存、安全认证等诸多模块,但却唯独漏了一个最基础的设施:P2P 的去中心化与分布式网络。这是有原因的,P2P 网络具体怎么搭建,方案非常多,视具体业务场景不同有许多可能的方法。本次我要搭建的 P2P 网络,是面向这个类似 Minecraft 的 Demo 而设计的,其客户端是采用 three.js 引擎、基于 WebGL 技术、跑在类浏览器环境(但我会借助 Node 与 Electron 等技术使其能脱离传统浏览器运行),因此本 Demo 的 P2P 网络将主要基于 WebSocket 协议来实现。或许有时间的话我还会尝试实现一套基于其它本地引擎的客户端,不过后端的原理是相近的,把基于 WebSocket 的架构迁移到基于其它双工长连接协议的架构上不难。
首先,我们还需要搭建一个简单的 HTTP 服务,虽然我们的 P2P 网络建设与 WebSocket 之上,但在一些不需要双向通讯、长连接保持的地方,比如 HTML 页面与静态资源等的伺服方面,HTTP 无疑是更好的选择。我使用 gin-gonic/gin 框架来搭建 HTTP 服务,除了提供前面所说的页面与资源外,还同时负责一些 API 接口的私服,以及响应模板、JSON 等的渲染。搭建细节不是重点,接下来,我选择使用 gorilla/websocket 库做底层来搭建 P2P 网络,我用它来接管 Gin 监听的所有“/ws”路径上的连接与请求,将其 Upgrade 成为 WebSocket 连接,与其它 HTTP 服务分离开来。
当系统每收到一个 WebSocket 连接,我就会将其放入一个哈希表进行维护,并开启两个 goroutine 分别负责监听这个链接上的读(接收消息)与写(发送消息)操作,参考官方指南,将其分别命名为 readPump 与 writePump,后文称作读泵与写泵(还是挺形象的),当系统收到新消息时,由读泵将其内容解析为 JSON,并根据 JSON 中的 action 字段,将其派发给事先注册好的不同消息处理器中进行处理。写泵是用来向外界发送消息的(包括收到的消息处理完毕后向来源发送响应),我分配一个名为 send、允许通过任意接口的 channel 来作为写泵的入口,当系统中实际需要向外发送信息时,直接将消息放进 send 管道里,而后写泵将从中把消息取出并实际写入到 WebSocket 连接内,发送给目标端。这种读写泵的机制本质是基于 goroutine 与 channel 实现的一种轻量级消息队列,对系统压力很小,可以同时开启大量的实例,而不用费心设计并发锁、维护线程池,非常适用于这种 P2P 的、微服务的场景。
另外,服务端不止需要架设与客户端、其它服务端之间的连接,还需要架设好本地以及远程控制台管理服务,以及常驻系统后台的守护进程。我基于 TCP 协议实现了一个小型的带有权限管理的控制模块,一部分部署在服务端,另一部分作为独立的控制台应用运行。因此,本系统 Demo 启动时实际需要制定两个服务地址(或端口),一个用来架设 HTTP 与 WebSocket 服务(它们共用一个地址与端口),另一个用来架设基于 TCP 的远程控制模块。后者,即 TCP 服务部分虽然是远程,但应该地址应该是非公开网段的,仅内网集群可访问的,它具有最高的后台管理员权限,需要最高安全与封闭性,而一般用户的管理操作等则是通过 Web 管理员页面,走 HTTP 部分完成的。然后,我基于 kardianos/service 框架实现了跨平台兼容的系统(这里指操作系统)守护进程的注册,使得本系统可以在后台以静默方式运作并正常提供服务。
3.3.2 客户端
前文里,我们曾完成了球面建模、区块划分、地形生成等部分,但它们都只停留在一堆抽象的后端控制台参数阶段。我们需要搭建一个漂亮的用户界面来方便用户交互,还需要构建一些管理员页面(不是后端 TCP 管理,而是提供给非后端维护人员的、用于管理系统内应用层的),以及一些监控与报表模块。
后台管理与监控报表等页面,我们将通通使用 Web 技术完成。但由于客户端最终目标环境并不是传统浏览器,所以我们可以直接运用一些激进的特性与方法来提高生产效率。比如,我们直接引入了 ES6 的包括 ArrowFunction、Destructuring、ESModule 等很多新语法,直接使用尚未得到浏览器广泛支持的 SynamicImport、Promise、PointerLock 等特性,为了快速的构建健壮可维护的项目,这些特性是我们必须的。另外,我将尽量避免使用模板语法与后端模板渲染,因为页面最终被打包到本地客户端环境里去,与传统的 Browser-Server 的工作机制会有一些差别。页面上的动态数据等都是通过 AJAX 方式,准确的说是 WebSocket 或 fetchapi 来主动获取的,由前端负责渲染到视图上。
真正重要的是主界面的开发。我选用了 three.js 引擎,或者也可以算作框架,来开发 3D 化图形页面与交互场景。three.js 是一款十分优秀的、运用广泛的 3D 框架,它基于现代浏览器的 WebGL 技术,来实现在浏览器及类似环境里的高效 3D 渲染。WebGL 是 OpenGL 在浏览器环境的替代品,它利用底层的图形硬件加速进行的图形渲染,大大提高了浏览器 3D 图形能力,使得基于浏览器的应用也终于能像本地应用开发高效的 3D 游戏。
three.js 其核心概念与 API 等于传统 3D 引擎差别不大,可以很容易的上手。我们需要设置相机、设置光照、设置场景,然后稍有不同的是,常见引擎里我们可能会需要“画布”来进行实体的渲染与,在“窗口”里进行绘制,而在浏览器环境里里,我们需要一个容器,它一般是一个 DOM 元素,来代替窗口作为绘制目标,而后选择合适的渲染器(renderer),一般可以选择 Canvas 或 WebGL 两种实现,3D 渲染一般用后者,来代替画布。renderer 持有一个 domElement 对象,它是一个浏览器 canvas 元素,但我们并不需要在这个“画布”上“作画”(虽然也可以这么做,一些简单的 2D 图形绘制没必要引入庞大的引擎是,这是一个原始但方便的选择)。另外,three.js 没有提供一个全局的主循环(MainLoop),需要我们自己建设一个并维护它,在浏览器里这很容易做到,唯一的问题是后面诸如游戏舞台切换、生命周期管理的问题需要自己设计与实现。
浏览器安全策略是个问题,相比于传统的本地桌面 App 环境,浏览器对用户与开发者做出了非常多的限制。好在之前说过,我们的最终目标环境不是传统浏览器,因此我们可以选择使用一些尚处于实验阶段的特性。比如现在,我们需要能通过鼠标完成对相机视角的控制,这在传统浏览器环境是不可想象的,因为浏览器大多不允许开发者将用户鼠标限制在一个窗口中(这是可以理解的,试想以前那些弹出的讨厌广告,如果它们能捕获用户鼠标,将产生非常不好的隐患)。但有一个出于实验阶段的浏览器 API 能解决这个问题,就是前文提到过的 PointerLock,有了它我们才有可能让用户能通过鼠标顺利的控制与交互。所以说,这些新特性、新语法是想要用浏览器实现这个 3D 沙盒 Demo 所必须的,这也是为什么我计划用 Electron 之类工具将最终生产环境打包成桌面 App 的原因。但另一方面,浏览器与 Web 技术又在诸如页面 UI 动画效果等方面给了我们成熟易用且强大的自由空间,这是本地 App 所不能比的,或者说同样的实现,本地 App 一般要麻烦许多,这也是我为什么仍然选择先基于浏览器开发,而后打包到本地的原因。
3.3.3 公共类库
最后,公共类库主要是一些基础设施或者比较通用的、以后很可能被拿去用到其它项目里的工具与库。它们中有一些甚至并不是本次才开始做的,而是我很早就开发并用于其它项目、或者从以前开发的项目里提取出来的公共部分。下面我选几个比较有代表性的来谈谈。
首先是配置模块。这个配置模块并不是传统意义上的文件配置,而是综合了控制台启动参数解析、文件配置解析、环境变量解析等多种手段,并将其整合后提供统一接口,实际项目启动时,对于重复的配置条目,以命令行参数、配置文件、环境变量的顺序,优先级递减。本系统自身就能独立运行与部署,无需类似 Tomcat 或 ApacheHttpd 之类容器服务,且前面提到过本系统自带注册系统服务、静默运行守护进程的能力,为了保证启动进程被后台进程接管等情况下系统内参数配置的一致性,配置模块就更为重要了。
然后比如事件系统,在 Golang 社区与习惯里,诸如依赖注入之类的设计并不常见,说实话实现起来也不太优雅。为此,我自己设计了一套事件系统,用于准确的调度各个模块启动与初始化时机,并支持在事件推送时附带各种参数,从而一定程度也解决了一些单例组件的传递与获取问题。稍稍有一点遗憾的是,事件系统完成的比较早,其中一些地方的设计残留了很多我以前做 Java 开发的影子,对并发考虑不够到位,所以其中一些地方加了一些全局锁、乐观锁等,稍稍有点难维护。
其它还有诸如 JSON 封装、HTTP 请求封装等工具性质的类库,虽然 Go 本身的 JSON 与 HTTP 支持都比较完善了,但大多是针对一般性的通用的场景设计的,实际项目使用中有些不便。比如说 JSON,对于接口传入的 JSON 数据,我希望控制器能将其默认视为合法的结构来进行处理,实际遇到 JSON 结构不合法,比如控制器内实际从 JSON 上取某个字段,发现这个字段不存在时,能直接记录出错的 JSON 并抛出,然后在响应给用户前被拦截,并自动生成一些可读的错误信息。内置的 JSON 支持并不能很好的解决这种需求,如果不自己封装一层的话,我就不得不在每个可能出错的 JSON 处手动校验 JSON 合法性,手动完成错误捕获与处理。
4 成果与分析
4.1 成果验证
完成后的 Demo 主要由 3 部分组成,分别是:服务器、Web 页面、桌面 App,下面我将依次展示。
4.1.1 服务器
由于 Go 语言成品直接编译成二进制的特性,服务端部署十分简单。本 Demo 自带后台守护进程、TCP 与 HTTP 监听等模块,无需 Tomcat、Apachehttpd 等容器。不过我仍然加了一层 Nginx,用于按照 Host 转发到本地 port,以避免直接暴露服务器端口或完全占用 80、443 等重要端口。这里唯一需要注意的时,proxy_pass 时需要带上原请求头,且 Update 到 1.1,以支持 WebSocket 协议与避免跨域问题等。
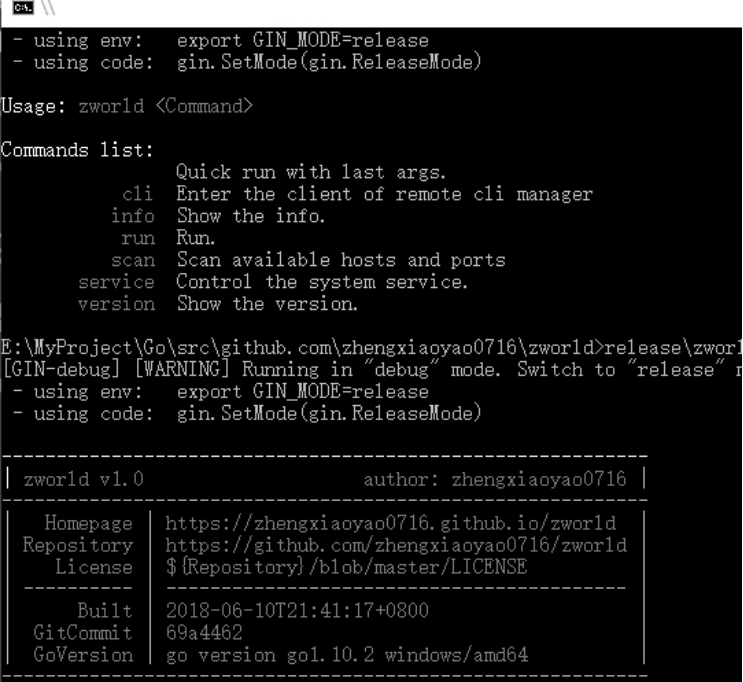
图 4-1Windowsx64 控制台
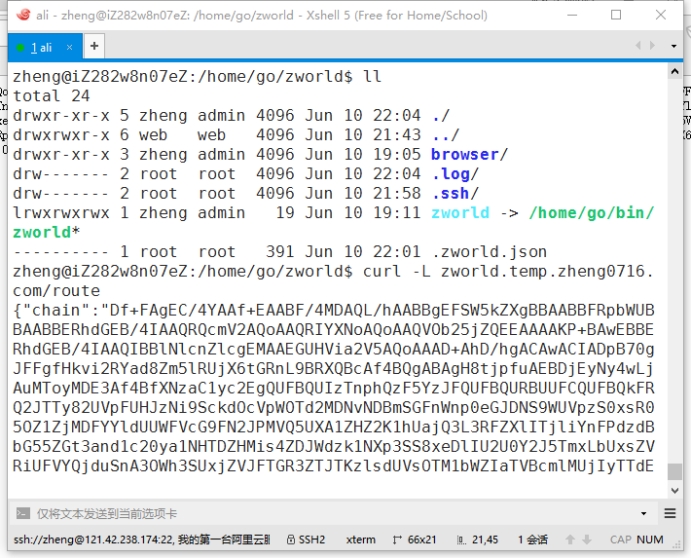
图 4-2Ubuntu14.04 终端(XShell)
图 4-1 与图 4-2 分别展示了服务端 windowsx64 版本(zworld.exe)与 linuxamd64 版本在相应平台上的部署与运行。其它平台没有实际测试,目前只测试了这两个平台,均按照期望正常运行。后面那张截图里可以看到“/route”的 curl 结果,chain 字段的值区块链的 Dump 数据,可以看到服务以及成功在后台启动,区块链已经建立。
4.1.2Web 页面
打开浏览器登入服务的仪表盘页面,可以看到当前服务器一些启动参数、内部状态,如图 4-3。
图 4-3 仪表盘部分截图
从图 4-3 所示的仪表盘上,我们能监控后台服务的一些关键参数与配置,以及一些当前服务内部状态的签名。比如上图中“chainsign”为当前区块链数据的短签名,用来直观的比较两个服务是否一致,“SSHKey”是当前后台服务的公钥,可以供其他服务用来与本服务握手验证或授权等。
4.1.3 桌面 App
桌面 App 主要通过 Electron 来进行打包构建,并在多种平台上发布。桌面 App 主要有三个窗口,分别是登入、主窗口、地图。
图 4-4 登入浮窗
图 4-4 所示为启动器登入浮动窗口,中间输入框里键入服务地址,下面选项卡上可以选择是否全屏启动、是否以开发者模式启动等。当登入成功时该启动器将会自行关闭,并将主窗口打开。
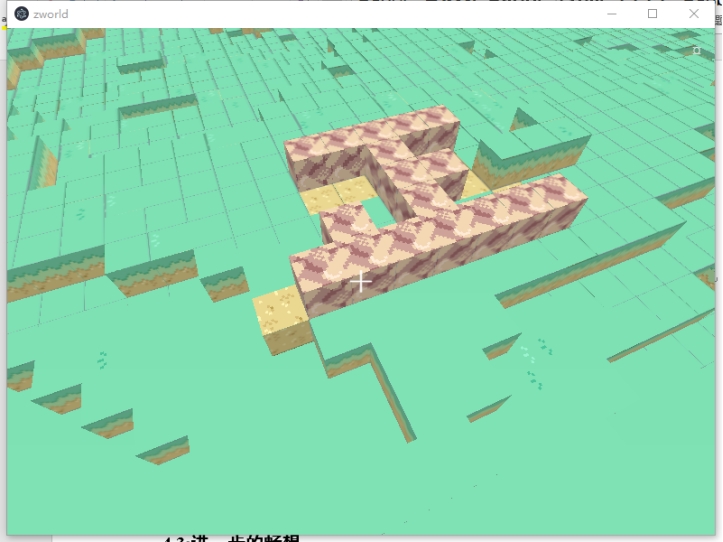
图 4-5 主窗口
图 4-5 展示了本 Demo 的主窗口,一个类似 Minecraft 的游戏。实际测试时,除了在加载地图区块时略微卡顿外,整体还算流畅,能正常进行交互与操作。
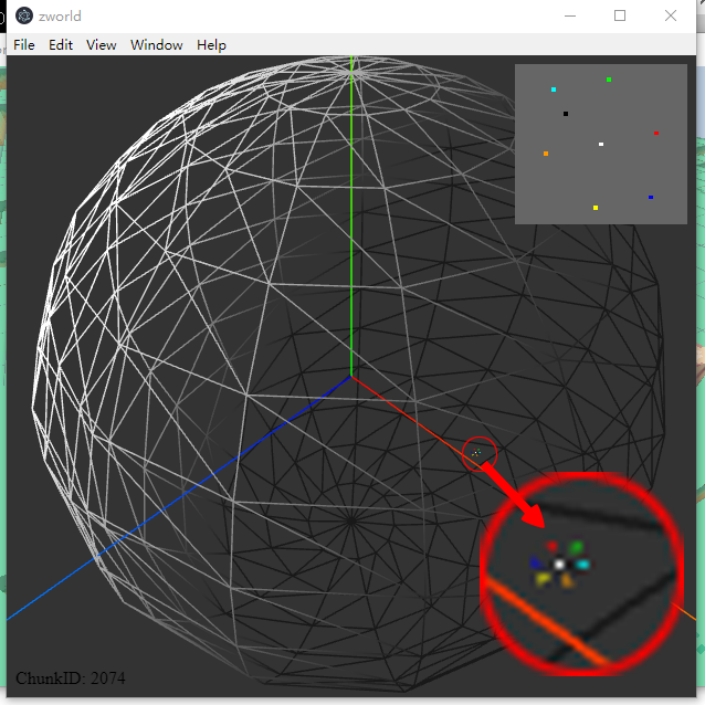
图 4-6 主窗口
图 4-6 展示了用户当前所在区块的球面与平面投影(右上角)的坐标,白色为区块中心,黑色为用户在区块中的位置,周围彩色的点为区块边界的顶点,图中左下角 ChunkID 为区块号。由于球面被划分成非常多个区块(这里测试时划分了 10×1024 个区块),单个区块在球体上看起来非常小。
4.2 分析改进
首先我们假设以下情景,用来验证该系统是否达到预期设计的目标:两名用户,分别独立地部署系统的两份拷贝(后直接称“系统”)。系统 A 与系统 B 应当各自独立,拥有不同的公钥密钥,各自在区块链上有一份“货币”用来证明自己。用户 A 与用户 B 一开始位于“类地球”模型上的两个相距很远的不同坐标,因为地形模型是随机的,他们分别看到的应该是不同的地形。然后,我们需要让用户 A 与用户 B“靠近”,即让用户 A 来到用户 B 的坐标附近,因为系统的模型针对同一地点,无论谁、无论何时观测都是一致,所以用户 A 会看到和用户 B 一样的地形。另外,此时系统 A 与系统 B“距离较近”,我们期望它们之间应该能交换数据,从而让用户 A 看到用户 B 对模型的改动,比如用户 B 在地上写的字之类的。
下面针对以上假设情景,我们开始验证:

图 4-7 系统 A 的用户视角,区块 2074
图 4-7 为系统 A 的用户视角的截图。可以看到,用户 A 位于 ChunkID=2074 的区块里,在球体模型上位于红色坐标轴附近,单个区块在地图上看起来很小,截图上可能看不清。
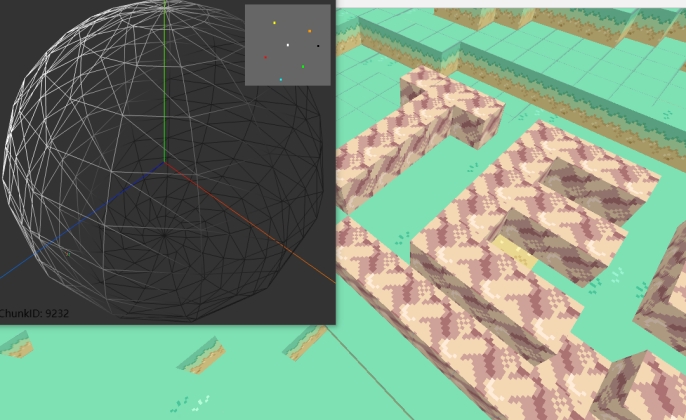
图 4-8 系统 B 用户的视角,区块 9232
图 4-8 为系统 B 用户视角的截图,他位于 ChunkID=9232 的区块里,与用户 A 相距可谓非常远。用户 B 在当前位置附近用石头摆出了“TEST”字样,当然现在仅他自己看的到,用户 A 是看不到的,因为用户 A 离他太远,系统 A 并没有共享系统 B 的数据。
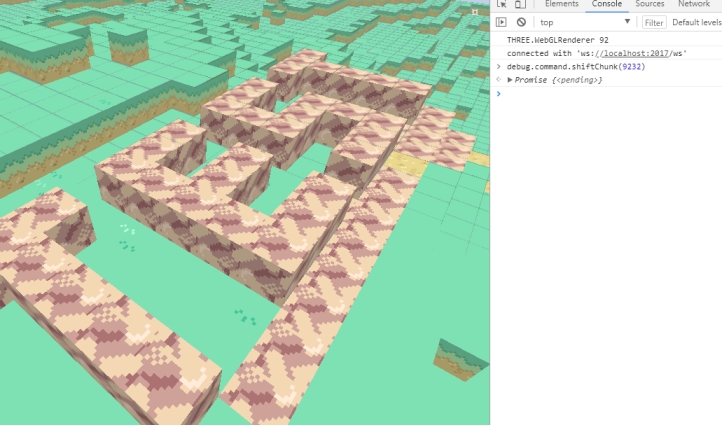
图 4-9 系统 A 用户来到 B 附近
如图 4-9 所示,真的从地图上跑的话距离实在太远了不现实,作为替代,我留下了一个控制台调试命令,用来进行区块移动。系统 A 通过 Shift 命令,移行到了系统 B 所在区块(ChunkID=9232)附近,我们看到了用户 B 摆下的字母。
经过以上步骤的验证,预期目的基本完成。这个 Demo 可以做到分布式的部署无数份,它们可以建立起一个去中心化的网络,并创建一个区块链。平时系统间(指运行中的该 Demo 的拷贝)各自相距(指其在模型上的位置)较远时,系统以很低的数据量近似单机的运行。当两个系统(上面验证中的 A 与 B)靠近时,它们间会交换用户数据,从而使得用户观测到其它用户在系统中做出的改动(A 看到了 B 摆出的字母)。而对于诸如地形地貌等“客观”的数据,则由各系统独立根据模型推演出来,无需经过数据交换。
经过测试,我也发现了不少本 Demo 的缺陷与问题。首先,客户端方面,3D 图形渲染算法有点问题,当地形不够“连续”时(比如地形突然升高或降低),会出现漏掉的透明方块,区块(这里的区块是指客户端加载地图的小分块)加载策略也需要调整,当前在区块间移动时还是有点卡顿。服务端方面也有点问题,通过配置与环境变量传入的参数无法在仪表盘显示,当直接通过“service”命令将本系统作为后台守护进程启动时,仪表盘等管理模块也可能会丢失启动参数信息,甚至会报错导致页面加载失败。
另外在测试中,我还发现了一些本系统可以改进的地方,比如当客户端与服务端在同一主机上运行时,完全没必要经过 HTTP 与 WebSocket 之类的服务进行通讯,可以直接通过 IPC 之类的机制交换数据,提高系统响应速度。再比如,系统内没有直接的 HTTPS 与 WSS 支持,而经过 Nginx 之类的转发又会造成系统内一些依赖于 HTTP 协议的模块失效,需要想办法改进。
4.3 下一步的畅想
本次这个 Demo 验证与实现了一些我的“类地球分布式模拟系统”的设计与猜想,获得了一些不错的特性。而针对前文提到的“祖先模拟”与“模拟现实”等问题,我还有一些进一步的设想等待完善与验证。下面是其中一些比较有意思的:
(1)上帝的视角?
在电影、游戏、小说等作品里,我们经常用“上帝视角”来指观众、玩家、读者等能脱离特定主角的视点,看到故事中人物看不到的事物,知道故事中主角不知道的东西。
这里我借这个概念思考这么一个问题:如果我们真的模拟出了一个世界,但却不以第一人称代入,那么就可以打破一些这个模拟世界的约束与法则。比如,模拟世界的一端有信息想要传递给另一端,如果用系统内的事物做载体,这个传递速度绝对不可能超过载体的速度,但如果从系统外加以干涉,那么只需要把消息上传给服务,再下传给另一端的用户就可以了。
(2)遗忘式记忆?
这或许算是一个意外发现,当我打算想办法持久化系统中某节点设备的数据时,我发现其实没这个必要。一般而言,为了在系统重启之类的时候接续之前的数据,我们需要通过数据库或文件系统等将重要数据持久化,但对于本系统或许没这个必要。
假设某用户要下线(停止其设备上运行着的系统),大部分用户数据都可以直接销毁,因为他“附近”(模型上距离)的设备帮他“记住”了他的数据,当他再次上线时直接从“附近”的设备同步回来就好了。当系统中设备非常多,且彼此是独立的、去中心化的时候,任何一台设备都可以视为周围设备的容灾备份。而如果某个设备真的特别“独立”,周围没有其它设备,那么当它下线时,它将确实的“遗忘”掉自己之前的数据。换而言之,“众人”的共同观测与认知保证了“记忆”的可靠,“集体”相互容灾保证了系统不会“归零”,没有“众人”与“集体”,就没有“文明”与“社会”,这就是我对“遗忘式记忆”的设想,某种程度上来说这或许挺真实可行的。
(3)模拟与可控?
基于分布式与去中心化技术分摊用户数据与计算,基于特殊的随机生成算法避免过大的模型数据量,构建一个“类地球”的模拟系统应该是可行的。
但有个问题是,我似乎只能“模拟世界”,而不能对控制这个模拟系统。当系统去中心化时,它就已经“失控”了,我无法从某个中央节点对所有节点发出必须遵守的命令。另一方面,特殊的随机生成算法虽然从局部来看可预测,但整体一定是未知的,具体来说,我可以随时演算出某个坐标的地形,就算地形随时间而演化,只要随机种子取自前文说的“可预知”参数,我也能演算出任意时刻该地形会演化成什么样。但这是局部,我却绝对无法预测整个模型的地形变化,因为那需要对近乎无限的所有坐标进行预测,需要非常庞大的数据量。
总而言之,虽然建立一个模拟系统是可行的,但要建立一个完全可控的系统看起来似乎还是很难办。这可能意味着,就算模拟论正确,但我们仍然是自由独立的。
5 结论
就结果而言,我对“分布式类地球模拟系统”的大部分设想都进行了验证与实现。经过验证,这个设想在现阶段技术与硬件条件下应该是完全可行的,虽然对于我个人而言可能稍微有点不切实际,因为工作量太大。在诸如区块链工作证明、数据交换与安全机制、去中心化分布式网络建设与维护等诸多方面,本次我完成的 Demo 虽然基本给出了可用实现,但距离真正生产环境下的部署与实施尚有不少距离。
我认为“分布式类地球模拟系统”的意义更多在于,将分布式技术引入了传统的地球模拟场景中,对于以后的依赖于地形生成、沙盒模拟的一些游戏、3D 仿真、虚拟现实,特别是涉及大量用户同时参与在线的项目与产品,可能比较有启发与参考意义。如果有机会的话,我希望能将本系统接入到更成熟的企业级分布式系统中,比如 EOS 平台上,这样应该会比我自己实现的区块链与分布系统的效果好很多。
另外,本次基于这个模拟系统设想而实现的这个 Demo,完成度还不错,我会继续维护与完善它。且基于“分布式类地球模拟系统”的理论与设计,这个 Demo 确实获得了一些颇具特色的不错特性,具有一定价值,今后有更多时间与精力时,我可能会考虑将其真正实用化、商业化,使其作为一款成熟的作品推出。
最后,我将这次研究的所有细节与内容公开,并将 Demo 的代码开源在了 GitHub 上,我个人的能力尚不足以完成一个生产环境可用的完整系统,希望能获得开源社区上的关注与支持,对我个人力所不及之处进行改进。
参考文献
[1]BostromN.AreWeLivinginaComputerSimulation?[J].PhilosophicalQuarterly,2003,53(211):243-255.
[2]RheaS,GeelsD,RoscoeT,etal.HandlingchurninaDHT[J].Proc.usenixAnnualTech.conf,2004.
[3]杨峰,李凤霞,余宏亮,等.一种基于分布式哈希表的混合对等发现算法[J].软件学报,2007,18(3):714-721.
[4]侯整风,赵香,杨曦.抗合谋攻击的门限签名方案[J].计算机工程,2008,34(17):147-148.
[5]LindellY.ParallelCoin-TossingandConstant-RoundSecureTwo-PartyComputation[J].JournalofCryptology,2003,16(3):143-184.
[6]PedersenTP.Non-InteractiveandInformation-TheoreticSecureVerifiableSecretSharing[C]//InternationalCryptologyConferenceonAdvancesinCryptology.Springer-Verlag,1991:129-140.
[7]GilbertS,LynchN.Brewer'sconjectureandthefeasibilityofconsistent,available,partition-tolerantwebservices[J].AcmSigactNews,2002,33(2):51-59.
[8]MattheusDT,House,Rogue,etal.Rogue-VideoGame[J].Vent,2012.
[9]FordyceR.DwarfFortress:LaboratoryandHomestead[J].Games&Culture,2015,13(1).
[10]芮小平,张彦敏,杨崇俊.基于 Perlin 噪声函数的 3 维地形可视化研究[J].测绘通报,2003(7):16-18.
[11]梁俊,王琪,刘坤良,等.基于随机中点位移法的三维地形模拟[J].计算机仿真,2005,22(1):213-215.
[12]周丽琨,刘金鹏,陈定方.随机分形地形生成及其浏览[J].武汉理工大学学报(交通科学与工程版),2001,25(4):390-392.
[13]SahashiK.NumericalExperimentofLandandSeaBreezeCirculationwithUndulatingOrography:PartIModel[J].JournaloftheMeteorologicalSocietyofJapan,2007,59(3):361-372
[14]邵兴,梁醒培.球面网壳非规则网格划分方法研究[J].空间结构,2012,18(4):35-38.
[15]MichalakesJG,PurserRJ,SwinbankR.DataStructuresandParallelDecompositionConsiderationsonaFibonacciGrid[C]//AMS,ConferenceonNumericalWeatherPrediction.1999.
[16]ChewLP.ConstrainedDelaunaytriangulations[C]//SymposiumonComputationalGeometry.ACM,1987:215-222.
[17]肖思煜,葛爱军,马传贵.去中心化且固定密文长度的基于属性加密方案[J].计算机研究与发展,2016,53(10):2207-2215.
[18]吴建军,王征.基于总线网络的分布式一致性算法[J].计算机工程与设计,2008,29(23):5993-5995.
[19]KingS,NadalS.PPCoin:Peer-to-PeerCrypto-CurrencywithProof-of-Stake[J].2012.
[20]KiayiasA,RussellA,DavidB,etal.Ouroboros:AProvablySecureProof-of-StakeBlockchainProtocol[C]//InternationalCryptologyConference.Springer,Cham,2017:357-388.
致谢
从三月初到现在两个多月时间,我暂时辞去实习专心投入这篇论文的撰写以及文中提到的系统的设计与开发,在这段时间乃至整个大学四年里,很多人给我提供了支持与帮助。
首先我要感谢我的导师。她在选题、任务计划、论文撰写等诸多方面给了我很多指导与建议,帮我纠正了很多疏忽与不成熟之处,使得我能够顺利的按照规范完成这篇论文。此外,大学期间,她也多次担任我的认识实习、分散实习等的指导教师,给了我很多的启发与教诲,让我获益良多。
另外要感谢教授,虽然没有直接提给我指导与帮助,但他是我名副其实的大学引路人。在大一期间的计算机前沿科技选讲上,他以渊博的知识、卓识的见解,带我了解了分布式、区块链、虚拟现实等前沿领域,坚定了我对计算机的信心以及对虚拟世界的执着,一定程度上直接启发了本次论文的系统设想。
此外,感谢曾与我一同创业奋斗的学长与学姐以朋友与同学,大学期间我的成长与进步离不开他们的帮助与共勉。也感谢其他良师益友,没有大家就没有我完整的大学四年生活与经历。
最后,感谢父母与家人对我的支持,使得我可以顺利完成大学四年的学业,找到自己想要的工作,步入自己心仪的行业。