心理咨询 网站模版嘉兴网站建设技术开发
一.将字符串不同类型拆分
import redef split_string(s):# 去除多余空格s = re.sub(r'\s+', ' ', s).strip()# 拆分字符串s1 = re.sub(r'[\u4e00-\u9fff0-9]', '', s).strip() # 删除中文和数字,保留英文s2 = re.sub(r'[a-zA-Z0-9]', '', s).strip() # 删除英文和数字,保留中文s3 = re.sub(r'[\u4e00-\u9fffa-zA-Z]', '', s).strip() # 删除中文和英文,保留数字return s1, s2, s3# 测试
s = " sdd dsd 新的谁 说的 12515 "
s1, s2, s3 = split_string(s)
print(f"s1 = '{s1}'")
print(f"s2 = '{s2}'")
print(f"s3 = '{s3}'")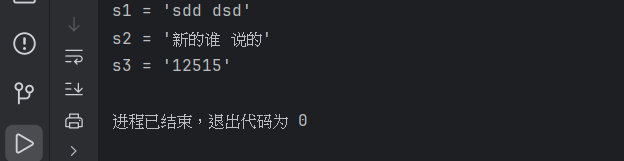
二.将长字符串各类型拆分
import redef split_string(s):# 去除多余空格s = re.sub(r'\s+', ' ', s).strip()# 拆分字符串s1 = re.sub(r'[\u4e00-\u9fff0-9]', '', s).strip() # 英文s2 = re.sub(r'[a-zA-Z0-9]', '', s).strip() # 中文s3 = re.sub(r'[a-zA-Z\u4e00-\u9fff]', '', s).strip() # 数字return s1, s2, s3s = ''' Activity 发现问题的活动Trigger 触发因素Impact 结果影响Phase Found 问题发现阶段Severity 严重程度Target 问题根源对象Defect Type 缺陷类型Content Type 缺陷内容类型Qualifier 缺陷界定Source 问题责任来源Age 缺陷年龄Location 问题位置
'''print(s)s1, s2, s3 = split_string(s)
print(f"s1 = '{s1}'")
print(f"s2 = '{s2}'")
print(f"s3 = '{s3}'")
三.将长字符串各类型拆分再整理
import redef split_string(s):# 去除多余空格s = re.sub(r'\s+', ' ', s).strip()# 拆分字符串s1 = re.sub(r'[\u4e00-\u9fff0-9]', '', s).strip() # 英文s2 = re.sub(r'[a-zA-Z0-9]', '', s).strip() # 中文s3 = re.sub(r'[a-zA-Z\u4e00-\u9fff]', '', s).strip() # 数字return s1, s2, s3def chaihuan(s1,s2,s3):# 去除多余空格s1 = ' '.join(s1.split())s2 = ' '.join(s2.split())s3 = ' '.join(s3.split())# 按照空格拆分字符串s1,生成列表c1c1 = s1.split(' ')c2 = s2.split(' ')c3 = s3.split(' ')# 将字符串s1中的空格替换为换行符,生成字符串t1t1 = s1.replace(' ', '\n')t2 = s2.replace(' ', '\n')t3 = s3.replace(' ', '\n')# 输出结果print("c1:", c1)print("c2:", c2)print("c3:", c3)print("t1:\n", t1)print("t2:\n", t2)print("t3:\n", t3)return c1,c2,c3,t1,t2,t3s = ''' Activity 发现问题的活动Trigger 触发因素Impact 结果影响Phase Found 问题发现阶段Severity 严重程度Target 问题根源对象Defect Type 缺陷类型Content Type 缺陷内容类型Qualifier 缺陷界定Source 问题责任来源Age 缺陷年龄Location 问题位置
'''print(f'{s}\n')
print('--------------------------------')
s1, s2, s3 = split_string(s)
print(f"s1 = '{s1}'\n")
print(f"s2 = '{s2}'\n")
print(f"s3 = '{s3}'\n")
print("------------拆换开始----------------------")
c1, c2, c3, t1, t2, t3 = chaihuan(s1, s2, s3)
print("------------各自明细----------------------")
print(f"c1 = '{c1}'\n")
print(f"c2 = '{c2}'\n")
print(f"c3 = '{c3}'\n")
print(f"t1 = '{t1}'\n")
print(f"t2 = '{t2}'\n")
print(f"t3 = '{t3}'\n")
整理不易,诚望各位看官点赞 收藏 评论 予以支持,这将成为我持续更新的动力源泉。若您在阅览时存有异议或建议,敬请留言指正批评,让我们携手共同学习,共同进取,吾辈自当相互勉励!