在 Windows 11 上从零复现 3D Gaussian Splatting (3DGS)
一、环境准备与基础软件安装
| 硬件/软件 | 作用 | 推荐/必须 |
|---|---|---|
| 系统 | Windows 11 | 基础环境 |
| 显卡 | RTX 3060 (12GB) | 必须 NVIDIA GPU |
| Git Bash | 克隆代码,命令行操作 | 推荐 |
| Anaconda3 | 隔离 Python 环境 | 强烈推荐 |
| CUDA 11.7 | GPU 计算核心,匹配 PyTorch | 必须 |
| VS 2019 | 编译器工具链(C++/CUDA) | 必须 |
1. CUDA 11.7 安装与验证
cuda11.7 地址 : [cuda11.7](CUDA Toolkit 11.7 Downloads | NVIDIA Developer)
更多cuda版本选择: CUDA Toolkit Archive | NVIDIA Developer由于我们将使用 PyTorch cu117 版本,CUDA 必须为 11.7。
-
下载:访问 CUDA Toolkit 11.7 下载页面,下载并默认安装。
-
设置系统环境变量:安装完成后,确保
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7目录存在。选择path系统环境变量,选择新建。 -
验证:打开 CMD 终端,输入:
nvcc --version如果显示版本信息,即为成功。
2. Visual Studio 2019 (VS2019) 安装
VS2019 社区版即可。安装时,确保勾选 “使用 C++ 的桌面开发” 工作负载,因为后续安装子模块时需要 C++ 编译器。
二、3DGS 环境与依赖安装
1. 创建并激活 Conda 环境
conda create -n 3dgs python=3.8
conda activate 3dgs
2. 代码克隆与 PyTorch 安装
使用 Git Bash 克隆代码,必须加上 --recursive 参数以确保子模块也被下载。
git clone https://github.com/graphdeco-inria/gaussian-splatting --recursive
cd gaussian-splatting
3. 安装 PyTorch (CUDA 11.7 版本)
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu117
在国内下载 PyTorch 时,建议关闭代理或 VPN,使用官方镜像通常速度更快。
3. 安装依赖包,推荐分别执行
pip install plyfile
pip install tqdm
pip install opencv-python
pip install joblib
- 安装子模块,推荐分别执行
# 注意:这些命令必须在设置了 CUDA_HOME 环境变量的终端中运行
pip install submodules/diff-gaussian-rasterization
pip install submodules/simple-knn
pip install submodules/fused-ssim
如果你在安装子模块时遇到 CUDA_HOME environment variable is not set 错误,请确保成功设置cuda的环境变量
三、使用官方数据训练
下载官方数据:GitHub - graphdeco-inria/gaussian-splatting: Original reference implementation of “3D Gaussian Splatting for Real-Time Radiance Field Rendering”

1. 可视化数据集
可视化工具下载地址: https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/binaries/viewers.zip
在项目根目录下创建文件夹viewers,将压缩包中的文件全部复制到viewers文件夹中
在数据集还在训练中,接着再开启个CMD命令行,用cd命令切换到D:\gaussian-splatting-main\viewers\bin(根据自己路径修改)执行可视化命令,如果出现画面则为成功
.\SIBR_remoteGaussian_app.exe
2. 运行训练代码
python train.py -s D:\paper_data\3dgs\gaussian-splatting\tandt_db\db\playroom --iterations 6000
如果显存不够,可以尝试降低质量
--resolution 4 降低分辨率
--percent_dense 0.3 控制点云密度为 30%
python train.py -s D:\paper_data\3dgs\gaussian-splatting\tandt_db\db\playroom --iterations 6000 --resolution 2
四、数据集制作(自制数据)
为了方便训练自制数据,我们需要安装 Colmap 和 FFmpeg。
1. 安装 Colmap 和 FFmpeg
下载 Colmap CUDA 版本 和 FFmpeg Essentials。
- 在项目根目录(
gaussian-splatting)下新建tools目录。 - 将下载的文件解压到
tools中。 - 配置系统环境变量:将 Colmap 和 FFmpeg 的
bin目录路径(例如D:\...tools\COLMAP-3.8-windows-cuda\bin)添加到系统的 Path 环境变量中。 - 验证:打开 CMD,输入
COLMAP和ffmpeg -version,若能正常运行则安装成功。
2. 视频转图片
将你的视频转换为一系列图片。
# 示例:将 video/chair.mp4 逐帧转为图片序列
ffmpeg -i video/chair.mp4 image/input_%04d.png
【经验】 视频逐帧提取图片数量过多(如 500 张)会导致 Colmap 和训练时间过长。为加速,请在 ffmpeg 命令中加入 -r <帧率> 参数。例如:
# 降低到 5 帧/秒,图片数量大幅减少
ffmpeg -i video/chair.mp4 -r 5 image/input_%04d.png
3. 图片转点云 (Colmap)
在项目目录下,新建数据集文件夹(例如 lab_chair),并在其中创建 input 目录存放图片,distorted 目录为空。然后运行转换脚本:
python convert.py -s lab_chair
这一步将调用 Colmap 进行相机位姿估计和稀疏点云生成。
4.运行训练
# 自制数据集训练示例
python train.py -s lab_chair -m lab_chair/output --resolution 2
-s lab_chair:指定数据集源文件夹。-m lab_chair/output:指定输出模型目录。--resolution 2:【关键优化】 图像分辨率降低 2 倍(1/4 尺寸),可以大幅减少显存占用和训练时间。
5.查看模型
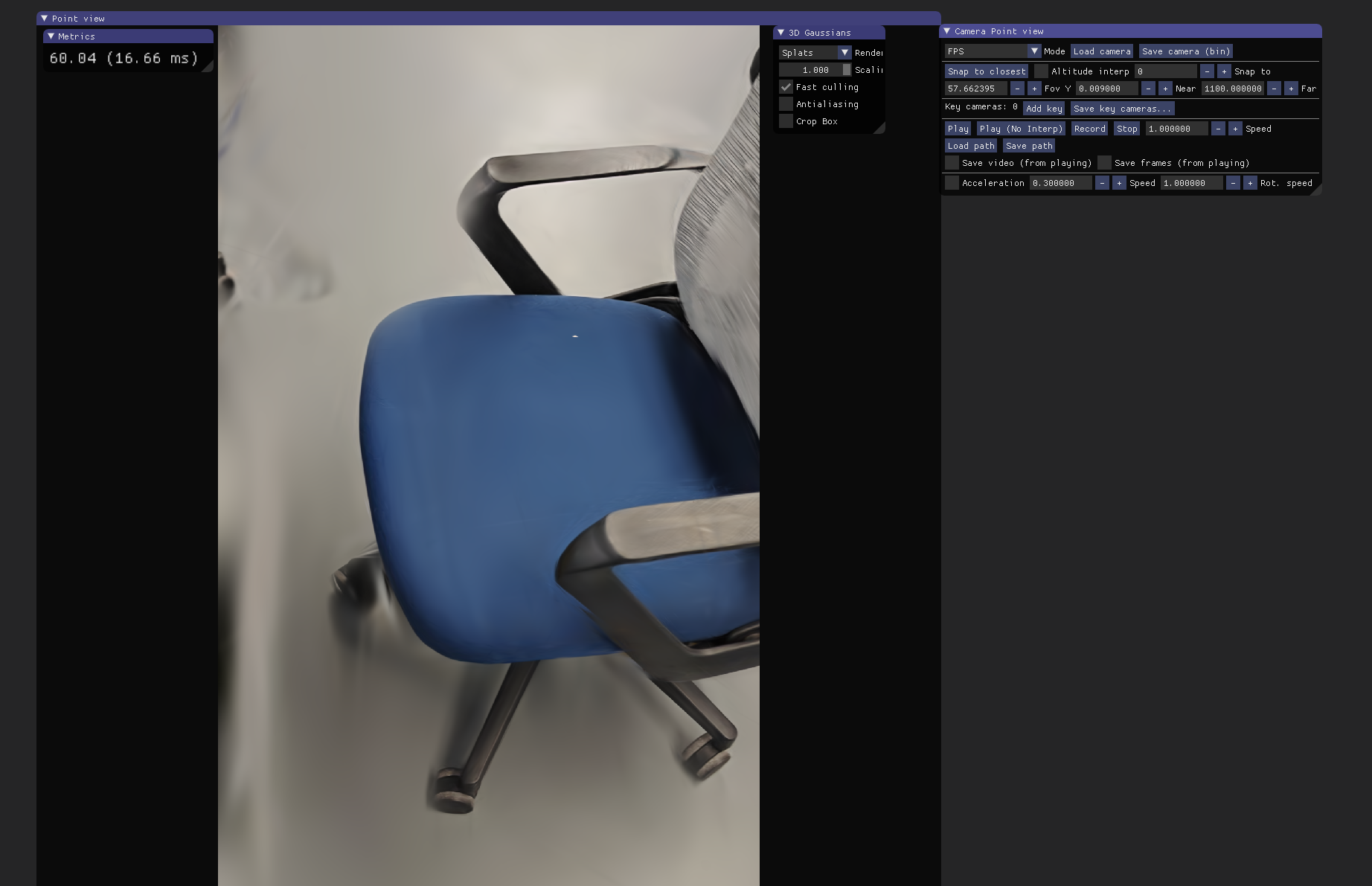
加载模型: 运行以下命令,替换为你实际的模型输出路径:
.\viewers\bin\SIBR_gaussianViewer_app -m D:\paper_code\3dgs\gaussian-splatting\output\6d2101eb-9
报错 由于找不到 cudart64_12.dll, 无法继续执行代码:这是因为查看器是为 CUDA 12.x 编译的。你需要下载 cudart64_12.dll 并将其复制到 viewers\bin 目录下即可解决。
下载地址:CUDART64_12.DLL : Free .DLL Download