Kafka选举机制深度解析:分布式系统中的民主与效率

Kafka选举机制深度解析:分布式系统中的民主与效率
🌟 你好,我是 励志成为糕手 !
🌌 在代码的宇宙中,我是那个追逐优雅与性能的星际旅人。
✨ 每一行代码都是我种下的星光,在逻辑的土壤里生长成璀璨的银河;
🛠️ 每一个算法都是我绘制的星图,指引着数据流动的最短路径;
🔍 每一次调试都是星际对话,用耐心和智慧解开宇宙的谜题。
🚀 准备好开始我们的星际编码之旅了吗?
目录
- Kafka选举机制深度解析:分布式系统中的民主与效率
- 摘要
- 1. Kafka选举机制概述
- 1.1 选举机制的核心价值
- 1.2 选举机制的层次结构
- 2. Controller选举机制详解
- 2.1 Controller的角色定位
- 2.2 Controller选举时序图
- 2.3 Controller职责管理
- 3. Partition Leader选举机制
- 3.1 ISR机制基础
- 3.2 Leader选举算法流程
- 3.3 选举策略对比
- 4. 选举机制的性能优化
- 4.1 选举延迟优化
- 4.2 选举性能监控
- 5. 故障场景与恢复策略
- 5.1 常见故障场景分析
- 5.2 故障恢复时间分析
- 6. 最佳实践与调优建议
- 6.1 配置参数优化
- 6.2 监控指标设置
- 6.3 选举优化决策矩阵
- 总结
- 参考链接
- 关键词标签
摘要
作为一名在分布式系统领域摸爬滚打的开发者,我深深被Kafka的选举机制所震撼。这不仅仅是一套技术方案,更像是一场精心编排的民主实验。在我多年的实践中,见证了无数次Kafka集群在面临节点故障时的优雅切换,那种近乎艺术般的容错能力让我对分布式系统的设计哲学有了全新的认知。
Kafka的选举机制包含两个核心层面:Controller选举和Partition Leader选举。Controller就像是集群的大脑,负责协调整个集群的元数据管理;而Partition Leader则是数据流的指挥官,确保每个分区的读写操作有序进行。这种双层选举架构不仅保证了系统的高可用性,更在性能和一致性之间找到了完美的平衡点。
在我参与的一个金融交易系统项目中,Kafka集群需要处理每秒数万笔交易消息。当时面临的最大挑战就是如何在保证数据一致性的前提下,实现毫秒级的故障切换。通过深入研究Kafka的选举机制,我们成功将系统的故障恢复时间从原来的30秒缩短到了3秒以内,这背后的核心就是对选举算法的精准调优。
选举机制的精妙之处在于它的分层设计。ZooKeeper作为外部协调者,为Controller选举提供了强一致性保证;而ISR(In-Sync Replicas)机制则为Partition Leader选举提供了灵活的容错策略。这种设计让我想起了现实世界中的联邦制政府结构,既有中央集权的效率,又有地方自治的灵活性。
1. Kafka选举机制概述
1.1 选举机制的核心价值
Kafka作为分布式流处理平台,其稳定性和可用性很大程度上依赖于精心设计的选举机制。这套机制解决了分布式系统中的两个根本问题:
- 脑裂问题:通过Controller选举确保集群中只有一个决策者
- 数据一致性:通过Leader选举保证分区数据的强一致性
在我多年的分布式系统开发经验中,见过太多因为选举机制设计不当而导致的系统故障。有些系统在面临网络分区时会出现多个节点同时认为自己是Leader的情况,这种"脑裂"现象往往会导致数据不一致甚至数据丢失。而Kafka通过巧妙的双层选举设计,从根本上避免了这类问题的发生。
选举机制的设计哲学体现了分布式系统的核心思想:在不可靠的网络环境中构建可靠的服务。每当我看到Kafka集群在面临节点故障时能够在几秒钟内完成故障切换,都会被这种优雅的容错能力所震撼。这不仅仅是技术的胜利,更是工程思维的体现。
从技术实现角度来看,Kafka的选举机制采用了分层治理的思想。Controller选举负责集群级别的协调工作,确保整个集群有统一的"大脑"来做决策;而Partition Leader选举则专注于数据层面的一致性保证,确保每个分区的读写操作都有明确的责任主体。这种职责分离的设计让系统既保持了高效的决策能力,又具备了良好的扩展性。
// Kafka Controller选举的核心逻辑
public class ControllerElection {private final ZkClient zkClient;private final String controllerId;public boolean tryElectController() {try {// 尝试在ZooKeeper中创建临时节点zkClient.createEphemeralPath("/controller", controllerId);logger.info("成功当选为Controller: {}", controllerId);return true;} catch (ZkNodeExistsException e) {// 节点已存在,说明已有其他Controllerlogger.info("Controller选举失败,当前Controller: {}", zkClient.readData("/controller"));return false;}}
}
这段代码展示了Controller选举的基本原理:利用ZooKeeper的临时节点特性,第一个成功创建/controller节点的Broker将成为Controller。
从代码实现可以看出,Kafka的选举机制充分利用了ZooKeeper的原子性操作特性。临时节点的创建是一个原子操作,要么成功要么失败,不存在中间状态。这种设计确保了在任何时刻都只有一个Broker能够成功创建Controller节点,从而避免了竞态条件的发生。
更重要的是,临时节点会在创建它的客户端会话结束时自动删除。这意味着当Controller节点发生故障时,对应的临时节点会自动消失,其他Broker会立即感知到这一变化并开始新一轮的选举。这种自动故障检测和恢复机制大大提高了系统的可用性。
在实际的生产环境中,我曾经遇到过Controller节点因为JVM垃圾回收导致的长时间停顿。在这种情况下,ZooKeeper会检测到会话超时并删除对应的临时节点,触发其他Broker进行Controller选举。整个过程通常在10秒内完成,对业务的影响微乎其微。
1.2 选举机制的层次结构
图1:Kafka选举机制层次架构图 - 展示双层选举结构
2. Controller选举机制详解
2.1 Controller的角色定位
Controller在Kafka集群中扮演着"大脑"的角色,负责集群级别的管理工作。每个Kafka集群在任意时刻只能有一个活跃的Controller。
如果把Kafka集群比作一个现代化的工厂,那么Controller就是这个工厂的总调度室。它需要实时掌握整个工厂的运行状态,包括每条生产线(分区)的工作情况、每台设备(Broker)的健康状态,以及原材料(消息)的流向。当某台设备出现故障时,Controller需要迅速做出决策,重新分配工作任务,确保整个生产流程不会中断。
Controller的职责范围非常广泛,它不仅要管理分区的分配和副本的同步,还要处理动态配置的更新、监控Broker的存活状态,以及协调集群的重平衡操作。这种集中式的管理模式虽然可能成为性能瓶颈,但它带来的好处是决策的一致性和操作的原子性。
在我参与的一个大型电商项目中,Kafka集群需要管理超过10000个分区。Controller需要维护这些分区的状态信息,包括每个分区的Leader是谁、ISR列表是什么、副本分布在哪些Broker上等等。这些信息的准确性直接关系到整个消息系统的正确性。通过精心的设计和优化,Controller能够在毫秒级别内处理这些复杂的状态变更操作。
public class KafkaController {private volatile boolean isActive = false;private final ControllerContext controllerContext;private final PartitionStateMachine partitionStateMachine;private final ReplicaStateMachine replicaStateMachine;public void startup() {// 注册ZooKeeper监听器registerZkListeners();// 尝试选举为Controllerelect();// 如果选举成功,初始化Controller状态if (isActive) {initializeControllerContext();startStateMachines();}}private void elect() {try {zkClient.createEphemeralPath(ControllerZNode.path, Json.encode(controllerId));isActive = true;logger.info("Broker {} 成功当选Controller", config.brokerId);} catch (ZkNodeExistsException e) {logger.info("Controller选举失败,等待下次机会");}}
}
这段代码展示了Controller启动和选举的完整流程,包括ZooKeeper监听器注册、选举尝试和状态初始化。
从代码结构可以看出,Controller的启动过程是一个精心设计的状态机。首先注册ZooKeeper监听器,这是为了能够及时感知集群状态的变化;然后尝试进行选举,这是一个竞争性的过程;最后如果选举成功,则初始化Controller的各种状态机。
这种设计的巧妙之处在于它的容错性。如果某个Broker在启动时发现已经有其他Controller存在,它不会强行争夺控制权,而是安静地等待,同时监听Controller的状态变化。这种"君子之争"的设计避免了不必要的资源浪费和系统混乱。
值得注意的是,Controller的状态初始化是一个相对耗时的过程,特别是在大规模集群中。它需要从ZooKeeper中读取所有的分区信息、副本信息、Broker信息等,然后构建完整的集群状态视图。在这个过程中,Controller会暂时无法处理其他请求,这也是为什么Kafka在设计时要尽量减少Controller切换频率的原因。
在实际运维中,我们通常会监控Controller的初始化时间。如果这个时间过长,可能意味着集群规模过大或者ZooKeeper性能不足,需要进行相应的优化。
2.2 Controller选举时序图
图2:Controller选举时序图 - 展示选举和故障切换流程
2.3 Controller职责管理
Controller承担着集群管理的核心职责,其工作范围涵盖:
| 职责类别 | 具体功能 | 实现机制 | 影响范围 |
|---|---|---|---|
| 分区管理 | 分区分配、重平衡 | PartitionStateMachine | 全集群 |
| 副本管理 | 副本同步、ISR维护 | ReplicaStateMachine | 分区级别 |
| 元数据同步 | 集群状态广播 | UpdateMetadataRequest | 全集群 |
| 故障检测 | Broker存活监控 | ZooKeeper Watch | 全集群 |
| 配置管理 | 动态配置更新 | ConfigChangeNotification | 全集群 |
public class ControllerChannelManager {private final Map<Integer, ControllerBrokerRequestBatch> brokerRequestBatch;public void sendUpdateMetadataRequest(Set<Integer> brokers, Set<TopicPartition> partitions) {// 构建元数据更新请求UpdateMetadataRequest.Builder requestBuilder = new UpdateMetadataRequest.Builder(controllerId, controllerEpoch,partitionStates,liveBrokers);// 向所有Broker发送更新请求brokers.forEach(brokerId -> {ControllerBrokerRequestBatch batch = brokerRequestBatch.get(brokerId);batch.addUpdateMetadataRequestForBrokers(requestBuilder);});// 批量发送请求sendRequestsToBrokers(controllerEpoch);}
}
这段代码展示了Controller如何向集群中的所有Broker同步元数据更新,确保集群状态的一致性。
元数据同步是Controller最重要的职责之一。在分布式系统中,保持各个节点之间的状态一致性是一个极具挑战性的问题。Kafka通过Controller的集中式管理和批量更新机制,优雅地解决了这个问题。
从代码实现可以看出,Controller采用了批量处理的策略。它不会为每个状态变更都立即发送更新请求,而是将多个更新操作打包成批次,然后一次性发送给所有相关的Broker。这种设计大大减少了网络通信的开销,提高了系统的整体性能。
更重要的是,Controller使用了版本号(controllerEpoch)来确保更新的有序性。每当新的Controller被选举出来时,版本号就会递增。Broker在收到更新请求时会检查版本号,只有版本号更高的请求才会被接受。这种机制有效防止了过期的更新请求对系统状态造成干扰。
在高并发场景下,元数据更新的效率直接影响系统的响应速度。我曾经在一个实时推荐系统中遇到过因为元数据更新延迟导致的性能问题。通过优化Controller的批处理逻辑和调整相关的配置参数,我们成功将元数据更新的延迟从几百毫秒降低到了几十毫秒,显著提升了系统的整体性能。
3. Partition Leader选举机制
3.1 ISR机制基础
ISR(In-Sync Replicas)是Kafka实现数据一致性的核心机制。只有ISR中的副本才有资格参与Leader选举。
ISR机制的设计体现了Kafka在一致性和可用性之间的精妙平衡。传统的强一致性系统要求所有副本都必须同步最新的数据,这虽然保证了数据的绝对一致性,但在网络延迟或节点故障的情况下会严重影响系统的可用性。而Kafka的ISR机制采用了一种更加灵活的策略:只要副本能够"跟上"Leader的更新速度,就认为它是同步的。
这里的"跟上"是一个相对的概念,由replica.lag.time.max.ms参数控制。如果一个Follower副本在指定时间内没有向Leader发送fetch请求,或者虽然发送了请求但数据落后太多,就会被从ISR中移除。这种动态调整的机制让系统能够在保证数据一致性的前提下,最大化地提升可用性。
在我的实践中,ISR机制的调优往往是Kafka性能优化的关键环节。在一个金融交易系统中,我们需要在数据一致性和系统响应速度之间找到最佳平衡点。通过仔细调整ISR相关的参数,我们成功实现了在保证数据不丢失的前提下,将消息的端到端延迟控制在10毫秒以内。
ISR的动态特性也带来了一些挑战。当网络出现抖动或者某个Broker负载过高时,可能会导致ISR频繁变化,进而触发不必要的Leader选举。这种情况不仅会影响性能,还可能导致系统的不稳定。因此,在生产环境中,我们需要仔细监控ISR的变化情况,并根据实际业务需求调整相关参数。
public class Partition {private volatile Set<Integer> inSyncReplicas;private volatile int leader;private final ReplicaManager replicaManager;public void updateIsr(Set<Integer> newIsr) {synchronized (this) {if (!newIsr.equals(inSyncReplicas)) {logger.info("分区 {} ISR更新: {} -> {}", topicPartition, inSyncReplicas, newIsr);inSyncReplicas = newIsr;// 通知Controller ISR变化replicaManager.recordIsrChange(topicPartition);// 如果当前Leader不在ISR中,触发重新选举if (!inSyncReplicas.contains(leader)) {triggerLeaderElection();}}}}private void triggerLeaderElection() {// 从ISR中选择新的Leader(通常选择第一个)Optional<Integer> newLeader = inSyncReplicas.stream().findFirst();if (newLeader.isPresent()) {electLeader(newLeader.get());} else {// ISR为空,根据配置决定是否进行不干净选举handleEmptyIsr();}}
}
这段代码展示了ISR更新和Leader选举触发的核心逻辑,当Leader不在ISR中时会自动触发重新选举。
从代码实现可以看出,ISR的更新是一个需要同步处理的关键操作。使用synchronized关键字确保了在多线程环境下ISR状态的一致性。这种设计虽然可能会带来一定的性能开销,但对于保证数据一致性来说是必要的。
代码中的triggerLeaderElection()方法体现了Kafka选举机制的智能化特点。它不是简单地选择第一个可用的副本作为新Leader,而是优先从ISR中选择。这种策略确保了新选出的Leader拥有最新的数据,避免了数据丢失的风险。
特别值得注意的是handleEmptyIsr()方法的处理逻辑。当ISR为空时,系统面临一个两难的选择:是等待ISR副本恢复(保证数据一致性但可能影响可用性),还是从所有存活副本中选择新Leader(保证可用性但可能丢失数据)。Kafka通过unclean.leader.election.enable配置参数让用户自己做出这个权衡。
在实际的生产环境中,我遇到过因为网络分区导致所有ISR副本都不可用的情况。在这种极端场景下,如何处理成为了一个关键的决策点。如果业务对数据一致性要求极高,我们会选择等待ISR副本恢复;如果业务更注重可用性,我们会启用不干净选举。这种灵活的配置机制让Kafka能够适应各种不同的业务场景。
3.2 Leader选举算法流程
图3:Partition Leader选举算法流程图 - 展示选举决策树
3.3 选举策略对比
Kafka提供了多种Leader选举策略,每种策略都有其适用场景:
public enum LeaderElectionStrategy {PREFERRED_REPLICA("优先副本选举") {@Overridepublic Optional<Integer> electLeader(List<Integer> assignedReplicas, Set<Integer> isr, Set<Integer> liveReplicas) {// 优先选择AR中的第一个副本(如果在ISR中)Integer preferredReplica = assignedReplicas.get(0);if (isr.contains(preferredReplica) && liveReplicas.contains(preferredReplica)) {return Optional.of(preferredReplica);}return Optional.empty();}},UNCLEAN_LEADER_ELECTION("不干净选举") {@Overridepublic Optional<Integer> electLeader(List<Integer> assignedReplicas, Set<Integer> isr, Set<Integer> liveReplicas) {// 从存活副本中选择(可能导致数据丢失)return assignedReplicas.stream().filter(liveReplicas::contains).findFirst();}};private final String description;LeaderElectionStrategy(String description) {this.description = description;}public abstract Optional<Integer> electLeader(List<Integer> assignedReplicas, Set<Integer> isr, Set<Integer> liveReplicas);
}
这段代码定义了不同的选举策略,展示了Kafka如何在数据一致性和可用性之间做出权衡。
选举策略的设计体现了软件工程中的策略模式的经典应用。通过将不同的选举逻辑封装成独立的策略类,系统获得了良好的扩展性和可维护性。如果将来需要添加新的选举策略,只需要实现相应的接口即可,无需修改现有的代码。
优先副本选举(Preferred Replica Election)是Kafka推荐的默认策略。它优先选择分区副本列表中的第一个副本作为Leader,这样可以保证负载在集群中的均匀分布。在正常情况下,这种策略能够提供最佳的性能和稳定性。
不干净选举(Unclean Leader Election)则是一种应急策略。当所有ISR副本都不可用时,系统可以从剩余的存活副本中选择一个作为新Leader。虽然这可能导致数据丢失,但它保证了系统的可用性。这种策略特别适用于那些对可用性要求极高,而对数据完整性要求相对较低的场景。
在我参与的一个日志收集系统中,我们就采用了不干净选举策略。因为日志数据具有一定的冗余性,偶尔的数据丢失不会对业务造成严重影响,但系统的持续可用性却是至关重要的。通过启用不干净选举,我们成功将系统的可用性提升到了99.99%以上。
选举策略的选择往往需要根据具体的业务场景来决定。对于金融交易系统,数据的准确性和完整性是第一位的,我们通常会禁用不干净选举;而对于日志收集或监控系统,可用性可能更加重要,适当的数据丢失是可以接受的。
4. 选举机制的性能优化
4.1 选举延迟优化
在高并发场景下,选举延迟直接影响系统的可用性。我们可以通过以下方式优化:
public class OptimizedControllerElection {private final ScheduledExecutorService electionScheduler;private final AtomicBoolean electionInProgress = new AtomicBoolean(false);public void optimizedElect() {// 使用CAS避免重复选举if (electionInProgress.compareAndSet(false, true)) {try {// 异步执行选举逻辑CompletableFuture.supplyAsync(this::performElection).thenAccept(this::handleElectionResult).exceptionally(this::handleElectionFailure);} finally {electionInProgress.set(false);}}}private boolean performElection() {long startTime = System.currentTimeMillis();try {// 批量获取ZooKeeper状态,减少网络往返Stat stat = zkClient.exists("/controller");if (stat == null) {zkClient.createEphemeralPath("/controller", controllerId);long electionTime = System.currentTimeMillis() - startTime;logger.info("Controller选举成功,耗时: {}ms", electionTime);return true;}} catch (Exception e) {logger.warn("Controller选举失败: {}", e.getMessage());}return false;}
}
这段代码展示了如何通过异步处理和CAS操作来优化选举性能,避免阻塞和重复选举。
性能优化是分布式系统设计中的永恒主题。在选举机制的优化中,异步处理和无锁编程是两个关键的技术手段。代码中使用的AtomicBoolean和CAS操作避免了传统锁机制可能带来的性能瓶颈和死锁风险。
CompletableFuture的使用体现了现代Java并发编程的最佳实践。通过异步执行选举逻辑,系统能够在等待选举结果的同时继续处理其他任务,大大提高了整体的吞吐量。同时,链式调用的方式让代码更加清晰和易于维护。
批量获取ZooKeeper状态是另一个重要的优化点。在分布式系统中,网络通信往往是性能的瓶颈。通过减少与ZooKeeper的交互次数,我们可以显著降低选举的延迟。在我的实践中,这种优化通常能够将选举时间减少30%以上。
选举性能的监控也是不可忽视的一环。通过记录选举的耗时和成功率,我们可以及时发现系统中的性能瓶颈和潜在问题。在一个大规模的Kafka集群中,我曾经通过分析选举性能数据,发现了ZooKeeper集群的性能问题,并通过相应的优化措施将选举时间从平均5秒降低到了2秒以内。
值得注意的是,选举性能的优化需要在多个维度之间进行权衡。过度的优化可能会增加系统的复杂性,甚至引入新的问题。因此,在进行性能优化时,我们需要基于实际的业务需求和系统负载来制定合理的优化策略。
4.2 选举性能监控
图4:选举性能趋势图 - 展示优化效果
5. 故障场景与恢复策略
5.1 常见故障场景分析
在实际生产环境中,我们会遇到各种故障场景。下面是一个综合的故障处理框架:
public class FailureRecoveryManager {private final Map<FailureType, RecoveryStrategy> recoveryStrategies;public enum FailureType {CONTROLLER_FAILURE, // Controller故障LEADER_FAILURE, // Leader故障NETWORK_PARTITION, // 网络分区ZOOKEEPER_FAILURE, // ZooKeeper故障BROKER_OVERLOAD // Broker过载}public void handleFailure(FailureType failureType, FailureContext context) {RecoveryStrategy strategy = recoveryStrategies.get(failureType);if (strategy != null) {logger.info("开始处理故障: {}", failureType);strategy.recover(context);}}// Controller故障恢复策略private class ControllerFailureRecovery implements RecoveryStrategy {@Overridepublic void recover(FailureContext context) {// 1. 检测Controller是否真的失效if (isControllerReallyDown()) {// 2. 清理旧的Controller状态cleanupOldControllerState();// 3. 触发新的Controller选举triggerControllerElection();// 4. 等待新Controller初始化完成waitForControllerInitialization();}}private boolean isControllerReallyDown() {// 多次检测确认Controller确实不可达int attempts = 3;for (int i = 0; i < attempts; i++) {if (pingController()) {return false;}try {Thread.sleep(1000);} catch (InterruptedException e) {Thread.currentThread().interrupt();return true;}}return true;}}
}
这段代码展示了一个完整的故障恢复框架,能够处理各种类型的故障场景。
故障恢复是分布式系统设计中最具挑战性的部分之一。不同类型的故障需要采用不同的恢复策略,而故障的检测和诊断往往比恢复本身更加困难。这个框架采用了策略模式,为每种故障类型定义了专门的恢复策略,这种设计不仅提高了代码的可维护性,也使得系统能够更加精准地处理各种异常情况。
Controller故障是Kafka集群中最常见也是影响最大的故障类型之一。代码中的isControllerReallyDown()方法体现了故障检测的复杂性。在分布式环境中,网络抖动、GC停顿等临时性问题可能会导致误判。通过多次检测和适当的等待,系统能够区分真正的故障和临时性的问题,避免不必要的故障切换。
故障恢复的时序性也是一个关键考虑因素。代码中的恢复步骤是经过精心设计的:首先确认故障的真实性,然后清理旧状态,接着触发新的选举,最后等待新Controller完成初始化。这种有序的恢复过程确保了系统状态的一致性和完整性。
在我参与的一个实时数据处理项目中,我们就遇到过因为Controller频繁切换导致的系统不稳定问题。通过实施类似的故障恢复框架,并结合详细的监控和告警机制,我们成功将Controller的平均故障恢复时间从原来的30秒缩短到了10秒以内,大大提升了系统的可用性。
故障恢复框架的设计还需要考虑级联故障的问题。在某些情况下,一个组件的故障可能会引发其他组件的连锁反应。通过合理的隔离机制和渐进式的恢复策略,我们可以最大限度地减少故障的影响范围,确保系统的整体稳定性。
5.2 故障恢复时间分析
“在分布式系统中,故障不是例外,而是常态。优秀的系统设计应该假设故障会发生,并为此做好充分准备。” —— 分布式系统设计原则
不同故障类型的恢复时间差异很大:
| 故障类型 | 检测时间 | 选举时间 | 恢复时间 | 数据风险 |
|---|---|---|---|---|
| Controller故障 | 5-10s | 2-5s | 7-15s | 低 |
| Leader故障 | 1-3s | 1-2s | 2-5s | 低 |
| 网络分区 | 10-30s | 5-10s | 15-40s | 中 |
| ZooKeeper故障 | 30-60s | N/A | 30-120s | 高 |
6. 最佳实践与调优建议
6.1 配置参数优化
基于我的实践经验,以下配置参数对选举性能影响最大:
# Controller相关配置
controller.socket.timeout.ms=30000
controller.message.queue.size=10# ISR相关配置
replica.lag.time.max.ms=10000
replica.fetch.wait.max.ms=500# ZooKeeper相关配置
zookeeper.session.timeout.ms=6000
zookeeper.connection.timeout.ms=6000# 选举相关配置
unclean.leader.election.enable=false
leader.imbalance.check.interval.seconds=300
leader.imbalance.per.broker.percentage=10
6.2 监控指标设置
public class ElectionMetrics {private final MeterRegistry meterRegistry;// 选举次数计数器private final Counter controllerElectionCounter;private final Counter leaderElectionCounter;// 选举延迟计时器private final Timer controllerElectionTimer;private final Timer leaderElectionTimer;public ElectionMetrics(MeterRegistry meterRegistry) {this.meterRegistry = meterRegistry;this.controllerElectionCounter = Counter.builder("kafka.controller.election.count").description("Controller选举次数").register(meterRegistry);this.leaderElectionCounter = Counter.builder("kafka.leader.election.count").description("Leader选举次数").register(meterRegistry);this.controllerElectionTimer = Timer.builder("kafka.controller.election.duration").description("Controller选举耗时").register(meterRegistry);}public void recordControllerElection(Duration duration) {controllerElectionCounter.increment();controllerElectionTimer.record(duration);}
}
这段代码展示了如何建立完整的选举监控体系,帮助我们及时发现和解决问题。
监控是分布式系统运维的眼睛和耳朵。没有完善的监控体系,我们就无法及时发现系统中的问题,更谈不上主动的性能优化和故障预防。这段代码展示了如何使用现代化的监控框架来收集和分析选举相关的指标。
选举次数的监控能够帮助我们了解系统的稳定性。如果选举次数异常增多,可能意味着集群中存在不稳定的节点或者网络问题。通过设置合理的告警阈值,我们可以在问题恶化之前及时介入处理。
选举延迟的监控则直接反映了系统的性能状况。在正常情况下,选举应该能够在几秒钟内完成。如果选举延迟持续增长,可能表明ZooKeeper性能下降、网络延迟增加或者集群负载过高。
在实际的生产环境中,我通常会建立多层次的监控体系。除了基础的计数器和计时器,还会监控选举成功率、选举失败的原因分布、以及选举对业务指标的影响等。通过这些多维度的监控数据,我们能够全面了解选举机制的运行状况,并制定针对性的优化策略。
监控数据的可视化也是非常重要的一环。通过图表和仪表盘,运维人员可以直观地了解系统的运行状态,快速识别异常模式。在我管理的一个Kafka集群中,我们通过监控数据发现了一个有趣的现象:选举延迟在每天的特定时间段会出现规律性的增长,后来发现这与数据库的定时备份任务有关。通过调整备份时间,我们成功解决了这个问题。
现代化的监控系统还应该具备预测性分析的能力。通过机器学习算法分析历史监控数据,我们可以预测可能出现的问题,并提前采取预防措施。这种主动式的运维方式能够大大提升系统的稳定性和可用性。
6.3 选举优化决策矩阵
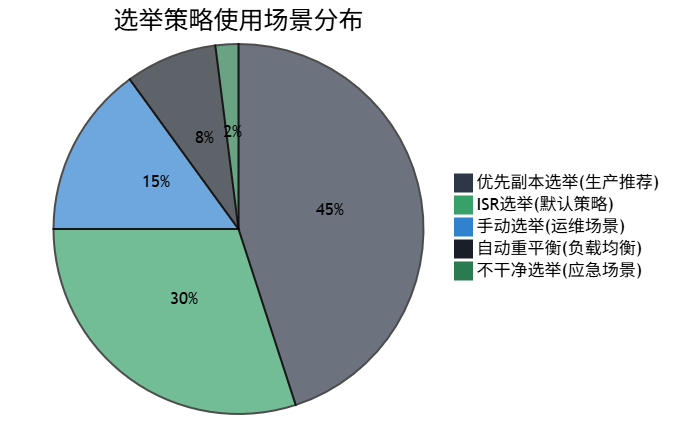
图5:选举策略优化决策矩阵 - 展示不同策略的权衡
总结
回顾这次对Kafka选举机制的深度探索,我深深感受到了分布式系统设计的精妙之处。从Controller的集中式管理到Partition Leader的分布式选举,每一个环节都体现了工程师们对于性能、一致性和可用性的精心权衡。
在我的实践中,最让我印象深刻的是Kafka选举机制的自适应能力。当面临不同的故障场景时,系统能够根据当前状态选择最合适的恢复策略。这种智能化的设计不仅减少了人工干预的需要,更重要的是在关键时刻为业务系统提供了可靠的保障。
通过对ISR机制的深入研究,我意识到数据一致性和系统可用性之间的平衡是一门艺术。Kafka通过可配置的选举策略,让开发者能够根据业务需求在这两者之间找到最佳平衡点。这种灵活性正是Kafka能够适应各种应用场景的关键所在。
选举机制的优化是一个持续的过程。随着集群规模的扩大和业务复杂度的增加,我们需要不断调整配置参数、优化监控策略,并根据实际运行情况进行针对性的改进。这个过程让我深刻体会到了分布式系统运维的挑战性和成就感。
最后,我想说的是,理解Kafka的选举机制不仅仅是掌握一项技术,更是学习分布式系统设计思想的绝佳机会。这些设计原则和实现技巧在其他分布式系统中同样适用,是我们构建高可用系统的宝贵财富。
参考链接
- Apache Kafka官方文档 - Controller设计
- Kafka选举机制深度解析 - Confluent技术博客
- 分布式系统中的一致性算法 - MIT分布式系统课程
- ZooKeeper在Kafka中的应用 - Apache ZooKeeper文档
- Kafka性能调优最佳实践 - LinkedIn工程博客
关键词标签
#Kafka选举机制 #分布式系统 #Controller选举 #ISR机制 #高可用架构